
一种新的高效轻量级卷积神经网络模型
2021-04-23 02:09:58张舰舰
计算机与现代化 2021年4期
张舰舰
(杭州电子科技大学计算机学院,浙江 杭州 310018)
0 引 言
肥胖是许多国家人们的健康问题之一,也是许多疾病的诱因。计算卡路里摄入量是对抗肥胖的解决方案之一。传统的饮食记录方法由于非常需要人与人之间的互动,因此不够准确。需要一个自动识别系统,该系统能够准确估算用户的卡路里摄入量。当前,智能手机能够跟踪膳食并估算其卡路里。
和其他物体一样,食物也有不同的特征,例如形状、颜色和质地。通常从食物图像中提取手工制作的特征,例如颜色直方图、定向梯度直方图(HOG)、尺度不变特征变换(SIFT)、局部二值模式(LBP)、Gabor滤波器和特征包(BoF),然后将它们输入线性或非线性分类器中,以确定食物的类别。手工制作的描述符表示能力有限。因此无法在特征空间中正确区分食物,因为不同类别的特征可能会相互重叠。所以人们需要一个能够充分表达其特征的描述符,来学习食品的最重要和最有区别的特征。最近卷积神经网络在ImageNet数据集上取得了令人印象深刻的结果。一个卷积神经网络通常由几个卷积和池化层组成,这使其比手工制作的方法具有更大的表示能力。从另一个角度看,卷积网络的卷积和池化层学习了用于分类的区分特征。
在ImageNet数据集上表现令人印象深刻的那些大型卷积神经网络模型,都需要大量的内存。但是食品识别系统通常在微机(有限的内存)上运行。内存需求少、计算成本低的卷积神经网络模型将更适合像智能手机这样的微机。而经典网络AlexNet[1]、GoogLeNet[2]、ResNet[3]和VGGNet[4]分别具有57M、6M、24M和138M这样较大的参数量。
1 相关研究
Kong等[5]开发了一个名为DietCam的应用程序,该应用程序使用食物图像的多个视图来识别食物的类型。它从多个角度(每个食物6个角度)评估食物摄入量。另外,他们根据形状将食物分为规则形状和不规则形状2类。第1类食品具有一定的形状,例如水果、汉堡包和比萨饼。第2类食品具有可变形的形状,例如面条、面食和沙拉。在这项工作中,他们提出了规则形状食品的算法,利用高斯区域检测器和SIFT作为描述符。Kawano等[6]提出了一种移动食品识别系统,该系统首先要求用户绘制边界框使用GrubCut分割食物区域。然后用子窗口搜索(ESS)来估计食物区域的预期方向。最后提取颜色直方图和基于SURF的特征包,并使用χ2核的线性支持向量机对食物分类。
