
基于BERT的短文本相似度判别模型
2021-04-13 08:46方子卿陈一飞
电脑知识与技术 2021年5期
方子卿 陈一飞
摘要:短文本的表示方法和特征提取方法是自然语言处理基础研究的一个重要方向,具有广泛的应用价值。本文提出了BERT_BLSTM_TCNN模型,该神经网络模型利用BERT的迁移学习,并在词向量编码阶段引入对抗训练方法,训练出包括句的语义和结构特征的且泛化性能更优的句特征,并将这些特征输入BLSTM_TCNN层中进行特征抽取以完成对短文本的语义层面上的相似判定。在相关数据集上的实验结果表明:与最先进的预训练模型相比,该模型在有着不错的判定准确率的同时还有参数量小易于训练的优点。
关键词:词向量模型;自然语言处理;短文本相似度;卷积神经网络;循环神经网络
Abstract: Short text representation methods and feature extraction methods are an important direction of basic research in natural language processing, and have a wide range of applications. This paper proposes the BERT_BLSTM_TCNN model. The neural network model uses BERT's transfer learning and introduces an adversarial training method in the word vector encoding stage to train sentence features that include the semantic and structural features of the sentence and have better generalization performance, and combine these The feature is input into the BLSTM_TCNN layer for feature extraction to complete the similarity determination on the semantic level of the short text. The experimental results on the relevant data set show that: compared with the most advanced pre-training model, this model has a good judgment accuracy rate and also has the advantages of small parameters and easy training.
Key words: word embedding model; natural language processing; short text similarity; convolutional neural networks; recurrent neural networks
近些年來随着个人计算机的普及和各种网络信息技术的快速进步,数字化的文本数量也随之呈现爆炸式的增长。其中很大一部分是短文本,如微信、微博等社交网络上的信息和博文、京东、淘宝等网络商城上关于出售商品的评价、电子政务平台里的群众意见反馈等。虽然数据量的激增对现行的信息处理系统是一种挑战,但大数据的出现也使得新方法的研究成为可能。如何将这些语料资源进行筛选分类,使之成为有用的、真正有价值的素材,成为最需要解决的核心问题。文本的相似度判定是自然语言处理领域中的一个基础任务,研究准确快速的相似度判定方法对信息的初步筛选分类和更进一步的处理都有重大意义。
