
基于DenseNet的红外图像热斑状态分类研究
2021-04-13 11:23贾帅康白英君孙海蓉曹瑶佳
山东电力技术 2021年3期
贾帅康,白英君,孙海蓉,曹瑶佳
(1.华北电力大学控制与计算机工程学院,河北 保定 071003;2.华北电力大学河北省发电过程仿真与优化控制技术创新中心,河北 保定 071003)
0 引言
随着传统化石能源面临着诸多如资源不可再生、环境污染的问题,而在新能源领域如太阳能,由于其环保、分布区域广等优点在能源产业结构的比重逐渐增加,使得新能源领域光伏发电产业迅速发展。然而,在产业规模扩大的同时,光伏组件系统的安全运行也越来越受到研究人员的关注。当光伏组件受到物体的遮挡后,受其特性的影响,遮挡部分所在的电池片流过的电流变小,在其他串联电池片的影响下,成为负载,并将其他电池片产生的能量以热量的形式消耗掉,这就是热斑效应[1]。为保证光伏发电的安全有效运行,对光伏发电系统进行可靠的故障检测就尤为重要[2]。由于热斑会以热量的形式消耗能量,导致其与周围的电池片会出现温度上的巨大差异,因此可借助红外热像仪判断热斑。关于利用红外图像进行热斑检测已有不少学者进行了相关实验和研究。文献[3]通过分析红外图像的温度线轮廓以及灰度直方图特征,得出热斑与特定的不连续电池片相关的结论。文献[4]提出利用图像处理的方法,采用Canny 边缘检测算子检测热斑模块及其相关故障。文献[5]提出一种利用无人机技术采集数据的热斑识别方法,通过统计学的方法区分异常状态的光伏组件。
近年来,深度学习大放光彩,在各个研究领域都取得了优异的表现,文献[6]利用卷积神经网络将预处理好的光伏红外图像的热斑进行训练测试。文献[7]利用VGG16 对Faster RCNN 进行初始化,并在制作的数据集上进行训练微调。在实际中,热斑区域面积偏小,上述研究工作未能充分利用热斑的细微特征,为进一步提高准确率,提出一种基于深度学习DenseNet模型的方法,在原有的DenseNet(Densenet-40-12)网络基础上改进网络结构,并将原模型的损失函数更换为Focal 损失函数,增强网络中对热斑的学习能力,提高模型分类准确率。
1 数据采集及预处理
模型训练所采用的数据集,来源于某光伏电场。将采集的光伏红外图像进行规则裁剪,经筛选整理后,分为8个类别,共计1 011幅图像,每幅图像仅包含一块电池片。数据集图像根据光伏板的不同状态划分为类型白、类型红、类型黄、类型黄绿相接、类型蓝、类型蓝绿相接、类型绿和类型湛蓝8种。区分依据如下。
1)类型白:图像整体呈红白色,光伏板温度高,状态异常,为重度热斑隐患状态。
2)类型红:图像整体呈红色,光伏板温度较热,状态有异常,为中度热斑隐患状态。
3)类型黄:图像整体呈黄色,光伏板较正常工作状态温度略高,状态较正常,为轻度热斑隐患状态。
4)类型黄绿相接:图像主要为黄色与绿色点相互黏合在一起,在电池片边缘,绿色点一般呈不规则的絮带状分布,状态较正常,黄色点聚集区为重度热斑隐患危险状态。
5)类型绿:图像整体呈浅绿色或者绿色,光伏板温度正常,状态较正常,为中度热斑隐患危险状态。
6)类型蓝绿相接:图像主要为蓝色与绿色点相互黏合在一起,图像上层以蓝色絮状物为主,图像下层为绿色,状态较正常,为轻度热斑隐患危险状态。
