
半监督两个视角的多示例聚类模型
2021-04-12 04:19蔡昊,刘波
广东工业大学学报 2021年3期
蔡 昊,刘 波
(广东工业大学 自动化学院,广东 广州 510006)
在大数据时代,许多应用领域均包含大量的图像数据[1-2],图像聚类能够有效地处理这些图像数据,因此得到了广泛的关注。目前大量的图像聚类方法[3-4]已经被提出。例如,Ren等[3]提出了一种基于深度密度的图像聚类框架,其首先使用深度卷积自编码去提取图像的低维度特征,而后使用基于密度的聚类方法进行聚类。Yang等[4]为图像聚类提出了一种对偶约束的非负矩阵分解算法,其中一个约束用来保持图像标签特征,而另一个约束用来增强图像表示的稀疏性。
近年来,多示例学习也在图像处理中引起了广泛的关注[5-6]。针对于多示例图像聚类,Zhang等[6]提出了一种大边缘的多示例图像聚类框架,他们首先识别最相关的示例,而后划分这些示例进入几个不同的组。此外,在图像聚类中,人们可以获得除了图像本身之外的其他信息。例如文本信息,其能够完整地描述相应图像的内容。在现实生活中,很容易收集到大量的图像信息和文本信息,并构造它们成两个视角的数据集去解决图像聚类问题。进一步地,也可以为少量的图像添加标签信息,以提高聚类的性能。
本文提出了一种半监督两个视角的多示例聚类模型,其将文本视角引入图像视角去解决具有少量标签的图像聚类问题。该模型首先嵌入概念分解[7]和多示例核成为一个整体,学习每个视角的关联矩阵和两个视角所共享的聚类指示矩阵;随后,模型引入l2,1范数去学习最优的关联矩阵和聚类指示矩阵。进一步地,为了提高包之间的判别力,模型强迫具有相同标签包的聚类指示向量间的相似性趋于1,不同标签包的指示向量间的相似性趋于0。本文的主要贡献如下:
(1) 提出了一个新的模型,即半监督两个视角的多示例图像聚类模型。该模型引入 l2,1范数提高了包与聚类中心的关联度,同时也获得了理想的聚类指示矩阵。
(2) 基于已知的标签信息,提出的模型强迫包的聚类指示向量间的相似性趋于1或0,提高了包之间的判别力,有助于进一步区分包。
(3) 真实数据集上的实验结果显示:与已有的模型相比,提出的模型能够获得一个更好的聚类结果。
1 相关工作
1.1 多视角学习
