
从时频联合域提取客观参量建立声品质预测模型
2021-04-17 02:02左言言吴传刚
噪声与振动控制 2021年2期
孙 瑞,左言言,吴传刚
(江苏大学 振动噪声研究所,江苏 镇江212013)
声品质主观评价需要消耗大量的人力和时间,学者提出建立基于主观评价预测模型的客观评价法。目前声品质客观评价参数主要有基于物理声学和心理声学的评价参数[1-2]。文献[3]应用支持向量机建立基于心理声学参数的声品质预测模型,并将预测结果与多元线性回归模型进行对比,得出应用基于支持向量机的预测模型预测精度更高;文献[4]提出一种基于Adaboost算法的车内噪声声品质预测模型,以心理声学参数作为输入,主观评价值作为输出,经试验验证,该预测模型的预测精度较理想;文献[5]提出基于小波变换的冲击噪声声品质客观评价参数,并构建多元线性回归预测模型,结果表明该客观参数可以很好地反映冲击信号的特征。文献[6]建立基于心理声学参数的粒子群-广义回归神经元网络预测模型,用于变速箱壳体激励噪声声品质的预测;文献[7]利用集总经验模式分解技术提取传动系噪声声信号特征,建立经遗传算法优化的小波神经网络预测模型。由此可知,声品质的客观评价主要停留在基于心理声学参数构建预测模型上,仅考虑信号在时域或频域上的特征,声信号对人的影响反映不足,因而基于此参数建立的声品质预测模型的精度有待提高。
文中在时频和频域上对声信号进行分析,提取出新的客观参量,建立声品质评价模型。利用互补集成经验模式分解法(CEEMD)对声信号进行分解,再进行Hilbert变换(HT),并引入临界频带值对各信号的瞬时频率进行计权,计算各信号的计权能量值;然后将计权能量值作为声品质评价的客观参量,构建声品质预测模型。以混合动力汽车动力耦合机构处的噪声为研究对象,分别利用心理声学参数和基于CEEMD-HT 法得到的计权能量值建立声品质评价模型,将评价结果与主观评价结果对比,以检验基于CEEMD-HT法构建的声品质预测模型的精度。