7)类型蓝:图像整体呈蓝色,一般会有轻微的白色或者湛蓝色絮状物在蓝色上层显示,光伏板温度较低,状态正常,为热斑潜伏状态。
8)类型湛蓝:图像整体呈湛蓝色,光伏板温度低,状态正常,为光伏组件正常工作状态。
为获取模型有效输入,对构建的数据集图像进行如下预处理:1)为降低卷积运算的计算量,提高模型的训练速度,对模型输入图像的大小进行适应调整(针对提出模型设置图像大小为32×32(宽32 像素,高32 像素),其余对比模型的输入图像大小为默认大小),对不足模型输入大小的图像部分进行填充、对超出的区域进行像素压缩,使之符合模型的输入尺寸;2)为增加数据集的样本量,避免模型因训练样本小导致模型过拟合,提高模型的鲁棒性,对图像分别进行随机旋转(旋转的最大角度设置为30°)、随机水平移动和随机垂直移动(平移设置的最大距离为图像宽或高的0.2 倍)、随机缩放、随机水平和随机竖直翻转等操作来实现数据集的扩充工作。
2 Densenet 神经网络
DenseNet[8](Dense Convolutional Network)是2017 年由何凯明等人提出的一种深度卷积神经网络,DenseNet 在思想上借鉴了ResNet[9]模型结构,通过设置特征复用[10-11]和旁路连接,保证输入信息在网络模型层与层之间最大程度地传输,能够有效将图像的原始特征传递给后层各个网络,保障了每一层都可以直接连接输入层和损失层,能有效避免网络过深而使得模型训练效果变差的现象,整体的网络结构变得十分稠密。
2.1 DenseNet网络
DenseNet 神经网络主要由多个紧密块以及过渡层堆叠而成,如图1 所示。每个紧密块内,第L层所得到的特征图是将此层前面所有的前向特征图进行连接后再通过卷积核卷积的结果,如式(1)所示。
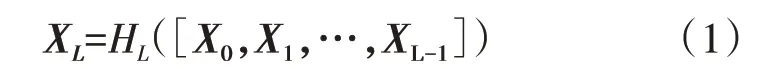
式中:XL为第L层的输出;HL([X0,X1,…,XL-1])为网络非线性变换(包含批归一化,线性整流函数(ReLU)和卷积层(Conv)操作);([X0,X1,…,XL-1])对各层特征图进行连接的操作,则L层的网络就会有L(L+1)/2个连接。
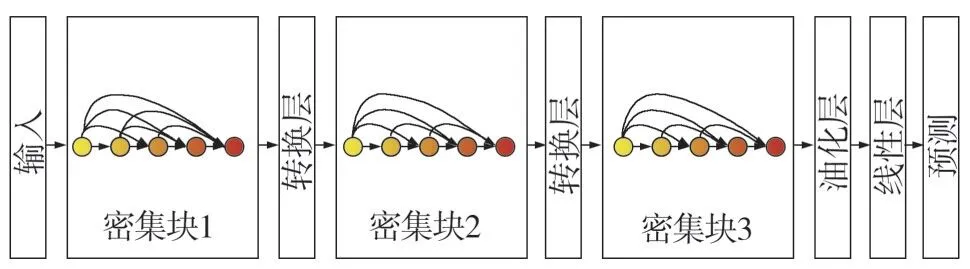
图1 DenseNet模型结构
DenseNet 网络中增加了两个超参数,第一个称之为生长率,是Block 内经过卷积层后输出的特征图个数k;第二个是Block 中卷积的层数L。如果产生k个特征映射,经过第L层的紧密块,其输出的通道数的计算方法如式(2)所示。
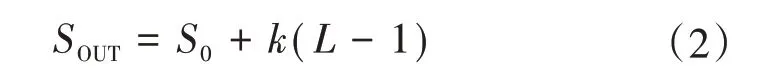
式中:S0为Block的输入通道数,SOUT为输出通道数。
由于密集神经网络结构其稠密性的特点,特征图的数量会逐级增长,为减少特征图的数量,设置的卷积核于每个紧密块的卷积之前,DenseNet 模型在相邻的Dense Block之间添加Translation Layer降低网络整体参数量,Translation Layer 由一层卷积层和一层池化层(Pooling Layer)构成,使得DenseNet可以学习更多的低层次特征,其模型的训练效果也更具泛化能力。
2.2 改进的DenseNet网络
