
术语表研制的四个步骤
2021-04-22 05:32刘宇红殷铭
中国科技术语 2021年2期
刘宇红 殷铭


摘 要:在国外学者的词频研究方法、语境研究方法和语料对比方法的基础上,以英语语言学56万余字的语料为基础,提出了四个步骤的术语表研制方法,并且归纳出了359个英语语言学术语。这种研究不仅是对英语语言学术语的第一次尝试性归纳,而且研究方法上的创新可以应用于其他学科的术语研究和术语表的研制。
关键词:术语表;英语语言学;词频;语境;语料库
中图分类法: N04;H083文献标识码:ADOI:10.3969/j.issn.1673-8578.2021.02.002
A Four-Step Building of Glossaries: Case Study of English Linguistic Glossary//LIU Yuhong, YIN Ming
Abstract: On the basis of the methodologies of Frequency, Context and Corpus Contrast originated outside China and by using a linguistic corpus of over 560 000 words, we put forward a four-step glossary building method and summarized a total of 359 English linguistic terms. This research is the first attempt in English linguistic glossary building while its innovation in research methodology benefits other disciplines in terminology research and glossary building.
Keywords:glossary; English linguistics; frequency; context; corpus
引言
術语表(glossary)是特定学科术语的集合。术语表的质量取决于术语的质量。梁爱林[1]把术语质量的标准概括为六个方面,即清晰性、一致性、得体性、简洁性、 准确性以及词的衍生能力;Perinán-Pascual[2]认为突显性(salience)、关联性(relevance)和连贯性(cohesion)决定了术语的质量。要确保术语表的质量,最重要的是从文本中提取术语的方法和程序要合理。一般来说,作为教材附录的术语表是将教材中出现过的术语按一定的顺序排列出来,这不是一件难事,但是要把一个学科的常用术语尽可能全面地遴选出来,代表一个学科的全部的知识体系和研究方法,却不是一件容易的事。本文以英语语言学为例,将提出一种四步骤的术语表研制方法,并将尽可能全面地归纳出英语语言学的术语。
1 术语表的研制方法回顾
国内的术语表研究是多侧面多角度的,比如叶其松[3]提出“术语编纂”三分说,从广义、一般概念和狭义三个维度对术语进行论述;郑述谱和梁爱林[4]对国外术语学研究现状进行了评介;梁爱林[1]对术语资源的质量评估进行了较全面的探讨。偶尔也有学位论文(如陈观喜[5])对文档术语表的自动构建方法展开研究,提出了一些较有价值的观点。
至于国外的术语表研究,更多地关注术语的产生过程和实施方法,在研究思路上大致可以分为三类。第一类是基于词频的方法,第二类是基于上下文语境的方法,第三类是语料对比的方法。这些研究与本文的关系更加密切,所以我们来简要介绍一下它们的主要观点和代表性理论,然后评述一下其得失。
