
一种法律判决预测的影响因素分析方法
2021-04-23 12:54:56李晓辉李常宝顾平莉吕守业
计算机与现代化 2021年4期
殷 敏,李晓辉,李常宝,顾平莉,张 可,吕守业
(1.华北计算技术研究所,北京 100083; 2.北京遥感信息研究所,北京 100011)
0 引 言
随着新兴科技的不断发展和进步,各个行业的数据量都在飞速增长,司法领域也不例外。当今社会作案手段变化多端,导致案件越来越复杂,同时刑侦手段也越来越完善,案件数据量也随之增加[1-2]。而案件复杂度的提升、数据的大量增长,也给司法工作带来了更多的挑战,法官在适应信息化带来的新变化过程中,也面临更多的困境[3]:一是案件日趋复杂,裁判结果难以把握和统一;二是案件相关资料繁多,对案件事实的梳理和校核难度较大。法律判决预测技术在一定程度上缓解了上述问题,是智能法律助理制度的一项关键技术。一方面,它为律师、法官等专业人员提供方便的参考,提高工作效率[4]。另一方面,它可以避免不同法官之间判罚尺度不统一导致的判决偏差,有效解决同案不同判、类似案件不类似处理的问题[5-6]。
法律判决预测[7]是指机器依据案件事实描述来预测判决结果的技术,是法律界特别是大陆法系最为关键的技术之一,因此几十年来一直受到人工智能研究者和法律界人士的广泛关注。法律判决预测的研究由来已久,早期的研究工作通常侧重于使用数学和统计算法分析特定场景中的现有法律案例。近年来随着人工智能技术的快速发展,利用自然语言处理等机器学习方法进行法律判决预测成为主要的研究方向。机器学习方法效果虽好,但其模型在预测结果解释方面没有较明确的体现。一方面,如深度神经网络或复杂的模型等,这种类型的方法通常具有较高的准确性,然而这些方法模型的内部原理和机制却难以理解,也无法得到特征对模型预测结果的影响力。另一方面,像线性回归和决策树之类的简单模型通常有更好的可解释性,但其预测能力通常是有限的,准确性较低。这就导致了现有的法律判决预测研究通常具有较高的准确性,而无法对预测结果的原因给出合理的解释说明,缺少决策的支撑依据。
