
融合知识图谱的网络安全违法行为识别系统
2021-04-12 09:50吕明琪朱康钧陈铁明
小型微型计算机系统 2021年4期
吕明琪,朱康钧,陈铁明
(浙江工业大学 计算机科学与技术学院,杭州 310023)
1 引 言
自2017年6月起,《中华人民共和国网络安全法》(以下简称《网络安全法》)正式实施.一方面,《网络安全法》实施时间很短,而其复杂程度较高(《网络安全法》的立法过程花费了14年来完成),导致普通大众对其缺乏深入的了解.另一方面,《网络安全法》与公众的日常生活息息相关,普通大众的网络行为常常涉及到网络安全问题.因此,一个能够协助普通大众判别自己的行为是否触犯《网络安全法》的违法行为识别系统显得极为重要.
大多现有的违法行为识别系统基于信息检索技术进行设计:给定案件描述文本,首先从中提取出关键词,然后用这些关键词在法律知识库中检索相关判例,并基于判例实现违法行为识别,进而支持智能研判、智能量刑等功能.例如,上海二中院应用人工智能辅助开庭审案[1],该智能辅助办案系统会根据指令自动从案件卷宗中抓取关键证据进行显示.江苏省检察官助手“小智”从基础卷宗中提取出关键词,再通过在后台设定的规则进行检索与筛查,最后将可能存在问题的案件推荐给检察官重点监督[2].然而,现有的违法行为识别系统面临以下两个问题:
1)对现有判例数量要求大、质量要求高.
2)系统面向专业用户,基于司法语言体系,难以适应普通大众日常口语化的表达.
上述问题导致现有违法行为识别系统难以直接用于《网络安全法》.原因在于:
1)《网络安全法》实施时间较短,已文书化入档的判例十分稀少,难以支撑需要大量数据的模型训练.
2)《网络安全法》很大程度上面向的是普通大众,而普通大众难以用司法语言体系与系统交互.例如:司法语言体系中提到的“非法出售违禁物品”,在普通大众日常口语表达中可能是“出子弹闲鱼付款”.
针对上述挑战,本文提出了一种基于知识图谱的网络安全法违法行为识别系统.该系统的主要功能为:给定一段网络安全案件描述文本,返回该案件所违反的《网络安全法》中的条款.实现该系统的方法由知识图谱构建、违法实体识别(违法实体包括违法事件实体和违法主体实体)、案件分类3个模块组成.其中,知识图谱构建模块结合《网络安全法》、网络安全相关语料、以及专家知识,半自动化地构建网络安全法知识图谱.违法实体识别模块提出了一种混合式的违法实体识别方法,利用网络安全法知识图谱从案件描述文本中识别出违法事件类型和违法主体类型.案件分类模块采用文本分类模型得到案件违反的法律条款.之所以采用分类模型,是由于《网络安全法》条款数量较少,分类模型可以更准确地定位到条款.下面给出一个实际案例,说明该系统如何识别违法行为:
“宿迁市某党政机关开设的党建网技术保护措施不足,导致遭黑客攻击入侵,网站页面跳转为赌博网站,致使党建网无法正常运行访问而被迫关闭.警方在黑客攻击入侵行为开展立案调查的同时,依法对该单位未履行网络安全保护义务开展查处.”
在这个案件中,对违法事件的描述与司法语言体系差异较大.例如,违法事件“遭受黑客入侵”是口语化表达,对应《网络安全法》中的“未防范计算机病毒和网络攻击”.违法主体“党建网”对应《网络安全法》中的“网络运营者”.针对该案件,文本提出的系统首先基于网络安全法知识图谱,采用实体检测、实体链接、实体分类等手段实现上述对应,然后使用文本分类模型对这一段案件描述进行分类,最终分入类别“未落实网络安全等级保护制度,未履行网络安全保护义务”.
2 相关工作
人工智能结合法律领域的研究近年来发展迅速,目的基本在于增进司法判决的效率,或协助撰写法律文件.主要研究犯罪主体识别、类案检索、法律文本分类,以及罪名推断等.
