
基于迁移学习的驾驶分心行为识别及模型解释
2021-04-13 02:02张瑞宾
科学技术与工程 2021年7期
周 扬, 张瑞宾
(1.西安航空学院车辆工程学院, 西安 710077; 2.长安大学汽车学院, 西安 710064;3.桂林航天工业学院汽车与交通工程学院, 桂林 541004)
驾驶分心是导致交通事故的重要原因之一。在美国,2017年有9%的致死事故与驾驶分心相关, 3 166人因驾驶分心所导致事故而死亡[1]。在挪威, 2011—2015年发生的致死交通事故中有近1/3的事故与驾驶分心有关,其中使用手机导致了2%~4%的致死事故,而其他分心行为如交谈、操控车内娱乐设施等导致了10%的致死事故[2]。因此研究驾驶分心识别对于减少交通事故、提高行车安全具有重要的意义。
为了研究方便,学者将驾驶分心分为4种基本类型[3],包括认知分心(走神)、视觉分心(驾驶人视线离开前方道路)、听觉分心(交谈、听歌)以及动作分心(手离开方向盘)。在实际情况下,驾驶人的一种驾驶分心行为可能包括几种分心类型,比如发短信,就包含有视觉、认知及动作分心3种分心类型。不同驾驶分心行为对行车安全会造成不同程度的影响,研究普遍认为包含视觉分心的驾驶分心行为会导致更大的行车风险。Klauer等[4]采用100辆车的自然驾驶数据统计后发现,驾驶人视觉分心超过2 s将使事故风险增加2倍;而Fitch等[5]研究发现驾驶人手持电话(主要为动作和认知分心)对行车安全不存在显著影响。
在驾驶分心识别的相关研究中,可按照所采用特征的不同分为基于车辆特征和基于驾驶人特征2种类型。前者不直接针对驾驶人,而是间接通过驾驶人操控车辆时的绩效表现来识别分心。马艳丽等[6]采用车速、加速度、车辆横向位移等特征构建了识别模型,对驾驶人操纵车载信息系统的判别准确率达到89.86%;Li等[7]利用实车自然驾驶数据提取的驾驶人视觉-动作分心下的两个敏感特征建立识别模型,模型的识别准确率为93%。基于驾驶人特征识别驾驶分心是更为直接的方法。文献[8-9]中分别采用了驾驶人眼动特征实现了驾驶人视觉分心及认知分心的识别;Liu等[10]融合驾驶人眼动及头动特征,通过半监督学习方法训练了认知分心识别模型;Miyaji等[11]结合了驾驶人眼动、头动及心电特征并利用Adaboost算法建立识别模型,对驾驶人交谈及做算术引发的认知分心识别准确率达到89.8%和90.3%。
