
SUV车型外观评论文本情感分析
2021-04-19 02:14李兰友陆金桂张建德
汽车工程学报 2021年2期
李兰友,陆金桂,张建德
(1.南京工业大学 机械与动力工程学院,南京 211800;2. 南京工程学院 计算机工程学院,南京 211167)
互联网的快速发展,催生了“互联网+”的产品设计新理念,那就是必须要倾听用户的心声。而以论坛、微博等网络平台产生的海量评论文本,是商家获取用户体验的重要源泉。利用词云可视化技术和潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)主题模型等情感分析方法,能自动化地进行情感分析,为企业提供精准的用户群体特征、全面的评价对象属性和有效的产品特征识别,有助于企业优化产品设计,为生产企业的商业决策提供数据支撑,便于破坏性创新。
随着汽车行业的快速发展,汽车产业的竞争日益激烈,而汽车外观是消费者的第一印象,获取汽车外观的评论文本,进行挖掘分析,有助于汽车企业了解用户的审美意向和情感状态,进而开发设计出受市场欢迎的汽车产品。本文将词云可视化技术和LDA主题模型相结合,以SUV车型的太平洋汽车网论坛[1]的68 216×20的原始评论数据为语料来源,构建了情感分析模型,实现对文本评论的倾向性判断和隐藏信息挖掘,给出了情感倾向性分析结果。
1 情感分析概述
情感分析(Sentiment Analysis)[2-3]又称情感挖掘(Sentiment Mining)、倾向性分析(Tendentious Analysis)等,是使用自然语言处理、语言学和机器学习等技术进行主观性意见相关的信息挖掘,并尝试用这些来计算文本文档所表示的积极、消极或中性等情感极性的过程,更深层次的,还可以分析文档中复杂的情绪,例如悲伤、快乐和讽刺语义等。
主流的情感分析方法[4]主要有以下4种:关键词识别、词汇关联、概念级技术和统计方法。关键词识别是利用文本中出现的清楚定义的影响词来影响分类。词汇关联除了侦查影响词以外,还赋予词汇一个和某项情绪的“关联”值。概念级的算法思路权衡了知识表达的元素,比如知识本体、语义网络等,它能探查到文字间比较微妙的情绪表达。统计方法通过调控机器学习中的元素,尝试用机器学习的方法进行情感分类,常见的统计方法如潜在语意分析法(Latent Semantic Analysis)、SVM法(Support Vector Machines)、词袋法(Bag of Words)等。