第一类方法的基本思路是:如果一个单词出现的频率比较大或者该单词以固定的搭配形式出现在特定的文本中,那么它在这个领域中成为术语的可能性比较大。
词频方法代表性的理论是TF-IDF[6]。TF(term frequency)指词频,即一个词条在文档中出现的频率。IDF(inverse document frequency)指逆向文本词频,如果包含某词条的文档越少,即IDF 越大,则说明该词条具有很好的类别区分能力。C-Value[7]是术语抽取方法中应用较多的理论,在统计词频时它要求候选术语不得嵌套在别的术语中,先通过计算候选术语频率和长度得到一个分值,然后根据包含该候选术语的更长的候选术语的词频来调整该分值。Basic[8]与 C-Value 方法刚好相反,根据Basic方法抽取的术语可以是其他候选术语的一部分。
第二类方法是基于上下文语境来区分术语和非术语。NC-Value[7]是代表性的方法之一,它主张一个特定领域的语料库中通常有一个“重要”单词的列表,在这些“重要”单词语境中出现的候选术语应该被赋予更高的权重。Domain Coherence[9]方法是 NC-Value 的一个改进,它用 Basic 方法抽取最好的 200个术语候选项,然后从它们的上下文中过滤其他词性的单词,这个过滤过程只保留在文档中词频至少占四分之一的名词、形容词、动词和副词,最后用标准化的Astrakhantsev[9]排序得到前 50个单词。
第三类方法是语料对比的方法,基本做法是通过单词在指定领域语料中的词频和其他语料中的词频进行比较,将术语与一般的单词或者短语区别出来。这类方法主要有Domain Pertinence、Weirdness和Relevance[9]。
上述三类方法,各有其合理性,下面我们分别进行评述。
第一类方法基于词频来遴选术语,这是最为基础的操作步骤,但是词频方法不能排除高频的非术语词组,尤其是包含2~3词的词组,它们在各类文体中都具有很高的出现频率,比如put on和take advantage of这类词组,总是混迹于通过词频遴选出来的术语库中,而且数量很大。Biber等人[10]统计发现,在英语口语和书面语中这类词组分别占30%左右和21%左右。Erman和Warren [11]的统计结果比例更高,认为分别占58.6%和52.3%,所以词频方法只能是术语表研制中的步骤之一,而不能成为独立的术语遴选方法。
第二类方法是基于语境来区分术语和非术语,某些“重要”单词在词串语境中与其他单词的共现概率很高,但是词组作为整体的出现概率不一定高,所以词组可能被词频统计方法所过滤。如果能将词频方法和语境方法结合起来,把整体的词频数据和词组内部各成分的共现概率进行量化,对两者进行综合平衡,按一定的比例取值,这样计算的结果会比单独考虑词频或语境特征更能遴选出合理的术语表。
第三类方法是进行语料对比,通过同一单词在不同文体或不同语域的语料中进行频次比较,在统计术语时,这种方法可以排除高频日常词组,比如上文提到的put on和take advantage of等词组是各种文体和各种语域中的通用词组,它们不仅整体的词频很高,而且内部各成分的共现概率也很高,所以第三类方法通过语域排查可以过滤非术语的词组,但是必须与第一和第二类方法结合起来使用。
从我们的分析可以看出,三类方法各有其合理性,但是单独使用时都有一定的缺陷,所以本文拟提出四个步骤的遴选方法,充分利用上述三种方法的优势,同时让它们扬长避短,优势互补,找到一条适合术语遴选的方法。
2 术语表研制过程详解