上述方法虽已被证明可有效识别驾驶分心,但仍面临以下问题:①仅能区分一种驾驶分心行为与正常驾驶,如区分视觉-动作分心行为与专注驾驶,无法对多种驾驶分心行为及正常驾驶进行分类。由于驾驶人不同的驾驶分心行为对行车安全会产生不同程度的影响,设计能够区分多种分心行为的驾驶分心识别模型可为建立具有不同预警等级的驾驶分心预警系统提供基础。②所依赖设备如眼动仪、生理仪较为昂贵、侵入性强[12],不易在实车条件下应用。虽然基于车辆特征的方法所依赖传感器在当前汽车上已有装备,但由于该方法应用的前提是驾驶人直接操控车辆,因此在当前的辅助驾驶及未来的人车共驾情景下,无法应用此方法进行驾驶分心判别。
由于驾驶人的常见驾驶分心行为具有不同的图形特征,研究者开始利用驾驶人图像识别驾驶分心行为。基于图像的方法仅需在车内安装摄像头,易于实现,随着近年来计算机视觉技术的发展,利用深度学习方法亦可准确地实现图像分类。Hssayeni 等[13]对比了采用传统人工设计特征构建的支持向量机分类模型与卷积神经网络(convolutional neural network, CNN)模型对多种驾驶行为的识别效果,发现前者的识别准确率(27.7%)远低于CNN模型(84.6%)。徐丹等[14]采用CNN构建驾驶人非安全驾驶行为识别模型,与先提取图像方向梯度直方图特征再进行分类的传统方法相比,识别准确率平均提高了3.62%。
训练CNN深度模型需要花费大量时间来确定模型的最佳结构、神经元数量及其他参数,一种更节省时间的方法是利用已在大型数据集中训练及验证的CNN模型进行迁移学习。戎辉等[15]利用迁移学习对AlexNet卷积神经网络进行微调,实现了7种驾驶行为的识别,准确率达到97.8%。Li等[16]利用神经网络结构YOLO(you only look once)实现了对包括驾驶人使用触摸屏、打手机及正常驾驶3种驾驶行为的判别,模型对应的F1评分分别达到0.84、0.69、0.82。陈军等[17]基于迁移学习方法提出了级联神经网络模型,针对驾驶员驾驶分心行为进行检测,准确率可达93.3%。