另外,Anthimopoulos等[7]使用BoF方法对11种食物分类。具体来说,他们使用分层次的k-均值聚类建立10000个Visual Words,并使用BoF方法表示食物。然后使用线性支持向量机对食物进行分类。并且他们的食物识别系统可估计糖尿病患者膳食中的碳水化合物含量。
Anthimopoulos等[8]开发了一种系统,该系统使用金字塔均值漂移滤波和区域增长算法对食物区域进行分割。然后通过颜色直方图和局部二值模式对分割后的区域进行描述,最后使用SVM将图像分类为6大类。
Matsuda等[9]提出了一种利用多种排序法的食品统计量来识别多种食品的方法。首先使用DPM(Deformable Part Models)、圆形检测器和JSEG区域分割方法对候选区域进行检测。然后使用HOG、SIFT、CSIFT、颜色直方图和Gabor滤波器提取候选区域的特征。最后用MKL-SVM对100种食物进行分类。
He等[10]提出了DietCam方法,该方法包括成分检测和食品分类。利用可变形零件模型和纹理验证模型的组合来检测食品成分,然后用多核支持向量机进行分类。与其他传统方法一样,Duan等[11]利用SIFT和Gabor描述符作为食物图像特征,并使用k-均值进行特征聚类,还使用云计算来提高食品识别的性能。
Zhang等[12]提出了一个由5个卷积池层组成的网络。在收集的水果数据集和UECFood-100数据集上分别达到了80.8%和60.9%的准确性。Wang等[13]提出了一种基于UPMC Food-100数据集上的食品配方自动识别系统。用BoW和OverFeat特征提取器提取视觉特征。然后使用TF-IDF来实现文本功能。最后融合视觉和纹理特征后输入到SVM分类器。
同样,Kawano等[14]提出了一种可以实时识别30种食品成分的系统,可以推荐与所识别成分相关的食谱。在这项研究中,使用BoF和颜色直方图作为描述符,并使用线性核SVM作为分类器来识别食品成分。从不同的角度来看,Xu等[15]利用地理位置以及餐厅的外部信息来进行食物识别,使用上下文信息,例如食材、烹饪方式和餐厅特定的菜肴。
