
基于EKM-AE模型的无监督主机入侵检测方法
2021-04-12 09:50柴亚闯杨文忠张志豪胡知权杜慧祥钱芸芸
小型微型计算机系统 2021年4期
柴亚闯,杨文忠,张志豪,胡知权,杜慧祥,钱芸芸
1(新疆大学 信息科学与工程学院,乌鲁木齐 830046) 2(新疆大学 软件学院,乌鲁木齐 830046)
1 引 言
随着计算机及网络技术的飞速发展,越来越多的人通过计算机学习知识、聊天通讯,甚至网上交易.然而随着计算机越来越多地应用于生活中的方方面面,计算机或服务器面临的安全隐患也越来越严重.入侵检测系统(Intrusion Detection System,IDS)作为一种监视和分析主机或网络事件的系统,在当前网络安全防御中发挥着非常重要的作用[1].由于物联网及工业控制网络对实际生活生产的巨大影响,大部分的入侵检测系统主要针对于物联网或工控网络,用于主机、服务器或其它领域的相对较少[2-6].近年来,许多国内外学者将机器学习方法引入入侵检测中,使网络设备的入侵检测能力大大增强.相比以往基于规则的入侵检测,这些机器学习方法通过学习网络的正常或异常行为反应在目标系统底层网络流量的不同特征来辨别入侵行为.因此这种方法相比以往方法具有能检测新的未知类型攻击的优点[7].但是目前机器学习或深度学习应用于入侵检测还有着以下不足[8]:
1)需要大量有标签的数据集进行监督训练.为了得到检测性能比较好的模型,用于训练模型的数据量往往是越多越好.且为了降低模型检测的误报和漏报率,这些数据集往往都要有人工添加标签处理[9].因此大量数据收集、整理并添加标签会给人们带来较高的工作量.
2)离线学习.目前机器学习或深度学习应用于入侵检测的基本流程是收集数据、对收集到的数据进行预处理、用备选模型进行训练、用检测数据测试模型性能.比如在入侵检测领域,基于公开离线数据集(KDD99、NSL-KDD等)开展的研究占了相当大的比例,尽管这些模型在公开数据集上取得了较好的检测效果[10],但不同于图像处理中训练及检测数据与实际应用环境中非常类似的特点,入侵检测领域中成功的入侵大都归功于攻击者奇异的想法和手段,因而其训练及检测数据集中所体现的网络环境和网络事件与实际使用中的可能会大不相同,而这种利用离线数据学习的方法会使模型只学习到收集数据时网络环境的特点,这就会导致模型在实际使用中缺乏灵活性与自学习能力,从而使其正确率及实际可用性大打折扣.
3)占用资源量大,训练复杂度高,且实时检测较难实现.用大量数据训练模型意味着方法对计算机或其它智能设备有较高的硬件要求.比如,加载数据集需要较大的内存,为了提高模型的训练及检测速度需要较高性能的处理器等.而人工神经网络的计算复杂度会随着神经元的个数指数增长[8],层数较深的网络也会有较高的训练复杂度.因此这种方法在执行速度上劣于基于规则的方法.面对每秒钟会产生的巨大数据包数量,实时检测往往难以保证.
鉴于以上不足,应该着力完善机器学习在入侵检测领域的应用方法和应用的具体网络场景.所以,本文提出了一种结合传统机器学习方法—集成K-means聚类和人工神经网络模型(Artificial Neural Network,ANN)—自编码器的无监督在线主机入侵检测方法EKM-AE,具有如下特点:
1)无监督学习.本文方法针对Kitsune方法[8](2018年NDSS会议论文,下文亦用Kitsune代表)需要正常数据样本训练自编码器的缺陷,利用集成K-means聚类从一般流量(正常与异常流量均存在)中得出正常样本用以训练自编码器,所以能在全程无监督(不需要标签)的条件下较好地区分测试集中的正常与异常流量.降低了一般机器学习需要大量标签数据产生的数据集收集整理的工作量.