CNN模型一般采用端对端的训练方式,在给定图片及对应类别标记的条件下,模型直接学习从图片到类别的映射关系,其黑箱性的特点决定了其存在解释性较差的缺陷[18]。然而,研究人员及用户需要了解模型判定类别的依据,据此才能建立对模型的信任。尤其是针对驾驶人驾驶分心行为的识别,若模型根据图像中无关的特征来判别驾驶分心行为,则在实际应用中可能造成大量误判而导致驾驶人关闭系统。
对CNN模型进行可视化有助于解释模型,近年来有大量研究采用如导向反向传播[19]、反卷积[20]、基于梯度的类激活映射[21](Grad-Cam)等神经网络可视化方法研究对CNN模型的分类依据进行解释。在这些方法中,采用Grad-Cam方法可提取模型分类时的重点关注区域(模型分类时所主要依据的图像区域),且不需要改变原模型结构。
基于上述分析,尽管已有部分研究基于CNN模型和迁移学习方法实现了驾驶行为的识别,然而现有研究中并未深入研究CNN模型的解释,为此现基于迁移学习方法构建驾驶分心行为判别模型,为提高模型的可解释性,将结合Grad-Cam算法提取模型识别驾驶行为类别时的重点关注区域并进行可视化,据此分析模型是否学到了驾驶分心行为判别的关键特征,以期为构建兼顾应用性和解释性的驾驶分心行为识别系统提供参考。
1 迁移学习方法
迁移学习方法可将已在任务A中所学的知识或技能转移以应用于新任务B中[22]。在应用迁移学习方法时,一般将已在大规模数据集上进行训练的神经网络模型部分层参数进行固定,而只训练模型的最后1层或几层参数。新模型可保留原训练模型已具备的能力,经过训练的新模型亦可更好地完成新的任务。
选择迁移学习方法构建驾驶分心行为识别模型的原因在于:①训练包含大量参数的CNN深度模型需要大规模的标注数据集,当数据集规模较小时,训练整个模型容易产生过拟合现象;②经过预训练的深度CNN模型如AlexNet、VGG等已具备了检测图像中边缘、纹理及物体等特征的能力[23],这些能力有助于识别驾驶人的驾驶分心行为。