Simonyan等[4]提出了一个非常深的网络,它由19层组成,只有3×3的卷积滤波器。结果表明,通过增加网络深度,可以显著提高性能。Hassannejad等[16]将Inception模块中3×3的卷积核变成了一个1×3和一个3×1的卷积核,这样做能大大降低参数的个数,对计算性能的要求大大降低,从而提高训练的效率,使其更加接近移动系统的要求。
2 网络结构
Sermanet等[17]表明将卷积神经网络中间层生成的特征图连接到分类阶段可以作为更高级的特征并能提高准确性。Maas等[18]提出的LReLU激活函数与标准ReLU功能不同,并且使用LReLU激活函数的网络与常规ReLU激活函数相比,准确率有所提高。He等[19]提出了一种新的激活函数,称为参数整流线性单元(PReLU),该函数在不增加额外计算成本的情况下提高了分类精度。为了处理任意大小的图像,He等[20]提出了空间金字塔池化(SPP),其中网络中的最后一个特征图被分为1、4、16等多个区域。然后将特征串联起来形成特征向量,并将它们输入分类层,这些SPP层可以提高所提出网络的性能。
即使使用ReLU、LReLU、PReLU等激活函数训练非常深的网络仍然很耗时。Ioffe等[21]表明,由于训练阶段需要较小的学习率和更适合的初始化参数,因此每一层分布的变化都会增加训练时间,这种现象称为内部协变量偏移问题。他们通过归一化每一层的输出和线性缩放以及改变归一化的输出来解决该问题,就像ResNet网络体系结构中需要用大量批处理规范化来训练较深的网络。Clevert等[22]提出了指数线性(ELU)激活函数,实验表明此激活函数可显著提高训练速度。
基于以上分析,本文提出一种卷积神经网络模型,如图1所示。虽然提出的网络较深,但网络是由一些相似的Block块控制的,即由一些基本的构造块组成,其中每个块由具有不同感受野的卷积层和池化层组成。第1个基本块由3个卷积层,分别为7×7、5×5和3×3大小的卷积核组成。这些卷积层的特征图通过通道连接起来。然后将连接后的特征输入卷积核大小为1×1的卷积层。该卷积层的作用是将特征在同一空间位置进行非线性组合。
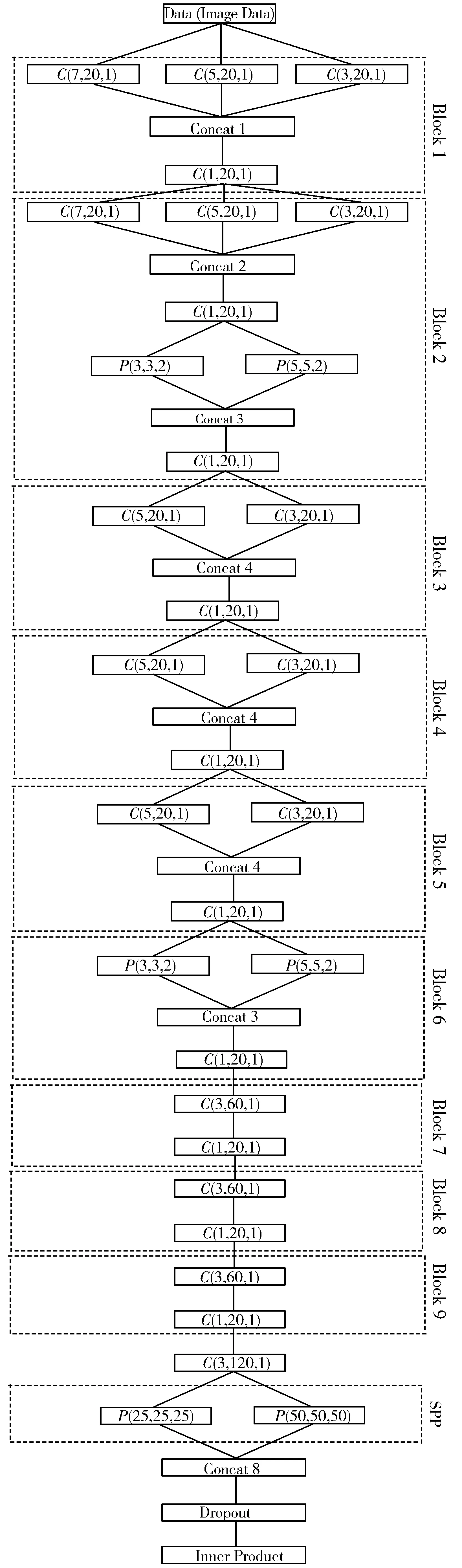