通常而言,多视角学习一般先从不同的视角中学习多个特征,而后引入一个联合框架来融合这些特征。现有的多视角学习方法主要基于共识原则和互补原则[8]。共识原则认为不同视角之间存在一致性信息,这种信息应该得到最大化。而互补原则认为每个视角均包含其他视角所不具备的信息,应该使用多个视角去更全面地描述数据对象。基于共识原则,Zhou等[9]为每一个视角构建一个完整的图,而后通过自动加权方法强迫所有构造的图趋于一个共识图。基于互补原则,Cao等[10]利用希尔伯特-斯密特独立性准则去实现不同视角间的多样性,从而增强多视角表示之间的互补性;Wang等[11]提出了一种多样性的非负矩阵分解算法,其定义一个多样性项,该项迫使不同视角表示两两正交,从而实现视角间的互补。对于两种原则的组合,Liu等[12]提出了部分共享潜因子学习算法,该算法主要学习一个潜在表示,该表示是由多个视角所共享的一致信息和每个视角的互补信息所组成。
1.2 多示例学习
多示例学习是一种弱监督学习方法,其训练数据以包的形式存在,而包由多个示例组成。数据的标签信息与整个包相关联,而包中示例标签是未知的。现有的多示例学习方法主要基于包水平和示例水平[13]。基于包水平的方法通常将每个包视为一个整体,而后从每个包中提取目标概念来预测包的标签。相反,基于示例水平的方法尝试识别关键示例,通过预测关键示例的标签来获得包标签。在基于包水平的方法中,Melki等[14]提出了多示例表示支持向量机。它学习一个包的表示选择器,其能够选择出对分类影响较大的示例,并将其作为包的表示卷入到支持向量机中去寻找最优的分离超平面。在基于示例水平的方法中,一个典型的例子是多示例支持向量机 (Multipleinstance Support Vector Machine,mi-SVM[15]),通过对训练包中的示例进行分类,mi-SVM得到一个最优的分离超平面,该超平面可以在每个正的训练包中至少分离出一个正示例。因此,当一个未知包通过该超平面获得一个正示例时,未知包被预测为正。
2 半监督两个视角的多示例聚类模型
本节首先提出半监督两个视角的多示例聚类模型,而后给出一个迭代更新算法去优化这个目标模型,最后,为提出的目标模型引入两个多示例核函数。
2.1 目标模型