1 时频联合域提取客观参量
1.1 理论基础
经验模态分解(EMD)[8-9]本质上是通过信号的特征时间尺度获得本征波动模式,实现对信号的逐层分解。EMD算法的具体分解步骤如下:
(1)对于原信号x(t),首先找出其所有的局部极大值和极小值,然后利用三次样条插值法形成上包络线u1(t)和下包络线u2(t),则局部均值包络线m1(t)可表示为:
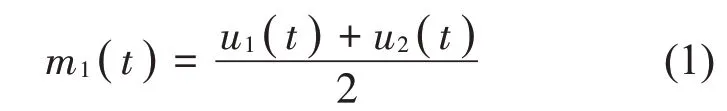
(2)将信号x(t)减去局部均值包络线m1(t),可得第一向量h1(t):

(3)判断h1(t)是否满足本征模函数(IMF)分量的条件。若不满足,则将h1(t)视为信号x(t),重复式(1)和式(2)的分解步骤直至得到满足IMF 要求的hb(t)。将hb(t)记作原信号的第一个IMF分量c1(t),则原信号的剩余量r1(t)可表示为如下形式:
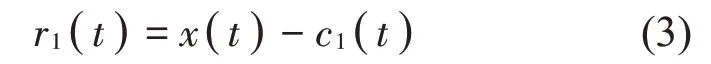
(4)对剩余量r1(t)做同样的分解,当第n阶残余信号rn(t)基本呈单调趋势或为一个常量时停止分解。最终可得到IMF分量。原信号x(t)可表示为如下形式:
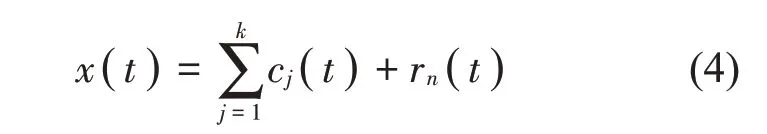
其中:cj(j=1,2,...,k)表示分解后的各阶IMF分量。
1.2 声信号的特征分析
采用CEEMD 技术对声信号进行分解,得到声信号的各阶IMF分量;然后利用HT 获得各阶IMF分量的瞬时幅值和瞬时频率,以此来分析声信号在不同时间尺度上的局部特征。具体操作步骤如下[10-11]:
(1) 在待处理的声信号中加入n组正负成对的高斯白噪声,得到2n个重构声信号。
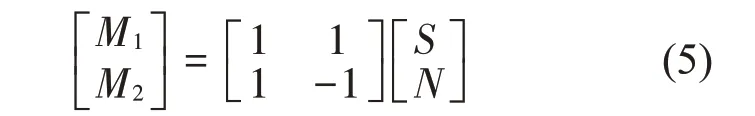
其中:M1、M2分别为加入正、负高斯白噪声后的信号;S为原信号;N为辅助高斯白噪声信号,且其幅值为原信号的0.2倍。