2)在线处理.本文方法可以设计成获取使用时流量作为训练数据的形式,即在线训练、在线检测,这样就有利于克服上述离线学习产生的缺陷,本文实验部分就以在线训练、在线检测方式进行实验对比,展现本文方法的有效性.
3)复杂度低.本文方法的检测模型主要由一自编码器构成,使得模型训练检测简单,执行速度在很多情况下高于数据包产生的速度.
2 相关工作
目前入侵检测可以根据其使用的方法分为非机器学习的检测和机器学习的检测.
Guo Q等人[11]设计了一种对无线传感器网络任一路由协议的所有攻击类型自动生成规则的方法,使得无线传感器网络场景下的入侵检测更具有普适性和灵活性;Shen S等人[12]将无线传感器网络中攻击者与入侵检测代理之间的作用建模成一种入侵检测博弈模型,根据两者的作用关系定义代价矩阵,从而得到一种可以节省无线传感器节点资源的防御方法;Fronimos D等人[13]评估了几种低交互式蜜罐的性能,并进一步讨论了低交互式蜜罐在发现高级可持续威胁早期迹象方面的用途;Pawlick J等人[14]对云控系统中云管理员、攻击者和设备3种不同角色用不同的博弈模型进行建模,深化了对云控系统安全的理解.
可以看出,入侵检测中的非机器学习方法大都通过生成规则或建立博弈模型来进行,部分方法对已知类型的攻击具有较好的检测能力,但这些方法有着不能检测未知攻击、对大数据场景不适用或使用的工具具有局限性(比如低交互式蜜罐)等缺点.
机器学习方法在入侵检测领域中的应用也比较多.基本模式是利用代表网络事件的网络流量等数据,建立模型,学习正常行为或攻击行为的不同特征,从而能够自动辨别入侵行为[15].
许勐璠等人[1]针对目标网络在遭受攻击时反应在底层重要网络流量特征各异的特点,引入信息增益率定量分析不同特征对检测性能的影响程度,采用半监督学习利用少量标记数据获得大量数据用于训练,提高模型的检测性能;Prabavathy S等人[16]针对规模可缩放、动态的物联网环境,基于模糊计算,采用在线序列极限学习机(Online Sequential Extreme Learning Machine)的方法,构建分布式的检测体系;Anand S等人[17]使用改进的遗传K均值算法(IGKM)进行入侵检测实验,并在KDD99数据集上与K-means++算法做了对比;Yisroel M等人[8]针对网关或路由器设备内存和计算能力有限的问题,提出了一种基于集成自编码器的在线入侵检测方法.
以上机器学习方法虽然能够检测未知类型的攻击,但会存在特征选取不全面、需要大量数据用以训练等问题,进而造成模型对某些类型的攻击检测性能不高、数据的可靠标签化需要成本、检测模型受限于训练数据等问题[18].比如文献[1]中方法虽然可以利用少量标记数据获得大量训练数据,但是半监督方式本身会使训练数据的标签出现一定的错误率.Kitsune虽然也采用了基于自编码器的在线检测方法,但该模型的训练要用正常流量数据进行,不能说是一种完全无监督的方法,而且该模型的特征提取方法在某些应用场景中不能全面反应网络流量的特点.
因此,本文提出基于EKM-AE模型的无监督主机入侵检测方法,实验部分把本方法同几种常用无监督方法以及Kitsune方法进行了对比.
3 相关理论
本文EKM-AE模型用到的相关理论有两部分:集成K-means聚类与自编码器.
3.1 集成K-means聚类
k均值聚类算法是一种迭代求解的聚类分析算法,首先选取k个对象作为初始聚类中心,通过某种距离计算方法,计算每个对象与各个聚类中心的距离,把每个对象分配给距离它最近的聚类中心.聚类中心以及分配给它们的对象就代表一个聚类.分配样本后,聚类中心会根据聚类中现有的对象被重新计算,这个过程将不断重复直到满足某种终止条件为止.这种方法可以自动地由样本间的某种距离将样本区分开来,具有简单、无监督和运行速度快的优点.