此外,少量的标签信息也很容易获得。如果两个包具有相同的标签信息,则它们的聚类指示向量应该相同或者高度相似;反之,标签信息不同,则聚类指示向量应该不同或者极其不相似。为了方便,这里使用内积去权衡相似性,即相同标签包的聚类指示向量间的内积应趋于1,不同标签包的指示向量间的内积应趋于0。具体公式表达如下:

2.2 模型优化
由于式(8)的变量 Wv和 H 均是未知的,因此目标模型无法求得全局最优解。但是可以使用一个迭代更新算法去求其局部最优解。通过定义Kv=φ(Bv)Tφ(Bv),式(8)被重写为

其中
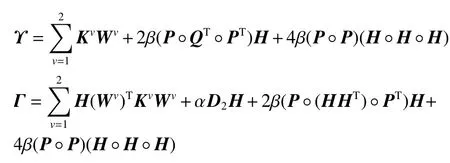
通过迭代的更新式(16)和式(17),目标模型(8)能够被优化。
2.3 多示例核
本节介绍两个多示例核方法,它们能够嵌入到目标模型(8)中。
2.3.1 混合模型核

3 实验
3.1 实验基线及设置
对于提出的两个视角的多示例聚类模型,它能够使用两个多示例核函数,即混合模型核与极大极小核。将两个核的模型分别命名为Ker1和Ker2。为了验证Ker1和Ker2的有效性,本文使用以下4种基线作为比较:
(1) 基线1为BAMIC1[18],其使用最小Hausdorff距离度量计算两个包中示例的最小距离,而后采用k-Medoids算法去划分包。定义最小Hausdorff距离度量为

(2) 基线2为BAMIC2[18],其使用最大Hausdorff距离度量计算两个包之间的示例距离,最后采用k-Medoids算法去划分包。定义最大Hausdorff距离度量为

(3) 基线3为BAMIC3[18],其使用平均Hausdorff距离度量计算两个包之间的示例距离,最后采用k-Medoids算法去划分包。定义平均Hausdorff距离度量为
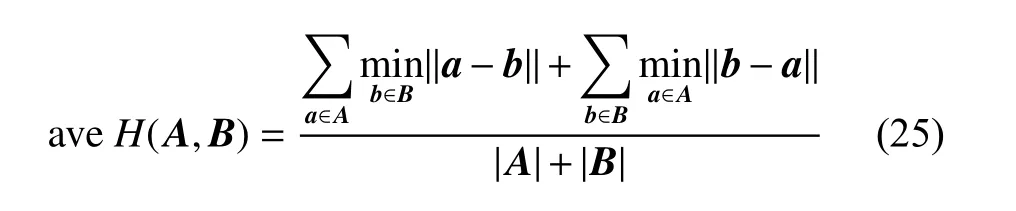
(4) 基线4为unKer1和unKer2,其是提出模型的两种无监督的比较方法,它们没有使用标签信息,而是直接初始化 P=Q=I,基线4的目的是验证半监督学习的优越性。
上述所有的基线均根据原始文献的建议设置参数。对于Ker1和Ker2,随机抽取每一类的5%的标签信息作为监督信息,其余标签信息未知。Ker1和Ker2中参数α , β 的范围被设置为[0.0001, 0.001, 0.01,0.1, 1, 10, 100, 1000] 。在Ker1中,设置参数K =100;对于Ker2,参考文献[17]设置参数 p=5。为了避免随机性,基于不同的初始化值,算法运行10次,并记录相应的平均聚类精度。聚类精度定义为