文本相似度判定可以被看成是一种特殊的文本分类任务,即一个二分类(相似或者不相似)问题。近几年的机器学习尤其是深度学习快速发展也使得其成为研究文本分类的一个热门方向。目前深度学习中主流的神经网络模型结构有卷积神经网络(CNN)和循环神经网络(RNN)两种。卷积神经网络在提取特征方面具有不错的效果并首先在图像领域取得突破,然后逐步应用于文本领域。Kim Y[1]首次将卷积神经网络应用于句子分类任务的模型设计中,并通过一系列实验证明了方法的有效性。Lei等[2]为了使CNN更好地适应文本处理,在标准卷积层基础上进行非线性化改造。Wang等[3]利用聚类算法进行语义扩展,再通过CNN进行分类。Joulin等[4]将训练好的词向量进行加权求和形成可以良好表示句子的句向量。循环神经网络能够很好地处理任意长度的序列并捕获上下文信息,LSTM(长短期记忆网络)是循环神经网络的一种改进模型,其具有能够存储上下文信息的特点。Arevian[5]在实际文本分类任务中应用了循环神经网络。Yang Z等[6]在LSTM的基础上通过引入了注意力机制进行改进并在文本分类任务上获得了不错的效果。Tang等[7]在处理情感分类任务时结合使用了卷积神经网络和门控神经网络来进行文本表示。Zhou等[8]使用卷积神经网络对向量化的词语进特征抽取后输入长短时记忆网络形成句子的表示。Lai等[9]在使用RNN构建文本表示后直接进行最大池化操作以获取最有效的分类信息。上述研究表明CNN与RNN(尤其是LSTM等改进模型)已经在文本分类领域取得一定的进展,利用深度学习的方法构建模型表示文本和文本相似度判定,已经被证明可以获得了良好的效果。
如何将短文本的信息更加有效的表示是进行相似句对判定的基础。基于统计学知识的文本表示模型等模型虽然简单有效,但是在处理短文本时由于本身的维度过高和数据稀疏的问题使得其无法更进一步提升。2013年,Mikolov等[10]人提出了基于word embedding(即词嵌入方法)的word2vec模型。相比于其他文本表示方法word2vec不仅可以从根本上解决了“维度灾难”问题,训练获得的向量还能够在语义层面上体现词间的关系 [11]。用这种方法训练出来的词向量,能从根本上来提升文本分类任务的效果。ELMo[12]和BERT[13]两种最新的词向量模型在2018相继被提出。尤其是后者,刚一问世就在多个自然语言处理任务上取得了突破。目前,BERT预训练模型由于其灵活的训练方式和不错效果,在许多任务中被深入的研究和应用。因此,在一系列BERT预训练模型中选用小参数量的BERT-base作为模型的向量编码层,采用了迁移学习中fine-tune(微调)的方法来调整预训练模型,使得训练出来的模型可以更好地适应金融领域的短文本相似句对判定任务。
1 BERT_BLSTM_TCNN模型
基于BERT预训练模型提出了BERT_BLSTM_TCNN模型,该模型主要由词嵌入阶段的BERT-base层和用于特征抽取的BLSTM_TCNN层两大部分组成。将文本预处理后的相似句对,对输入BERT-base层。在词嵌入阶段利用BERT-base预训练模型并引入对抗训练的FGM(快速梯度方法)训练相似句对进行词向量编码,再将训练好的[CLS]向量输入进入BLSTM_TCNN层,该阶段主要对其进行特征抽取,过滤掉对相似度判定任务没有帮助的特征,使得效果相比于直接利用BERT-base模型连接全连接层(Dense层),在相似句对判定表现上有所提高。BERT_BLSTM_TCNN模型结构如图1所示。