(2)分别对2n个重构声信号进行经验模态分解,对每个信号均可得到一组IMF分量cij。cij表示第i个重构声信号的第j阶IMF分量;
(3)将各信号相同阶数的IMF分量进行集总平均,求得原信号的IMF分量。
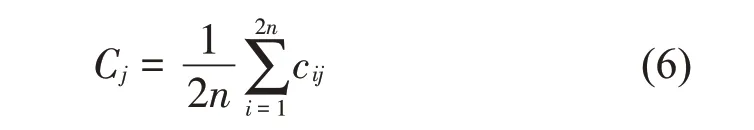
其中:Cj为原信号经过CEEMD 后的第j阶IMF分量。
(4) 对经CEEMD 分解得到的各阶IMF分量进行希而波特变换(HT):
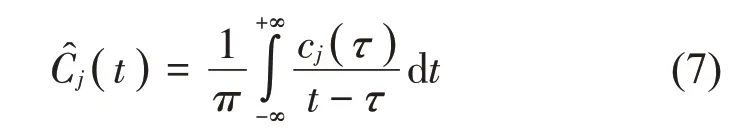
其中(t)为经CEEMD处理后第j阶IMF分量Cj的希尔波特变换。
(5)构造复信号Gj(t):
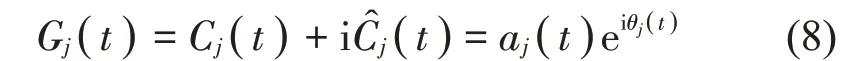
其中:aj(t)为Gj(t)的瞬时幅值,θj(t)为Gj(t)的瞬时相位。
(6) 计算各阶IMF的瞬时幅值aj(t)和瞬时频率fj(t):
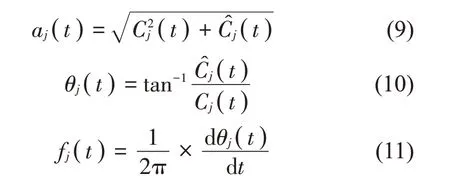
1.3 客观参量的提取
人的听觉系统具有掩蔽效应,但是当声信号的频率差超过阈值时,人耳可以辨别出不同频率信号的声音。Zwicker 等据此提出临界频带的概念,将20 Hz到20 000 Hz 内声信号的频率分为24个临界频带,每个相同临界频带内的声信号具有相同的临界频带值。信号的频率越高,其所在的临界频带值越大[12]。将瞬时频率所在的临界频带值作为计权值,以增强信号中高频成分的影响。然后通过对瞬时频率进行计权得到计权后的IMF分量,其计算公式为

式中:hj表示计权后的第j阶IMF分量,fj表示瞬时频率,zj表示fj所在的临界频带值。
接着计算计权后IMF分量的能量值,将计权能量值作为新的客观参量,其计算公式如式(13)所示:
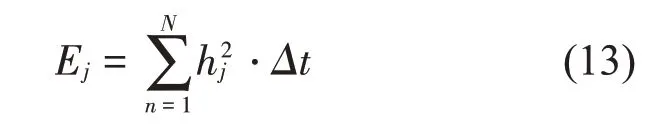