C(s,n,d)表示该卷积层包含n个大小为s×s、步长为d的卷积核,P(s,s,d)表示一个s×s步长为d的最大池化层
通过每一个Block块末尾的1×1卷积核使特征维度保持不变,从而来控制网络的复杂性。与第1个块相似,第2个基本块由3个卷积层和1个1×1的卷积层组成,还有5×5和3×3感受野的池化层,然后将它们进行特征维数叠加,再利用1×1的卷积核对特征进行非线性组合。
接着后面衔接3个基本构建块,其中每个块中有一个5×5和一个3×3卷积核大小的卷积层。像Block2一样,Block6同样有3×3和5×5大小的感受野的池化层和1×1的卷积层。接下来连接3个同样有3×3和1×1卷积核的Block。
最后一个卷积层(3×3)生成的特征被传递到空间金字塔池化层中。在空间金字塔池化层中,特征图将分别用4×4和1×1的网格去划分成1个区域和4个区域,然后每个区域再进行全局池化,分别生成了1×120和4×120的特征图。最后将SPP特征连接到分类器中。此外在每个卷积层后都使用了ELU激活函数。在完全连接层之前还使用一个Dropout层,用于调整网络。为了减少模型的大小和计算成本,本文网络中没有使用BN和ReLU的组合层。
ELU能提高训练速度,类似于BN层,使用BN层后训练速度的提高可以忽略不计,所以本文网络中丢弃了BN层,在一定程度上可以减少训练时间和计算成本。因此使用ELU网络能够缩短运行时间。
在同一个特征图上,本文使用2个具有不同感受野的池化层,并使用1×1卷积核将它们非线性组合起来,以减小网络的宽度。尽管2个池化层(在相同深度)的感受野区别不大,但它们被特征映射激活的方式有明显的区别。
如图2所示,这2个池化层在同一个特征上的相同位置将会激活不同的感受野,其中pooli-y(c,m,n)表示第i层中卷积核大小为y、在第c个特征(m,n)位置上的池化。

图2 不同感受野在同一个位置上的作用效果
3 实验结果与分析
目前存在各种各样的食物,食物类别的数量巨大,没有一个大型公开的食物数据集可以涵盖所有食物类别。本文选取公共数据集Food-101[23]作为实验数据。
Food-101数据集包含101类食物,每种食物都包含1000个样本,如图3所示。本文将数据集随机分成训练集、验证集和测试集。这3组的比例分别为65%、10%和25%。其中每个类包含650个训练样本、100个验证样本和250个测试样本,并且每个图像都进行了标准化处理。