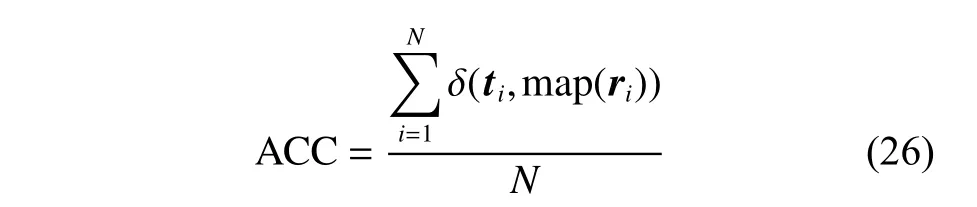
其中, N表示图像包的总数目, ti为真实标签, ri为算法所学习到的聚类标签;m ap(ri)为映射函数,其目的是映射 ri, 使之能与 ti匹配;δ (x,y)为 δ 函数,当 x=y时,δ(x,y)=1, 否则δ (x,y)=0。
3.2 数据集
NUS-WIDE数据集[19]是由新加坡国立大学所创立的图像数据集,其包含有269 648张图片,每张图片均有对应的文本描述。实验是从NUS-WIDE数据集中选择图像和相应的文本去构建2个不同的数据集。其一为NUS-WIDE1数据集,该数据集包含6种混合图像(actor,car_racing,fruit,insect,leopard,tunnel),共有2 605张图片。其二为NUS-WIDE2数据集,该数据集包含6种不同的花(即chrysanthemums,lily,orchid,poppies,rose,tulip),共有2 522张图片。
对于上述数据集,每一个文本被分割成一个文本包,每一张图像也被分割成一个图像包。3种不同的分割方法[20]分割图像并获得图像包,即K均值分割(K-means Segmentation,K-meansSeg)、局部二值模式(Local Binary Patterns,LBP) 和尺度不变特征变换(Scale Invariant Feature Transform,SIFT)。
3.3 实验结果
表1和表2分别列出了不同模型在NUS-WIDE1数据集和NUS-WIDE2数据集的聚类精度,其中Avg为平均精度。对于Ker1和Ker2,表中列出的是模型在 α=0.01, β=0.01的聚类精度。从表1和表2能够观察到提出的模型在聚类精度上是优于其他模型的。以NUS-WIDE1数据集为例,在K-meansSeg中,Ker1比其他的模型在平均精度上至少提高了4.17%;在LBP中,Ker2比其他的模型在平均精度上至少提高了5.91%;在SIFT中,Ker1比其他的模型在平均精度上至少提高了4.07%。这是因为提出的模型使用了标签信息,其监督着模型的学习进程,从而有效地提高了聚类的性能。