针对上述问题,为解决法律判决预测中存在预测结果解释说理不足的问题,并为判决预测的结果提供一个可参考的影响因素分析,本文基于法律案件智能裁判,以预测结果影响因素为研究对象,利用自然语言处理、大数据等新兴科学技术,融合中文分词技术、支持向量机技术(SVM)[8-10]和解释预测统一框架(SHAP)[11],提出一种法律判决预测的影响因素分析方法。该方法从法律判决预测和判决结果的影响因素分析2个方面展开:首先根据输入的案件涉嫌事实,构建一个综合规范化的法律判决预测模型,实现对法律案件判决罪名的预测;其次是在法律判决预测模型的前提下,搭建法律判决预测模型的影响因素分析框架,对模型进行科学的分析处理,得到案件不同特征值对模型预测结果的影响力大小,从而为决策结果提供一个可解释说理的结论。
1 法律判决预测
1.1 数据集介绍
本文所用的数据集为“中国法研杯”司法人工智能挑战赛(CAIL2018)数据集[12]。CAIL2018收录了中国最高人民法院公布的260多万件刑事案件,与法律判决预测工作使用的其他数据集相比,CAIL2018的规模更大,数据量为其他数据集的数倍。此外,CAIL2018对判决结果的注释更加详细和丰富,每个案例都由事实描述和相应的判决结果2部分组成,判决结果包括适用的法律条款、罪名和刑期,这些都是根据案件的事实描述来推断的。CAIL2018可作为专业人员提高工作效率的参考,对法律智能系统的研究具有一定的参考价值。CAIL2018数据集中的一个实例如表1所示。
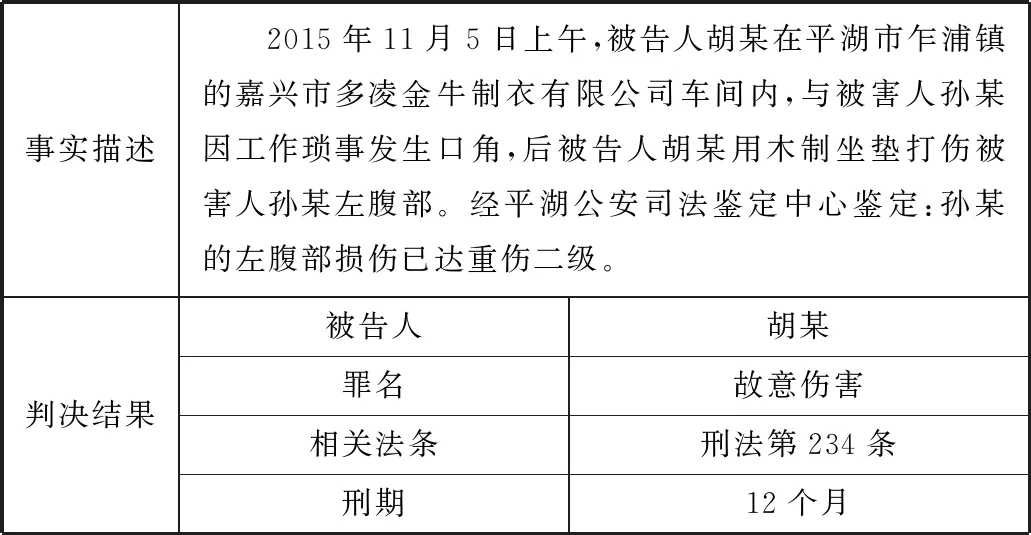
表1 CAIL2018的一个实例
1.2 数据预处理
数据预处理可以提高数据的质量,让数据适应模型,匹配模型的需求,从而有助于提高后续学习的精度和能力。本文以法律案件的事实描述为输入,首先对输入的一段文字描述进行分词,然后将得到的分词转化为词向量以便机器进行处理。
对文本的分词处理采用jieba工具[13],为提高分词的准确率,实验在分词过程中自定义了一个司法相关的词典。首先从CAIL2018数据集中获取案件事实描述的字段,对其进行清洗,剔除特殊字符。然后加载自定义的司法词典和jieba工具自带的词典生成Trie树,基于Trie树结构进行快速词图扫描,生成事实描述中汉字所有可能的成词结果所构成的有向无环图(DAG)。然后采用动态规划法查找最大概率路径,得到分词结果。对于不在词典中的词,则采用隐马尔可夫模型(HMM)进行新词发现。文本分词框架如图1所示。