情感分析根据分析载体的不同会涉及到很多不同的主题,像电影评论、舆情分析和产品评论等,研究的目的主要集中在识别给定的文本实体的主客观分析以及识别主观文本的极性。姜霖等[5]以豆瓣网站的电影评论为语料库,利用评论挖掘技术发掘用户的偏好,实现有效推荐决策。CHEN Kun等[6]运用LDA主题提取,采用TOPSIS方法对手机评论进行可视化分析,得到了市场布局图形化呈现效果。李昊璇等[7]以图书购物网站的书籍评论为语料库,提出了一种基于词向量和卷积神经网络的书籍评论情感分类方法。黄磊等[8]以美食、酒店、电影、休闲娱乐、结婚、家装等6个细分领域的评论为语料库,提出了一种融合群稀疏与排他性稀疏正则项的神经网络压缩情感分析方法。王伟等[9]针对数码相机评论、影评、手机评论等7类语料来源,采用词频统计方法,以SVM法等6种算法进行产品特征和观点的抽取,得出不同领域下的特征抽取难度是存在差异的结论。李晋源等[10]以京东商城的商品评论为语料库,提出一种面向方面深度记忆网络模型的细粒度情感分析方法。赵志滨等[11]使用规则法抽取产品评论中所描述的维度信息,然后分别针对各个维度计算维度情感分析。梁斌等[12]给出了一个多注意力卷积神经网络的特定目标情感分析方法,并在SemEval2014数据集和汽车领域数据集ADD上进行了试验,取得了较好的效果。尤天慧等[13]以汽车之家网站的在线评论信息为语料,提出了一种基于情感分析和证据理论的多属性在线评论决策方法。小鹏汽车创始人何小鹏在Rebuild2020科技全明星峰会上指出未来“好车”的定义是首先要好看,其次就是要展示自我个性,第三点就是车要很智能。从中可以看出“好车”设计的前两点都和外观相关,外观既要好看又要个性,但如何通过产品造型设计表达出来,这是汽车设计师亟待解决的难题。常用的方法之一是通过构建感性意象词汇空间,建立感性意象词汇和产品造型之间的映射模型,以达到“好看个性”的感性期望[14]。而汽车外观评论情感分析则是获取感性意象词汇的重要手段,也是评价汽车外观造型美学的重要方法,具备较高的实用价值。本文将以SUV车型外观评论语料为基础,给出一个情感分析的模型和方法。
2 情感分析模型
2.1 LDA主题模型