1.1文本预处理
文本预处理是进行词嵌入之前的重要步骤,对词嵌入生成的向量有较大的影响。中文文本与拉丁语系文本不同的是,中文文本中既没有空格作为天然分词符号,同时也存在大量的单字成词现象。所以使用分词的方式处理中文短文本虽然可行,但是由于中文词语数量巨大,如果对其进行向量化则需要大量相关语料,同时也容易导致维度灾难。对于中文短文本来说,基于字的编码方式直接利用BERT迁移学习进行向量化已经被实践证明是十分有效的。
经过对数据集的分析,实验所用数据集较为干净且由于大多数句子为问句,所以在句尾一般包含更多的有效信息。因此在数据预处理阶段,主要工作是对数据集中的长句进行处理。因为长句包含的信息干扰较多,这给其核心含义的提取增加了难度,所以对于一些长句需要进行截断操作来限制其长度从而达到消除干扰的目的,提高文本表示的效率。
1.2 BERT-base层
将预处理后的相似句对进行拼接,在拼接时在首位添加[CLS]向量和两句之间增加[SEP]向量,并进行相应的初始化后输入BERT预训练模型。BERT采用了Transformer进行编码,预测词或者字的时候通过在训练中引入了Self-attention(自注意力)机制 [14]双向综合的考虑了上下文特征,这样可以使训练出的句向量更加准确的获得语义层面的信息(Token embeddings)。同时BERT还通过判断给定的两个句子是否是连续的方式捕捉句子级别的特征(Segment Embeddings)。此外BERT还通过对句中每个字符独立编码的设计,在训练后可以获得字符间相对位置的信息(Position embeddings)。最后得到的句向量为Token embeddings(包含词或者字的信息)、Segment Embeddings(包含句子和句间信息)和Position embeddings(包含位置信息)三者相加的结果。该向量可以直接作为相似句对的表示输入后续的BLSTM_TCNN层完成特征提取。
1.3 对抗学习生成对抗样本
对抗训练是通过正则化的手段增强模型的抗干扰能力的一种训练技巧,目前已经有多种算法可以实现。其目的是通过对攻击样本的构造,让模型在不同的攻击样本中训练得到较强的识别性。选择在Token embeddings阶段引入Fast Gradient Method(快速梯度方法,FGM)[15]技术来生成对抗样本并加入训练集中一同训练,使得训练得到的模型拥有识别对抗样本的能力,其增加的扰动为:
通过在训练中添加扰动生成对抗样本并输入,可以帮助优化模型参数来提高鲁棒性,从而实现对干扰的防御。实验结果显示,在Token embedding阶段进行对抗扰动能有效提高模型的性能。
1.3 BLSTM_TCNN层
长短时记忆网络(LSTM)是一种特殊的RNN,其既保持了传统RNN能够接受任意长度序列的输入,又规避了传统RNN存在的梯度消失和梯度爆炸的缺陷。双向长短时记忆网络(BLSTM)则在原有基础上加强了上下文的关联性,实际应用中证明有着更好的效果。利用卷积神经网络(CNN)进行卷积和池化操作来提取对文本相似度判定任务有用的特征,来提高准确率。通过对BLSTM_TCNN设计和构建,在使用BERT-base预训练模型进行文本表示后将BLSTM与CNN相结合进行特征抽取,使之更好地适应短文本相似句对判定任务。