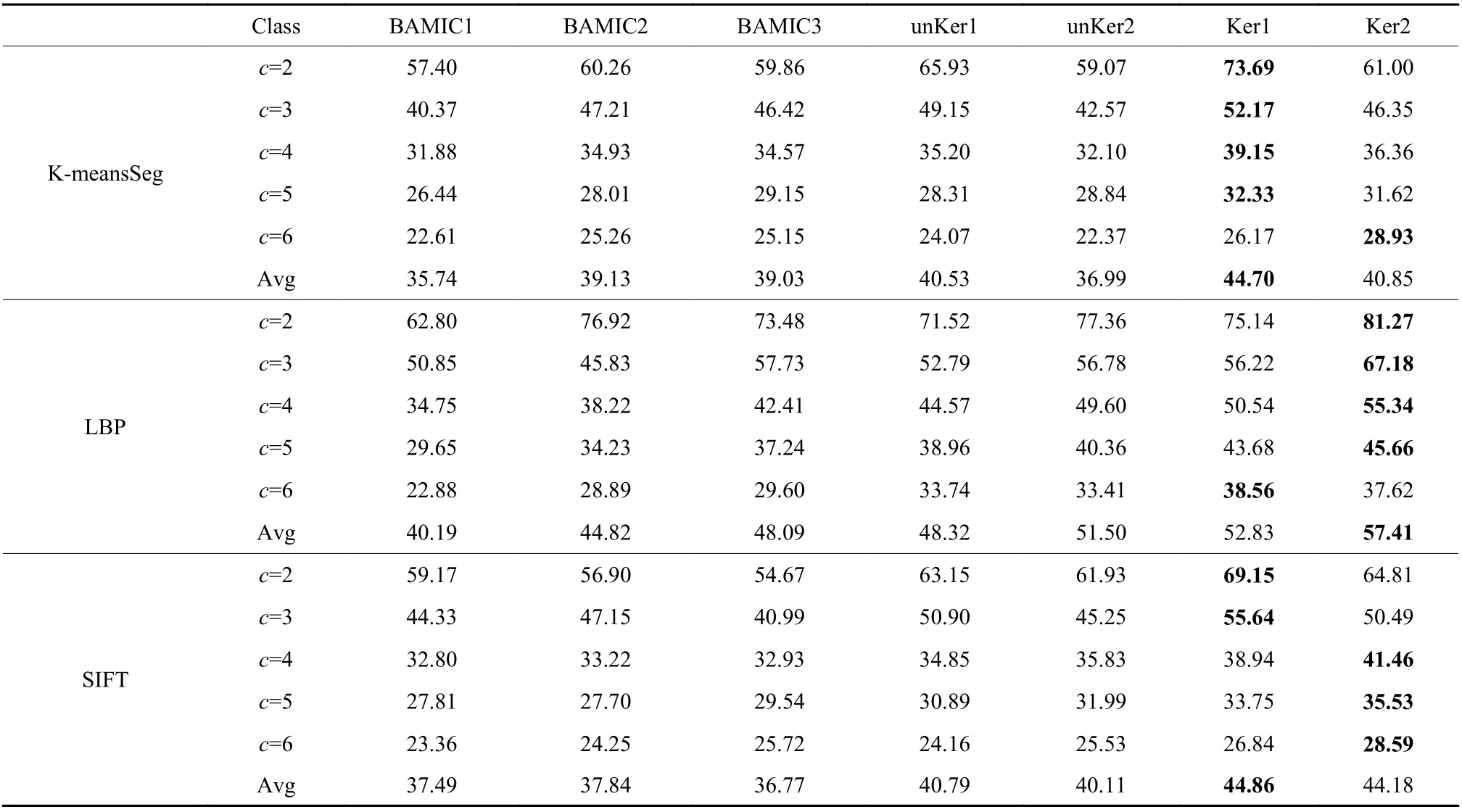
表1 在NUS-WIDE1数据集中各模型的聚类精度对比Table 1 The clustering accuracy comparisons of models on NUS-WIDE1 dataset %
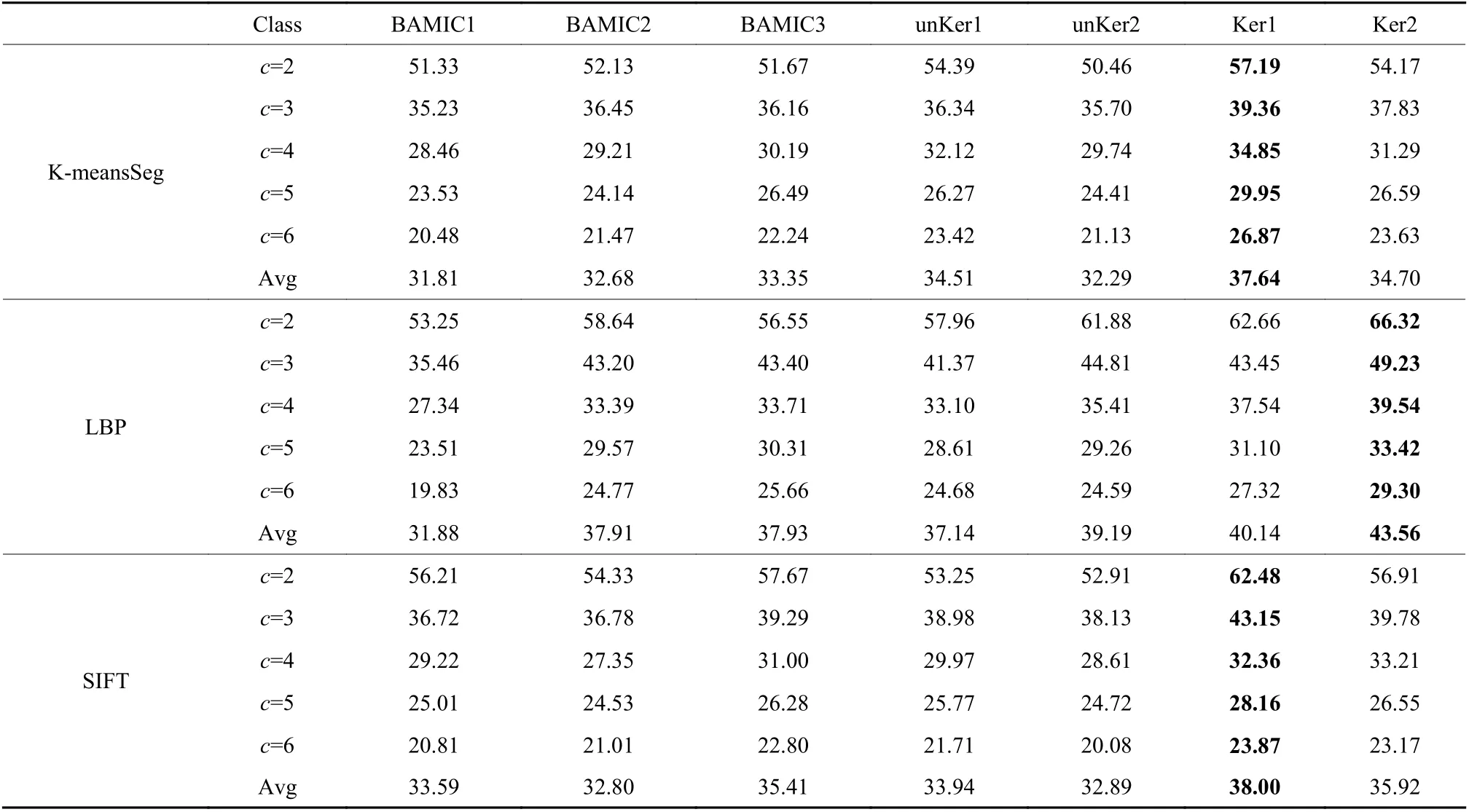
表2 在NUS-WIDE2数据集中各模型的聚类精度对比Table 2 The clustering accuracy comparisons of models on NUS-WIDE2 dataset%
3.4 参数敏感性分析
本节着重构造实验研究参数 α, β对模型性能的影响。对于模型Ker1和Ker2,参数的选择范围为[0.0001, 0.001, 0.01, 0.1, 1, 10, 100, 1000]。在不同的正则化参数下,实验在NUS-WIDE1数据集中的两类数据上执行,对应的实验结果被展示在图1和图2中。从图1中,能够观察到Ker1在参数α , β的大多数情况下的聚类精度均超过了65%。从图2中,能观察到Ker2的聚类精度在K-meansSeg和SIFT中随着参数α, β 变化保持稳定;对于LBP,当α ≤100, β ≤1时,Ker2的聚类精度大多数超过了75%。此外,从图1和图2中,还可以观察到参数 β设置不大于1更合适。总之,Ker1和Ker2的聚类性能对于参数α , β的调整是相对鲁棒的。
3.5 收敛性分析
提出的模型采用迭代更新规则发现目标方程的局部极小值。为了研究模型的收敛性,有必要可视化模型(Ker1和Ker2)在更新规则下的收敛曲线。图3和图4分别展示了提出的模型在NUS-WIDE1数据集内的两类数据上的收敛曲线。从图3和图4中,能够观察到Ker1和Ker2随着迭代次数的增加是逐渐收敛的。
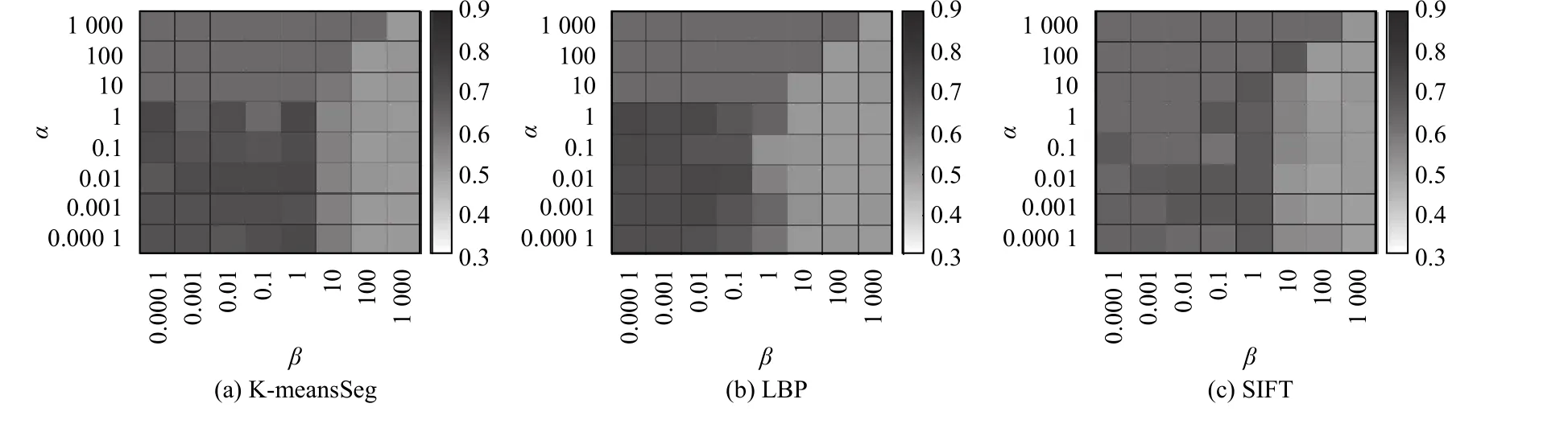
图1 NUS-WIDE1数据集内的两类数据的Ker1参数敏感性实验Fig.1 Parameter sensitivity of Ker1 on the two-class data of NUS-WIDE1