违法行为识别系统从面向专业人员的辅助工具到面向大众的普法工具,经历了很多变革.例如,Lame等人[3]针对法国的法律文件建立常用字表,利用TF-IDF(Term frequency-inverse document frequency)计算出的权重结合SVM(Support vector machine)对法律文本进行分类,以确定该法律文件所属的法律子领域.Moens[4]研究了文本挖掘算法改善明确措辞在概念性法律文档检索方面的潜力.虽然主要目的仍是文本检索与文本分类,但这时使用到的技术已跟违法行为识别系统十分接近了.Ashley等人[5]使用决策树来对案件文本进行归类,并通过将新的案件文本归入已知类型的案例来预测新的案件的结果.Chen和Chi[6]使用警方的调查文件,通过分析调查文件与历史案件的相似性来对案件进行类型识别.此时违法行为识别系统已初见雏形,但大多对文本的专业性有着很高的要求.
随着深度学习的兴起,LSTM-CRF、LSTM-CNN等网络及其变体在文本领域大放异彩,同时也出现了很多强大的工具.比如ELMo[7]、GPT[8]、BERT[9]等.这些方法与工具的更新使得从法律文本中抽取实体与关系变得更可靠.Luo等人[10]采用案件事实与相关条款之间的关联机制,通过分类预测罪名.Chalkidis等人[11]在大样本多文本标签的数据上使用BERT分类来预测罪名,并得到了较好的分类效果.但是,这些研究对数据量的要求很大,且仍然建立在专业语料的基础上,公众无法利用日常用语来在这些模型中完成检索.
Chen等人[12]提出了将日常用语翻译成法律术语的方式来协助公众通过更自然的方式来检索法律文件.另外,也有部分商业公司开发了一些比较初级的面向大众的工具.如类案推荐平台“包小黑”(1)https://pc-bxh.ai-indeed.com/ 包小黑法律助手、民法刑法罪名预测平台“度小法”(2)https://duxiaofa.baidu.com/ 度小法罪名预测等.但是这些工作仍只能在刑法、民法等拥有大量案例的法律范围内生效,其方法难以直接用于《网络安全法》的违法行为识别任务.
3 方法
3.1 总体架构
给定一段案件描述文本,本文提出的系统的处理流程如图1所示.
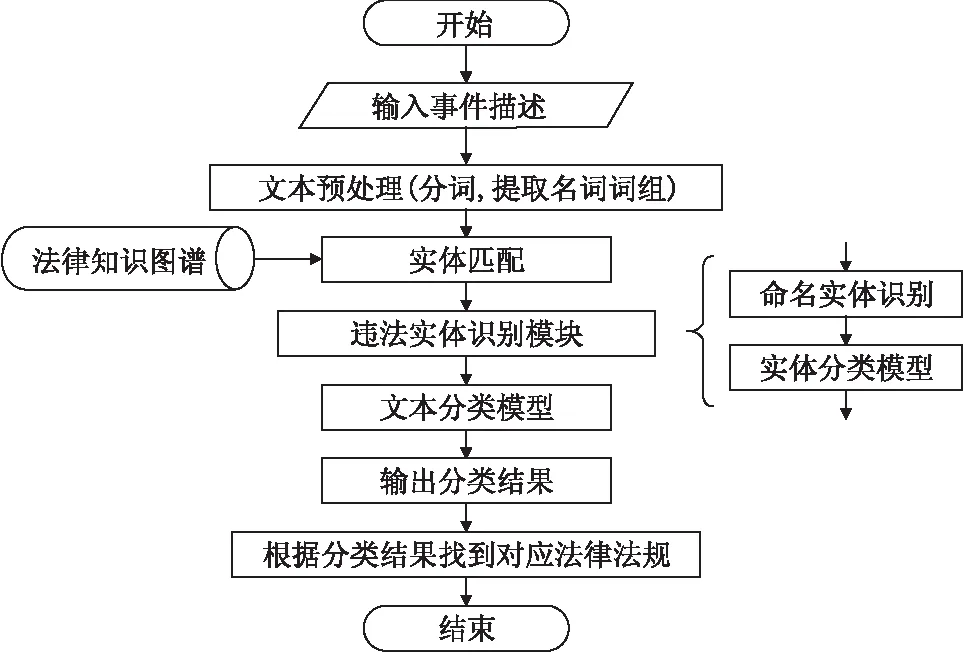
图1 任务整体流程图Fig.1 Overall flowchart
1)预处理:对案件描述文本进行分词、提取关键词等处理.
