
基于BP-GamysBoost的乳腺癌诊断模型
2021-04-23 02:09:40彭慧娴托尼谢伊
计算机与现代化 2021年4期
刘 军,彭慧娴,黄 斌,托尼·谢伊
(1.佛山科学技术学院机电工程与自动化学院,广东 佛山 528225; 2.东密歇根大学工程技术学院,密歇根 伊普西兰蒂 MI 48197)
0 引 言
根据国际癌症研究机构(IARC)统计报告发现,乳腺癌仍然是导致全世界女性死亡的主要原因之一,据统计每年新增病例有近210万例[1]。经研究发现,如果在早期阶段能检测出乳腺癌,就能在癌症扩散前成功治疗局部肿瘤[2]。因此,乳腺癌肿瘤的早期准确诊断是医学诊断中的一项重要任务。针对传统乳腺癌诊断方式可能存在误诊、诊断耗时耗力等问题,智能辅助诊断成为近年医疗诊断领域的热点。随着数据挖掘与机器学习从各种数据集中提取模式和规则这一技术的成熟[3],使其在研究分类问题上有了很好的进展。受Fuzzy Min-Max(FMM)网络[4]的启发,Kumar等人[5]提出一种改进后的FMM网络用于数据分类;Bellazzi等人[6]提出一个框架来解决在临床医学中构建、评估和开发数据挖掘模型的问题。同时,在这样的发展背景下,分类模型不仅可以辅助医生进行疾病的识别和诊断,也为减少诊断错误的智能辅助诊断系统的建立提供了可能性。
据了解在机器学习领域,乳腺癌诊断一直被认为是一个分类问题。近年来,随着人工智能的发展,越来越多的智能分类方法已经应用于乳腺癌的诊断中。例如Singh等人[7]利用BP(Back Propagation)神经网络对乳腺癌组织病理学图像进行分类;George等人[8]开发了一种基于BP算法的多层感知器、概率神经网络(PNN)、学习矢量量化和支持向量机(SVM)[9]的智能乳腺癌分类系统;Nahato等人[10]使用粗糙集不可分辨关系的方法和反向传播神经网络(RS-BPNN)进行乳腺癌检测;Abdel-Zaher等人[11]提出了一种基于深度信念网络的无监督路径和反向传播监督路径相结合的乳腺癌检测计算机辅助诊断方案;Kaymak等人[12]通过BP神经网络[13]实现对乳腺癌图像的自动分类。