图2 NUS-WIDE1数据集内的两类数据的Ker2参数敏感性实验Fig.2 Parameter sensitivity of Ker2 on the two-class data of NUS-WIDE1
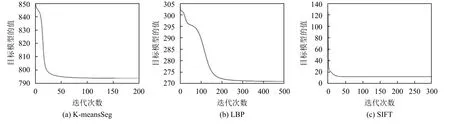
图3 NUS-WIDE1数据集内的两类数据的Ker1的收敛曲线Fig.3 Convergence curve of Ker1 on the two-class data of NUS-WIDE1

图4 NUS-WIDE1数据集内的两类数据的Ker2的收敛曲线Fig.4 Convergence curve of Ker2 on the two-class data of NUS-WIDE1
4 结语
本文提出了一种新的半监督两个视角的多示例聚类模型,其将文本视角和图像视角结合,有效地解决带有少量标签多示例图像聚类问题。通过嵌入概念分解和多示例核函数为一个整体,该模型为每个视角学习了一个关联矩阵,同时也获得了被两个视角所共享的聚类指示矩阵。而后,通过在关联矩阵和聚类指示矩阵上引入 l2,1范数,模型不仅提高了包与聚类中心的关联度,也获得了最优的聚类指示矩阵。随后,基于已知的标签信息,模型强迫相同标签包的聚类指示向量的相似性趋于1,不同标签的指示向量相似性趋于0,这有效地提高了包之间的判别力。最后,一个迭代更新算法被提出,有效地优化了提出的模型。在真实数据集的实验结果表明,提出的模型在聚类精度上优于现有的多示例聚类模型。
猜你喜欢
新世纪智能(语文备考)(2019年10期)2019-12-18
山东冶金(2019年5期)2019-11-16
铁道通信信号(2019年6期)2019-10-08
山东冶金(2019年1期)2019-03-30
中学生数理化·七年级数学人教版(2018年9期)2018-11-09
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
雷达学报(2017年6期)2017-03-26
公民与法治(2016年10期)2016-05-17
互联网天地(2016年1期)2016-05-04