选择VGG-16模型作为迁移学习源模型。VGG模型由Simonyan等[24]提出,在2014年ImageNet大规模图像分类与定位挑战赛(ILSVRC2014)中取得优异成绩,VGG模型根据所包含CNN层数量的不同可分为8、10、13、16 4种类型。采用的VGG-16模型包含13个CNN层及3个全连接层(fully connected layer, FC)。由于原模型是识别ImagNet中所包含的1 000种类别,为识别所采用数据集中所包含的6种驾驶行为,对原模型进行如下修改:①删除原模型中的FC层;②添加两个新的FC层。输出层包含6个神经元,分别输出6种驾驶行为所对应的概率。为了研究不同数量神经元的中间FC层对模型判别效果的影响,分别建立了包含64、128、256个神经元中间层的模型结构,分别记为FC-64,FC-128、FC-256模型。
最终构建的驾驶人驾驶分心行为判别模型结构及各层参数如图1所示,模型包含5个卷积块(Convblock),各个卷积块中的CNN层均采用3×3的卷积核,步长大小设为1,每个卷积块最后均进行最大池化(Max pooling)操作,池化核大小为2×2,步长设为2。除最后1层采用Softmax函数外,其他层之间均采用Relu作为激活函数。为减少过拟合,在FC层之间增加Dropout。
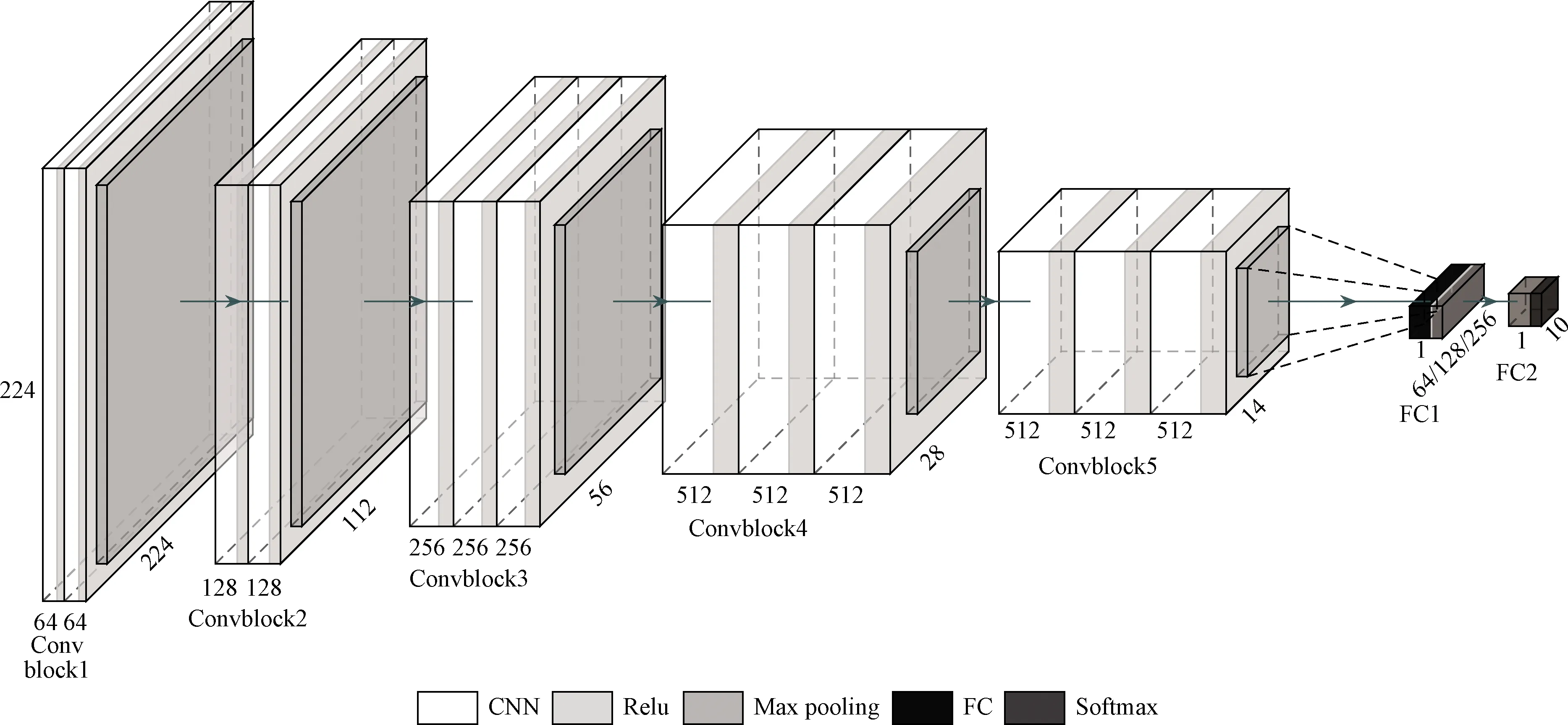
图1 驾驶人驾驶分心行为识别模型结构Fig.1 Framework of drivers’ inattentive driving behavior recognition model
2 模型重点关注区域提取
利用Grad-Cam方法提取模型在判别输入图片所属类别时的重点关注区域,以理解模型在分类时的主要依据,从而提高模型的解释性。
CNN深度模型的整体结构一般可分为2部分:第1部分为所有的卷积层,它们共同构成了特征检测器,其作用是分别检测输入图像的不同层次特征,比如靠前的卷积层作用是检测图像的低层次特征如边缘、纹理,而靠后的卷积层则负责检测更高层次的特征,如物体、场景,越靠后的卷积层往往保留了更为丰富且与分类更相关的特征,这些特征会在其后的FC层中消失,因此为了对CNN模型进行解释,一般对其最后1层卷积层的输出特征进行可视化[25];第2部分为所有的FC层,其共同构成了分类器,作用是利用特征提取层检测到的图像特征进行分类。