集成学习因为相较于单个模型通常能够获得更好的预测结果被广泛应用.一般通过构建并结合多个单个模型来实现.在单个模型产生后,通过某种策略将单个模型的结果结合起来,产生更好的预测结果.
因此,为了增强K-means聚类结果的可靠性,本文采用集成K-means聚类方法.先通过一定策略将输入数据分成若干部分,接着对每一部分进行K-means聚类操作,最后结合每部分数据的聚类结果综合得出输入数据的聚类结果.该过程可用图1来表示.
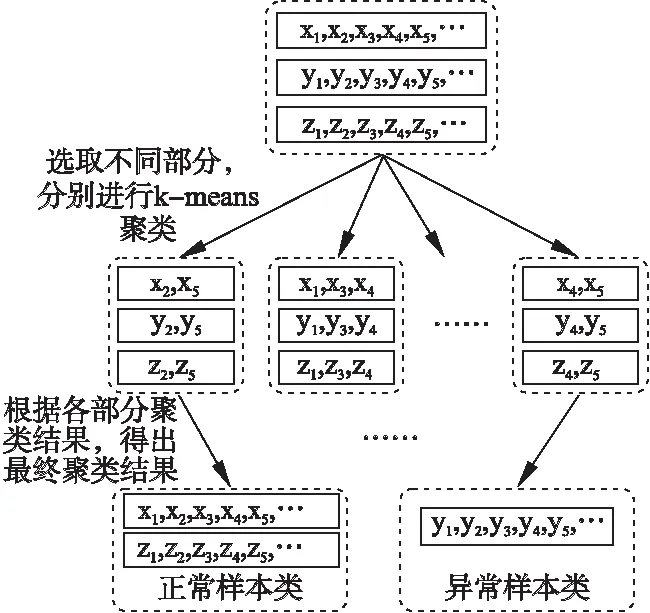
图1 集成K-means聚类示意图Fig.1 Schematic diagram of the ensemble K-means clustering
注意,还有其它的无监督聚类算法可以使用,比如DBSCAN等,但是集成方式的K-means算法在本环境中最直接有效.若采用DBSCAN算法,由于必须不断通过调整eps和min_samples参数值来得到合适的聚类数,所以在集成方式的每轮迭代中都会造成较高的时间复杂度,以至基本无法在实际环境中使用.第5节会进一步讨论该问题.
3.2 自编码器
自编码器(autoencoder,AE)是一类半监督学习和无监督学习中使用的人工神经网络,功能是通过将输入信息作为学习目标,对输入信息进行表征学习.包含编码器和解码器.对输入信息的高效表示称为编码,这种表示维度一般远小于输入数据,使得其可用于降维.而由编码阶段的低维表示还原出原输入信息称为解码.自编码器一般表现为将输入复制到输出来工作,但通过不同方式对神经网络增加约束,可以使这种复制变得极其困难.比如,可以限制内部表示的尺寸(即实现降维),或者对训练数据增加噪声并训练自编码器使其能恢复原有.这些限制条件防止自编码器机械地将输入复制为输出,并强制它学习到数据的高效表示.此外,自编码器还有着其它许多作用.
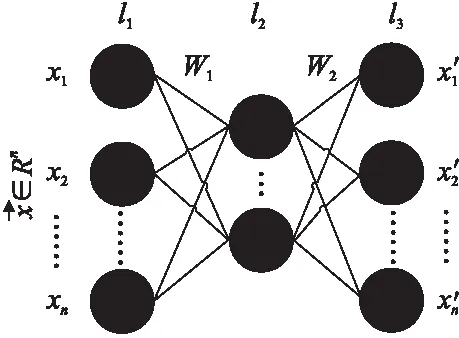
图2 自编码器示例图Fig.2 Schematic diagram of the autoencoder
作为一种特殊的人工神经网络,自编码器具有神经网络的一般结构:输入层(input,visible layers)、隐藏层(hidden layers)和输出层(output layers).一个典型的自编码器(只有一个隐藏层)结构可以用图2来表示.