其中:Ej表示计权后第j阶IMF分量的计权能量值,N为离散后的信号点数,hj(t)为计权后的第j阶IMF分量,Δt为采样时间间隔。
2 声品质的评价模型
相关向量机(RVM)是一种基于贝叶斯框架构建学习机的稀疏概率模型[13],与支持向量机相比,RVM模型的泛化能力更强,准确率也更高[14]。设RVM模型的输出为
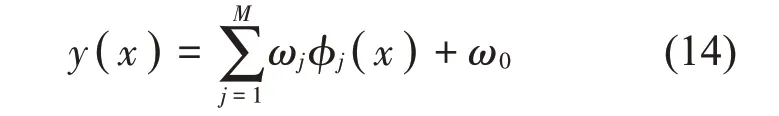
其中:{φj}表示模型的基函数,一般选择高斯函数作为基函数;{ωj}表示模型的权值。
然后利用最大似然法训练模型的权值{ωj},提高模型的泛化能力。权值ωj的先验概率分布为
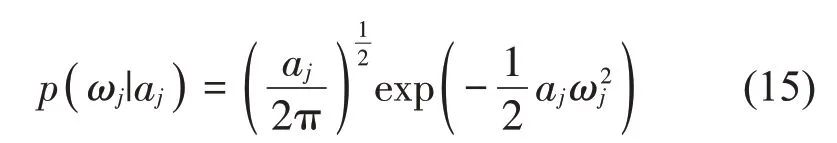
式中:aj表示决定权值{ωj}先验分布的超参数。
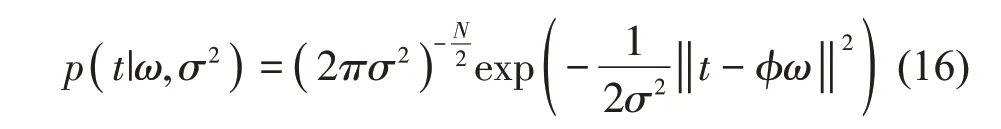
采用贝叶斯公式计算权值的后验概率分布:
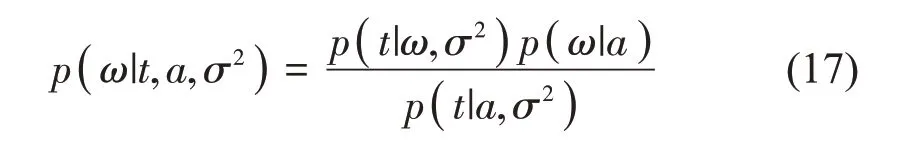
通过对权值变量进行积分训练目标值,并求得超参数的边缘似然分布:

式中:C表示协方差;A表示(a0,a1,...,aN)的对角矩阵。
若给定模型的输入值x,则模型输出的概率分布如式(20)所示,且其服从高斯分布:
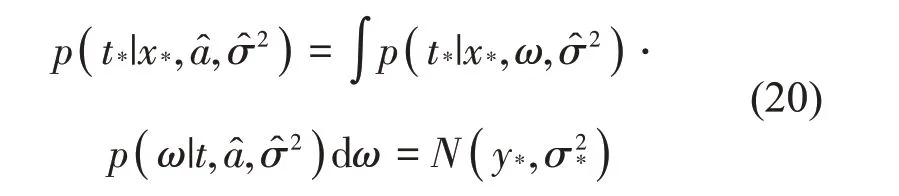
其中:y*表示预测均值:
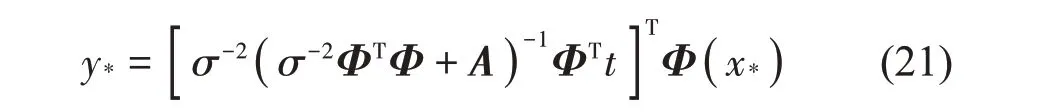
σ2*表示预测方差:
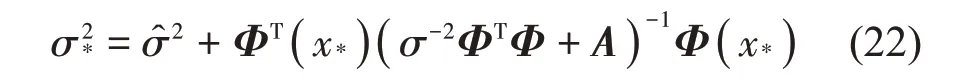
RVM很好地解决了模型的参数选择问题,具有较好的适用性,适合本研究事件的训练与预测。
3 应用实例
以混合动力汽车动力耦合机构处噪声为例,分别利用CEEMD-HT 法提出的计权能量值和心理声学参数建立声品质RVM评价模型,并将两模型的评价结果与主观评价试验结果进行对比,验证CEEMD-HT法的有效性。