BLSTM_TCNN模型主要由两大部分组成:双向长短时记忆网络(BLSTM)和文本卷积神经网络(TCNN)。其中,BLSTM 层捕捉输入的句向量中可能相关的上下文信息,TCNN层用于筛选和提取对相似判定有效的特征。
1.3.1 BLSTM
前向LSTM和后向LSTM分别捕捉输入序列的上下文信息,二者之间没有信息交換,仅在输出时将二者进行拼接,形成最终的输出。其对应转换函数公式如下:
1.3.2 TCNN层
卷积神经网络最先应用于计算机视觉领域,其优点是可以很好地提取对象的局部特征,比如相同的一个物体,虽然可能周边环境发生改变但是物体本身的特征没有发生改变,可以通过这个特点识别出物体 [18]。输入的文本信息经过前述BERT-base层和BLSTM层后,已经有相当多的信息被向量化,此时需要CNN来进行特征抽取以筛选出对相似度判定有效的特征。通常来说,单层卷积捕捉的特征是有限的,因此为了获取较为全面的特征需要根据文本特点对卷积层和池化层进行设计。在单个通道中,输入的向量在卷积层进行一维卷积得到特征,然后在池化层选取这些特征中的最大值。最后将每个通道中得到的特征进行拼接构成新的向量来表示文本。重复前述卷积与池化操作若干次,直至提取的特征满足相似度判定要求后输入下一层。经过阅读相关资料和实验测试,在前三次卷积层池化层交替设置后,模型效果都有一定提升,而再往上堆叠卷积层和池化层后效果下降。综合BLSTM输出向量的维度,以及对有效特征的估计,需要利用三层尺度递减的卷积核捕捉向量有效的特征,这样既保证了信息的全面性也在一定程度上减轻了过拟合的影响。设输入的向量为M,其中的维度为d,卷积操作如式(12)所示。
1.3.3 SoftMax层
最后选用SoftMax作为判定层,并使用交叉熵函数(式13所示)作为代价函数进行训练:
2实验结果和分析
2.1数据集介绍
蚂蚁金融语义相似度数据集 AFQMC(Ant Financial Question Matching Corpus),该数据集是金融领域(阿里蚂蚁金融)的专业数据集,对研究金融领域的相似度判定以及后续的真实性验证有很强的相关性。同时它也开放了模型得分排行榜方便比较模型的优劣。数据示例如表1所示。
其中label 为1代表短文本句对相同,label为 0代表短文本句对不同。这类的短文本相似句对的数据量为训练集34334,验证集4316,测试集3861。
2.2實验设置和评估指标
实验设备为个人台式电脑(PC),在Windows 10专业版系统下的Anaconda虚拟环境下进行的实验,内存16GB,利用GPU加速,GPU为 RTX2060。训练时长根据模型大小的不同和参数的不同在40分钟至3小时不等。
检验输出的结果和标准答案对比。 测评指标为准确率,计算公式为:
准确率 = 正确预测数目 / 总问题对数目
2.4实验结果
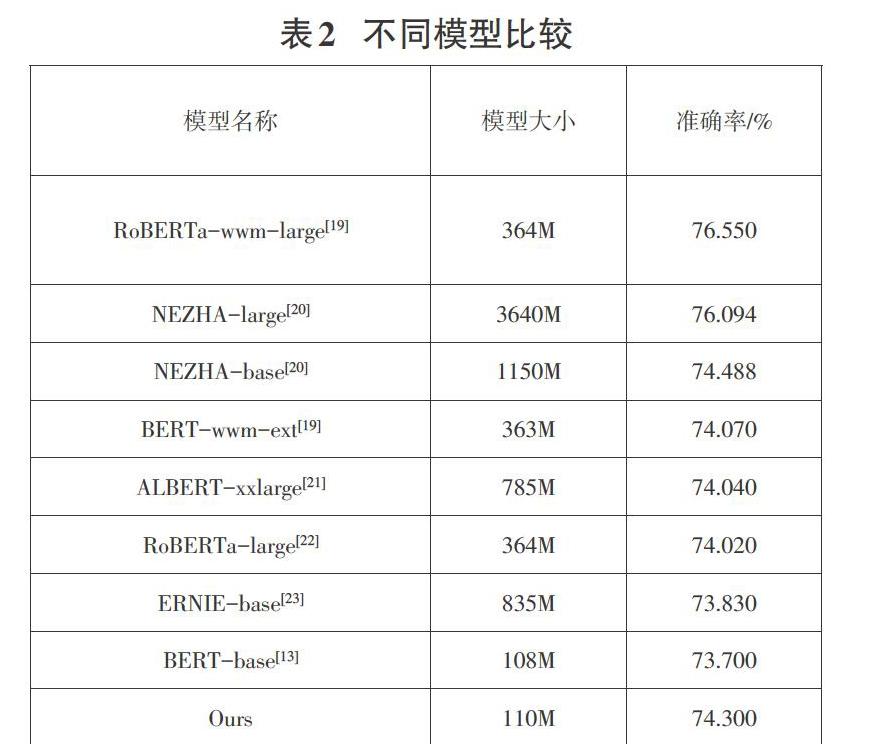
2.4.1在CLUE benchmark进行与其他模型对比
其中 RoBERTa-wwm-large [19]和BERT-wwm-ext [19]模型是哈工大讯飞实验室基于BERT和Roberta[21]训练方法引入全词遮盖和中文语料训练等改进的模型。NEZHA-large[20]和NEZHA-base[20]则是华为诺亚方舟实验室在BERT训练方法的基础上增加了相对位置编码函数、全词掩码、混合精度训练、优化器改进等优化的模型。BERT-base[13]是谷歌提出的小参数预训练模型。ALBERT-xxlarge[21]是在BERT训练方法的基础上通过参数共享的方式降低了内存,从而达到提升训练速度效果的改进模型。