本研究以英语语言学的术语提取和术语表制作为例。此研制方法不仅可以为其他学科术语表的研制提供一种示范,其研究结果也可以为英语语言学学科提供可以利用的术语库,指导英语语言学教材编写时的术语选用,同时也可以用作教材的附录,供教材读者使用。当然,由于语料选择的有限性和各种参数在量化精度上的局限性,术语表不可能穷尽一切术语,而且由于学科在不断发展之中,术语表也必须随着时间推移而不断更新。
2.1 步骤一:运用词频统计方法进行初步筛选
步骤一运用词频统计方法,筛选出候选的术语,是对第一类方法的借鉴和发挥。
为了研制英语语言学语域的术语表,我们设计了一个自建语料库,包括四种语言学著作,并将它命名为Linguistic Academic Corpus(LAC)。四部著作分别是:Bussmann[12]的Routledge Dictionary of Language and Linguistics;Kracht[13]的Introduction to Linguistics;Saussure [14]的Course in General Linguistics;胡壮麟[15]的《语言学教程》(第五版)。Routledge Dictionary of Language and Linguistics是到目前为止词条最多、声望较高的语言学词典,是学界同行最常拥有的工具书,涉及英语语言学的各个子学科,内容完整、全面。其他三部都是普通语言学的经典教材,它们涉及的术语比较全面,也比较规范。其中,Introduction to Linguistics是Marcus Kracht根据自己在UCLA讲授普通语言学时的讲义编写的教材,Course in General Linguistics是根据F. de Saussure在日内瓦大学三次讲授普通语言学的讲义整理出版的遗著,《语言学教程》是国内读者熟悉的普通语言学的经典教材,在内容和语言的经典性方面不逊于国外同类教材。四部著作的形符数(tokens)为568 138词,类符数(types)为27 828词。
在处理语料时,我们使用了语料库检索软件Collocate 1.0,对语料中的N元词组(N-gram)进行检索,词组长度设定为2~5词(即N=2,3,4,5),以词频(Frequency,下文缩写为Freq)为统计参数,发现共有86 918个词组类型,在下文中我们称之为LAC-86918,其中2~5词的词组分别是39 339、27 694、12 986、6899个。表1是各种长度词组的举例,它们分别是各组中词频最高的10个例子。
从表1可以看出,10个频率最高的2词词组只有of language与语言学相关,3词词组只有the meaning of与语言学相关,4~5词词组中与语言学相关的词组稍多,共有6个与语言学有关,而且,它們都不具备术语的名词性范畴特征,或者是语义不完整,没有明确的语义指向。对4~5词词组来说,词组不具有单一的语义中心,如trends in linguistics The Hague,或者说它们具有跨句的组合性特征。所以,必须对LAC-86918进行较大规模地压缩和精简。
2.2 步骤二:运用停用词列表进行二次筛选
对LAC-86918进行压缩和精简,是第二步的操作,即根据停用词表(stopword list)来进行过滤和精简,可以较大限度地区分术语与非术语。所谓的“停用词”,指高频率的虚词或与检索目标无关的高频词组。
使用停用词表,符合第二类方法中的NC-Value理论(Frantzi et al 2000),它认为在某些“重要”单词语境中出现的候选术语应该被赋予更高的权重,“停用词表”的使用正是对这一原则的逆向使用,因为“停用词表”是可以认定的“不重要”的单词或词组,可以把它们或与之搭配的词组过滤掉。Domain Coherence [7]用Basic方法抽取最好的200个术语候选项,再从它们的上下文中过滤其他词性的单词,过滤过程只保留在文档中词频至少占四分之一的名词、形容词、动词和副词,这种方法的逆向使用也与使用“停用词表”的方法异曲同工,因为“停用词表”包含的过滤项包括各种虚词(还有PL和AFL),过滤的结果与Domain Coherence方法只保留高频名词、形容词、动词和副词的方法在思路上是一致的。