基于以上用于乳腺癌诊断的分类器,不难看出BP算法在乳腺癌诊断中应用十分广泛。
当前,在医疗诊断过程中,信息、数据与知识间的关联表现出了一定的复杂性和模糊性[14],各种症状与其诊断结果之间的映射呈现出非线性关系。虽然在相比之下,人工神经网络中的BP神经网络能够更好地处理这种非线性关系,但它所存在过拟合和易陷入局部最优的问题也是不容忽视的。针对这一问题,人们通常借助遗传算法(GA)全局寻优和快速收敛的能力进行改善[15]。但遗传算法仍然容易陷入局部最优,于是引入模拟退火(SA)算法[16]对遗传算法进行改进,从而更好地避免陷入局部最优。对于大多数不平衡数据的分类,Adaboost算法[17]可直接作用于不平衡数据集的分类,但在乳腺癌数据分类中,Adaboost算法所采用增大错分样本权值的策略,忽略了样本不平衡带来的影响,从而容易造成漏诊现象。此外,在乳腺癌诊断中,仅靠Adaboost算法集成神经网络并不能提高分类问题的精度和准确性。为此,本文提出BP-GamysBoost算法,在标准的Adaboost算法基础上,建立BP神经网络模型,然后借助模拟退火遗传算法来优化BP神经网络的初始权值和阈值,使优化后的阈值和权值能更好地预测其输出,最后得到由BP弱分类器组成的强分类器,即BP-GamysBoost模型。本文选取权威数据库UCI的威斯康星乳腺癌数据集作为应用案例,采用与多个模型的多项性能指标进行评估对比的方法,验证BP-GamysBoost算法模型的合理性和有效性。
1 样本数据预处理
