
能源互联网背景下供应链智慧监控与预警研究
2021-04-16 14:48:46林江刚
机械设计与制造工程 2021年3期
林江刚
(江苏省工程咨询中心,江苏 南京 210003)
能源互联网是进入21世纪后在“互联网+”能源的基本架构上搭建起来的,将发电、输变电、能源燃料供应等各个领域的物联网数据进行充分整合,最终形成的互联网体系。能源互联网的本质是能源大数据,其功能实现来自对大数据的深度挖掘和人工智能技术。在能源互联网支持下,各电厂的能源燃料配送、各种相关设施的耗材和设备配件供应,以及相关的供应链保障措施,在理论上可以得到大数据支持,即保证整个相关供应链体系可以得到有效监控并提供数据预警。
文献[1]研究了将能源互联网的数据融合用于解决能源产业的运行效率,其中实现智慧供应链是该文献的重要展望方向;陈积光等[2]研究了在电力系统物联网基础上搭建智慧供应链的有效途径;贾景姿等[3]在供应链运作参考模型(supply-chain operations reference model,SCOR模型)基础上对能源互联网体系进行了优化,并使其大数据得到了更深度的挖掘应用;王栋等[4]研究了将区块链的智能合约技术应用到能源互联网智慧供应链的实现过程,实现了去中心化的智慧供应链模式。
可以看出,2015年前能源互联网及其应用仍处于概念研究阶段,该技术在当前技术条件下仍为“互联网+”能源体系中的前沿课题,但因为早期单项物联网的硬件建设已经初具规模,所以能源互联网的相关功能建设推进速度较快[5]。本文对能源互联网支持智慧供应链的功能实现进行研究,有助于进一步完善能源互联网的整体研究[6]。
1 能源互联网与智慧供应链技术基础分析
1.1 能源互联网的技术基础
众所周知,能源互联网的本质是对与能源相关的物联网、互联网数据进行融合。物联网数据通过网桥设施与公共互联网整合,同时在各相关互联网数据中心(internet data center,IDC)的应用程序接口(application programming interface,API)服务器之间构建逻辑连接。而能源互联网本身的云计算架构需要在专用IDC中构建,用于控制能源互联网本身的数据资源并提供相应的云计算功能,如图1所示。
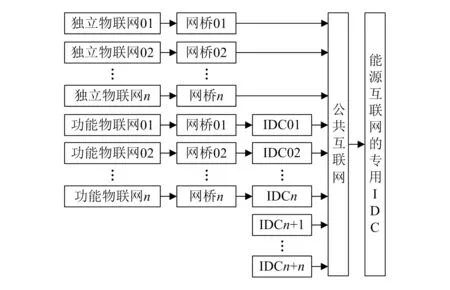
图1 能源互联网的数据来源及数据采集模式
图1中,独立物联网数据通过协议转化网桥与公共互联网连接,特定IDC下的功能物联网将数据整合到本地IDC后,IDC数据与公共互联网连接,部分不涉及物联网的相关功能IDC机房的相关数据直接与公共互联网连接,而能源互联网的专用IDC设施从公共互联网中获得相关数据,数据在各自API服务器之间使用加密传输构建逻辑连接[7]。
能源互联网专用IDC的构建模式与传统IDC并无显著差异,其数据仓库部分、计算中心部分、云计算服务支持部分、任务管理部分、防火墙及网络安全部分、路由及访问行为控制部分均使用常规布局;与其他相关IDC和网桥设施之间的数据传输,使用基于API服务器搭建的加密逻辑连接构成虚拟子网,以满足在公共互联网上传递弱脱敏涉密数据的传输需要[8]。在王楠[9]对于基于区块链实现可搜索加密公平性的研究中可以看出,使用区块链加密技术或使用其他对称密钥加密等手段,可以保障数据的安全性。
1.2 智慧供应链的技术基础
智慧供应链的基本架构能否不断地运行,关键在于物资的物流和交易过程,在交易过程上构建交易平台、物资数据平台、物流追溯平台、供应链金融平台,对于智慧供应链的运行起到了极为关键的作用。智慧供应链可以通过相关数据来判断相关物资的仓储量和需求量的关系,且可以实现对相关物资和供应链资金的调用,如图2所示。
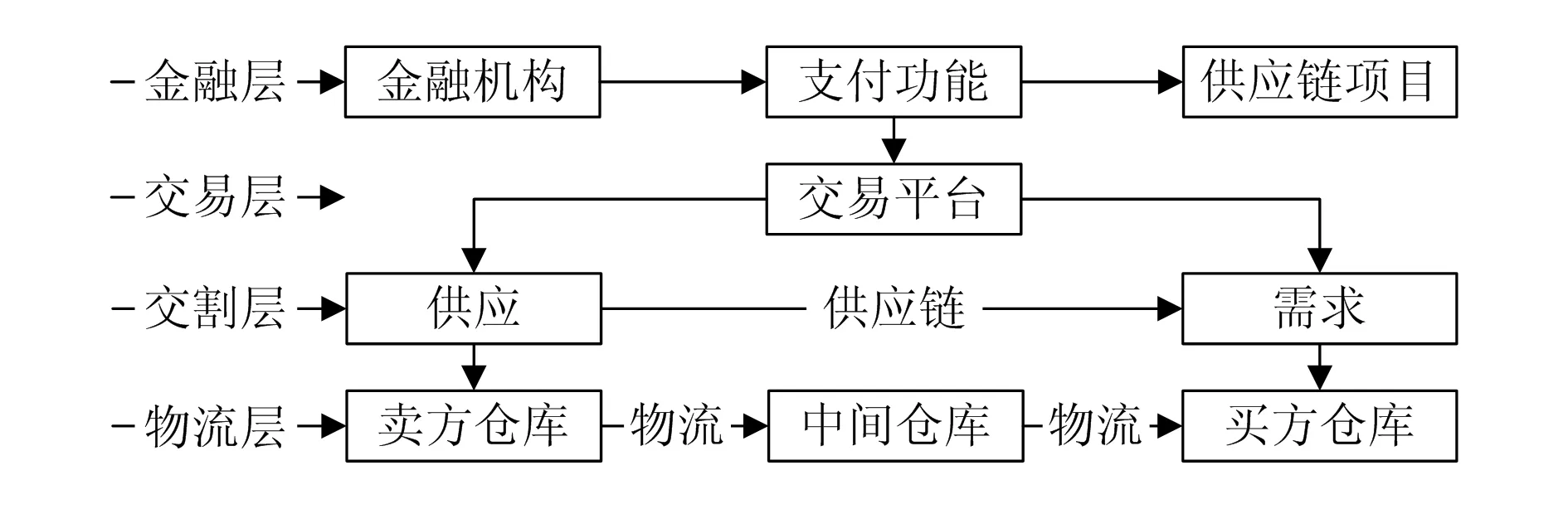
图2 智慧供应链的基本构成图
图2中,以相关物资的实际流通过程构成物流层,相关的物联网体系包括仓库管理系统、物流管理系统、进销存系统、内部市场化系统等。该体系通过获取仓库内的相关物资的数量推算其用量,服务于物流层的各个相关功能。金融层中相关账户的授信额度和账户余额,也作为信息反馈给智慧供应链相关功能模块。智慧供应链系统的数据来源见表1。