LDA是由BLEI等[15]于2003年提出的,它假设文档中主题的先验分布和主题中词的先验分布都遵循了贝叶斯统计基础理论,而服从狄利克雷分布。LDA包含隐含变量,根据词的共现信息的分析,拟合出词(w)、文档(d)、主题(z)的分布,进而将词、文本都映射到第一个语义空间中,并采用了词袋技术的关键词提取模型。令词表大小为L,一个L维向量(1,0,…,0,0)表示一个词。由N个词构成的评论记为d=(w1,w2,…,wN)。假设某一商品的评论集D由M篇评论构成,记为D=(d1,d2,…,dM)。M篇评论分布着K个主题,记为zi(i=1,2, …,K)。记α和β为狄利克雷函数(Dir)的先验参数,θ为主题在文档中的多项分布(Multi)的参数,其服从超参数为α的狄利克雷先验分布,φ为词在主题中的多项式分布参数,其服从超参数β的狄利克雷先验分布,LDA模型如图1所示[16]。
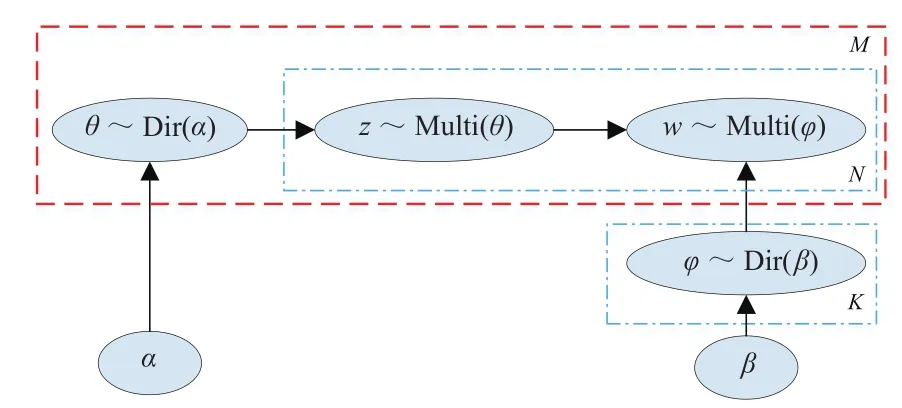
图1 LDA主题模型结构
LDA模型实际训练过程中对参数θ、φ的近似估计通常使用马尔科夫链蒙特卡洛算法中的一个特例吉布斯(Gibbs)抽样。据此,其训练步骤如下:
(1)随机初始化,对语料中每篇文档中的每个词w,随机地赋予一个主题编号z。
(2)重新扫描语料库,对每个词w按照吉布斯采样公式重新采样它的主题,在语料中更新。
(3)重复以上语料库的重新采样过程直到吉布斯采样收敛。
(4)统计语料库的主题词共现频率矩阵,该矩阵就是LDA的模型。
2.2 语义网络模型
语义网络模型最先由西蒙(R. F. Simon)于20世纪70年代提出[17],是自然语言理解及认知科学领域研究中的一个概念,用来表达复杂的概念及其相互之间的关系,是一个有向图,其顶点表示概念,而边则表示这些概念间的语义关系,从而形成一个由节点和弧组成的语义网络描述图。
同时,要想对中文评论文本进行整体结构情感分析,首先就得进行分词处理,以完成情感信息的抽取工作,而情感信息的分类工作则通过LDA模型以统计学的方式来完成,但这也产生了一个问题,分词打乱了整个评论文本的结构,从而导致无法全面获取文本的语义。这就需要采用语义网络模型将这种原本已凌乱的关系重新进行整合,进而清晰地还原出原始评论文本中所蕴含的语义内容。这是情感分析建模的重要环节,通过词云可视化分析以及LDA主题模型分析,将评论数据抽取成正面、负面、中性等3个方面,然后对正面、负面两组数据进行语义网络重构,在此进行交互诊断,以借助重构的可视化网络图,来完成判断特定产品的优缺点、抽取消费者的兴趣点等工作。