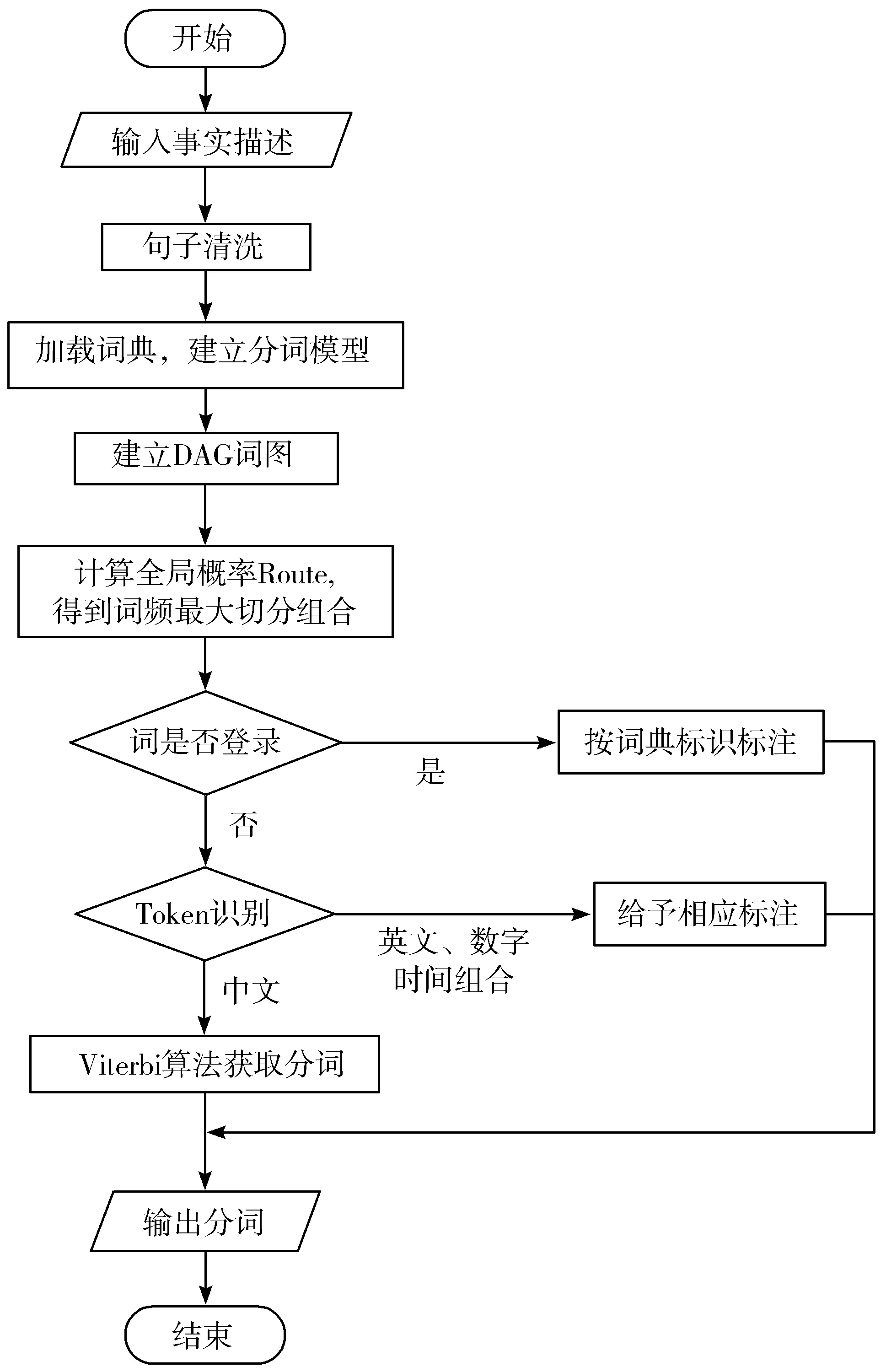
图1 文本分词框架
输入文本的分词完成后,本文采用词嵌入[14]的方法对分好的词进行词向量表示[15-16]。词向量将所有的词向量化,可以较好地表达不同词之间的相似和类比关系,越相似的词在向量空间上的夹角越小,这样词与词之间就可以定量地去度量它们之间的关系,以便接下来机器的处理。实验采用Word2vec工具来生成词向量,Word2vec工具中的模型为浅而双层的神经网络,用来训练以重新建构语言学的词文本。网络以词来表现,并且猜测相邻位置的输入词,在Word2vec中词袋模型假设下,词的顺序是不重要的。
训练完成之后,Word2vec模型可用来映射每个词到一个向量,可用来表示词与词之间的关系,该向量为神经网络的隐藏层。词量化表示过程如图2所示。
1.3 基于SVM的法律判决预测
完成数据预处理后,得到输入的案情描述相关的词向量,随后实验对得到的词向量进行机器学习,生成一个可解释的法律判决预测模型。
实验使用支持向量机(SVM)技术[8,17],对数据进行学习。SVM是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器。SVM的学习策略就是使间隔最大化,实质上就是求解凸二次规划的问题,也等同于最小化正则化的合页损失函数的问题。综合上述讨论内容,SVM的学习算法就是求解凸二次规划的最优化算法,支持向量机(SVM)的线性学习算法步骤如下:
图2 词向量框架
输入:训练模型所要的处理后的数据集T={(x1,y1),(x2,y2),…,(xN,yN)},其中,xi∈Rn,yi∈{+1,-1},i=1,2,…,N。
输出:分离超平面和分类决策函数。
1)选取适当的惩罚参数C>0,构造并求解凸二次规划问题:
(1)
其中,0≤αi≤C,i=1,2,…,N。
根据公式(1)得到最优解:
2)分类间隔计算:
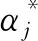
3)求分离超平面:
w*·x+b*=0
求分类决策函数:
f(x)=sign(w*·x+b*)