表1 试验工况
3.1 噪声试验与声样本的获取
参考GB/T 18697-2002 标准,采用LMS 公司的SCADAS数据采集系统,并采用LMS.Test.Lab数据采集软件,进行某混合动力汽车的噪声试验。在混合动力汽车动力耦合机构正上方布置一个传声器,采集动力耦合机构处的噪声信号,声信号的采样时间为30 s。试验工况如表1所示,包括不同车速下的电机驱动工况、发动机驱动工况以及混合驱动工况。
对采集到的噪声信号进行处理,剔除有问题的噪声信号,再利用Artemis软件选取声信号中波形变化较平稳的时间段,截取长度为5 s的声样本,最终得到54个声样本。通过Artemis软件对54个声样本进行等响处理,避免在主观评价试验中各声样本之间响度差异所造成主观感受的偏差[15]。
3.2 声品质的主观评价
声品质的主观评价是评价主体根据自身的听觉感受,按照评价标准对声信号进行打分[16-17]。
3.2.1 主观评价试验设计
进行主观评价试验时采用耳机和扬声器在试听室内播放和收听声音样本,其背景噪声符合标准。本次主观评价试验选择21 位振动噪声控制方向的在校研究生作为评价主体,以烦躁度作为评价指标,采用成对比较法对采集的声样本进行主观评价。
采用成对比较法时先将声样本成对组合,然后评价主体根据事先规定的评价标准(烦躁度)对这些声样本打分,此种方法适合没有评价经验的人员且评价结果较准确[18]。
3.2.2 主观评价试验的结果分析
主观评价试验结束后,使用SPSS软件计算评价主体之间的相关系数,将相关系数的算术平均值作为评价主体的相关系数值,相关系数值越高表示该评价主体的稳定性越好[19],如表2所示。
由于表2中第6个评价者、第15个评价者和第18个评价者的相关系数低于0.75,为保证实验的准确性应将其评价结果删除。再对各个声样本的打分进行集总平均,并对结果进行归一化处理,最终得到各个工况声样本的主观评价值,如表3所示。本次试验中主观烦躁值越高,动力耦合机构处的声品质越差。