基于DenseNet(L=40,k=12,即每个block 中有40 层,每层卷积产生12 个特征图)网络模型针对构建数据集的特点进行改进,主要改进策略为对构建数据集进行迁移学习,更改模型的前连接层结构。
2.2.1 DenseNet网络结构改进
在DenseNet(L=40,k=12)网络基础上保留原有的Block 模块,并在模型全连接层之后增加一层全连接层和Dropout 层,全连接层神经元个数为64,Dropout层设置系数为0.25。模型自动学习红外光伏图像的底层到高层的特征信息,并在全连接层进行特征整合,最后通过SoftMax 分类器进行故障状态的识别判断。
2.2.2 Focal-Loss损失函数
在深度学习中,损失函数用于评估样本在神经网络运算后其模型的预测值与标签真实值的不一致情况。研究表明,在相同实验下,不同的损失函数表征相同的模型性能时也不尽相同,因此,合理选用损失函数对深度学习模型的性能有一定的影响[12]。DenseNet 网络使用的是交叉熵损失函数(Cross Entropy Loss),如式(4)所示。

式中:y∈{0,1}是真实标签;是预测值。
由于构建的样本数据集类别具有不平衡的特点,为提高模型分类效果,采用Focal-Loss[13]对数据集进行校正,对难分类样本加大权重,对易分类样本减轻权重,使模型多关注难分类的样本。如式(5)所示。
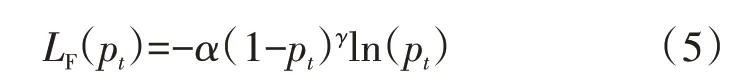
式中:α(1-pt)γ为交叉熵损失函数对应的权重;pt为特征值属于第t类的预测概率;γ相当于惩罚项;α∈[0,1],表示权重因子,用来平衡难分类和易分类样本的重要性。依据文献[13]实验,设置超参数γ为2,α为0.5。实验结果表明,Focal Loss通过改变损失函数的非线性度,从而使模型训练中针对难分类的样本会进行自动学习调整,解决了数据集样本本身不平衡的特点,提升模型分类精度。
2.3 迁移学习
深度学习神经网络的训练往往需要大规模的样本,才能使模型训练出较好的分类效果,而当训练样本不够充分时,通常模型效果会不够理想,可以考虑通过迁移学习,获取非目标图像的基本特征,改善模型效果。通过采用迁移学习[14]的方式,将模型在图像数据集CIFAR 10[15]进行预训练,得到的权重参数迁移到构建的数据集中进行微调训练,模型的所有层都参与方向传播的参数更新,以进一步学习构建数据集的特征信息。
2.4 模型评价指标
模型使用在图像分类领域中常用的平均准确率Acc 评价指标,作为评估模型分类结果的评判依据,计算表达式如式(6)所示[16]。

式中:nc为数据集的类别数,此处为8;t为数据集类别的标签值(取值范围1~8);nt为类别标签为t的样本数目;ntt为模型预测类别t正确的个数。
2.5 模型参数设置
模型采用批量训练的方法,每批次送入神经网络16 幅图像,即模型每次迭代处理图像个数16 张。设置迭代轮数为20,每轮迭代125 次,其初始学习率设置为0.001。
3 实验结果与分析
本文所有实验均使用Tensorflow 作为后端的Keras 深度学习框架搭建,利用Python3.7 进行编程,其处理器为Intel(R)Xeon(R)Platinum 8259CL CPU@2.50 GHz,内存大小为8 GB。
3.1 实验数据集