2 基于SHAP的影响因素分析
可解释机器学习在近几年慢慢成为了机器学习的重要研究方向。作为数据科学家需要防止模型存在偏见,且帮助决策者理解如何正确地使用模型。越是严苛的场景,越需要模型提供证明它们是如何运作且避免错误的证据[18]。在许多应用中,除了要求模型要达到一定的准确率,理解一个模型为什么会作出某种预测也十分重要。然而,现在大型数据集的高准确率往往是由结构复杂的黑盒模型实现的,得到的结果也难以解释,例如集成或深度学习模型,在准确性和可解释性之间形成了一种不平衡关系[19-21]。近几年,不少研究者提出了各种不同的方法来解决这个问题。但是,这些方法大都缺乏所需属性,无法良好地运用于法律判决预测影响因素分析。针对这个问题,有研究者提出了一个解释预测统一框架SHAP,为每个特征指定一个特定预测的重要值[22],该值可在模型输出结果的基础上对结果进行影响因素分析,在一定程度上增强模型的解释说明能力。
上文中实验得到的法律判决预测模型,其模型就存在黑盒特性,无法对其为什么输出该预测结果进行合理的说明。针对现有法律判决预测过程中普遍存在预测结果说理不足等问题[23-24],本文借鉴SHAP框架的方法,将其运用于法律判决预测,在基于SVM法律判决预测模型的基础上,对每个法律案件的预测结果进行影响因素分析,将影响预测结果的重要特征进行抽取,在一定程度上解决了该领域一直以来的黑盒性问题[25],为法律工作者提供一个有效的参考依据。
关于模型的解释性,对于复杂模型,如集成方法或深度网络,因为它不容易理解,因此不能使用原始模型作为自己的最佳解释。相反,必须使用一个更简单的解释模型,即原始模型的任何可解释的近似模型来给出合理的结果解释。SHAP实际上是用Python开发的一个“模型解释”包,可以解释任何机器学习模型的输出结果,它是在合作博弈论的启发下构建的一个近似的解释模型,使用博弈论中的经典Shapley值及其相关扩展将最佳信用分配与本地解释联系起来。对于每一个数据样本,SHAP模型都产生一个预测值(SHAP value)来反映该样本中每个特征的影响力。
假设第i个样本为xi,第i个样本的第j个特征为xij,模型对该样本的预测值为yi,整个模型的基线(通常是所有样本的目标变量的均值)为ybase,那么SHAP value服从以下等式:
yi=ybase+f(xi1)+f(xi2)+…+f(xik)
其中f(xij)为xij的SHAP值。直观上看,f(xi,1)就是第i个样本中第1个特征对最终预测值yi的贡献值,当f(xi,1)>0,说明该特征提升了预测值,有正向作用;反之,说明该特征使得预测值降低,有反作用。
传统的feature importance只告诉哪个特征重要,但人们并不清楚该特征是怎样影响预测结果的。SHAP value最大的优势是SHAP不仅能反映出每一个样本中的特征的影响力,而且还表现出影响的正负性。将其运用到法律判决预测中,则能体现出案件描述中哪些因素在预测中起到决定性的正向作用,从而得出该预测结果是有依据且可靠的,在一定程度上对结果做了解释说明。
3 实验结果与分析
在本章中,将法律判决预测模型与基线的性能进行比较,并对模型的输出预测结果提供影响因素的分析结果。本文使用3种度量标准来评估基线模型,包括在分类任务中广泛使用的准确度(Acc)、宏精度(MP)和宏召回(MR)。为了评估模型的性能,本文将法律判决预测模型与以下3种经典的文本分类方法进行比较:FastText、CNN、LSTM。实验结果对比如表2所示。在法律判决预测的基础上,本文还对模型预测结果的重要影响因素进行了科学的分析,通过将复杂模型拟合为简化的近似模型对预测结果的影响因素进行分析,输出了样本中影响力较大特征,某一样例的影响因素分析结果如图3所示。
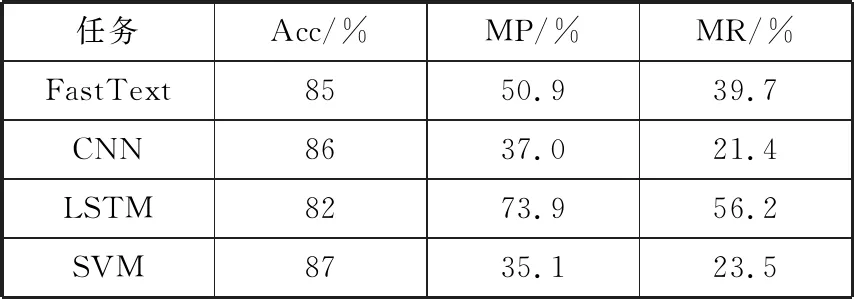
表2 实验结果对比
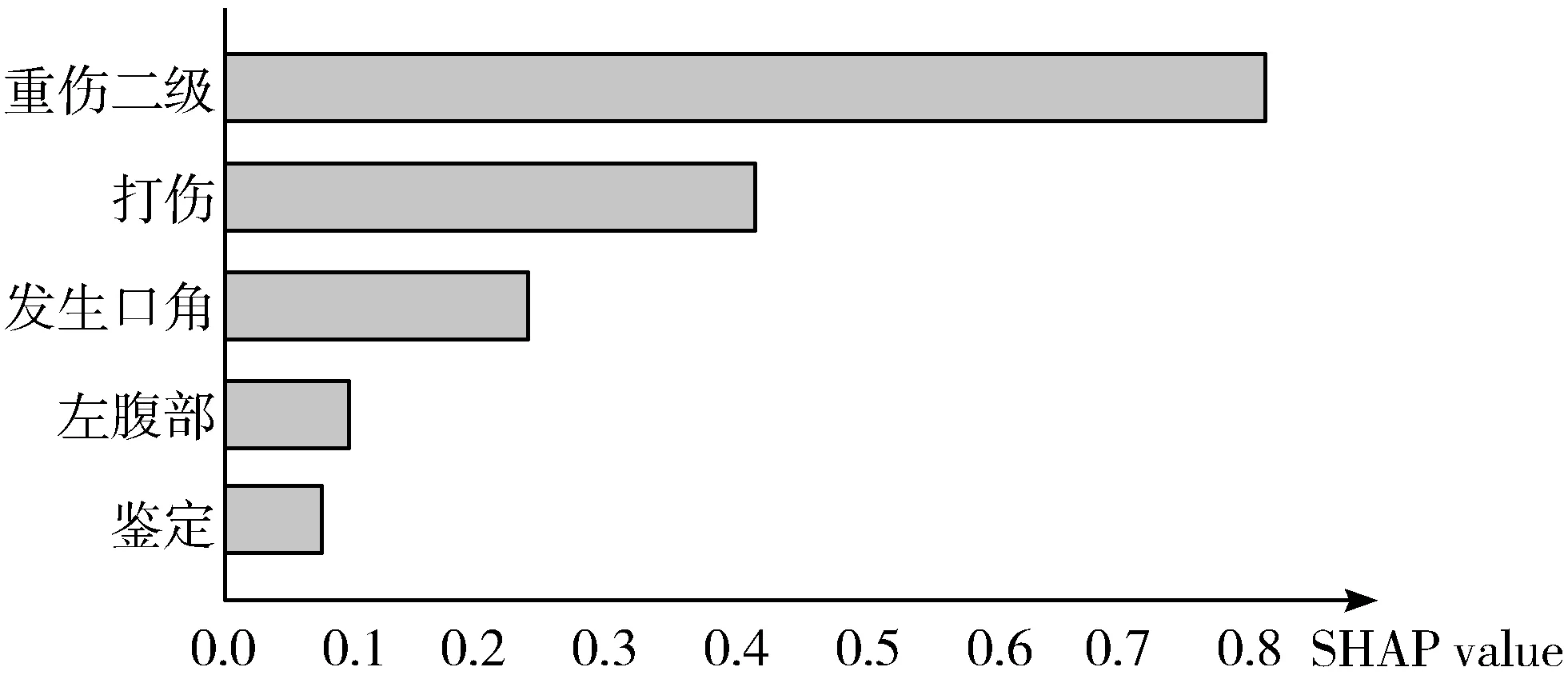
图3 影响因素样例
实验结果表明:在现有的数据集上,本文的模型在准确率的性能上明显优于其他基线,它表明了本文所提出的方法的有效性和健壮性。与传统的分类任务模型相比,本文的方法更重视数据预处理,使数据更加适应模型的需求,并充分利用SVM良好的学习能力和较低的泛化错误率,在基线的基础上实现了很好的改进。此外,本文的方法对模型的预测结果进行了科学的影响因素分析,使样本中每个特征所分配到的SHAP value值,能反映出每一个样本中特征的影响力情况,为模型的决策提供支撑依据。