从表1可以看出,LAC-86918中包含了太多的虚词成分(如介词、不定式的小品词to等),另外还包含很多非学术的通用词组和通用学术词组,为了把这两类词组过滤掉,我们选择了PL和AFL这两个词组库。
PL是Martinez和Schmitt[16]基于英国国家语料库(BNC)选取的505条非学术词组库(PHRASal expressions list)。在505条非学术词组中,有119条被两位作者标记为在书面文体中“少见或不存在”(rare or non-existent),只在口头文本中有较大频率,所以本研究只选取在书面文体中有较高频率的386条短语(386=505-119),包括2~4词组成的非学术词汇。
AFL是由Simpson-Vlach和Ellis[17]所创建的通用学术语料库(academic formula list),总共607个词组,包括三个部分,第一部分是在口语与书面语中均为高频的207个核心词组(core AFL academic formulas),第二部分是在书面语中高频的200个词组(written AFL top 200),第三部分是在口语文体中高频的200个词组(spoken AFL top 200)。我们选取207个核心词组和200个书面语词组,共计407个。它们是由3~5词组成的学术词组。
选用PL和AFL的理由,是因为它们分别代表日常话语中的通用词组和多学科的通用学术词组,而本研究选用的语料是语言学语域的专门学科文本,其目标是提取语言学语域的专门术语,所以该术语表不会与PL和AFL交叉或共现。
运用停用词对LAC-86918进行二次筛选,得到2~5词的术语分别为6356条、573条、82条和25条,总数是7036,只有LAC-86918的不到1/12。为了方便,我们把精简后的词组库称为LAC-7036。表2列出了LAC-7036中词频排序最高的10个术语词组,这些词组中大部分都具有术语的结构特征,也体现术语的语义类型。
LAC-7036的数量仍然太过庞大,而且,4~5词的词组具有跨句的组合特征,许多外来语(如grammatica storica della lingua italiana)也混跡其中,所以必须开启第三步骤的筛选。
2.3 步骤三:运用互信息熵MI和词组教学值FTW来进行第三次筛选
第三步的筛选是运用互信息熵MI(mutual information)和词组教学值FTW(formula teaching worth)来体现语境的筛选功能,也是借鉴了上文的第二类方法[7,9]。我们先介绍一下互信息熵MI和词组教学值FTW。
互信息熵MI[18]可以测量中心词(node word)和搭配词(collocate) 之间的关联强度 (association strength) 或可搭配性(collocability)。MI的计算公式是:MI(x,y)=fobs(x,y)/fexp(x,y)。在公式中,x是中心词,它的前后若干长度内的搭配词为y,MI(x,y)是x和y之间的互信息熵。等式右边是两个函数式(f: function)相除,x与y的观测共现频数(obs: observation)的函数fobs(x,y)为分子,零假设下中心词与搭配词的期望共现频数(exp: expectation)的函数fexp(x,y)为分母[19]。