2)违法事件实体识别:将提取的描述违法事件的关键词在网络安全法知识图谱中进行实体链接,得到违法事件的类型,其目的是消除口语表达和司法语言表达描述的差异.
3)违法主体实体识别:采用命名实体识别、实体分类等手段,从案件描述文本中识别出违法主体的类型.
4)案件分类:结合前两步的处理结果和原始文本特征,对案件描述文本进行分类,分类结果对应《网络安全法》的条款.
3.2 网络安全法知识图谱构建
知识图谱本质上是一种语义网络,其结点代表实体或概念,边代表实体/概念之间的语义关系.相比传统数据库,知识图谱不仅包含事实类知识,还能够提供知识之间的关系,为知识推理提供了有力的支持.本文基于如下步骤构建面向《网络安全法》的知识图谱.
第1步.概念图谱设计.如图2,我们将网络安全法知识图谱的节点分为3大类,将关系也分为3大类.
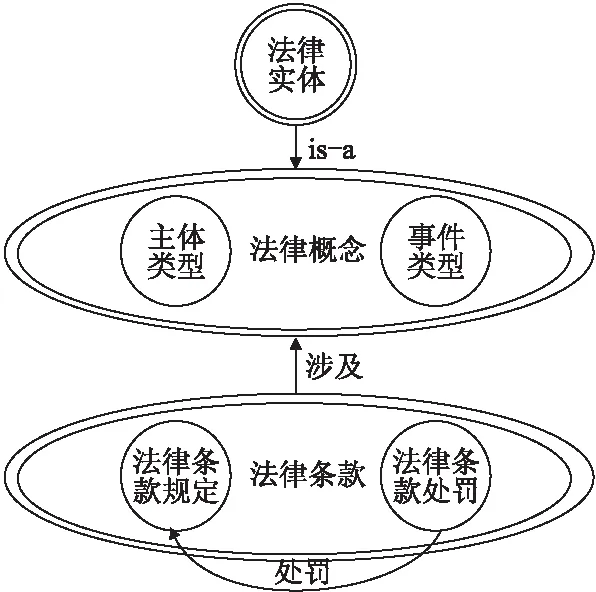
图2 概念图谱Fig.2 Conceptual knowledge graph
3类节点:
1)法律条款:代表具体的法律条款,如“网络运营者为用户办理……推动不同电子身份认证之间的互认”.将《网络安全法》的法律条款分为规定型条款和处罚型条款两类.规定性条款主要为对违法行为和性质的描述;处罚型条款与规定性条款对应,主要描述触犯了规定性条款后的处罚规定.
2)法律概念:代表与网络安全法相关的违法事件类型(如“网络入侵”)和违法主体类型(如“网络运营者”).
3)法律实体:代表法律概念对应的下位概念或具体实体(法律实体和法律概念之间是“is-a”关系).例如,“木马”、“后门”是违法事件类型“入侵”对应的下位概念(“木马” is-a “入侵”), “腾讯”、“阿里巴巴”是违法主体类型“网络运营者”的具体实体(“阿里巴巴” is-a “网络运营者”).
3类关系:
1)包含关系:描述法律概念与法律实体之间的关系,即“is-a”的关系.
2)涉及关系:描述法律条款与法律概念之间的关系,即某条法律条款中涉及哪些法律概念.
3)处罚关系:描述规定型法律条款与处罚型法律条款之间的关系,即当触犯某条规定型条款时,根据哪一条处罚型条款来来进行处罚.
第2步.构建知识图谱.
采用半自动化的方式构建网络安全法知识图谱[13].