2.3 分析方法与过程
本文的分析过程如图2所示。主要步骤如下:
(1)利用八爪鱼爬虫工具对太平洋汽车网点评频道进行SUV车型样本评论文本采集,完成数据采集工作。
(2)通过文本去重、空行删除、机械压缩、专用词典构建、文本分词、停用词去除以及关键词提取等操作,完成文本数据的预处理工作。
(3)利用词云可视化技术、LDA主题分析模型以及情感倾向分析等方法对评论文本数据进行多方面的分析诊断。
(4)获取用户情感倾向分析结果,并挖掘出特定SUV车型外观的优缺点。
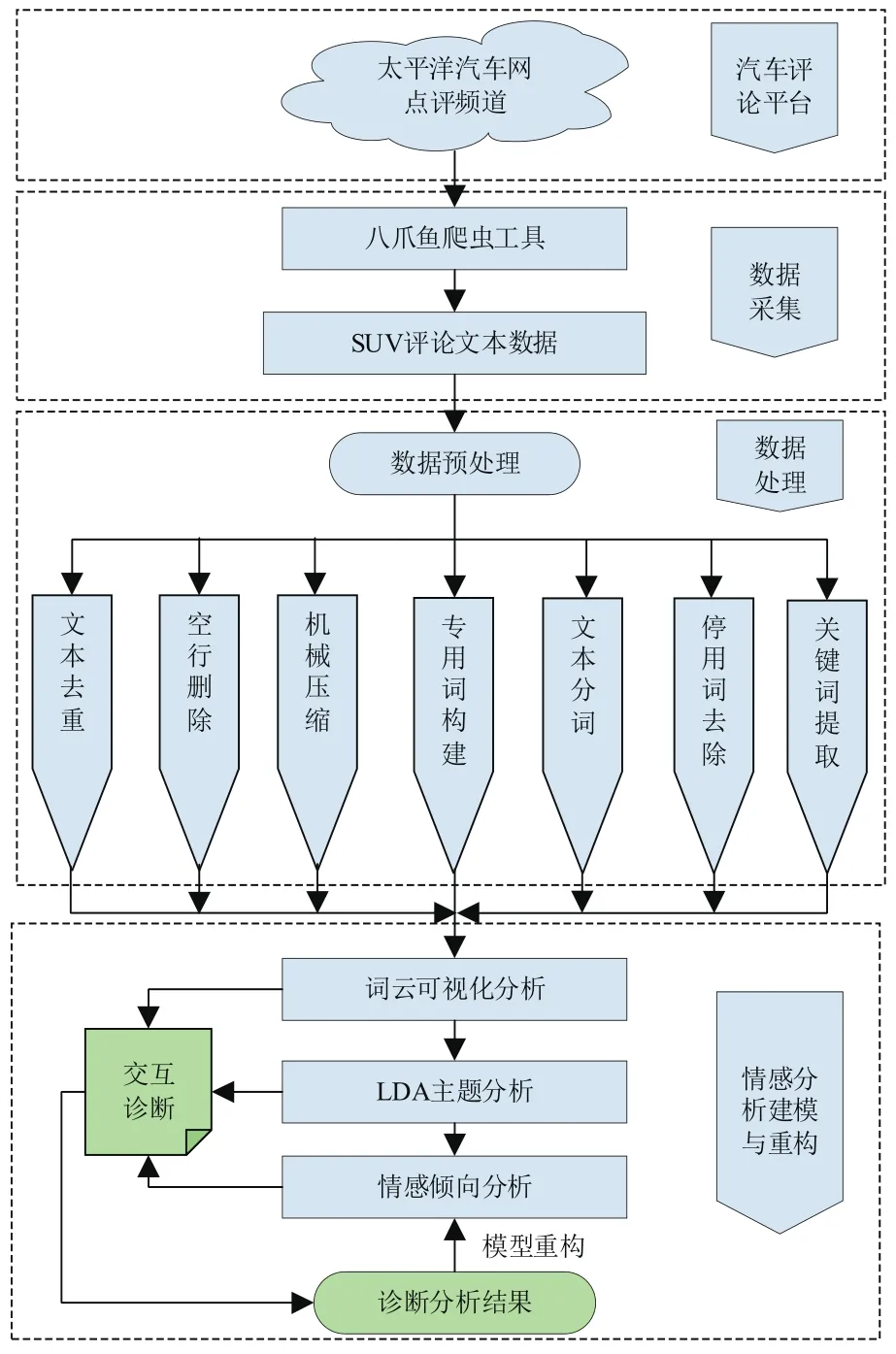
图2 情感分析流程
3 试验分析
3.1 试验环境
试验的硬件平台为一台计算机,处理器为Intel(R) Core(TM) i7-6700HQ@2.60 GHz,内存8 G,硬盘容量600 G。Python开发环境在各具体开源库之间进行了兼容性测试,将不兼容的库剔除,并替换成最优的相互兼容集成的库,具体见表1。
3.2 数据语料库
自行采集的数据语料库为60款不同SUV样本的车主点评频道评论信息,包括页面网址、客户、发表时间、购买车型、购买时间、购买地点、裸车价格、平均油耗、行驶里程、评分、优点、缺点、外观、内饰、空间、配置、动力、越野、油耗、舒适性等20个维度,从2019年6月13日下午16:30开始至2019年6月19日凌晨3:12结束采集,共整理得到68 216×20的原始文本数据矩阵,采集得到的某款SUV车型的评论文本信息部分维度示例见表2。由于本文重点关注外观维度的评论语料信息,所以通过Python语言的pandas包专门抽取“外观”这一个维度的评论信息,组成外观评论汇总数据集,共68 008条(将外观这一维度的空数据去除)。
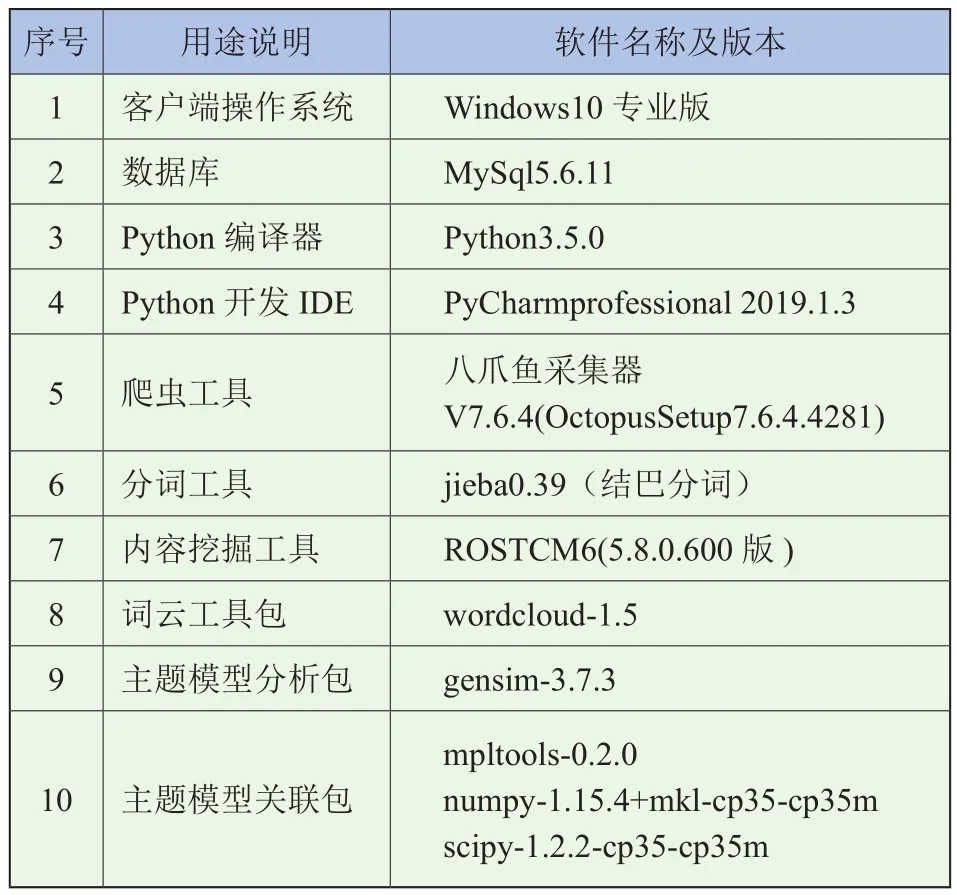
表1 试验开发运行环境表

表2 文本语料示例表
3.3 数据预处理
从语料库中获取的评论文本信息含有大量的空格、空行、以及价值低甚至无价值的评论冗余信息,这些信息会对情感分析造成干扰,所以通过文本去重、空行删除、机械压缩、停用词去除等操作来降低噪声。此外,SUV车型评论会涉及到汽车行业专用词汇,所以需要构建专用词典,最后通过文本分词和关键词提取为后续的情感模型分析奠定数据基础。
3.3.1 文本去重