乳腺癌数据集存在冗余现象。为了减少冗余信息所造成的误差,减少计算量,提高医疗诊断效率,需要对数据样本进行降维处理。本文采用逐步回归分析法(Stepwise Regression)[18]对输入变量进行筛选,主要是以自变量对因变量作用程度作为变量选取的依据,从而保留作用程度大的变量,剔除作用小的变量。通常在计算过程中,变量的引入与剔除是在两端同时进行的,基本步骤如图1所示。通过MATLAB软件的stepwise的过程,在剔除p-val的值大于0.05的变量后,如图2所示,最终得到13个变量,具体标号为6、8、11、14、15、17、21、22、24、27、28、29、30。
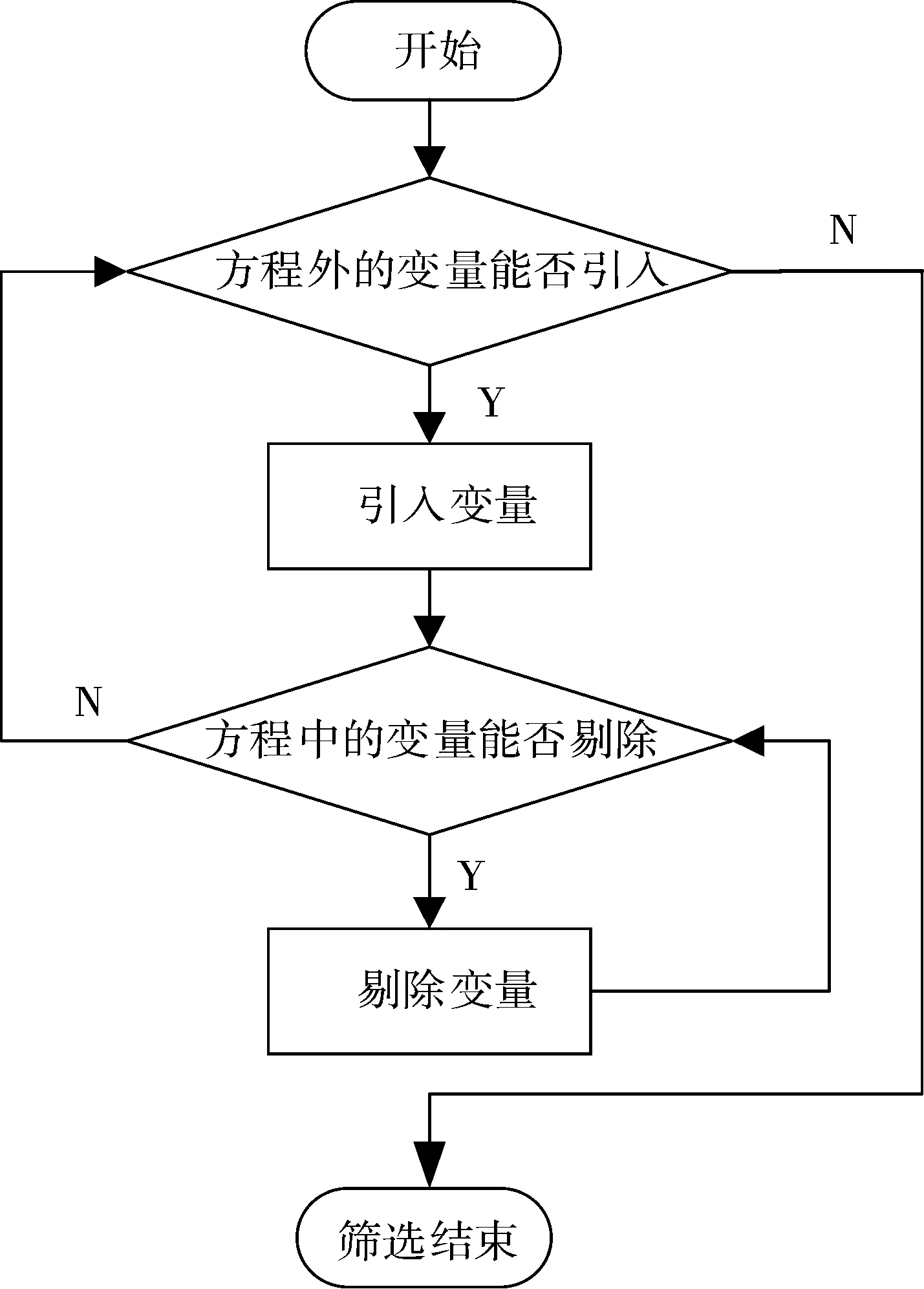
图1 逐步回归分析法基本步骤
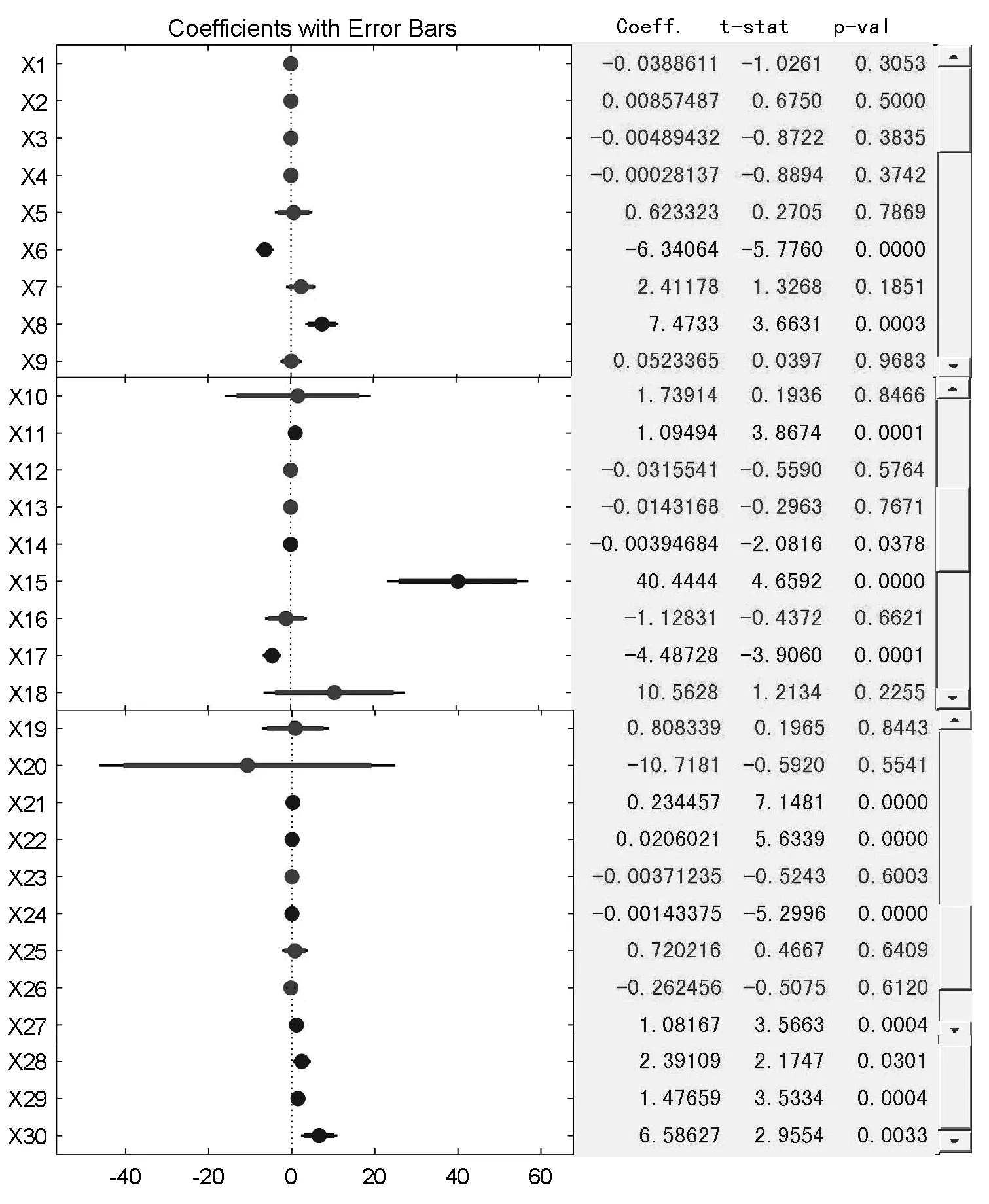
图2 逐步回归法变量筛选结果
逐步回归分析算法流程如下:

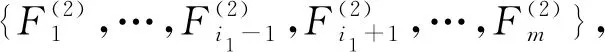
3)考虑因变量对变量子集{{Xi1,Xi2,Xk}|k∉{i1,i2}}的回归,重复步骤2。
重复上述步骤,直至经F检验后没有自变量引入。
2 算法简述
2.1 BP算法
BP算法在误差反向传播时,通常是通过计算输出层与期望值之间的误差来调整网络参数,从而使误差变小。对于每个训练样本,BP算法的基本流程为:1)将输入样本提供给输入神经元,使信号逐层传递至产生输出层结果;2)将计算出的误差信号反向传播至隐藏层单元;3)通过隐藏层神经元的误差修改权值;4)循环迭代至满足停止条件为止。BP算法通常采用梯度下降法来进行参数寻优,当误差函数具有多个局部最优时,则无法保证所找到的解是全局最优解。
2.2 GA算法
遗传算法因其全局搜索能力而在特征选择方面应用广泛[19-21]。由于遗传算法对底层搜索空间大小和多元分布的鲁棒性,所以在对高维空间进行特征选择时能提供有效策略。遗传算法的基本流程为:1)编码和产生初始种群;2)给定适应度函数,从而计算每个个体的适用度值;3)经过选择、交叉、变异等一系列操作产生新的种群;4)判断所得到的个体的最大适应度是否是最优解,如果是,则结束,反之则返回步骤2。