1)基于《网络安全法》构建:由于《网络安全法》篇幅不长,因此人工从中提取出法律概念与相关条款,通过涉及关系与处罚关系构建出基础的知识图谱.
2)基于互联网公开语料构建:一方面,收集网络安全相关的语料,从中提取名词与名词短语,人工从中挑选出违法事件与违法主体,并根据包含关系更新知识图谱.另一方面,从互联网上公开的半结构化文本中(如《海关总署禁止、限制进出境物品表》,《互联网企业100强》)自动抽取实体,并与相应的法律概念节点通过包含关系相连接.
本文构建的网络安全法知识图谱部分节点如图3所示.
3.3 实体识别
本文的实体识别包括违法事件实体识别和违法主体实体识别两部分.其中,违法事件实体识别的目的是让用户的口语化表述与法条的司法语言描述对应起来.主要针对如下问题:普通大众都是用日常口语化的表达来描述案件,而法律条款都是用司法语言进行描述的,这造成了案件描述与法条描述的割裂.违法主体实体识别的目的是识别出案件中违法主体的具体类型.主要针对如下问题:当有些违法行为基本一致,但责任主体类型不同时,系统提取出来的证据非常相似,但它们的适用法条很可能大相径庭.
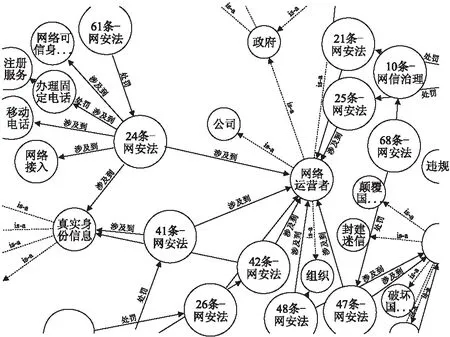
图3 《网络安全法》知识图谱部分可视化Fig.3 A part of law knowledge graph
违法事件和违法主体实体识别可有效地将纷繁复杂的案件描述概念化,从而使得模型能够更容易地对其违法行为进行识别.具体来说,实体识别分为实体检测和实体链接两个步骤,具体说明见3.3.1-3.3.2节.
3.3.1 实体检测
实体检测的目的是找出案件描述文本中可能是违法事件实体或违法主体实体的部分,并尽可能地过滤掉无关的部分.总体来说,违法事件大多是“动词+名词”短语的形式,有些落脚点在动词(如“对公司服务器进行渗透”中的“渗透”),有些落脚点在名词(如“未落实网站防护工作”中的“网站防护工作”).而违法主体则基本上是名词.因此,先根据词性标注技术提取出符合上述词性的关键词或关键短语(称为候选关键词),则违法事件实体和违法主体实体就可在候选关键词中筛选得到.
3.3.2 实体链接
违法事件实体链接:违法事件实体链接是指将口语化的违法事件描述(即候选关键词)对应到网络安全法知识图谱中相应的违法事件实体节点(即事件类型的法律实体节点).例如,将案件描述文本中的违法事件描述“枪支弹药”对应到知识图谱中的“违禁物品”节点,将案例中的违法事件描述“淫秽色情”对应到知识图谱中的“不良信息”节点.
违法事件实体链接过程分两步进行.
步骤1.计算每个候选关键词与知识图谱中所有违法事件实体节点的编辑距离D[14].若D≤2,则将当前违法事件实体节点视为可链接的候选.
步骤2.若可链接节点有且仅有一个,则直接将该候选关键词与该违法事件实体节点链接.若可链接节点有多个,则计算候选关键词的词向量与可链接节点的词向量之间的余弦相似度,并选择相似度最高的违法事件实体节点进行链接.若无可链接节点,则将所有违法事件实体节点视为候选并一一计算词向量余弦相似度[15],在相似度大于阈值λ的所有违法事件实体节点中选择相似度最高的作为与该候选关键词链接的节点.如果没有相似度大于λ的节点,则该认为该候选关键词不是描述违法事件,予以删除.在完成与违法事件实体的链接后,再通过当前违法事件实体节点的包含关系找到对应的违法事件概念节点(即事件类型的法律概念节点),则此节点就是这一起违法事件的类型.