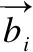
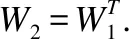
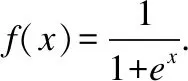
自编码器可采用典型的神经网络训练方法—误差反向传播算法进行训练.训练之前,需要定义输出向量与输入向量差值的度量(即重构误差),作为反向传播的优化目标.
自编码器可以起到很多作用,用于异常检测就是其中之一.基本原理就是以数据X进行训练之后的自编码器就会具有重构与X处于相同分布的其它数据的能力.如果一个数据与X属于不同的数据分布规律,则其重构结果与其本身就会有较大的误差.同样,在定义了输入与其重构结果之间差值的度量后,通过设定阈值,就可以检测是否有异常情况发生,本文就是利用这一特点检测网络中存在的异常情况.
4 本文方法
本文EKM-AE模型可分为EKM(集成K-means聚类)部分和AE(自编码器)部分,其中EKM部分用于以无监督的方式得出流量中的正常样例用于训练,AE部分是用于执行训练和异常检测的自编码器.整个方法流程包括数据包抓取、数据包解析、特征获取、模型训练和异常检测5个部分,如图3所示.
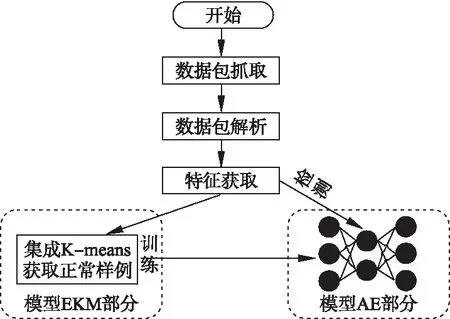
图3 本文方法流程图Fig.3 Flow diagram of this method
数据包抓取通过第3方工具捕获流经主机网卡的实时流量数据.本文使用wireshark工具,将网卡流量数据捕获为原始流量数据pcapng文件.数据包解析通过wireshark中的tshark工具,将原始pcapng文件中的有关属性信息提取出来,从而将原始流量数据转换为检测需要使用的信息.特征获取将数据包解析的结果转换成计算机能够处理的数字(向量),用于下一步模型的训练或执行.模型训练部分先无监督地找出代表正常流量的数字向量,并构造自编码器,然后由这些向量对自编码器进行训练.异常检测部分接收代表实时流经网卡流量的数字向量,并用完成训练的自编码器模型对数字向量进行重构,给出数字向量的重构误差.在重构误差大于某一阈值时,方法判定对应的流量数据具有入侵行为.
由于数据包抓取,数据包解析两部分均通过第3方工具来实现,因此本文对这两部分不做详细说明.
4.1 特征获取
特征对于模型最终的性能会产生非常大的影响,一般使用全面反应客观数据规律的特征训练得到的模型都具有较好的性能.特征获取的任务最主要是用数字去代表实际的数据,有不少方法根据实际信息计算出某些统计量(即统计特征)作为特征获取结果,也有些方法为了降低模型的复杂度,选用尽可能少的特征去代表实际信息.这些方法有着选取特征不全面或计算复杂度过高的问题,因此本着简单有效的原则,本文选取了数据包长度、源目MAC地址、源目IP地址和源目TCP端口等可能对检测结果有影响的18个属性信息,这些属性在tshark中的对应名称如表1所示.

表1 属性名称列表Table 1 Table of property name used
然后用数字对抓取数据中这些属性出现的取值进行编号,即一种编号对应一种属性取值情况.在实现中,利用python语言中字典数据类型即可实现这种转换,将属性取值作为字典键值key,其对应的数字编号作为value,这种处理得到的示例字典如图4所示.