针对外观维度的评论信息如果出现两条一模一样的评论,很大的概率就是后一个用户复制粘贴前一个用户的,这对情感分析来说,没有太多价值,还会对词频分析造成干扰。所以利用最基础的比较删除法来去重,就是两两比较,完全相同的就去除,如果有空行的也一并删除。利用pandas包的unique()函数完成此项操作,共删除重复数据25 333条。
3.3.2 空行删除
经过文本去重后,还要判断读取的数据是否存在缺失值,可以使用pandas库中的isnull()函数判断是否含有空数据。如果文本中还有空行的情况,就利用strip()函数,传递“ ”参数实现空行删除的效果。如果没有空行,说明没有缺失值,可以继续分析。
3.3.3 机械压缩
机械压缩操作解决的是评论文本中存在的许多无实际意义的重复词汇,当读取的字符与第1个列表的第1个字符相同时,则触发压缩判断,若得出重复,则进行压缩去除,清空第2个列表,并针对文本开头及连续重复的语料进行压缩去词,例如:
“大气!大气!!大气!!!就是她的大气吸引我去驾驭她的。”
压缩后成为:
“大气!!!就是她的大气吸引我去驾驭她的。”
实际压缩试验后,数据由压缩前的4 386 kB缩小到4 382 kB。
3.3.4 专用词构建
因本文着重研究汽车外观文本评论,对于汽车行业的专用词汇需要进行构建,以防分词工具误将专业词汇拆分。根据网络扩展语境,通过百度百科等高级搜索工具对一些流行的网络评价词汇给予收录。据此,构建jieba分词工具的分词词典。分词词典的格式为一个词占一行,每一行分为词语、词频(可省略)、词性(可省略)三部分,用空格隔开,顺序不可逆,词典文本采用utf-8编码。这里,分词词典的词频越高,成词的概率就越大,词性中“nz”代表其他专有名词,见表3。

表3 专用词典示例表
3.3.5 文本分词
词在语言理解中是最小的能够独立活动的有意义的语言成分,和印欧体系大不相同,中文必须进行分词处理,才能将句子转化为词的表示,通过计算机自动识别出句子的词,在词间加入边界标记符,分隔出各个词汇,这个切词的处理过程就是中文分词。分词结果的准确性对后续文本情感分析有着很大的影响,如果分词效果不佳,即使后续算法优秀,也难以实现理想的效果。本文采用Python的中文分词包“jieba”(结巴分词)进行分词,它结合了基于规则和基于统计的这两类的方法,并且具有丰富的功能和高涨的活跃度,使用简单,而且Python语言包也丰富,提供了分词、词性标注、未登录词识别、用户词典和停用词词典过滤等功能。本次采用结巴分词库的精确模式即参数“cut_all=False”。