数据集经过筛选后得到总样本数为1 011幅,其中训练集大小为671 幅,测试集大小为340 幅,不同数据集类型中各个类别样本数据集的分布如图2 所示,各个类别的样本数分布不均衡,可能会导致模型在识别不同类别时存在偏差,因此将训练集数据增强3 倍,最终数据集扩充至3 025 幅图像,其中训练集大小为2 684 幅,测试集大小为341 幅,部分数据增强效果如图3所示。
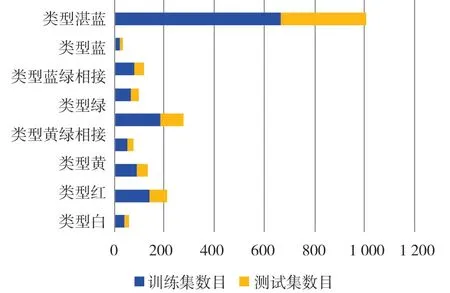
图2 数据分布效果

图3 数据增强部分效果
3.2 模型分类准确率
为验证本方法的有效性,将不同模型采用相同的实验参数,给出对比实验结果,各个模型准确率对比如表1所示。

表1 各模型准确率对比
表1 中DenseNet 表示原始的DenseNet 模型,DenseNet+Focal-Loss 表示使用Focal-Loss 损失函数的DenseNet 模型,DenseNet+Focal-Loss+迁移学习表示使用Focal-Loss 损失函数和迁移学习的DenseNet模型。表1 的结果表明:改进后的DenseNet 模型取得了最好的分类准确率,比其余DenseNet(损失函数选择交叉熵)、DenseNet+Focal-Loss(损失函数使用Focal-Loss)模型提高5%~7.06%,改进模型结构后,通过采用Focal-Loss,模型的分类效果继续提升,这说明Focal-Loss 损失函数能够有效改善数据集样本的不平衡性,提升模型分类精度,模型在迁移学习后,模型精度进一步提高,表明选用的权重参数能够有效学习图像的基本特征,有效防止模型的过拟合的风险。
3.3 模型稳定性
各个模型在20 轮迭代过程中测试集上的准确率与损失函数的变化情况如图4 和图5 所示。图4结果表明,改进后的模型,虽然在初始迭代过程中的准确率较低,但随着模型的不断训练,模型的稳定性较好,由图5 可知,改进后模型的损失函数的波动问题有了较好的改善,证明了在小样本数据集中利用迁移学习的方法是可行的。

图4 不同模型测试集准确率对
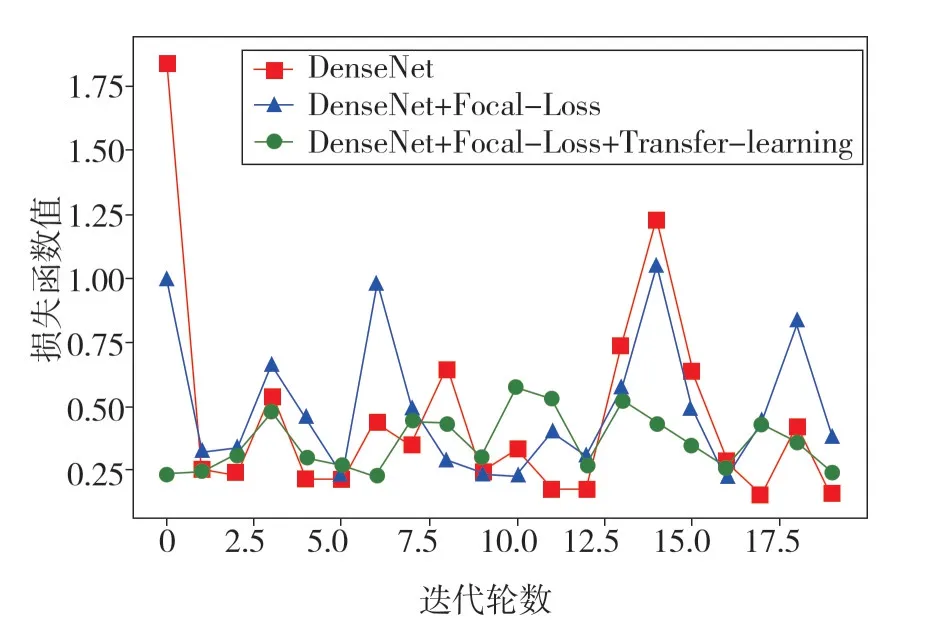
图5 不同模型测试集损失函数对比
4 结语
提出的基于改进的密集连接神经网络的方法,避免传统深度学习需要进行复杂的特征提取,节省了训练时间;所采用的Focal-Loss 损失函数,对分布不均衡的样本具有良好的效果,由网络的输出和真实的偏差决定分类样本的权重,实现网络自适应调整,模型能够得到有效的训练,大大增强了模型的泛化能力,提高分类效果,改进后的DenseNet-40-12网络能够更好地处理红外光伏图像,并通过数据增强的方法,使得模型能够得到有效的训练,实验结果证明所提方法具有较高的识别准确率,并且具有较强的鲁棒性和泛化能力。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
中学生数理化·高一版(2021年2期)2021-03-19
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
领导决策信息(2018年16期)2018-09-27
北京航空航天大学学报(2018年1期)2018-04-20
数学学习与研究(2017年3期)2017-03-09
共产党员(辽宁)(2015年2期)2015-12-06