Grad-Cam方法通过反向传播计算模型的输出对最后1层卷积层的导数,再进行全局平均以得出最后1层卷积层所输出各特征图(feature map)对于判定图片类别的重要性。具体计算方法为
(1)
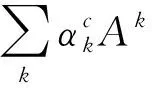
(2)

(3)
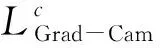
3 试验验证
3.1 试验数据集
采用文献[14]中所使用的state-farm驾驶人行为数据集进行模型训练和验证。该数据集共包含10种驾驶行为,总计18 466张图片。由于原数据集中的部分驾驶行为实际上均包含了同种驾驶分心类型,如驾驶人用右手打电话与用左手打电话,这2种行为均包含了视觉、动作及认知3种分心类型,对行车安全的影响基本相似,因此可以合并为1类。对原数据集中的驾驶行为按照所包含的驾驶分心类型进行合并,具体合并方式如图2所示。
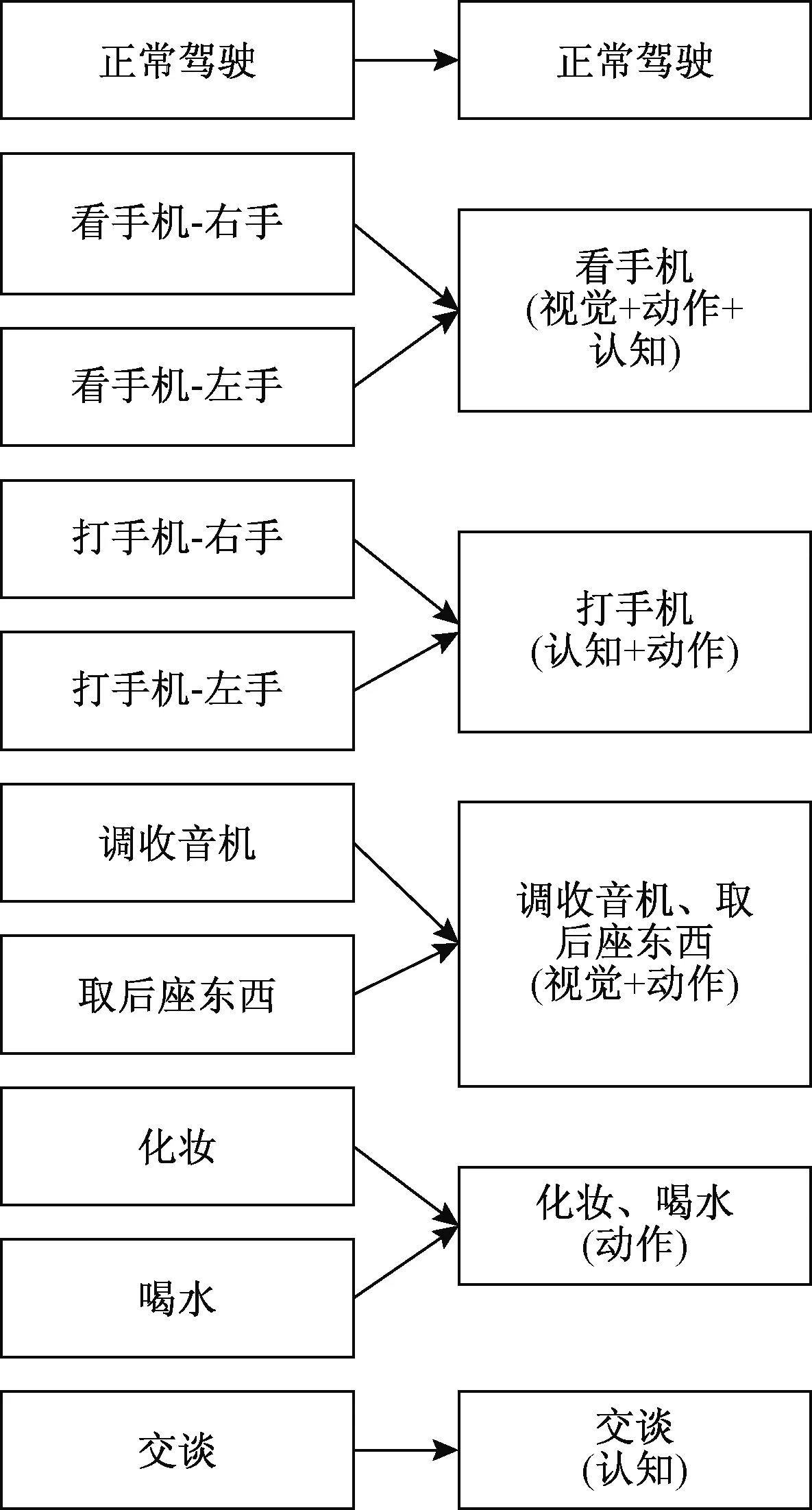
图2 数据集合并方式Fig.2 The way of dataset combination
3.2 模型训练
在PyTorch环境下训练模型,采用多分类常用的交叉熵损失作为目标函数,通过随机梯度下降方法训练模型,将学习率设为0.001,动量设为0.9,采用分段学习率衰减方法,模型训练中每10回合将学习率衰减0.5倍。训练批量设为32,训练总回合数设为50。
将数据集划分为训练集、验证集和测试集,划分比例为7∶1∶2。利用训练集对模型进行训练,在训练过程中,选择验证集中准确率最高的模型为最终模型。通过最终模型在测试集中的准确率评估模型的泛化能力。
由于数据集中的原始图片尺寸为480×640,而所采用的迁移学习原模型VGG-16的输入尺寸为224×224,因此需首先对数据集中图片进行压缩处理。另外,为了提高模型在实际应用中的鲁棒性,防止模型过拟合并加速模型训练过程,在训练时对训练集进行预处理,如图3所示。
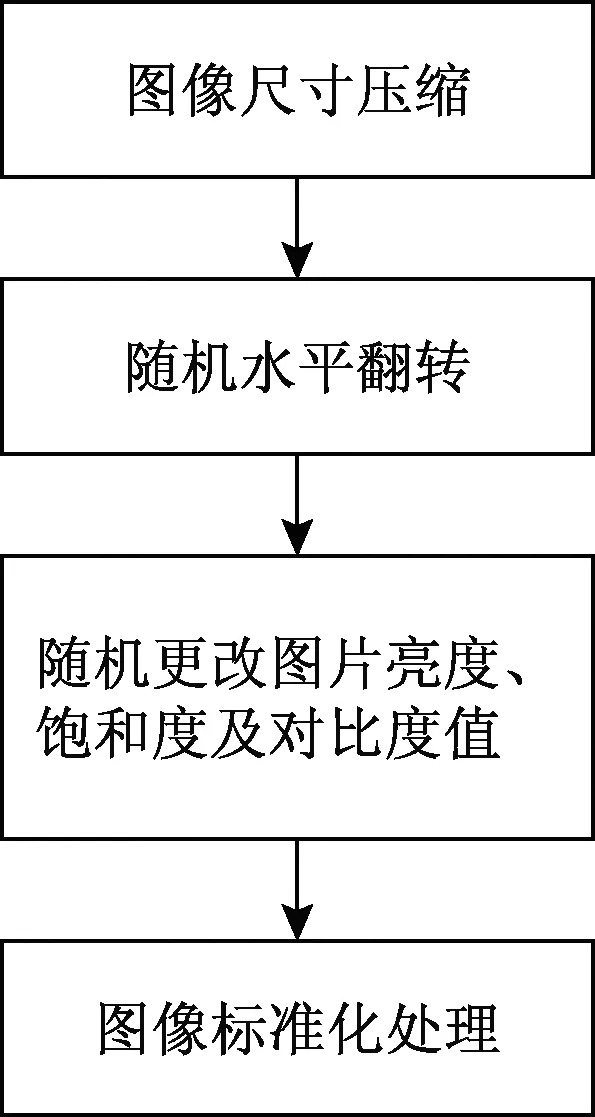
图3 图像预处理步骤Fig.3 Image preprocessing procedures