图3 Food-101数据集
3.1 图像预处理
为了提高模型的鲁棒性和减少过拟合的现象,本文对训练数据集进行如下变换:
1)图像随机扰动。
3)HSV处理。通过将图像转换成HSV颜色空间并将饱和度分量按0.9和1.1的因子缩放来修改图像的饱和度。在另一个转换中,值分量按因子0.7缩放。
4)PCA。首先计算训练数据像素的主成分P∈R3×3矩阵。然后将输入图像的像素投影到主分量中以获得系数向量b。接下来,在范围[0,0.5]内随机生成3×1向量v,并且使用新的系数向量b′=b-bΘv,通过将像素反向投影到RGB颜色空间来重构图像,其中Θ是一个元素级乘法运算符。
5)通过直方图均衡化变换和图像锐化来进一步增强数据集。
3.2 网络的训练
设置本文网络训练参数momentum为0.9,mini-batch为20后开始训练。
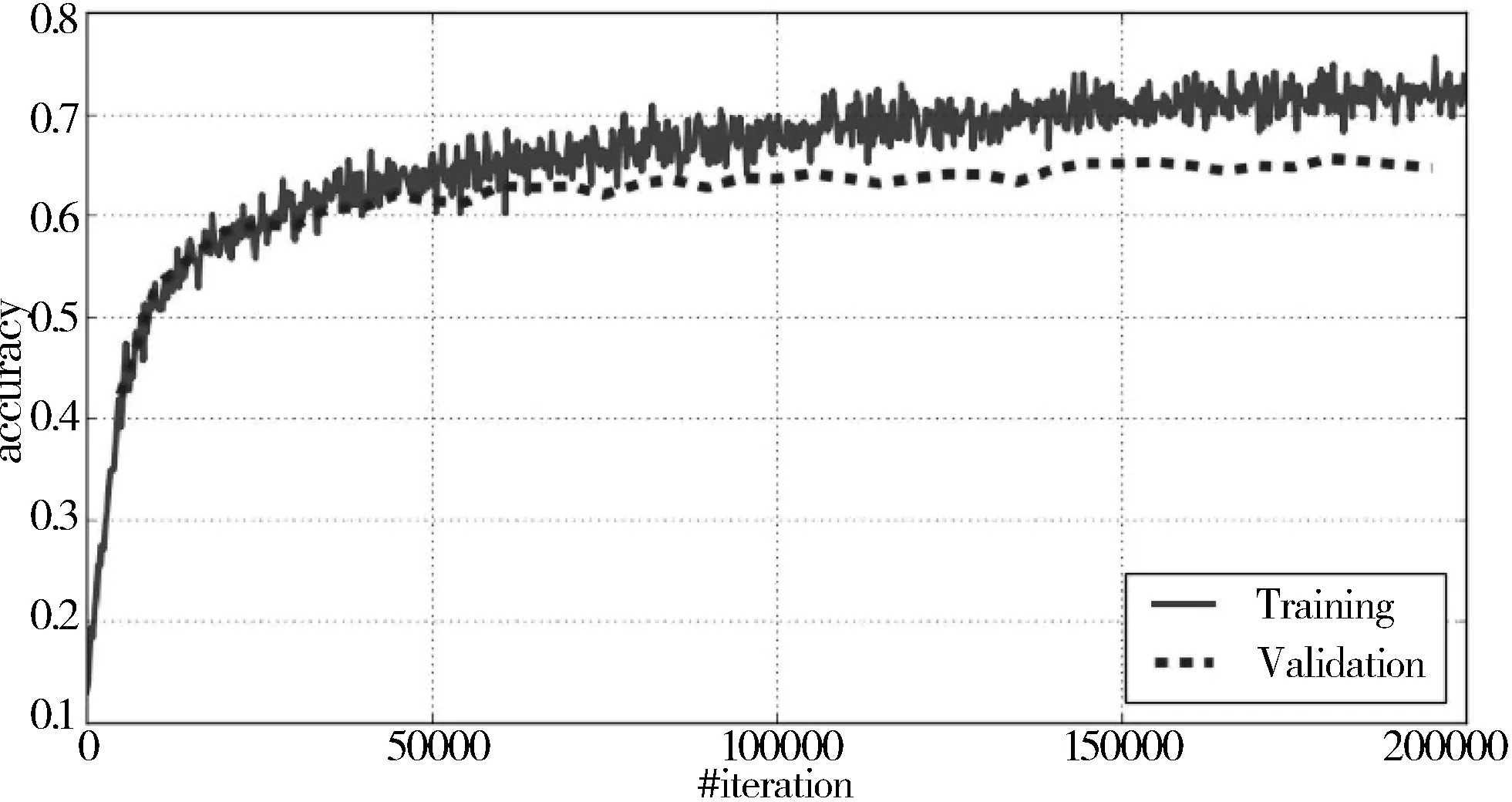
图4 网络训练
如图4所示,经过50k次左右的迭代后,网络开始呈现过拟合现象,但是验证曲线仍在上升。因此继续训练迭代到200k次,最终训练精度在71%左右,验证精度在64%左右。
3.3 与其他方法的比较
在过去的几年里,AlexNet、GoogLeNet、VGGNet和ResNet50在ImageNet大规模计算机视觉识别挑战中取得了令人瞩目的成绩。因为它们在大型数据集(像ImageNet)上训练过,模型已经基本学习到了图像的纹理、形状和外观等特征。因此可以经过微调使它们迁移到本文的食物图像分类实验中。
Dosovitskiy等[25]以及Mahendran等[26]研究表明,例如在网络的最后一层,神经网络倾向于学习更抽象的特征。相反,神经网络的第一层则主要提取边缘和颜色斑点等低级特征。ImageNet数据集中的图像,低级特征的差别可能并不大,而高级特性可能会有明显不同。
①切实有效的贯彻落实落实预检分诊制度:相关的医院要更加明确的设立相关的预检分诊室,该分诊室要有专业的护理人员进行专门值班,一旦有家属陪伴患儿来到医院进行就诊时,护理人员首先要对于他们进行简洁明快的有针对性评估,从整体上观察其是否有出疹、发热等一系列相应现象,特别是要密切观察3岁以下的孩子,如果出现了疑似的病例,要在第一时间及时有效的上报到上级的科室,并有效的把他们引导到相关的隔离区进行候诊准备;