表1 智慧供应链的数据来源汇总表
2 智慧供应链的数据分析算法
2.1 数据回归及曲线估计策略设计
五阶多项式回归在大部分数据分析平台中均可得到应用,包括金山的VBS数据分析、Python的数据分析、LAMP的数据分析等平台。这些数据分析平台将数据回归和曲线估计过程进行了封装,所以本文仅对数据回归及曲线估计的策略进行分析。五阶多项式在1/10周期内拥有较高的数据趋势信度,在1/100周期内拥有较高的数据量值信度,即在1 000步长的离散数据中,使用五阶多项式策略进行曲线估计,向前延伸100步长,其数据趋势仍有较高信度,向前延伸10步长,其数据量值仍有较高信度。
五阶多项式的基函数为:
(1)
式中:Y为最终估计的曲线;M为原数据的总步长数;Aj为在第j阶多项式项中的待回归变量;Xi为第i个输入数据。
为充分做出数列的曲线估计,提升最终的数据量值估计精度和数据信度,可以采用原值-差值法进行双向回归和数据拟合。即对Xi序列进行回归的同时,使用ΔXi=Xi-Xi-1构成差值序列,并对差值序列同步进行曲线估计。实际的曲线估计预测值使用下述平差算法进行数据拟合:
(2)
式中:Y′(Xi)为平差后的最终估计值;Y(Xi)为第i个步长的量值估计值;ΔY(Xi)为第i个步长的差值估计值。
式(2)为迭代公式,经过深度迭代后,该估计值将更加精确。表1中买方仓库的物资余量、买方仓库的物资调用量、买方支付账户资金余额、买方授信余额等信息,均需要进行曲线估计分析并作出预警。
2.2 数据预警的模糊矩阵设计
为每个数据设定一个预警红线,即该值低于或者高于该预警红线时,代表该数据应被管理干预。低于红线预警的数据,被称作上部控制数据;高于红线预警的数据,被称作下部控制数据。其中,物资余量、支付账户资金余额、授信余额等,为上部控制数据,物资调用量数据为下部控制数据。为使数据预警更加具有前瞻性,对数据红线进行衍生层次划分,见表2。
表中X为预警红线值,如1.0X就是1.0倍预警红线值。针对该红线衍生层次布局,对下部控制方法和上部控制方法设定数据预警模糊矩阵,可得表3和表4。表4中D为曲线估计结果的导数值等效斜率。
在该模糊矩阵策略下,可以实现对表1中买方仓库的物资余量、买方仓库的物资调用量、买方支付账户资金余额、买方授信余额等信息的曲线估计结果进行一定前瞻周期的数据预警。其算法数据流如图3所示。