3.3.6 停用词去除
在文本分词中,将对文本含义无贡献的词语删除,以消除对文本情感分析的影响。主要有两方面特征,一是词频高,总量大;二是包含信息量低,对文本情感分析无实际意义。例如“的”“地”“着”等助词,“哈”“啊”等拟声词等,不过在停用词的去除中,需要保留否定词。具体采用停用词表的方式进行过滤,将分词结果与停用词表中的词语进行匹配,若匹配成功,则进行删除处理。
3.3.7 关键词提取
关键词提取就是根据文本分词的结果,将词频最高的那一部分分词列出,构建评论文本的关键词列表,同时为绘制词云图做好前期准备。采用两种算法分别进行关键词提取操作,第1种是基于TFIDF算法的关键词抽取,调用的函数为jieba.analyse.extract_tags(),其基本思想是计算出文档中每个词的TF-IDF值,然后按降序排列,排在最前面的词即为关键词;第2种是基于TextRank算法的关键词抽取,调用的函数为jieba.analyse.textrank(),其基本思想是将待抽取关键词的文本进行分词,然后以固定窗口大小统计词之间的共现关系,来构建无向带权图,进而计算图中节点的PageRank,最后提取关键词。提取关键词的过程中,获取文本的纯词频统计数据。两种算法的前15个关键词及其词频和权重见表4。由表可知,TextRank与TF-IDF这两种算法均严重依赖于分词结果,但是提取的权重前15个关键词并不完全相同;TextRank算法的效果并不优于TF-IDF算法;TextRank虽然考虑到了词之间的关系,但是仍然倾向于将高频词作为关键词。

表4 关键词及其词频和权重示例表
3.4 制作词云
分词和词频都准备好后,就可以制作词云了。取词频最高的前100个分词为素材,通过Python中的wordcloud库进行词云的绘制。绘制词云一般有两种方式:一种是采用“/”将词分开的形式;一种是采用制定词语频率字典的形式。本文采用字典的形式进行绘制,并调用了一张SUV车型的背景图片进行mask,绘制的词云图如图3所示。

图3 情感分析词云图
3.5 LDA主题模型实现