2.3 SA算法
模拟退火算法是一种启发式的全局优化方法[16],SA算法的基本思想是从一个初始的解决方案开始,然后与Metropolis Monte Carlo过程集成。SA的第一个迭代过程是生成新的解,然后判断其是否符合Metropolis准则,如果符合则接受,否则放弃。
2.4 BP-Adaboost算法
Adaboost作为一种迭代算法,其核心思想是对同一个训练集训练多个分类器(弱分类器),并将这些弱分类器组成强分类器。其算法本身是通过不断地改变权重来实现的,然后将更新后的权重作为下一个分类器的权重进行训练,最后将得到的多个弱分类器组成强分类器。而BP-Adaboost算法便是以BP神经网络为基础,即将BP神经网络模型作为弱分类器,通过不断地训练预测样本的输出,并结合Adaboost算法,最终得到所需要的强分类器。
3 本文提出的框架
本文提出的BP-GamysBoost算法是一种混合算法,是在BP-Adaboost算法的基础上进行优化。首先,因为BP-Adaboost中的BP神经网络拥有强大的表示能力,因此它容易陷入局部最优,从而导致其训练误差持续降低,但测试误差却可能上升的现象。故本文采用模拟退火遗传算法来克服这一缺点,即首先通过遗传算法生成适应度值较高的种群,然后通过SA操作对新种群的每个个体进行退火,不断循环重复,直到满足收敛准则为止[22],以此来得到最优的阈值和权值。流程框图如图3所示。

图3 BP-SAGA算法流程框图
该算法的核心流程为:先以种群中的个体代表BP神经网络的初始阈值和权值,其次将BP神经网络的预测误差作为个体初始化时的适应度值,最后通过一系列(选择、交叉、变异、退火)的操作流程,所得到的最优个体,即为BP神经网络的初始权值,从而克服单一BP神经网络的缺点,提高了BP神经网络的预测精度。