图4 特征获取构造字典示例图Fig.4 Schematic diagram of the generated dictionaries for getting features
利用字典中的value值得到代表每条数据样例的向量表示.随后对这些向量表示进行归一化操作以便于训练.需要注意的是,为了实现在线训练、在线检测的方式,本文参考了Kitsune对数据归一化的操作方式,根据处理过的向量不断改变记录最大值和最小值的参数norm_max和norm_min,并利用当前参数norm_max和norm_min的值对要处理的向量进行归一化,实现一种在线归一化的方式,归一化公式为:
其中pad取非常接近于0的正小数,如10-15.按照这种方式,在模型训练前,记录前10000条数据逐一归一化后的结果以在模型训练阶段使用,类似地,在异常检测阶段,根据训练阶段最后的norm_max和norm_min参数值,对待检测样例的向量表示进行归一化,之后输入到已完成训练的自编码器模型进行检测.
这种特征获取方法以简单直接的方式记录了实际数据包的特点,避免了计算复杂统计量对时间的大量消耗,又能够较全面地记录实际流量数据的特点,对比实验中也说明了这个问题.
4.2 模型训练
本文在模型训练部分,与以往方法最显著的不同就是设法弥补自编码器需要正常标签的数据进行训练的不足.如果能够无监督地发现正常样本,再用这些正常样本对自编码器训练,就能够实现更大程度的无监督化,这种无监督化,在对比真实标签测试模型性能之外的其他阶段,均不需要人工方式为数据集添加正常或异常标签.为了实现这个目标,本文EKM-AE模型在EKM部分利用网络流量中正常数据要远远多于入侵性数据的一般规律,采用集成K-means方法对目标数据进行无监督聚类操作,并认定最终聚类结果里,占多数的一类为正常数据类.EKM部分中的集成K-means聚类操作可表示为下述算法1.
算法1.EKM部分中集成K-means聚类:
clustering(train_x,n):
last_result=[]
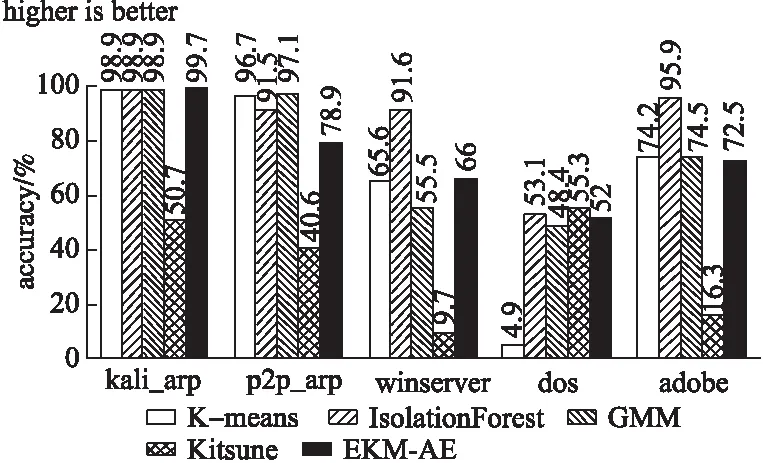
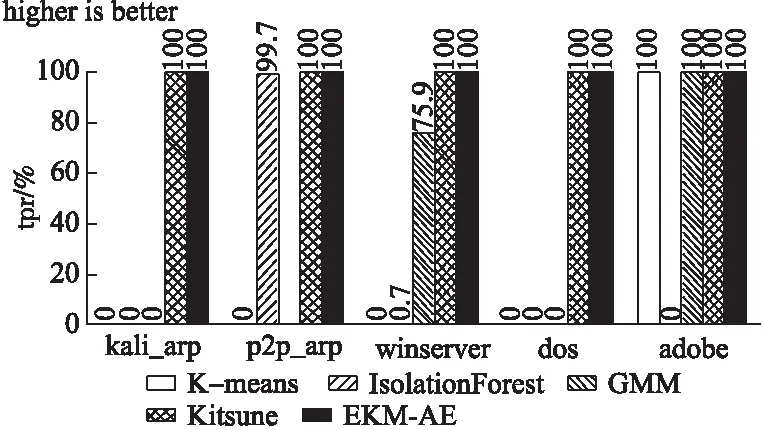
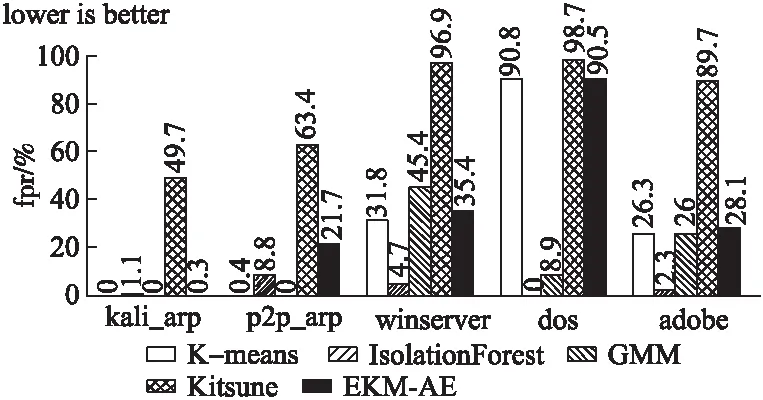
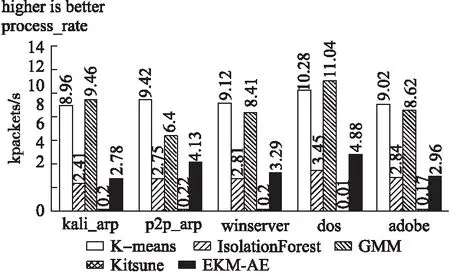
while cur_iter sub_x=select_sub_matrix(train_x) result= K-means(k=2,sub_x) result=modify_by_more_to_negative(result) last_result.append(result) cur_iter++ end 活动安排的时间是一天,有听报告、听课、参观校园等,内容比较翔实而常规,但时间安排比较宽松,我们有足够的时间在校园“游荡”。随后的接触、所见所闻,随意的溜达,彻底颠覆了刚来时的那点“灰灰”的印象。 last_result=numpy.array(last_result).T final_result=decide_by_vote(last_result) return final_result 根据这种机制,在模型训练之前,捕获最开始的10000条数据样例,执行集成K-means聚类操作,将多数的一类视为正常样例,用于自编码器模型的训练.