图4与图5所示分别为采用上述训练参数及预处理方法对所构建模型进行训练时的损失及准确率变化曲线。从图4、图5中可以看出,模型在训练过程中损失逐步下降,识别准确率逐步提升,在训练大约35回合后,模型的损失、准确率趋于稳定。对包含不同数量神经元中间层的模型分类准确率进行对比后发现,随着神经元数量的增加,模型在训练集中的分类准确率随之提高,由于验证集图片并未进行上述的图像预处理,因此验证集中的分类准确率变化较小。

图4 模型训练中损失变化Fig.4 Change of loss during model training
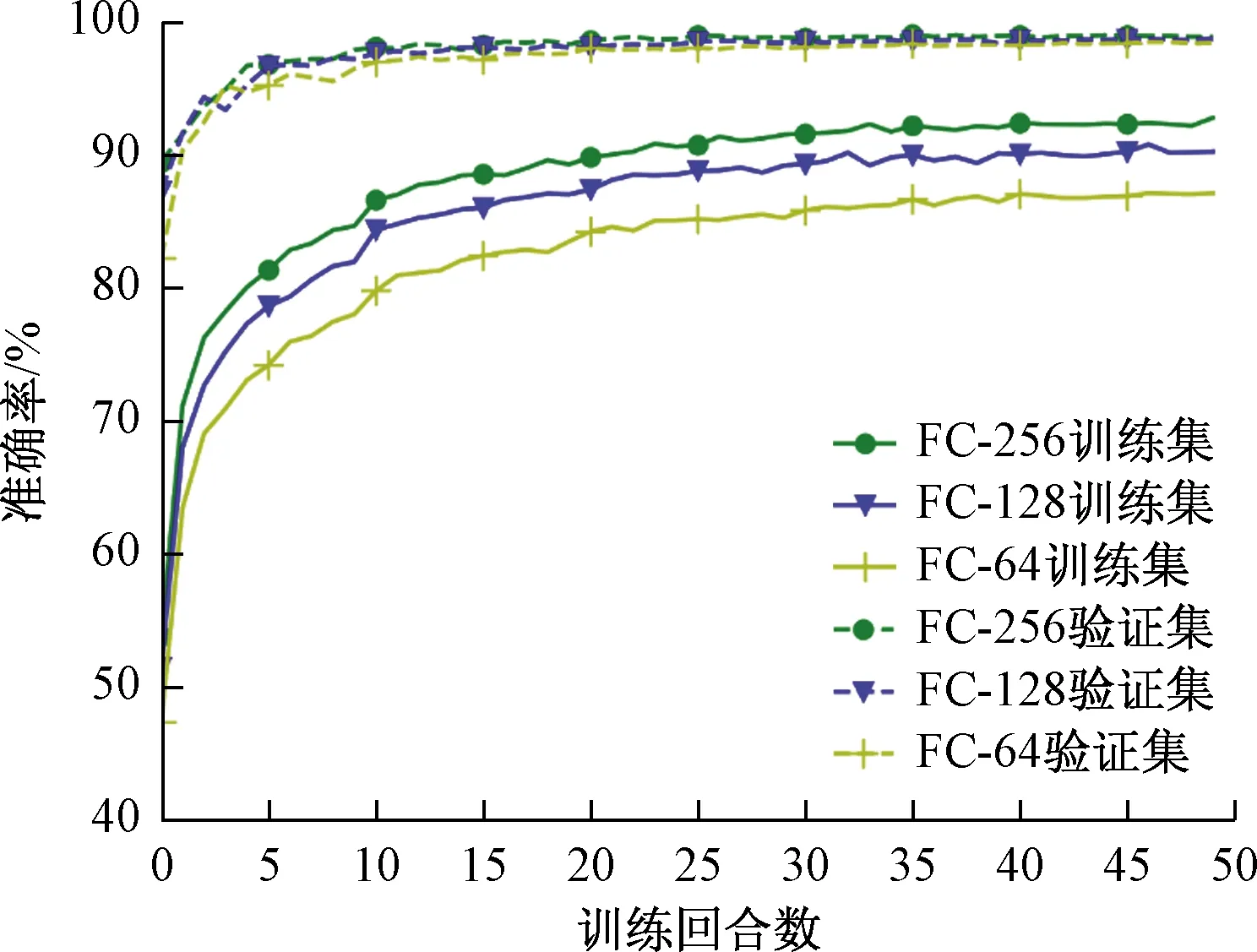
图5 模型训练中准确率变化Fig.5 Chang of accuracy during model training
FC-64、FC-128、FC-256模型在训练集中的最高分类准确率分别为87.25%、90.90%、92.90%,随着中间层神经元数量的等比例增加,驾驶行为的识别准确率分别提升了3.65%及2%,可见中间层神经元数量对于模型准确率的提高程度逐步减小。由于增加神经元数量会使得模型训练时间延长,因此未尝试继续增加神经元数量,而选定中间层神经元数量为256的FC-256模型为最终模型。
表1所示为选定模型在测试集中对各种驾驶行为的识别准确率。模型对6种驾驶行为的平均判别准确率为98.89%,可见模型已能够准确地识别不同类型的驾驶分心行为。

表1 模型在测试集中的判别准确率Table 1 Classification accuracy in the test set
3.3 重点关注区域可视化
采用Grad-Cam分别提取了所训练模型在识别数据集中的6类驾驶行为时的重点关注区域,如图6所示,图中越明亮的区域为模型确定图片所属类别时更加重要的区域。

图6 模型分类时的重点关注区域Fig.6 Focused areas for classification of the model