标准的BP-Adaboost算法在每次迭代过程中更新权重时,主要是以错分的样本为基础,但在乳腺癌的医疗诊断的实际应用中,因医疗数据集分布不平衡的问题,所以需要更加注意漏诊现象,因此本文所提出的算法在迭代过程中是根据乳腺癌样本特点进行权重的改变,对于医疗诊断过程中出现的将患病样本错分为健康样本现象,分配更大的权重。本文算法流程如图4所示。
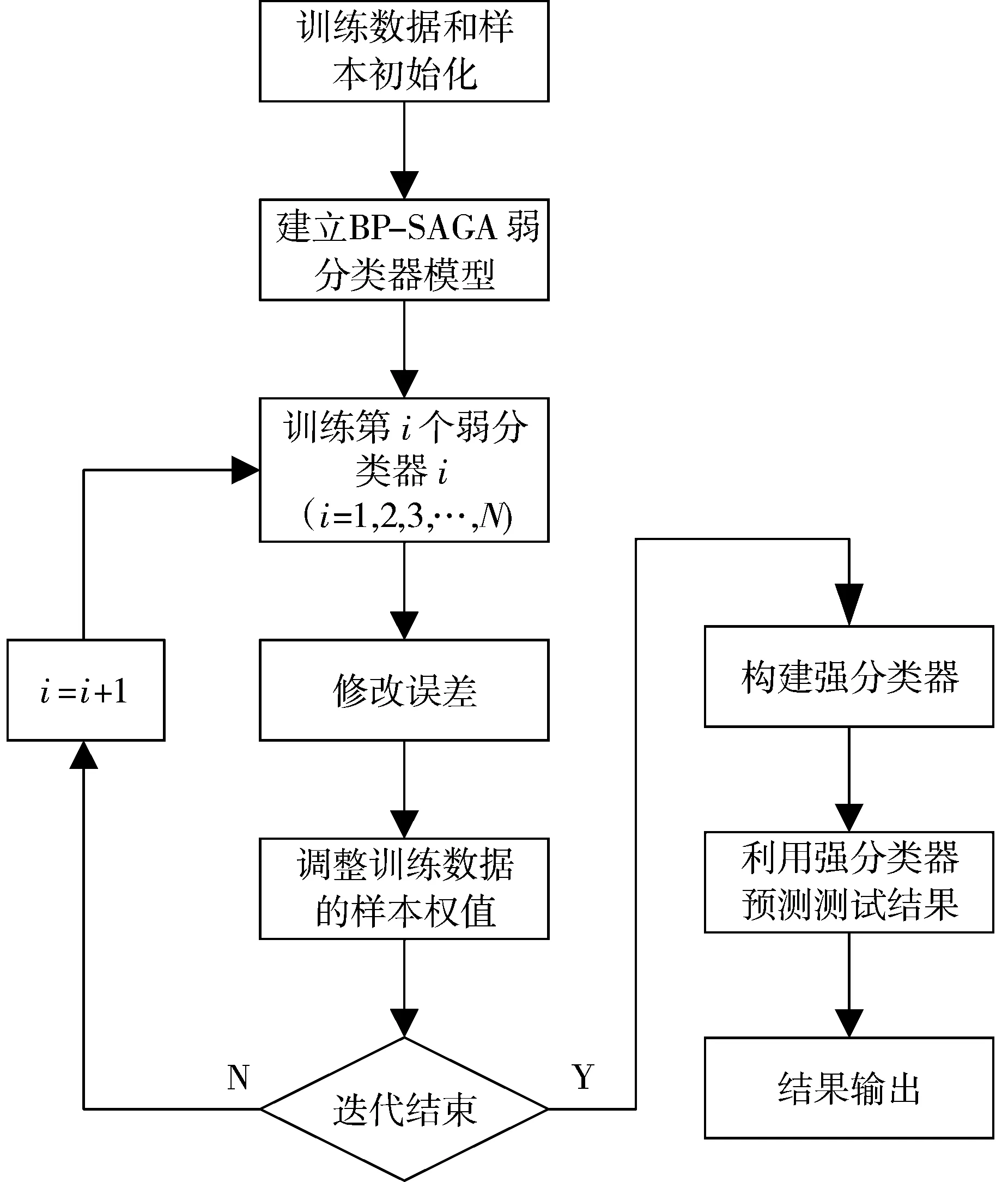
图4 BP-GamysBoost算法流程图
BP-GamysBoost算法流程如下:
1)从样本空间随机选择m组训练数据,初始化训练样本权重Dt(i),使得Dt(i)=1/m,根据样本输入输出维数确定神经网络结构,初始化BP神经网络的权值和阈值。
2)训练第t个弱分类器,用训练数据训练被遗传算法优化过的BP神经网络,并预测训练数据输出,得到预测序列g(t)的预测误差et,其计算公式为:
式中y为预期分类结果,g(t)为预测结果。
3)根据预测序列g(t)的预测误差et,调整下一轮训练数据的权重αt,权重计算公式为:
4)根据预测序列权重αt,对下一轮训练样本的权重进行调整,调整策略为:
IF(模型输出≠期望输出) and (期望输出为患病类别) THEN
IF (模型输出≠期望输出) and (期望输出为健康类别) THEN
ELSE
Dt+1(i)=Dt(i)
其中,Bi为归一化因子,i=1,2,…,m。
5)训练T轮后得到T组弱分类函数f(gt,αt),由T组弱分类函数组合构成强分类函数h(x):
4 实验分析
4.1 WBCD数据集描述
本文实验是基于UCI机器学习库的WBCD数据集进行研究的,该实验数据中共包括569个病例,其中显示非癌症的样本数量为357个,显示癌症的样本数量为212个,即良性357例,恶性212例。WBCD数据集中每个样本所包含的变量如表1所示。