为了防止数据信息在逐层传递中不断丢失,本文采用只有一个隐藏层的自编码器作为训练与检测模型.由于输入样例维度为18,所以自编码器的输入神经元个数与输出神经元个数均为18,隐藏层神经元个数按一定的比例进行压缩.训练过程可表示为下述算法2. 算法2.自编码器训练过程: train(θ,X,max_iter): cur_iter=0 while cur_iter<=max_iter do: A,X′=hθ(X) deltas=bθ(X,X′) θ=GD(A,deltas) cur_iter++ end return θ 上述过程中,A与X′分别表示当X作为输入时,正向传播所得到的每个神经元的激活量与实际的输出,由于模型训练目的是能够重构输入,所以deltas表示实际输出与期望输出(输入本身)的差值(其他符号可参见3.2节),随后利用梯度下降算法更新权重,直到迭代次数超过既定最大次数为止.注意在本实验中,为了保证模型在检测阶段的有效性,同时减少模型的训练时间,模型训练阶段权值调整方式为每条训练数据仅对模型权重进行一次调整,即cur_iter初始化的值与max_iter相等.当聚类模块得到的所有正常样例都已执行过训练过程,自编码器的训练结束. 图5 异常检测过程图Fig.5 Schematic diagram of anomaly detection 为了检测本文EKM-AE方法在基于主机的入侵防御中是否有效,使用虚拟化软件VMware-workstation搭建了虚拟的局域网实验环境.针对可能对主机发起的5种攻击类型做了实验,包括从目标主机中抓取流量数据,用EKM-AE方法给出实验结果,将结果与相关方法进行对比并分析原因等过程. 实验选取的5种攻击类型有:使用kali-Linux对主机进行的arp攻击(含此攻击的测试数据用“kali_arp”代表,本段下文括号内字母意义类似)、使用第3方软件p2p终结者对主机进行的arp攻击(p2p_arp)、针对主机操作系统漏洞的攻击(winserver)、针对主机的dos攻击(dos)以及包含后门的文件对宿主主机的攻击(adobe).以上5种攻击中,kali_arp、dos攻击通过kali_linux的命令行命令arpspoof、hping3实现,winserver攻击通过在kali-linux中,利用靶机win 7操作系统曾有的漏洞ms17_010_eternalblue来实现,adobe攻击利用靶机Adobe Reader 9版本软件中含有的漏洞,在kali-linux里生成含有后门的pdf文件来实现,p2p_arp攻击通过使用第3方工具软件p2p终结者,以图形用户界面方式实现. 实验环境中涉及的系统或软件版本如表2所示. 表2 各软件或系统版本详情表Table 2 Table of details of software and system used 为了说明EKM-AE中无监督聚类部分的有效性,即尽管训练数据中含有异常样本,方法也能发现后续发生的入侵行为,在模型的训练数据中引入了入侵性数据(用kali-linux对靶机进行了arp欺骗).