在外观评论情感分析中,应用LDA主题生成模型时[18],评论中的特征词是模型中的可观测变量,而主题就是每篇文档的潜在中心思想。主题模型自动分析每个文档,统计文档内的词语,根据统计的信息来断定当前文档含有哪些主题,以及每个主题所占的比例各为多少。试验中,考虑到文本的正面评价和负面评价混淆在一起进行主题分析可能会产生令人困惑的情况,就对文本进行情感极性分析,主要通过以下步骤:
(1)空行删除、ANSI格式转换等数据预处理工作。
(2)利用ROSTCM6软件进行情感倾向性分析,产生正面评价文本、负面评价文本和中性评价文本三大类情感文本结果。
(3)对以上步骤中产生的分类结果数据进行UTF-8格式转换,去掉情感极性值,只留评论文本。
(4)抽取正面评价文本和负面评价文本,进行分词和停用词过滤处理,以及LDA主题分析。
(5)对正面评价文本和负面评价文本进行语义网络分析,并将LDA主题分析的结果融合到语义网络中进行综合诊断。
在进行情感倾向性分析时,采用了武汉大学沈阳教授团队[19]开发的ROSTCM6软件,通过此软件,可以生成“正面情感结果”、“负面情感结果”以及“中性情感结果”,还能进行社会网络和语义网络分析,舍弃“中性情感结果”,分别对“正面情感结果”和“负面情感结果”文本进行LDA分析,分析时的效果图如图4所示。

图4 情感分析效果图
以哈弗H6为特定SUV样本进行LDA主题分析,在选择主题个数时,参考了文献[20]中的困惑度方差指标法(Perplexity-Var)进行了最优主题数目K的确定试验,最终确定选择了3个主题聚类,每个聚类产生了10个代表性关键词及其相应的概率值,其正面评价文本潜在主题见表5,负面评价文本潜在主题见表6。
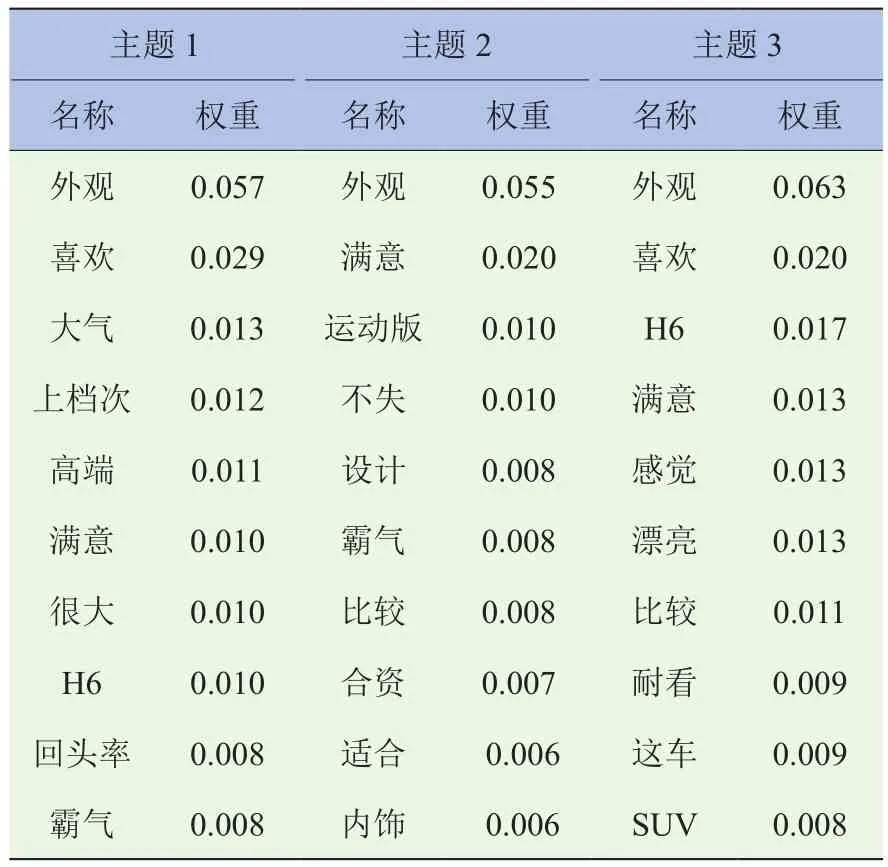
表5 哈弗H6正面评价潜在主题展示表
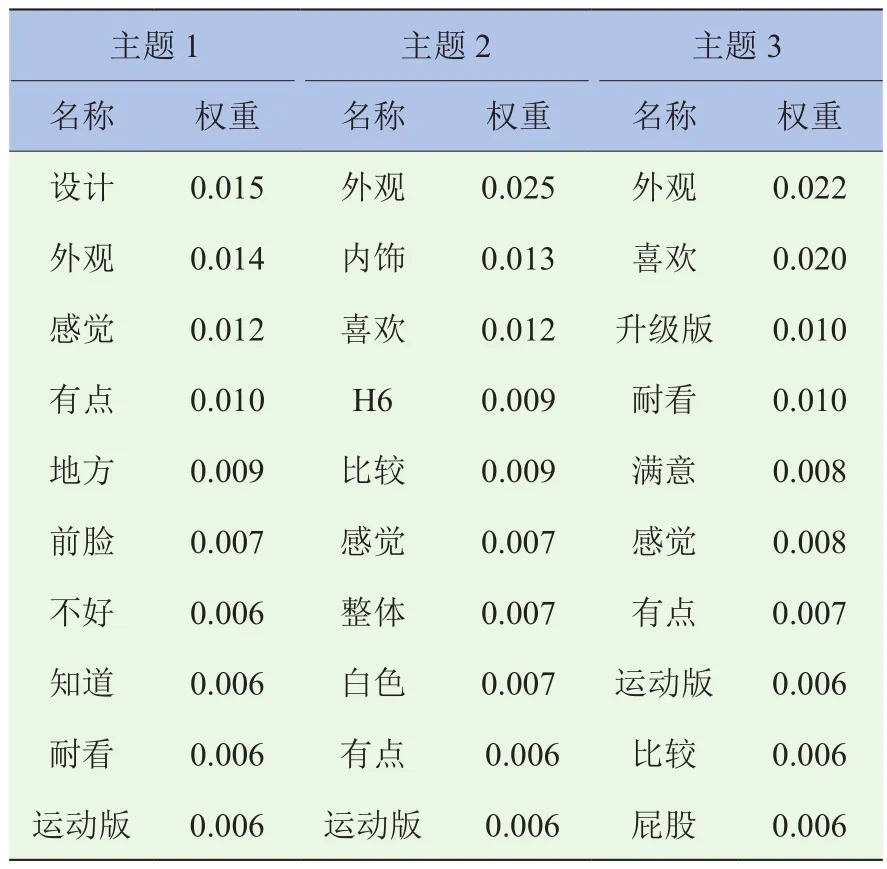
表6 哈弗H6负面评价潜在主题展示表
在语义网络分析时,选择经过ROSTCM6软件分析得出的正面情感结果和负面情感结果作为输入文本,进行社会网络和语义网络分析,通过软件的“提取高频词”,“过滤无意义词”,“提取行特征”,“构建网络”等步骤,得到语义网络矩阵,并启动NetDraw语义网络可视化软件,得到的语义网络正面分析结果和负面分析结果如图5所示。
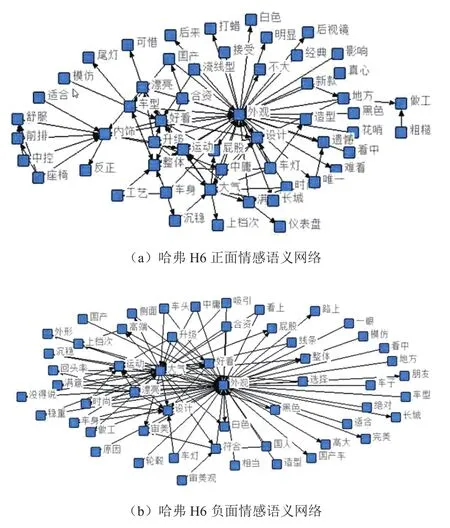
图5 语义网络分析效果图