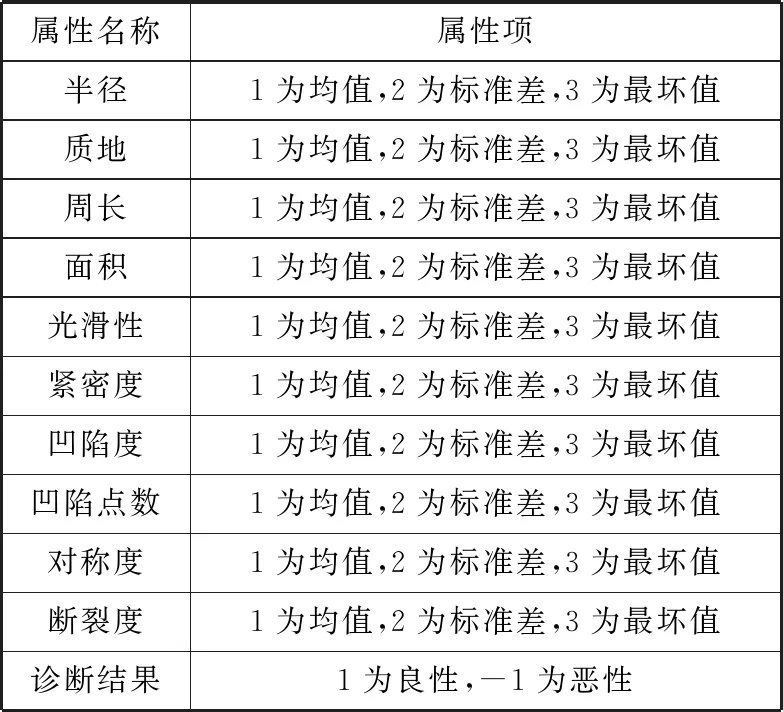
表1 WBCD数据集属性
4.2 评估指标
本文以模型的稳定性(Stability)、准确率(Accuracy)、漏诊率(MDR)、灵敏度(Sensitivity)、特异度(Specificity)和Youden值作为评价指标来检验该模型的有效性。稳定性主要是通过模型的标准差和100次实验的散点图来评估,另5个指标的计算公式如下:
其中TPR和TNR的计算基于混淆矩阵,如表2所示。对于以良/恶性乳腺癌肿瘤预测的二分类问题,可将样本根据其真实类别与机器学习预测类别的组合分为真阳性、假阳性、假阴性与真阴性4种情况。

表2 混淆矩阵
4.3 实验结果分析
本文为了消除随机性因素并反映结果的真实性,借助MATLAB平台,对WBCD数据集进行100次实验,选取实验结果的平均性能作为研究的最终结果。实验结果具体分析如下。
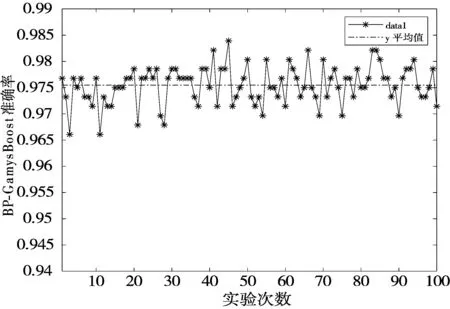
4.3.1 稳定性
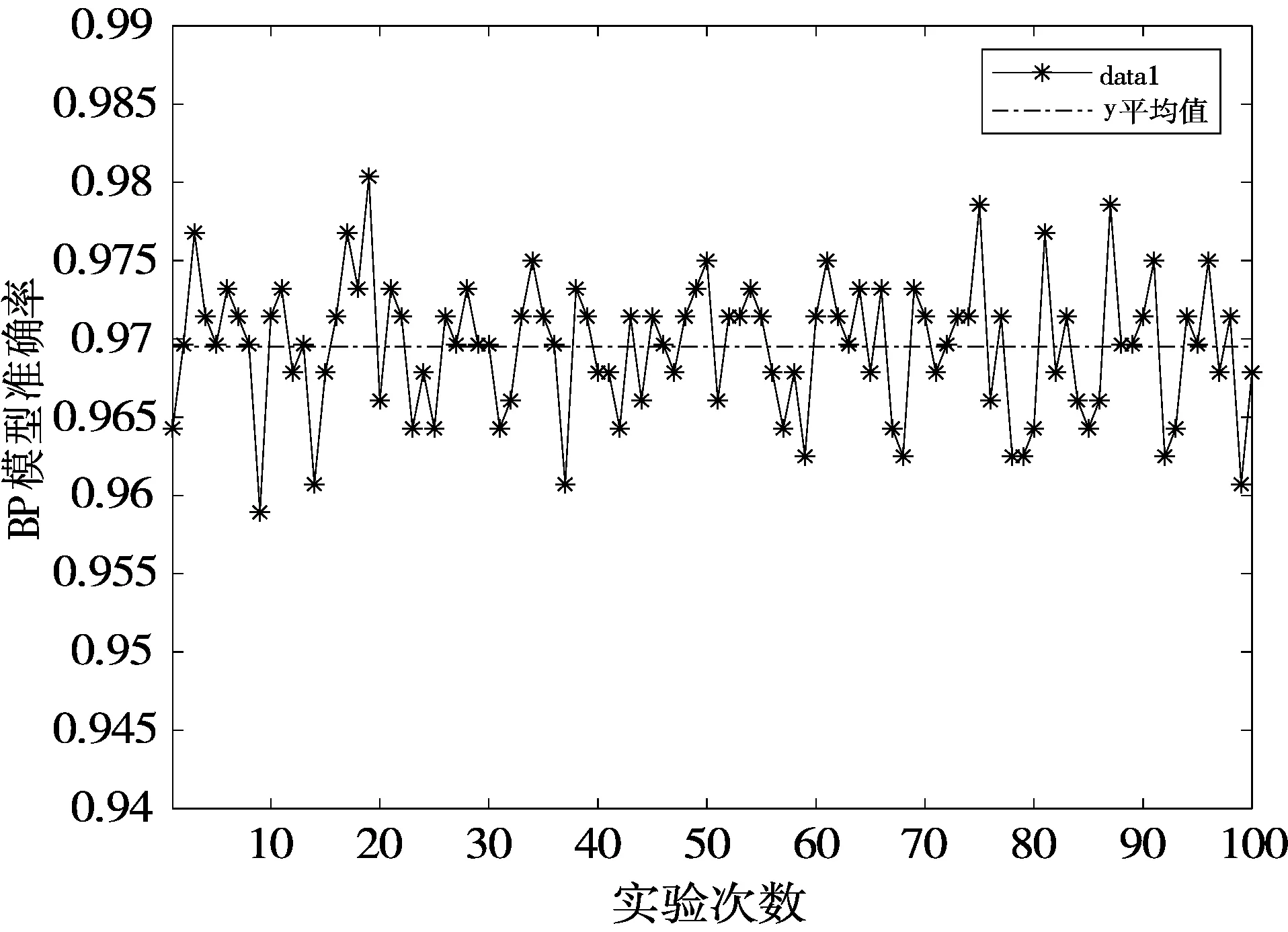
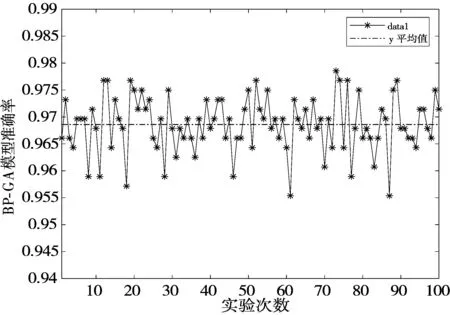
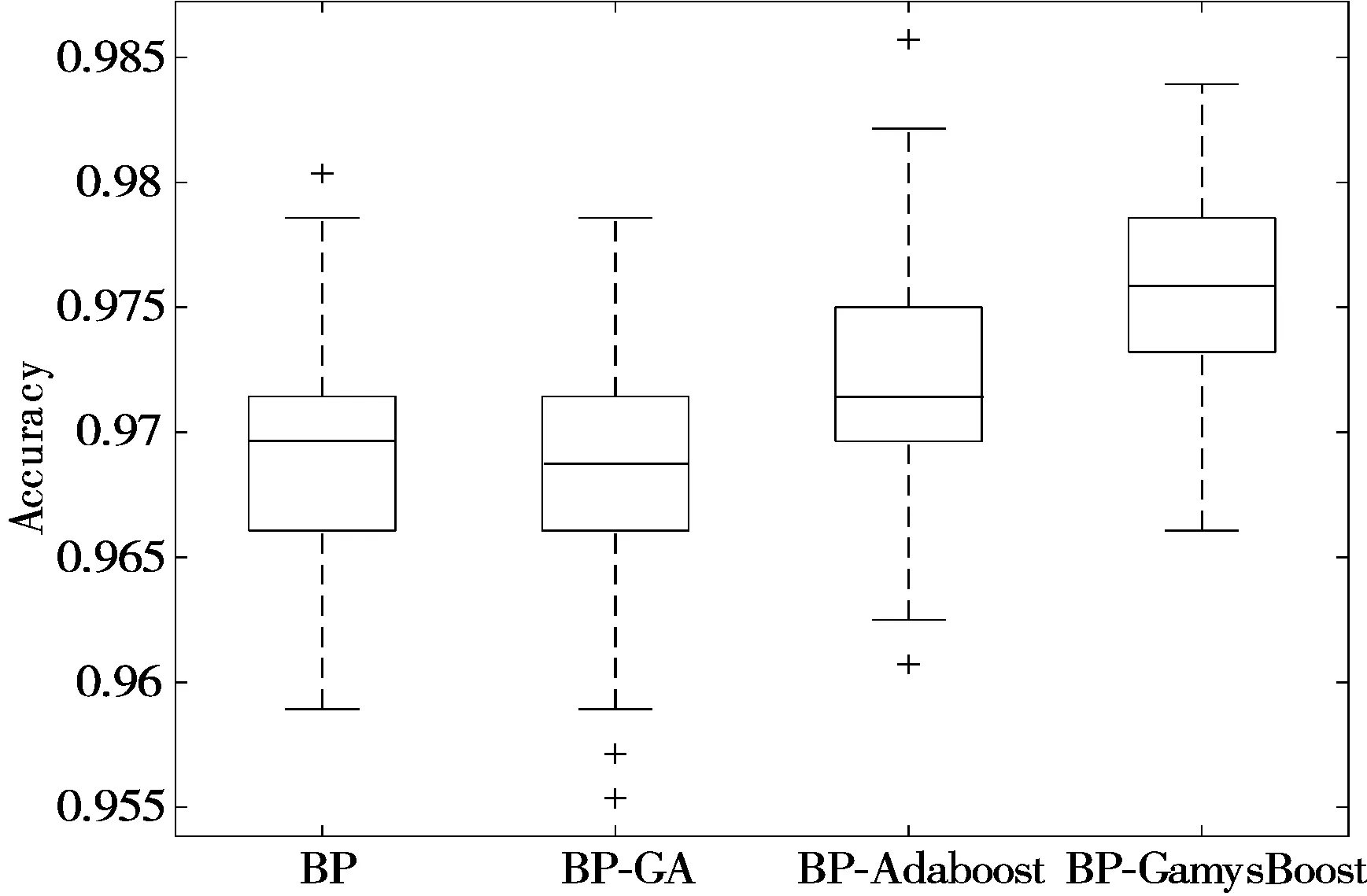
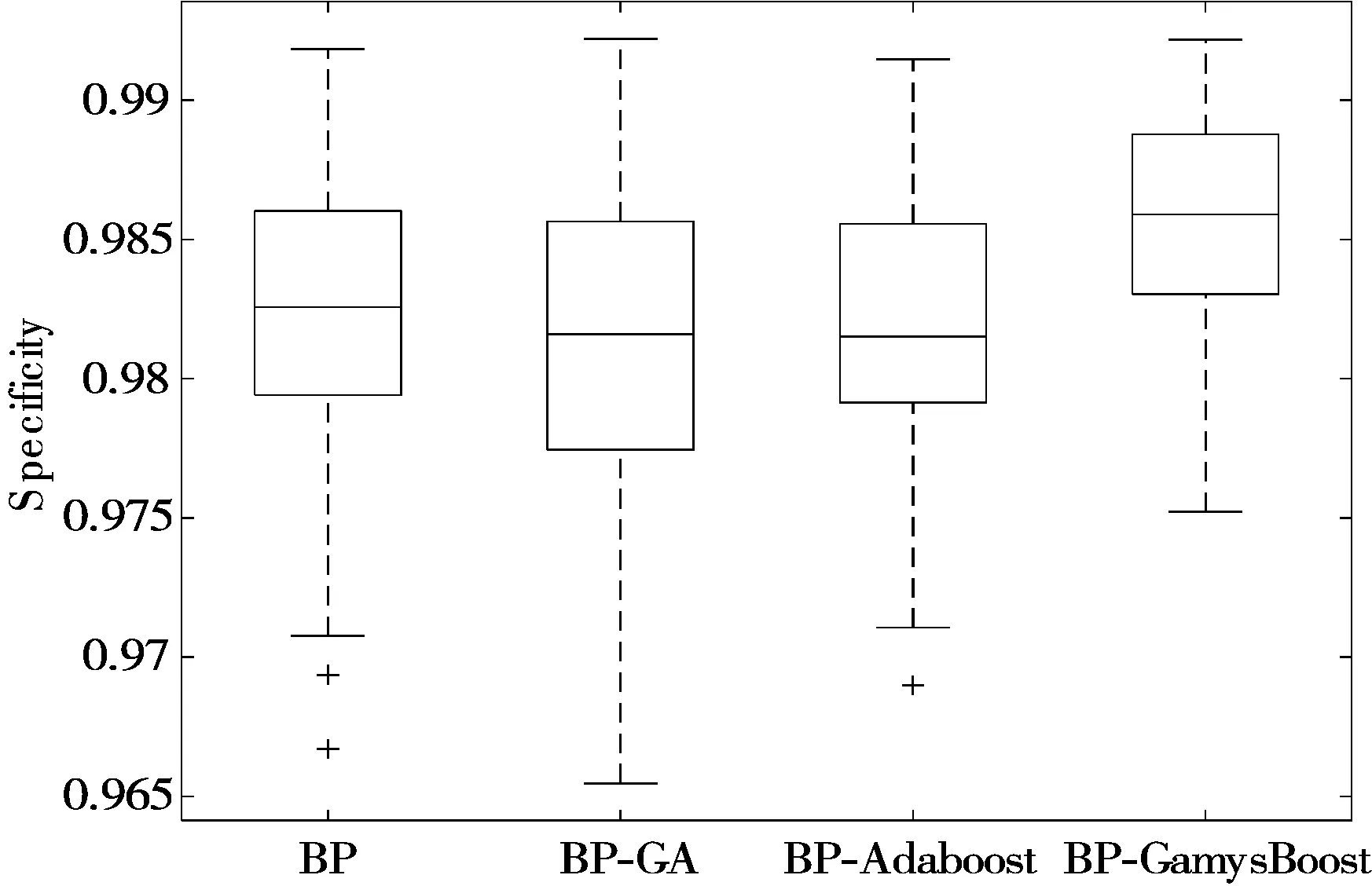
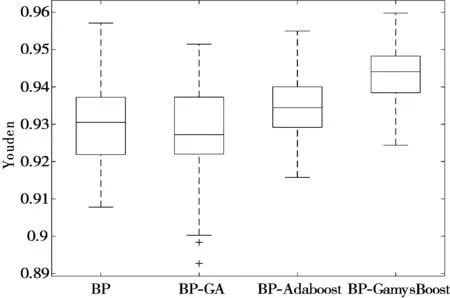
模型的稳定性又称为鲁棒性,它是决定模型是否可行的重要因素。由表3可知,4种模型的标准差大小顺序为:BP-GamysBoost 表3 4种模型标准差均值比较 (a) BP模型准确率 (b) BP-GA模型准确率 (c) BP-Adaboost模型准确率 (d) BP-GamysBoost模型准确率 4.3.2 准确率 在面对多种分类模型时,准确率是评价分类模型好坏的一个直观评价指标。