词组教学值(FTW)是Simpson-Vlach和Ellis[17]提出的计算方法,用于评估教师在多大程度上认为某词组应该成为教学内容。FTW是对互信息熵和词频的按比例取值,即FTW =0.56 MI +0.31 Freq,当MI、Freq和FTW三个参数取值相互冲突时,Simpson-Vlach和Ellis[17]的做法是FTW优先。
所以,不管是MI还是FTW,都或多或少地体现了词组内部各成分之间的相互期待,体现了“重要”的词[7]与周边词之间相互吸引的强度,或者说体现了“重要”的词所受的语境约束的大小,所以MI和FTW一方面排除了词频对于术语遴选的唯一取舍功能,另一方面也可以弥补语料库规模对于词频总数的影响。任何语料库的规模都是有限的(不管它实际有多大),一般来说,语料库的规模越大,术语的出现频次就越多,所以如果考虑MI并且将它与词频按一定比例折算成FTW,就可以降低语料库规模的影响。这种做法体现了上文第二类方法对于第一类方法的补足与纠偏。
我们遵循这种算法,把FTW的取值设定为10.00,即只取FTW大于或等于10.00的词组,得出681个语言学语域的术语词组,我们称之为LAC-681,2~5词的词组分别是197个、377个、82个、25个,在规模上又只有LAC-7036的不到1/10,与LAC-86918相比只有不到1/127。对LAC-681在此暂不举例,因为它分为两部分,其中一部分是在第四步骤(见下一节)的操作中被淘汰的部分,所以在下一节将有举例,而保留的部分就是最终产品,即语言学语域的术语表。
2.4 步骤四:基于人工语义判断的第四次筛选
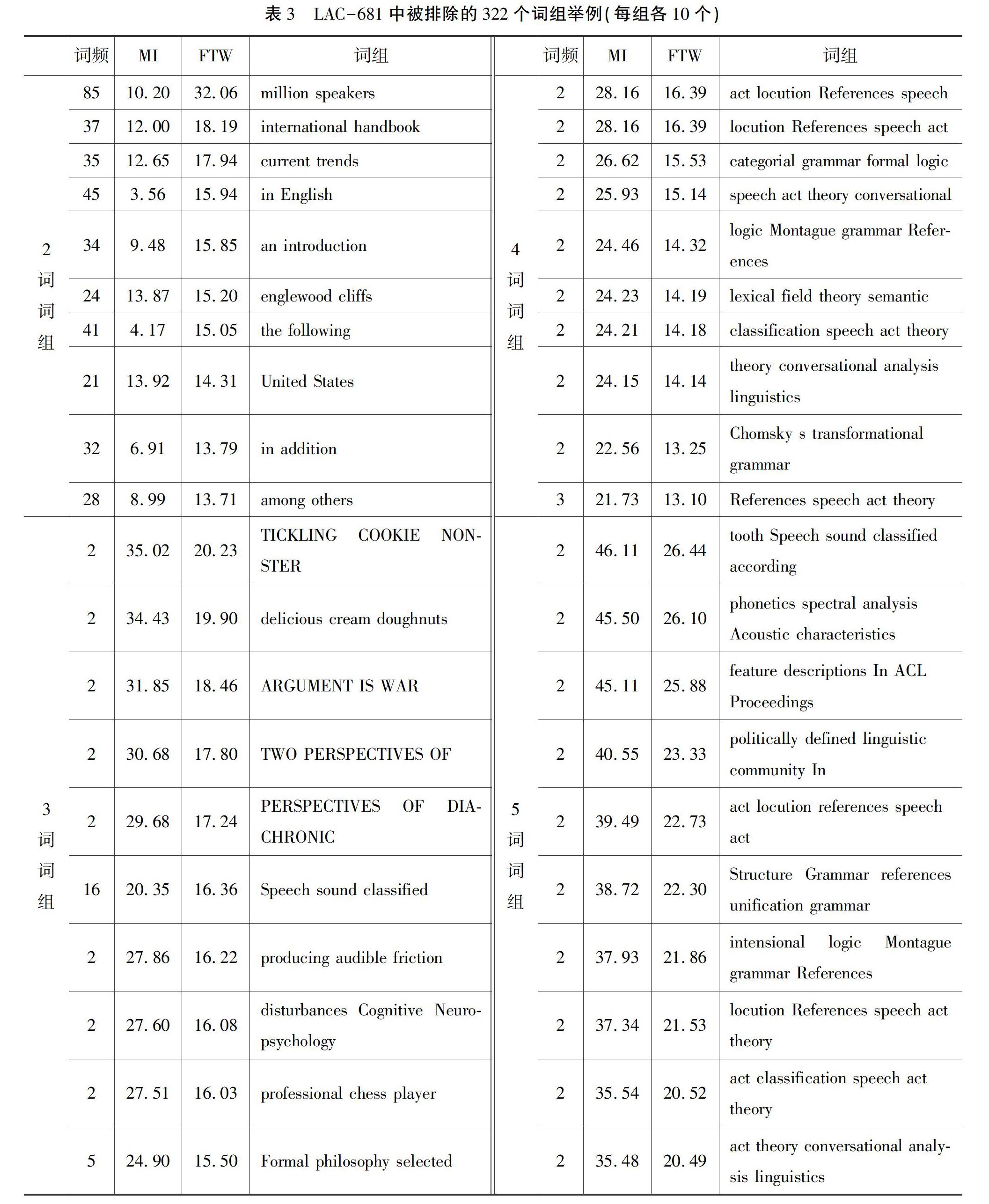
研究发现,LAC-681虽然经过三次过滤,但仍然包含了较多非术语的词组,必须进行第四步的过滤。造成过滤不彻底的原因有两个:一是在第二步骤中使用的停用词表不可能刚好与术语词组具有互补性,我们选择停用词表的原则是宁可过滤功能稍有欠缺,不可过滤功能太过强大;另一个原因是MI和FTW的使用客观上产生了一种负效应,因为原本可能通过词频被过滤的非术语词组,因为MI和FTW降低了词频的权重,所以一部分原本词频较低的词组又进入LAC-681中,比如表3中的tickling cookie monster只出现了2次,但是它的内部连贯性很强,所以MI的取值高达35.02,结果FTW的值被拉高了,但它显然不是语言学的术语。所以,为了把此类词组过滤掉,必须借鉴上文的第三类方法,即运用语料对比的方法,通过单词在指定领域语料中的词频和其他语料中的词频进行比较来排除。由于LAC-681的规模较小,所以我们采用人工判断的方法,把语言学语域的词组与非语言学语域的词组区分开来,排查的结果是剔除了322个词组,其中有的词组是语义不完整或者在结构上是跨句的词汇组合(如categorial grammar formal logic)。表3是322个被排除的词组中各种词长词组FTW取值最大的10个例子,按FTW的降序排列。
排除了322个非术语的词组后,余下的359个词组就是最终产品,称为LAC-359,即语言学语域的术语表,其中第1~97是2词术语,共97个,约占27.02%,FTW的平均值为14.07;第98~320是3词术语,共223个,约占62.12%,FTW的平均值为12.85;第321~356是4词术语,共36个,约占10.03%,FTW的平均值为19.1;第357~359是5词术语,共3个,约占0.83%,FTW的平均值为26.1。在附录中,每一种词长的术语都是按FTW的降序排列。
从上面的数据对比可以看出,3词术语最多,其次是2词术语,再次是4词术语, 5词术语最少。从FTW来看,4词术语和5词术语最高,它们的词频并不高,但是MI取值较高,即内部成分之间具有较高的相互期待。2词术语和3词术语的FTW相对偏低,它们的词频虽然较高,但是MI取值偏低。