本文使用预训练的AlexNet、GoogLeNet、VGGNet和ResNet50这4个网络作为比对方法,并且用3种微调方式来进行实验:1)冻结网络中除分类层以外的所有层来训练网络,即训练过程只更新分类层中的参数,其他网络参数保持不变;2)分类层及其前一层在训练过程中更新其参数,这样网络可以在食物图像中提取到高级特征;3)更新分类层及其前2层中的参数,这样网络可以更好地提取食物图像中更加高级的特征。
实验结果如表1所示,根据实验对比,更新最后3层时,可以获得最佳结果。因为当从最后第3层开始更新其参数时,网络能够更好地学习食物图像中的特征。
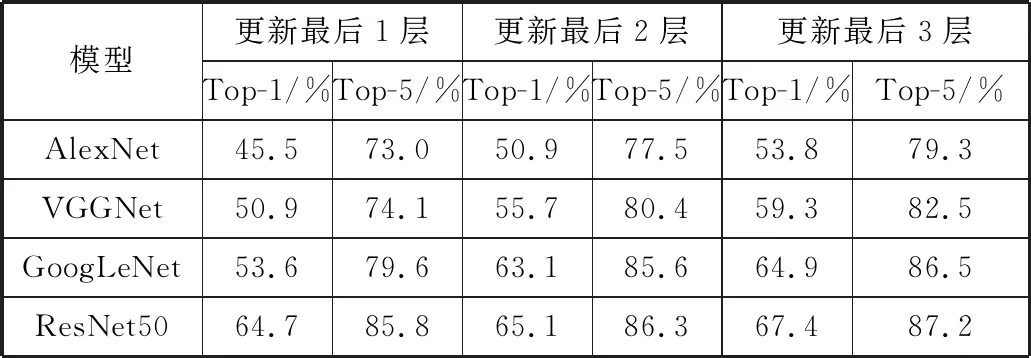
表1 3种微调方式的实验结果比较
如表2所示,本文还额外加入了非预训练的ResNet32网络,并在测试集上评估了ResNet32和本文网络。本文模型的性能要优于所有其他网络模型,其准确性接近于最佳表现的ResNet50模型,并且从参数量上来说,本文网络使用的参数减少了99.14%,而非预训练的ResNet32的准确性却低于本文网络模型。与GoogLeNet相比,本文网络模型结果更加精确,网络参数减少了96.6%左右。
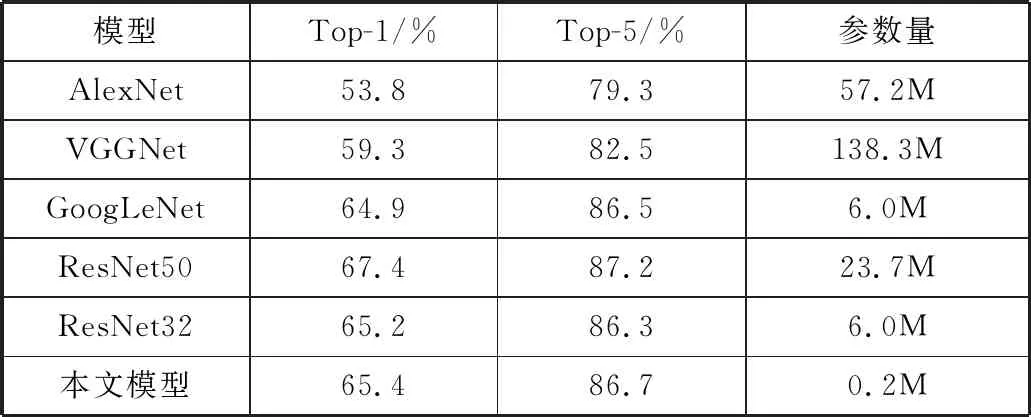
表2 与其他方法的比较
如图5所示,更加直观地给出了各个网络模型的准确率与其参数量之间的关系。
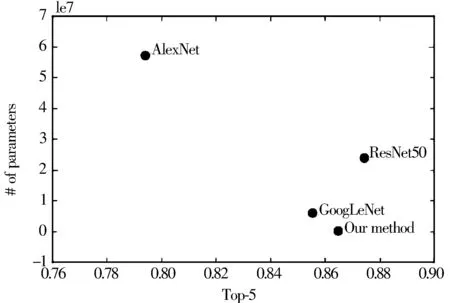
图5 准确率与参数量
如图6所示为Top-k的准确率,从图中可以清楚地看到,当k的值增加时,本文网络模型将趋向于ResNet50的精度,但是它比ResNet50的参数量更少。
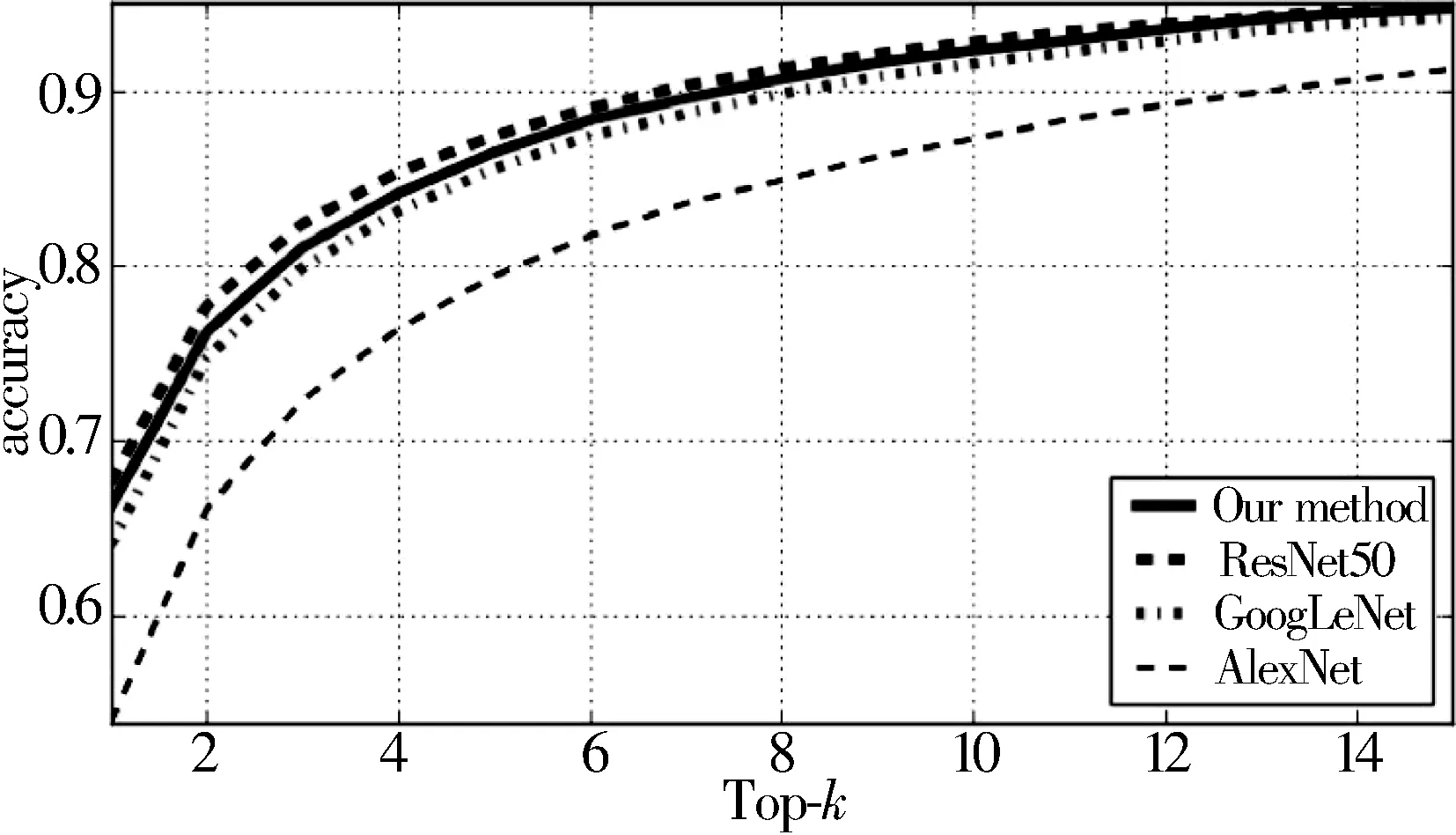
图6 Top-k精度
如图7所示,通过计算每个类的F1分数对分类结果进行更加详细的研究。从图中可以看出,有4个类的F1分数均大于0.8。F1分数在(0.6,0.8]和(0.4,0.6]之间的分别有47个类和41个类。在101个类中,有9个类的F1分数在[0.2,0.4]之间。