由表4可以看出100次实验后4种分类模型准确率均值大小顺序为:BP-GamysBoost>BP-Adaboost>BP-GA>BP,其中BP-GamysBoost的准确率为0.9755,与BP-Adaboost分类模型0.9718的准确率相比,提升了0.38%。从图6中4种模型准确率盒图可以得出,BP-GamysBoost分类模型在100次实验中25%的准确率高于0.97857,50%的准确率集中在0.97321~0.97857区间,与其他3个模型中准确率较高的BP-Adaboost模型相比,BP-GamysBoost分类模型大部分的准确率明显地高于BP-Adaboost模型,且准确率更为集中,集中的区间也优于BP-Adaboost模型。此外,BP-Adaboost模型和BP-GA模型还存在低于BP-GamysBoost模型最小准确率0.96607的异常值。 表4 4种模型的准确率均值比较 图6 4种模型准确率盒图 4.3.3 其他评估指标 在医疗诊断过程中,因乳腺癌数据存在数据分布不平衡现象,故在这种情况下,通常适用的准确率可能无法很直观地反映该分类器的好坏,简言之,此时的高准确率可能无法代表分类器的高性能。例如假设某疾病的患病率为1%,那么对于一个不加思考的分类器,它可能达到99%的准确率,但当真正遇到该患病样本时,这个分类器可能毫无反应,所以即便该分类器准确率如此之高,却仍然不能满足人们的要求。故对不同分类模型,还需要从漏诊率、灵敏度、特异度和Youden指数进行评估。 由图7(a)模型漏诊率盒图可知,BP-GamysBoost分类模型的漏诊率最低,说明本文提出的分类模型很好地控制了假阳性率,在乳腺癌疾病诊断中,降低了遗漏一名潜在病人的风险,其价值远高于误诊一名正常人。由图7(b)~图7(d)所示盒图可以分析出,在4种分类模型中,BP-GamysBoost分类模型在灵敏度、特异度和Youden指数上都高于其他3种模型。