3.3 声品质的客观评价
3.3.1 心理声学参数的计算
选取响度、波动度、尖锐度、音调度和粗糙度5个心理声学参数用于声品质的研究。在对采集到的声样本进行预处理后,使用Artemis软件计算声样本的心理声学参数值,计算得到的54个声信号的心理声学参数值见表4。
3.3.2 计权能量值的计算
利用Artemis中的滤波器对噪声信号进行滤波,滤掉低于人耳听阈的低频噪声。接着对处理后的声样本进行CEEMD 分解,共加入200个高斯白噪声,集总平均次数为200次,得到声样本的各阶IMF分量,图1为第一个声样本的各阶IMF分量。从图中可以看出IMF分量的能量值随阶数的上升越来越小,波动也趋于平稳。然后使用相关系数r分析各阶IMF分量和原信号间的相关程度,具体的计算公式如下:

表2 评价主体斯皮尔曼相关系数
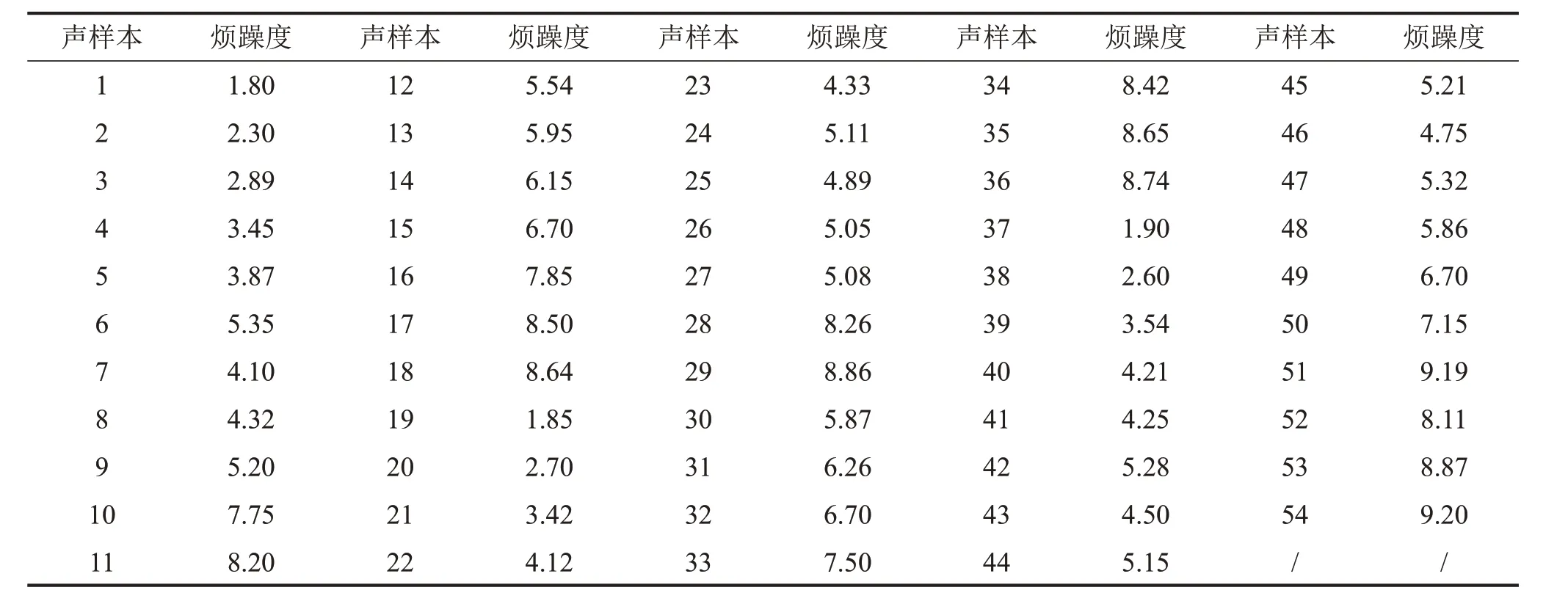
表3 声样本主观评价值
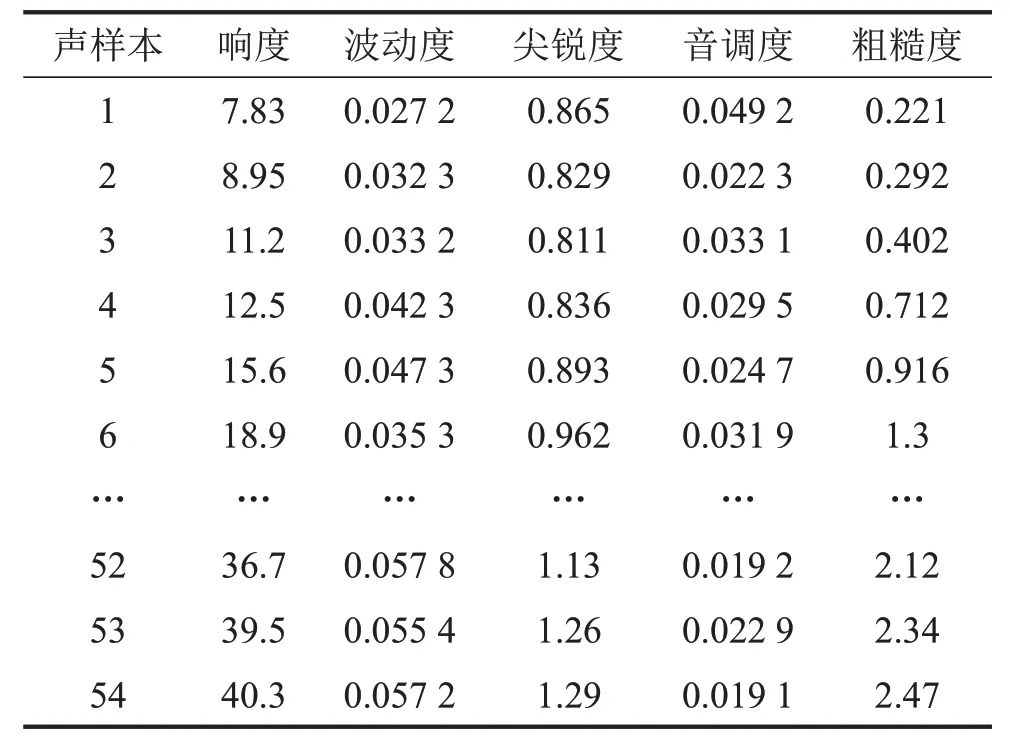
表4 声样本的心理声学参数
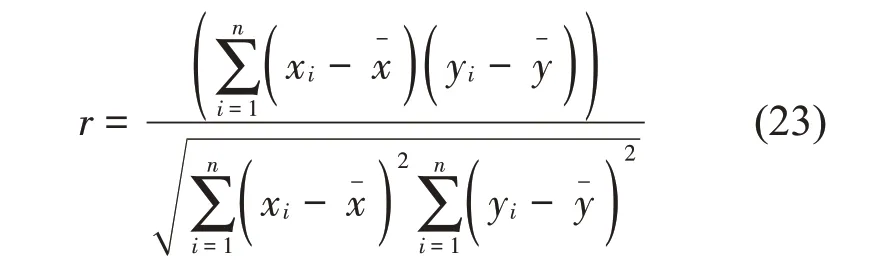
其中:x表示IMF分量,y表示原信号,和分别表示IMF分量的平均值和原信号的平均值。相关系数r值较大,表示分解的结果能反映出原信号的更多特征。表5为稳态工况声样本经过CEEMD 分解后的各阶IMF分量之间的相关系数,从表5中可以看出从第14阶开始声样本的IMF分量值与前几阶的数值相差一个数量级,则14阶往后的IMF分量是趋势项,可忽略。
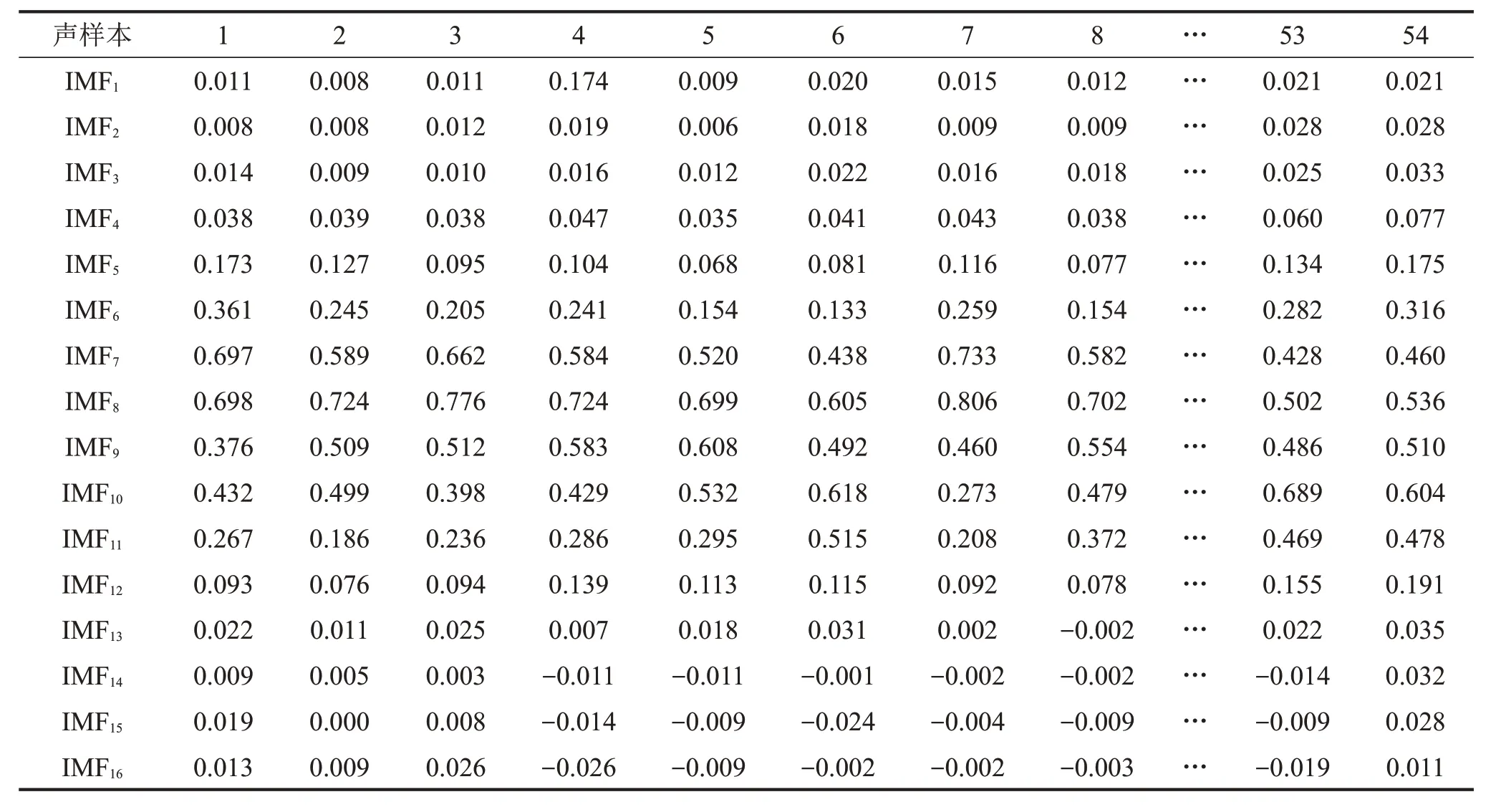
表5 各阶IMF分量和原信号的相关系数