根据以往法律判决预测中普遍存在的模型内部原理和机制难以理解,导致无法得到特征对模型预测结果的影响力的情况,本文提出的法律判决预测的影响因素分析方法可以有效地解决模型黑盒效应,从而针对法律判决预测结果给出相应的影响因素分析结果,在一定程度上对预测结果进行解释说理,有效地为执法人员在处理案件时提供了决策依据。
4 结束语
本文首先对法律判决预测技术的历史背景与现状进行了研究分析,针对现有技术现状下法律判决预测结果影响因素说理不足的问题,提出了一种法律判决预测的影响因素分析方法。法律判决预测的影响因素分析方法重点实现法律判决预测技术和预测结果影响因素分析2项关键技术。首先,对输入的法律事实描述通过分词与词向量表示进行数据预处理。然后基于支持向量机技术进行模型构建,依据案件事实描述实现法律判决预测。最后,采取解释预测统一框架SHAP对模型进行科学拟合分析,根据SHAP value值的大小得到对结果影响力较大的特征,为决策提供解释说理的依据。实验结果表明,法律判决预测的影响因素分析方法可以有效地对法律判决预测结果的影响因素进行科学的分析,通过特征值的影响力大小反映预测结果的可解释性。下一步工作,将从2个方面展开:一方面进一步提高法律判决预测的准确性,另一方面对案件的罪名、法律条款和刑期进行多任务学习预测[26-27]。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
水上消防(2021年4期)2021-11-05 08:51:36
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
学生天地(2020年2期)2020-08-25 09:03:04
智富时代(2019年6期)2019-07-24 10:33:16
高中生·天天向上(2016年9期)2016-11-22 09:10:34
中国交通信息化(2016年10期)2016-06-08 06:07:18
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
中国卫生(2015年9期)2015-11-10 03:11:24