RoBERTa-large[22] 是Facebook提出的模型,其主要改进是在更多语料和训练时长下,通过在训练方法上使用动态Masking机制代替BERT原有的静态Masking机制、引入输入多个句子判断连续性任务代替双句连续性判断任务等。ERNIE-base[23]则是百度提出的基于知识增强的模型,其主要通过对实体概念的建模学习更加符合实际应用中的语义关系。通过在测试集上表现已认证模型排行榜可以看出以下几点结论:①与BERT-base模型相比,BERT_BLSTM_TCNN模型因为附加特征提取层的缘故,参数量有较小的增加,而准确率却提高了0.6%,在小参数模型中拥有比较优秀的表现;②尽管提出的模型在最终准确率上并没有做到最高的准确率,与表中最好的RoBERTa-wwm-large相比准确率差2.2%左右,但是由于在词向量阶段使用的预训练模型BERT-base参数量较小,最终参数量却仅仅是其三分之一。小参数量意味了更快的训练速度和更低的运算资源需求,其训练和使用也是更加方便的;③模型的参数量对最终相似句对判定准确率有一定的影响,但是并不是参数越多结构越复杂的模型效果就越好。例如RoBERTa-wwm-large表现要比 NEZHA-large和NEZHA-base要好,其参数量却远小于后两者。因为大参数模型拥有更多的层数和更复杂的结构,其综合性能可能更优,但是在某些特定任务中,其中一些参数对最终结果会产生一定干扰致使模型性能下降。
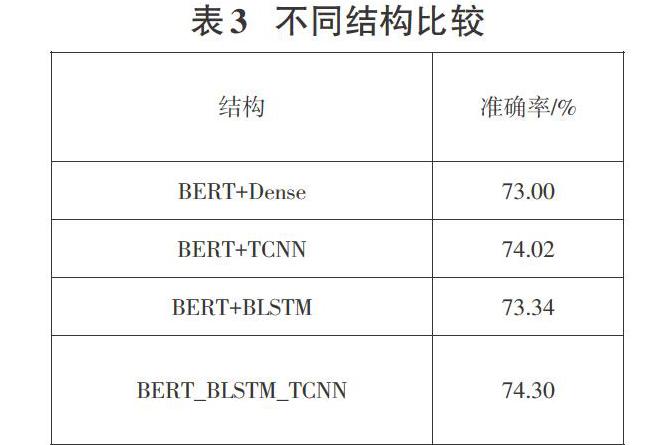
2.4.2不同模型结构比较
由上表可以明显看出,相比于直接加入全连接层,加入TCNN和BLSTM效果都有所提升,并且BERT_BLSTM_TCNN的效果最好。说明经过一定的结构设计,是能够在特征抽取阶段对BERT训练出的[CLS]向量在相似度相关的维度上进行修正以提高相似度判定的准确度。
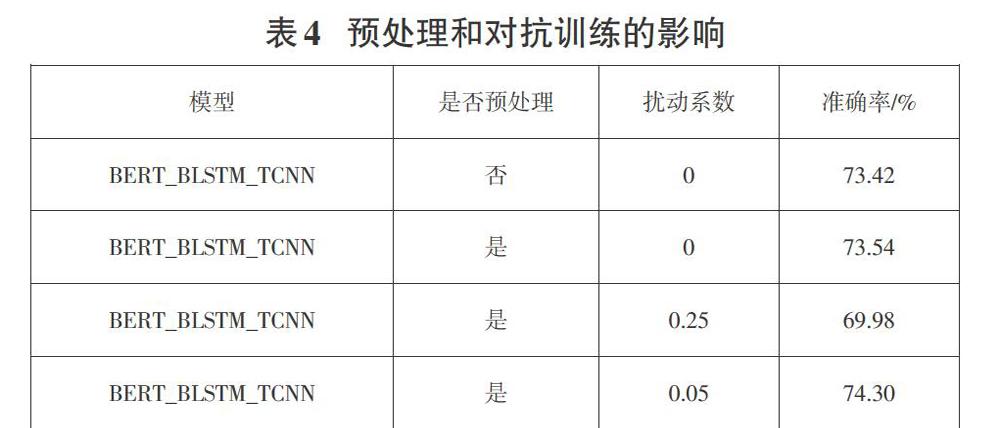
2.4.3预处理和对抗学习对模型效果的影响
与没有引入扰动和进行短文本的句子截断相比,引入扰动后,在合适的扰动权重下效果有所提升。同时截断长句也能在一定程度上提高模型的对相似度判定的准确率。
3结论
相比于直接使用大参数的预训练模型进行微调来适配任务,对小参数模型进行改良来获得一个比较良好的效果是更具有应用价值的。使用大参数模型意味着更多的计算资源的需求,这无疑是在无形中增加模型研究和应用的成本。虽然大数据量和大参数量的模型也有着调试方便、特征多样等优点,但是其研究和使用门槛也会随着参数量的增加越来越高,阻碍了其的实际应用。尤其在涉及语义相似度的任务研究时,基于大参数预训练模型进行调试可以较快地获得较好的效果,但是如果一个任务用简单模型就可以达成相对不错的效果,其应用价值无疑是更为广泛的。提出的BERT_BLSTM_TCNN模型利用小参数的预训练模型附加特征抽取层等方法,可以在小参数量的前提下在相似句对判定任务中达到较好的效果,说明小参数的预训练模型仍有很大的潜力可以挖掘。相比于近年来大热且不断更新的大参数量模型设计,对已经发布小参数词嵌入模型的调优改良的关注度相对较低,但是这并不代表BERT-base甚至是参数量更小的预训练模型已经没有研究价值。未来,如何特定任务场景下取得计算资源和模型参数量之间的平衡,使模型最具研究和应用价值会是一个值得给予关注的方向。
参考文献:
[1] Kim Y. Convolutional Neural Networks for Sentence Classification[EB/OL]. [2014-9-3]. https://arxiv.org/abs/1408.5882.