3 结语
国外学者对术语的研制方法可以分为三类:词频研究方法、利用语境的研究方法和语料对比的研究方法,他们各有优胜之处,也各有其不足。本文提出的四步骤术语表研制方法吸纳了三类方法的优点,同时回避了他们的不足。在四步骤方法中,第一步骤对应词频研究方法,第二和第三步骤是语境研究方法的应用和拓展,第四步骤是以人工筛选的方法体现语料对比的原则。通过对56万余字的英语语言学语料的多种操作,归纳出了359个英语语言学术语。本文的研究不仅是对英语语言学术语全面的尝试性归纳,其中的研究方法可以应用于各个学科的术语研究和术语表的研制。由于语料选择的有限性和各种参数在取值上的局限性,LAC-359不可能穷尽一切术语,而且受到学科发展阶段性特征的局限,术语表还必须随着时间推移而不断更新。
本文的术语提炼方法,对于其他学科具有同等的适用性。但是,鉴于本文的语料是英文,如果其他学科所采用的语料是中文,而且中文是音节文字,词句间有不同的断句方法,所以我们建议采用多种方法对语料进行分词(parse),在分词结果各不相同的前提下,建议采用“投票”软件(软件名为vote)。英文或其他印欧语言的语料,词与词之间有空格分开,无须进行分词操作。
我们建议同时使用hanlp、jieba和thulac这三种分词软件,以《语言学纲要》[19]第一章第一节第一段为例,三种分词效果对比如下。
hanlp的分词效果:
语言/的/功能/是/客观存在/的/。/功能/既是/语言/的/属性/,/也/是/我们/认识/语言/的/一个/视角/。/语言/的/功能/是/多方面/的/,/如果/从/宽泛/的/意义/上/讲/,/大致/都可/归入/语言/的/社会/功能/和/思维/功能/两/个/方面/。/
jieba的分词效果:
语言/的/功能/是/客观存在/的/。/功能/既/是/语言/的/属性/,/也/是/我们/认识/语言/的/一个/视角/。/语言/的/功能/是/多方面/的/,/如果/从/宽泛/的/意义/上/讲/,/大致/都/可/归入/语言/的/社会/功能/和/思维/功能/两个/方面/。/
thulac的分词效果:
语言/的/功能/是/客观/存在/的/。/功能/既/是/语言/的/属性/,/也/是/我们/认识/语言/的/一个/视角/。/语言/的/功能/是/多方面/的/,/如果/从/宽泛/的/意义/上/讲/,/大致/都/可/归入/语言/的/社会/功能/和/思维/功能/两/个/方面/。/
分歧存在于每段中的划线部分,所以必须采用“投票”程序,对三种分词效果进行“投票”,体现“少数服从多数”的原则。
投票结果:
语言/的/功能/是/客观存在/的/。/功能/既/是/语言/的/属性/,/也/是/我们/认识/语言/的/一个/视角/。/语言/的/功能/是/多方面/的/,/如果/从/宽泛/的/意义/上/讲/,/大致/都可/归入/语言/的/社会/功能/和/思维/功能/两/个/方面/。/
分词后,還必须进行人工校对,比如将“客观存在”分成两个词。国内各学科的同行使用的语料一般是中文语料,可按上述方法处理语料。在语料处理完成之后,对于处理结果的统计和人工校对可以借鉴本文的方法。
参考文献
[1]梁爱林. 术语资源的质量评估[J]. 辞书研究, 2016, (1):32-44.
[2] PERINAN-PASCUAL C, MESTRE-MESTRE D. Automatic Extraction of Domain-Specific Glossaries for Language Teaching[J]. Procedia Social & Behavioral Sciences, 2015, 198: 377-385.