对相关系数较高的7个IMF分量(IMF5、IMF6、IMF7、IMF8、IMF9、IMF10、IMF11)进行HT,得到相应的瞬时频率,分析瞬时频率主要分布的频率带,对应临界频率带,可以得到各阶IMF的临界频率值。根据式(14)和式(15)对这7个IMF分量进行临界频带计权,得到计权后的IMF分量和相应的计权能量值。各声样本计权能量值的计算结果如表6所示。
4 声品质评价模型预测精度分析
为对比依据心理声学参数和依据CEEMD-HT法提出的计权能量值所建模型的预测精度,这里建立两个RVM评价模型,并将评价模型的预测结果与声品质主观评价试验结果进行对比。评价模型1以计权能量值作为RVM模型的输入,以主观烦躁度值作为RVM模型的输出;评价模型2以5个心理声学参数值(响度、波动度、尖锐度、音调度、粗糙度)作为RVM模型的输入,以主观烦躁度值作为RVM模型的输出。声品质的主观评价试验和两个RVM 评价模型均使用同样的声样本集(即上文提到的54个声样本)。
选择第1~45个声样本为RVM模型的训练样本,第46~54个声样本为RVM模型的预测样本,相关向量机模型的预测结果与实际主观评价值的比较如图2所示。由图2可知,基于两种客观参量建立的相关向量机模型的预测结果与主观评价试验结果有较好的一致性,且第1个模型的预测值与主观评价值更接近。第1个模型预测值的最大相对误差为6.72%,平均相对误差为3.14%,第2个模型预测值的最大相对误差为8.98%,平均相对误差为6.64%,如表7所示。这是因为由CEEMD-HT 法提取的计权能量值不仅考虑声信号在时域上和频域上的特征,还考虑人的听觉特性,增强了原信号中高频成分的影响。由此可得基于CEEMD-HT 提取的计权能量值建立的声品质评价模型预测精度更高,也验证了从时频联合域上提取噪声信号特征的方法能更客观地体现声信号对人的主观感受的影响,可提高声品质评价模型的准确性。
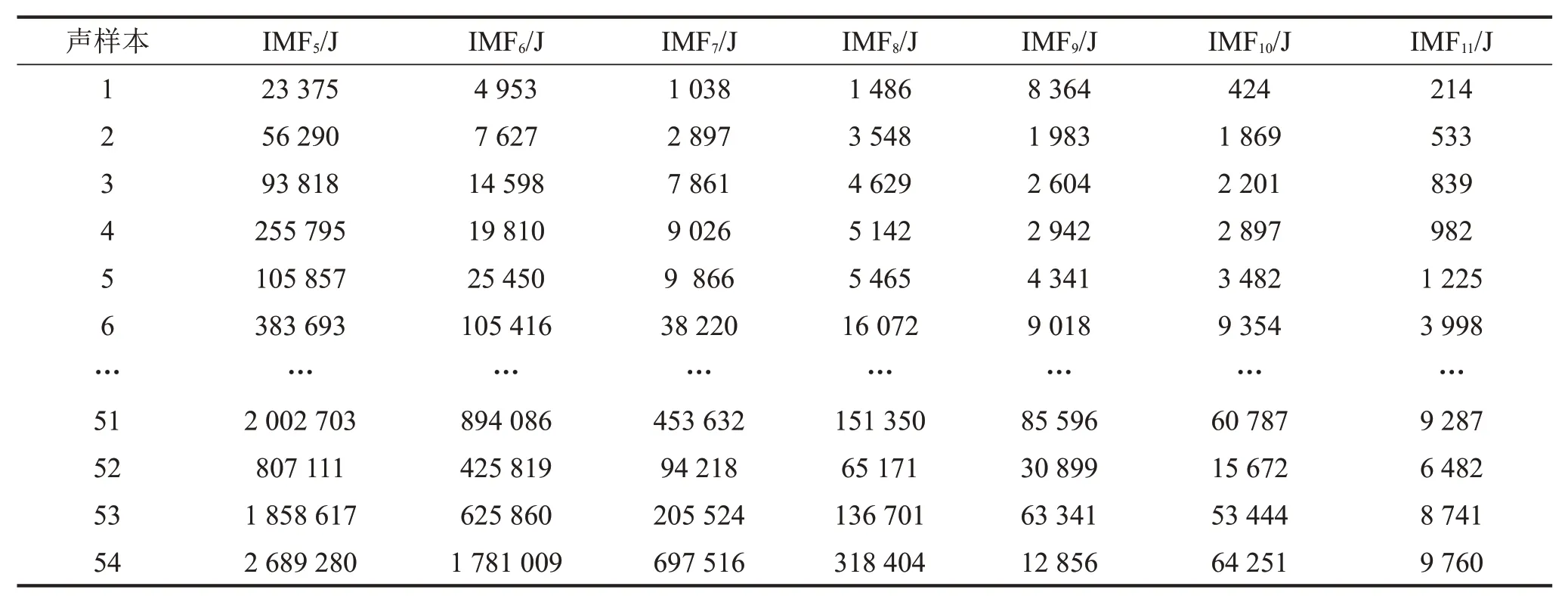