[2] Lei T, Barzilay R, Jaakkola T. Molding CNNs for text: non-linear, non-consecutive convolutions[J]. Indiana University Mathematics Journal, 2015, 58(3):1151-1186.
[3] Wang P. Semantic Clustering and Convolutional Neural Network for Short Text Categorization[J]. 数字内容技术与服务研究中心, 2015:352-357.
[4] Joulin A,Grave E,Bojanowski P, et a1. Bag of tricks for efficient text classification[C].Proceedings of the 15th Conference ofthe European Chapter of the Association for Computational Linguistics.2017: 427-431.
[5] Arevian G. Recurrent Neural Networks for Robust Real-World Text Classification[C].IEEE/WIC/ACM International Conference on Web Intelligence. IEEE, 2007:326-329.
[6] Yang Z, Yang D, Dyer C, et al. Hierarchical Attention Networks for Document Classification[C]. Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2017.
[7] Tang D, Qin B, Liu T . Document Modeling with Gated Recurrent Neural Network for Sentiment Classification[C]. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015.
[8] Zhou C, Sun C, Liu Z, et al. A C-LSTM Neural Network for Text Classification[J]. Computer ence, 2015, 1(4):39-44.
[9] Lai S W,Xu L H,Liu K,et a1. Current convolutional neural networks for text lassification[C]. oceedings of the Twenty-Ninth A AAI Conference Oil rtificial Intelligence,2016:2268-2273.
[10] Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and their Compositionality[J]. Advances in Neural Information Processing Systems, 2013: 3111-3119.
[11] 牛雪瑩, 赵恩莹. 基于Word2Vec的微博文本分类研究[J]. 计算机系统应用, 2019(8):256-261.
[12] Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[C]. Proceedings of the 56th Annual Meeting of the Azssociation for Computational Linguistics, Stroudsburg: ACL press,2018:2227-2237.
[13] Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[EB/OL].[2019-5-24]. https://arxiv.org/abs/1810.04805.
[14] Vaswani A, Shazeer N, Parmar N, et al. Attention Is All You Need[C]. Advances in neural information processing systems. Stroudsburg: MIT Press,2017: 5998-6008.
[15] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples[EB/OL]. [2015-3-20]. https://arxiv.org/abs/1412.6572.
[16] 徐铭辉, 姚鸿勋. 基于句子级的唇语识别技术[J]. 计算机工程与应用, 2005(08):89-91.
[17] Nowak J, Taspinar A, Scherer R. LSTM recurrent neural networks for short text and sentiment classification[A]. International Conference on Artificial Intelligence and Soft Computing[C]. Cham, 2017: 553-562.
[18] 周飞燕, 金林鹏, 董军. 卷积神经网络研究综述[J]. 计算机学报, 2017,40(6):1229-1251.
[19] Cui Y, Che W, Liu T, et al. Pre-Training with Whole Word Masking for Chinese BERT[EB/OL]. [2019-10-29]. https://arxiv.org/abs/1906.08101.
[20] Wei J, Ren X, Li X, et al. NEZHA: Neural Contextualized Representation for Chinese Language Understanding[EB/OL]. [2019-9-5]. https://arxiv.org/abs/1909.00204.
[21] Lan Z, Chen M, Goodman S, et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations[EB/OL]. [2020-2-9]. https://arxiv.org/abs/1909.11942.
[22] Liu Y, Ott M, Goyal N, et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach[EB/OL].[2019-7-26]. https://arxiv.org/abs/1907.11692.
[23] Sun Y, Wang S, Li Y, et al. ERNIE: Enhanced Representation through Knowledge Integration[EB/OL].[2019-4-19]. https://arxiv.org/abs/1904.09223.
【通联编辑:王力】
猜你喜欢
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
计算机应用(2016年12期)2017-01-13
求知导刊(2016年10期)2016-05-01