从图6中可以看出,所训练模型能够定位出各类驾驶行为的关键特征,模型根据这些关键特征判定驾驶行为所属的类别。由图6(a)可见,模型在判定正常驾驶时的重点关注区域为驾驶人的双臂或双手,从图中可以看出,驾驶人正常驾驶与其他相比最主要的特征即在于驾驶人双臂向前、双手与方向盘接触;从图6(b)与图6(c)可明显看出,模型识别出了驾驶人手持手机的位置,据此判别看手机与打手机行为;在识别驾驶人取东西及调收音机行为时[图6(d)],模型主要关注了驾驶人的手臂及面部区域,由图中可看出驾驶人调收音机及取东西时,其主要特征为驾驶人手臂处于图片右下侧或驾驶人手臂处于左下侧且面部偏向左侧;在识别驾驶人化妆、喝水行为时[图6(e)],模型识别出了该种行为的关键特征,即驾驶人手部的区域;当驾驶人与他人交谈时,其面部会偏向一侧,由图6(f)可见,模型在识别交谈行为时则主要关注驾驶人的面部区域。
需要注意的是,由于所使用的数据集图片均为被试驾驶同一辆汽车,汽车的内饰固定,因此所训练模型在识别某些驾驶行为时也依据了一些与该行为无关的特征,如在图6(c)中,驾驶人用左手打手机时,由于左臂抬起,左臂对车门开关的遮挡消失,因此模型在识别驾驶人左手打手机时重点关注了左侧车门开关区域。要避免模型根据此类无关特征判定驾驶分心行为,需进一步丰富驾驶行为数据集,增加车辆的多样性,或增加不同拍摄角度的图片。
4 结论
(1)采用迁移学习方法,仅修改原模型FC层而固定卷积层参数,可保留原模型的图像特征检测能力,如对轮廓、物体的检测,有助于实现驾驶分心行为的识别。
(2)采用端对端的模型训练方式使得CNN模型解释性下降,利用Grad-Cam方法对CNN模型最后1层卷积层输出的重要特征图进行可视化可有助于理解模型的分类依据。
研究中所采用的驾驶行为数据集规模有限,后期将在实车条件下采集更多不同种类、不同拍摄角度的驾驶行为图片,以进一步提高训练模型在实车条件下的鲁棒性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子产品世界(2021年8期)2021-01-16
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中国计算机报(2019年49期)2019-02-07
北京航空航天大学学报(2018年1期)2018-04-20