如图7(b)和图7(c)所示,BP-GamysBoost分类模型有较好的灵敏度和特异度,说明该网络能更好地逼近函数。如图7(d)所示,4种模型Youden指数大小顺序为:BP-GamysBoost>BP-Adaboost>BP>BP-GA,BP-GamysBoost的中值为0.94408,BP-Adaboost的中值为0.93445,二者相差1.031%,说明本文提出的模型筛查实验的效果更好,真实性更高。 (a) 4种模型漏诊率盒图 (b) 4种模型灵敏度盒图 (c) 4种模型特异度盒图 (d) 4种模型Youden指数盒图 本文提出了一种新的乳腺癌智能诊断分类模型BP-GamysBoost,该模型在BP-Adaboost模型基础上改进,引入改进后的GA算法并进行SA-GA优化,在每次迭代中根据乳腺癌样本特点对权重进行改变,在保证准确率的情况下尽可能降低漏诊率。为了评估性能,引入了BP、BP-GA、BP-Adaboost这3个模型,通过稳定性、准确率、漏诊率、灵敏度、特异度和Youden值6个评价指标进行对比,实验结果表明本文提出的集成算法比其他方法具有更好的性能,在临床乳腺癌诊断系统的应用上,可以协助医生做出正确有效决策。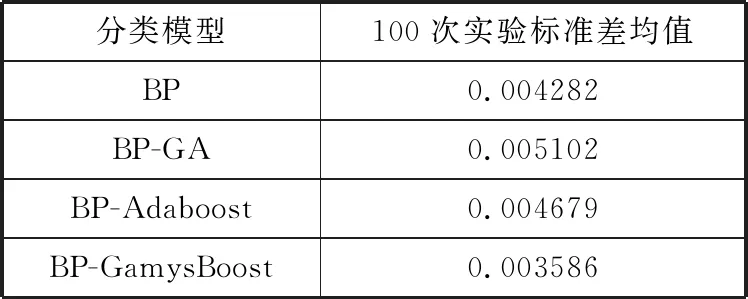




5 结束语
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子测试(2018年1期)2018-04-18 11:52:35
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
统计与决策(2017年2期)2017-03-20 15:25:24
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