同时,因为Kitsune方法需要在模型训练之前用一段数据得出特征映射矩阵以生成多个自编码器,所以本文做了如下设定用于这两种方法的对比:假设Kitsune用于得到特征映射的数据有10000条,用于训练模型的数据有10000条(根据文献[8],此20000条数据需均为正常访问数据),EKM-AE方法用于提取正常样本训练模型的数据共10000条(此10000条数据中含有恶意数据,更接近实际的使用场景),在含有上述5种攻击类型的测试数据上对比实验效果.此外,还将EKM-AE方法与离线处理的高斯混合模型(GMM)、孤立森林模型(IsolationForest)、K-means方法进行了对比. 一般可以通过真正率(TPR)、真负率(TNR)、假正率(FPR)、假负率(FNR)和准确率(accuracy)对二分类模型性能进行评价,分别定义为: 本文采用了TPR、FPR和accuracy指标来对比各个模型的性能.此外,本文定义了处理速度指标process_rate用以对比各个方法检测的实时性: 图6-图9分别表示5种方法在含有5种不同攻击类型的数据集上的检测准确率(accuracy)、真正率(TPR)、假正率(FPR)和执行速度(process_rate).其中K-means方法、GMM方法的参数均已通过sklearn中工具包GridSearchCV进行了参数调优,Kitsune异常检测的阈值选择原则是使分类TP值最大,同时FP值最小. 图6 各种方法在5种数据集上的准确率accuracyFig.6 Accuracy of each method in 5 data sets 从accuracy可以初步看出,EKM-AE在检测kali_arp、dos、adobe攻击时表现均不错.Kitsune方法表现不好的原因是它主要以数据包的长度计算对应样例的统计量,这样得到的特征较难以检测出具有欺骗或攻击性内容的数据包(如kali_arp、p2p_arp、winserver和adobe攻击).因为入侵检测数据集具有异常样例一般远少于正常样例的特点,这种情况下,accuracy值较高不一定说明检测出了足够多的异常样本.所以为了说明方法对异常样本的检测能力,我们还需要对比在5种数据集上的真正率(TPR)和假正率(FPR). 从图7可以看出,EKM-AE在5种数据集上均具有很好的效果,IsolationForest虽然从accuracy指标看表现很好,但其在大部分数据集上的tpr值均不高,说明其并没有把足够的异常样本检测出来,K-means方法和GMM方法也是类似的情况. 图7 各种方法在5种数据集上的真正率tprFig.7 True positive rate of each method in 5 data sets 图8进一步补充对比了各种方法的性能.可以看出,Kitsune在5种数据集上的fpr值均较高,说明该方法并不适合于本文基于主机的入侵检测.从上述三种指标的角度综合来看,EKM-AE能在全过程无监督的情况下较好地区分出局域网环境中对主机的正常访问流量与常见攻击流量.且对不同的攻击类型,方法性能具有相对稳定性. 图8 各种方法在5种数据集上的假正率fprFig.8 False positive rate of each method in 5 data sets 图9通过process_rate指标衡量了各种方法对流量处理的实时性. 