由表5可知,对哈弗H6外观正面评价的主题1的高频词为外观、喜欢、大气、上档次、高端、满意、回头率和霸气等,主要反映哈弗H6外观高端大气上档次、用户喜欢满意、回头率高等;主题2的高频词关注点是和合资车相比较,不失霸气的设计,尤其是运动版较为满意;主题3中的高频特征词关注点主要是喜欢、满意、感觉漂亮等,主要反映哈弗H6外观漂亮,车主喜欢等。
由表6可知,对哈弗H6外观负面评价的主题1的高频词为外观、设计、前脸、不好等,即主题1反映的是哈弗H6的前脸设计不好;主题2的高频特征词主要是内饰、整体、感觉等,反映的是哈弗H6的内饰给人的整体感觉不好;主题3的关注点主要是升级版、运动版、比较和屁股等,反映的是哈弗H6的升级版、运动版和老版系列比较时,其车尾(屁股)设计有待改进等。
综合表5、表6、图5可以看出,哈弗H6外观设计的优势主要体现在高端、大气、霸气和漂亮等,反映的是车型的整体感性特征是大气的、用户喜欢的;而外观设计的吐槽点主要表现在内饰材料使用方面不满意、前脸和车尾设计难看、做工粗糙等。对哈弗H6后续换代设计的建议是在保持高端、大气的感性设计理念不变的基础上,对前脸和车尾要升级优化,并对内饰设计进行改进,主要改变内饰的使用材料或者增添内饰的高科技元素,提升内饰的档次和品位。
4 结束语
本文给出了一个针对汽车外观评论文本进行情感分析的算法和试验案例,并能针对某SUV车型的用户情感倾向挖掘出该车型外观的优点与不足,对于汽车企业获取用户心声,改进设计和决策提供了一种解决方案。后续的拓展主要是训练文本极性分析的机器学习模型,本文中的ROSTCM6软件虽然分析效率较高,但是针对带否定词如“没的说”、“不用说”、“不错”、“不输给”等的判断有一定误差,会将这些虽然带有否定词但是具有正面评价的文本判定为负面。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
学苑创造·A版(2022年4期)2022-06-18
阅读(快乐英语高年级)(2022年6期)2022-06-17
西部交通科技(2022年2期)2022-04-27
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
读者·校园版(2015年7期)2015-05-14
心理学报(2014年4期)2014-02-02
中学生英语·外语教学与研究(2008年4期)2008-03-18