表2 数据红线的衍生层次布局设计表

表3 下部控制方法模糊控制矩阵设计

表4 上部控制方法模糊控制矩阵设计

图3 本文算法的数据流图
3 数据仿真验证及讨论
3.1 本文系统的数据仿真验证
本文选择2个变电站、2个燃煤发电厂、2个风光一体化新能源电厂共6个能源互联网用户的设备库智慧供应链历史数据作为数据仿真验证原始数据,按照1/10的数据划分,使用前90%数据作为实验数据,使用后10%数据作为验证数据。数据的曲线估计结果偏差程度的仿真结果详见表5。

表5 数据仿真准确率结果表 %
从表5可以看到,对1/100步长比的短周期数据估计值,数据精度控制在±1.00%以内;对5/100步长比的中长周期数据的估计值,数据精度控制在±2.00%以内;对10/100步长比的长周期数据的估计值,数据精度控制在±6.00%以内。如此可以认为,本文设计的算法在实际分析过程中,在1/100步长比的短周期数据和5/100步长比的中长周期数据中,数据精度处理拥有较高的参考价值;而在10/100步长比的长周期数据中,对数据变化趋势有较高的参考价值。
在10/100步长比条件下,如果数据的曲线估计可用的原始数据时间设定为2 a,步长为1 d,那么,可用原始数据步长数为730条的记录,其短周期估计能力为7 d,中长周期估计能力为35 d(约1月),长周期估计能力为73 d(约2.5月)。由此可知,该估计能力可以基本满足大部分供应链的实际智慧运行需求。
3.2 本文系统的应用场景
本文系统中对买方库存的曲线估计及数据预警,可以帮助能源系统的运行管理单位及时制定产品的采购计划,防止出现相应问题后因为备用物资储备不足而导致系统维护延期,更可以避免因过度储备相应物资造成的资金浪费。
在对买方支付账户及相关授信进行数据预警时,一方面可以帮助能源系统的运行管理单位及时调整资金规划,确保供应链的资金供应,选择对应金融机构的资金服务项目;另一方面也可与合作金融机构合作,实现对特定账户的主动授信管理,完善相应的金融服务产品和金融服务体系。
在本文系统的后续延伸开发中,还可以引入其他数据的采集和分析过程,实现更多的智慧供应链应用。
3.3 相关算法的选择原则
如图3所示,本文在选择算法时,并未采用机器学习相关算法。这是因为机器学习的统计学本质就是数据的深度迭代回归,而本文不仅采用了顺序程序下的深度迭代差值分析和平差计算,同时还兼用刚性算法完成对数据的曲线估计。这是由于机器学习过程需要更多的数据仓库存量数据和更大算力的浮点工作站提供支持,且数据响应周期较长,硬件占用量较大。
本文对于相关算法的选择过程中,采用了较少的浮点工作站算力,实现了在最小IDC规模下更高精度的数据曲线估计和迭代回归分析。但是在实际算法设计过程中,本着足够但不过度冗余的算法设计理念,可以使用最小硬件条件和数据生产环境,实现需求的功能。本文的IDC系统占用的硬件较少,可以与用户机构管理中的其他相关IDC设施一起实现机房物理空间的共享,节省了电力、空调等其他IDC附属设施的投资。该算法选择过程本身也是供应链优化的重要组成部分。
4 结束语
能源互联网是一种新型的“互联网+”能源的实现方式,也是重要的战略互联网资源,其目的是为了保障能源系统的充分数据融合,同时实现更丰富的应用层功能,在各项功能的应用下提升能源系统相关企业和机构的“互联网+”行业生态优化效果。本文采用的算法实现了长周期数据预警的基本功能,可以在现有能源互联网硬件基础上实现精准的智慧供应链数据支持。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30 06:25:30
小学科学(学生版)(2019年12期)2020-01-06 07:29:02
今日农业(2019年12期)2019-08-13 00:50:02
消费导刊(2018年10期)2018-08-20 02:57:10
现代园艺(2017年22期)2018-01-19 05:07:01
瞭望东方周刊(2016年8期)2016-03-12 23:33:52
火控雷达技术(2016年3期)2016-02-06 02:30:27
河北科技大学学报(2015年5期)2015-03-11 16:16:37
小说月刊(2014年11期)2014-04-18 14:12:28
电测与仪表(2014年2期)2014-04-04 09:04:00