图9 各种方法在5种数据集上的执行速度process_rateFig.9 Execution speed-process_rate of each method in 5 data sets 从图9可以看出,K-means方法和GMM方法也具有较快的训练检测速度,但从tpr、fpr和accuracy指标来看,它们没有较好的检测性能.Kitsune方法检测速度较慢,是因为其特征提取模块根据源目ip、源目mac和数据包长度进行了较为复杂的统计特征计算.EKM-AE对5种数据集均具有较快的训练检测速度.以最低process_rate=2.78(kpackets/s)来看,每秒处理2780条数据包已基本满足实际使用时的一般情况.因此综合来看,EKM-AE在具有稳定较好的检测性能的同时,也具有较好的检测实时性. 在无监督聚类模块,笔者用集成DBSCAN聚类代替本文中集成K-means聚类的实验中发现,为了得到合适的聚类数,DBSCAN方法需要不断调整eps和min_samples参数值,且在每次由不同特征列选出训练数据的“子部分”后都需要类似调整,而在实验中一次调参就耗费了较多的时间(71.82秒),说明在训练之前的聚类部分,相对于集成K-means,集成DBSCAN不适合本文环境下的使用. 因此上述实验结果表明,本文EKM-AE方法以在线训练、在线检测的方式,在全过程无监督的条件下,对实际使用场景中发生的攻击具有较好的检测性能,同时具有检测实时性. 本文提出了一种结合集成K-means和自编码器的无监督在线主机实时入侵检测方法EKM-AE.利用网络流量中正常访问数据多于异常访问数据的一般规律,通过集成K-means方法和自编码器模型,实现对网络入侵的无监督实时在线检测.通过局域网中基于主机的攻击检测实验表明EKM-AE具有一定的有效性.在网络攻击日益复杂、新颖的挑战下,这种在线训练、在线检测的方法会比传统离线学习模型发挥更大的优势. 对比其它相关方法可以发现,机器学习用于网络入侵检测,应注意提取的特征要具有全面性和实时性.全面性即特征应全面反应网络环境特点,实时性即特征要能代表当前网络环境特点.传统离线学习模型在实际应用中性能大打折扣就是由于其训练数据的特征不能或不全面反应实际使用时网络环境的流量特点,因此以后的研究中应更注重特征的全面性与实时性.另外,EKM-AE可以考虑更多的特征,并按特征所属协议种类进行分组,以实现更加准确、更多种类的入侵检测.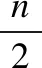
4.3 异常检测
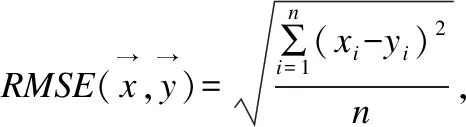

5 实验结果及分析
5.1 实验环境

5.2 评价指标

5.3 结果及分析
6 总结与展望
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
计算机与数字工程(2022年3期)2022-04-07
汽车实用技术(2022年4期)2022-03-07
数字技术与应用(2021年1期)2021-03-24
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
物联网技术(2018年8期)2018-12-06
科技与创新(2017年5期)2017-03-28
中国新通信(2016年2期)2016-03-11