[3] 叶其松. “术语编纂”三分说[J]. 辞书研究, 2014,(6):34-41.
[4] 郑述谱, 梁爱林. 国外术语学研究现状概观[J]. 辞书研究, 2010,(2):86-99.
[5] 陈观喜. 文档的术语表自动构建方法研究[D].南京:东南大学硕士论文,2018.
[6] AUGENSTEIN I, MAYNARD D,CIRAVEGNA F. Relation Extraction from the Web Using Distant Supervision[J]. EKAW, 2014, 8876: 26-41.
[7] FRANTZI K, ANANIADOU S, MIMA H. Automatic recognition of multi-word terms:the c-value/nc-value method[J]. International Journal on Digital Libraries,2000, 3(2): 115-130.
[8] BORDEA G, BUITELAAR P, POLAJNAR T. Domain-independent term extraction through domain modeling[C]//the10thInternationalConferenceonTerminologyandArtificialIntelligence. Paris: TIA,2013.
[9] ASTRAKHANTSEV N. ATRS: Toolkit with State-of-the-art Automatic Terms Recognition Methods in Scala[J]. Language Resources & Evaluation, 2016(4):1-20.
[10] BIBER D. JOHANSSON S, LEECH G, et al. Longman grammar of spoken and written English[M]. Harlow: Pearson Education ESL,1999.
[11] ERMAN B, WARREN B.The idiom principle and the open choice principle[J]. Text, 2000,20(1):29-62.
[12] BUSSMANN H. Routledge Dictionary of Language and Linguistics[M].Routledge Press. 1996. 外研社,2000.
[13] KRACHT M. Introduction to Linguistics[J/OL].[2020-11-12]. https://www.pdfdrive.com/introduction-to-linguistics-e5989391.html.
[14] SAUSSURE F. Course in general linguistics[M]. Translated and annotated by Roy Harris. London: Duckworth. 1916/1983.
[15] 胡壮麟. 语言学教程[M]. 5版.北京:北京大学出版社,2017.
[16] MARTINEZ R, NORBERT S.A Phrasal Expressions List[J]. Applied Linguistics, 2012(3):299-320.
[17] SIMPSON-VLACH R, ELLIS N C. An Academic Formulas List: New Methods in Phraseology Research[J]. Applied Linguistics, 2010, 31:487-512.
[18] FANO R M. Transmission of Information: a Statistical Theory of Communication[M].Massachusetts:MIT Press,1961.
[19] 冯跃进,汪腊萍.英语中词项搭配关系的定量研究[J].国外外语教学,1999(2):5-10.
[20] 叶蜚声,徐通锵.语言学纲要[M].3版.北京:北京大学出版社,1997.
作者简介:通讯作者:刘宇红(1966—),男,博士,2003年毕业于复旦大学外文学院,获文学博士学位,同年破格晋升为教授。现任南京师范大学外国语学院教授、博士生导师。2005—2006年在美国休斯敦Rice University访学。主要研究方向涉及认知语言学、功能语言学、语言哲学、语义学、语用学、神经语言学,发表论文90余篇,出版专著14种。通信方式:liuyuhong@njnu.edu.cn。
殷铭(1982—),男,硕士,研究方向为语料库语言学、应用语言学。2015年毕业于南京师范大學外国语学院,获英语语言文学硕士学位。现为南京师范大学泰州学院外国语学院副教授。发表论文8篇,主编及参编教材8部。通信方式:20061004@nnutc.edu.cn。
猜你喜欢
园林科技(2021年3期)2022-01-19
天津外国语大学学报(2020年1期)2020-03-25
青春岁月(2016年22期)2016-12-23
亚太教育(2016年35期)2016-12-21
考试周刊(2016年71期)2016-09-20
考试周刊(2016年71期)2016-09-20
语言与翻译(2015年4期)2015-07-18
读者·校园版(2015年7期)2015-05-14
深圳大学学报(理工版)(2015年5期)2015-02-28
图书馆论坛(2014年8期)2014-03-11