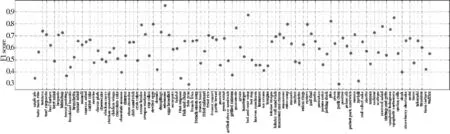
图7 F1分数
3.4 其他数据集上的比较
本文网络模型还在UECFood-256[27]数据集上进行了实验,并且与其他网络模型进行比较。
如表3所示,由在UECFood-256数据集上的实验结果可知,本文网络模型位于GoogLeNet和ResNet50之后,Top-1精度比它们低了1%和2%,Top-5精度低了1%。但是本文网络模型却比它们大大简化,具有一定的竞争力。
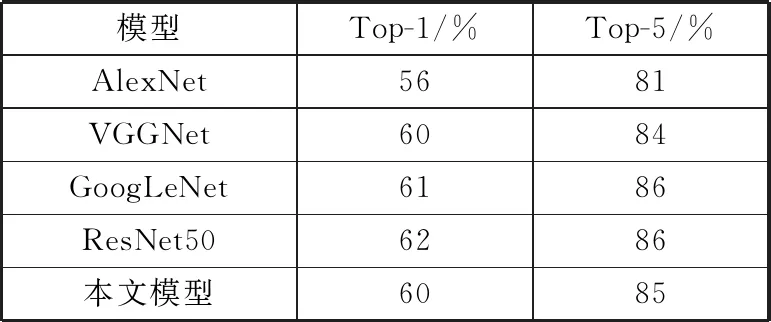
表3 实验结果
4 结束语
本文提出了一种新的高效轻量级网络模型结构,它包含32个卷积层和池化层以及一个完全连接层,这些层共同组成了一个深度为23的网络。网络由3个池化层块组成。前2个块中的每一个都包含2个具有不同感受野的池化层。第3个池化层是空间金字塔池化层,其中使用不同的感受野和步长将相同的特征汇集2次。在同一个特征图的同一个位置中,使用不同感受野的池化层池化,其神经元会受到不同程度的激活。与AlexNet、GoogLeNet和VGGNet相比,本文网络具有更准确的结果,与ResNet50相比准确率差不多。深度比AlexNet和VGGNet更深,但却拥有更少的参数量和更复杂的结构。但是比GoogLeNet和ResNet50更浅,没有这2个模型那么复杂。
与ResNet50和GoogLeNet相比,本文网络参数分别减少了99.14%和96.63%,性能表现却没有下降,这为卷积神经网络模型能嵌入到更加微小的机器中提供了可行性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
科技创新与应用(2021年23期)2021-08-30 11:46:16
无线互联科技(2020年15期)2020-11-10 06:00:58
科技传播(2020年6期)2020-05-25 11:07:46
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
雷达科学与技术(2018年3期)2018-07-18 00:59:32
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