表6 各阶IMF分量的计权能量值
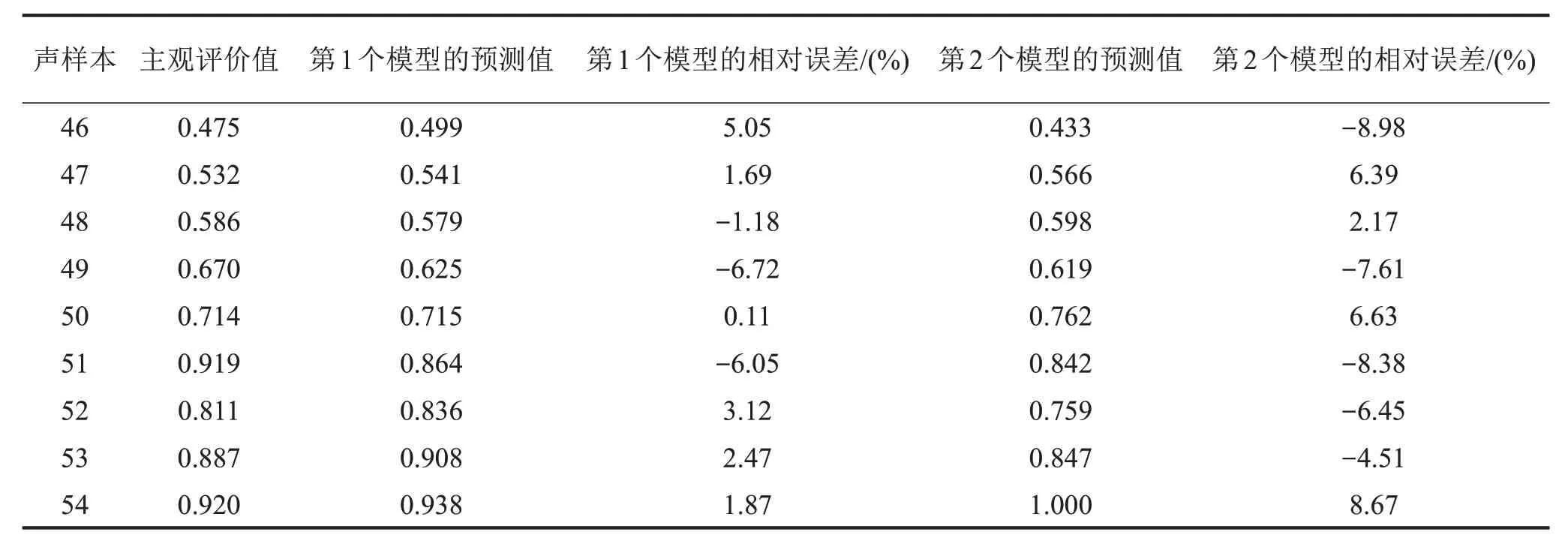
表7 RVM评价模型的预测误差
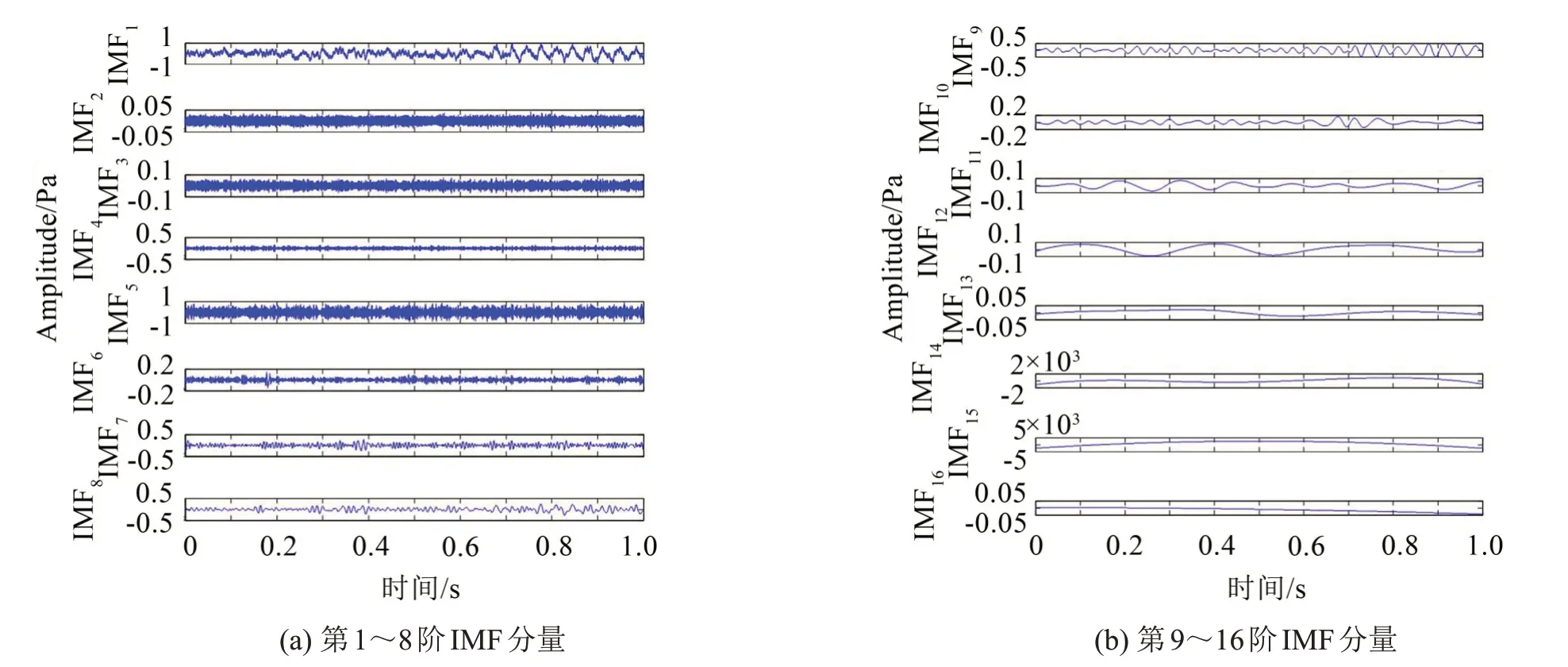
图1 第1个声样本各阶IMF分量
5 结语
本文提出一种从时频联合域上分析声信号特征、提取声品质客观参量、构建声品质评价模型的方法。通过具体的实例验证可以得出以下结论:
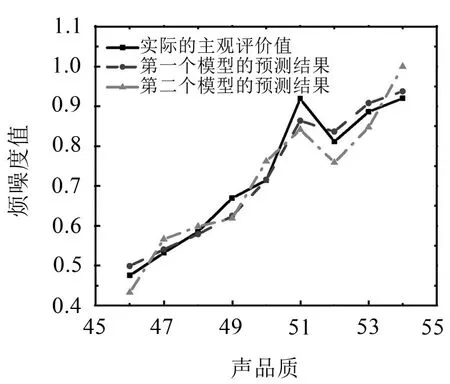
图2 声样本评价模型的评价结果
(1)基于CEEMD 和HT的客观参量提取方法将瞬时频率所在的临界频带值作为计权值,增强了信号中高频成分对整个信号的影响,更客观地体现声信号对人的影响,保证声品质评价模型的准确度。
(2)基于CEEMD-HT法建立的声品质评价模型的预测值与实际主观评价值间的相对误差更小,说明了基于从时频联合域提取的计权能量值建立的RVM 评价模型的预测结果比基于心理声学参数建立的评价模型更加符合人的主观感受。
从最终结果可以看出该方法的有效性和优越性,因此这种基于时频联合域提取声品质客观参量的方法不仅可以减少主观评价试验中人力和物力的投入,降低试验成本,还可以更客观地体现声信号对人的影响,提高声品质评价模型的预测精度。
猜你喜欢
农业知识(2022年9期)2022-10-13
数学杂志(2022年4期)2022-09-27
中共云南省委党校学报(2022年1期)2022-04-26
上海房地(2021年12期)2021-05-23
北京航空航天大学学报(2020年3期)2021-01-14
小学生优秀作文(低年级)(2020年4期)2020-07-24
山东冶金(2018年5期)2018-11-22
法律方法(2018年2期)2018-07-13
湖南农业(2017年1期)2017-03-20
经济与管理(2016年2期)2016-12-01