之所以使用编辑距离与词向量结合的方式,是由于编辑距离只能计算词频相似度,不能计算语义相似度.例如,编辑距离可以计算出“入侵”与“侵入”是相似的,但对“入侵”与“攻击”这样的状况时就会力不从心.实验证明加入词向量技术可以有效的解决这个问题.
违法主体实体链接:在实验中我们发现有些案件描述文本中违法事件基本一致,仅仅是因为违法主体不同而导致主被动关系变化,从而使得相关法规完全不一样的情况.例如,同样是“散布谣言”这一违法事件,当违法主体是个人或组织时,违背第12条,即传播不实信息;当违法主体为网络运营者时,则违背了第47条,即平台内容审核制度不完善.所以“违法主体”在案件分类工作中是一个不可忽视的重要的特征.
面向违法事件实体链接的方法难以适应违法主体实体链接的任务.这是由于违法主体可以是企业、组织、个人等,其具体数量不可控,难以在网络安全法知识图谱中做到全覆盖,导致大多情况下知识图谱中会缺少相应违法主体实体对应的节点[16].另一方面,虽然违法主体实体数量不可控,但违法主体类型却可以事先定义.因此,可在实体检测的基础上通过对违法主体实体进行类型标注的方式将其链接到网络安全法知识图谱中的违法主体类型节点.
基于以上原因,本文提出的违法主体实体链接的方法如下:首先直接使用候选关键词在知识图谱中的违法主体实体节点中进行检索,若匹配到完全一致的结果就直接链接,若无法匹配再通过命名实体识别(Named Entity Recognition,NER)或违法主体类型分类模型进行实体类型判定后再链接.
1)基于命名实体识别的违法主体实体链接
违法主体可以是企业、组织、个人等多种类型.其中,企业、组织等又可以进一步细分为运营商、生产商、媒体等,而个人不需要进一步细分,因此对个人和其它(包括企业、组织等)采用不同的实体链接方法.由于对人名的识别已有较为成熟的解决方案,本文采用命名实体识别技术进行个人的违法主体实体链接,命名实体识别工具采用基于BiLSTM-CRF结构的FoolNLTK(3)https://github.com/rockyzhengwu/FoolNLTK分词工具.
之所以仅使用NER识别个人实体,而不使用NER识别其它实体类型(如企业、组织),是由于命名实体识别模型需要大量的特定领域已标注语料来训练,且对专业背景知识要求较高、标注难度大.而如果仅仅使用通用语料(如开放的命名实体识别工具),则相应命名实体识别模型可识别的实体类型有限,只能识别如人名、时间、地点等实体,无法识别出企业的具体类型.如在“因在个人微信公众号发布大量违法反动言论,黄某被当地派出所拘留”这样的输入中,“黄某”可比较容易被识别为个人实体,但“微信公众号”却难以被识别成一个网络媒体平台.由于《网络安全法》颁布时间不长,作为判案依据不多,这方面的语料很少,以此为基础新训练出的NER模型效果较差.
2)实体类型分类
对于企业、组织等需要细分的违法主体,本文使用分类模型来完成实体链接.首先对案件描述文本分词并按照3.1节的规则进行实体检测,得到一个候选关键词列表Keylist={k1,k2,…kt…,kn},并将代表违法事件实体和个人的候选关键词过滤掉,在此基础上对剩余的候选关键词进行分类.由于单独的一个候选关键词信息量过少,难以进行准确分类,因此基于外部开放知识库对候选关键词进行特征扩展,具体方法如下:
首先,利用外部开放知识库(本文使用开放的大型知识图谱CN-DBPedia)对候选关键词进行检索,能够得到这些候选关键词对应的实体与实体属性.例如,关键词“乐视”对应的实体属性有“公司 网站 股票名称 股票传媒 股票创业板 乐视”,关键词“城堡争霸”则对应“游戏 游戏作品 手机游戏 单机游戏 手机网游 城堡争霸”等实体属性.可利用这些实体属性对候选关键词进行分类.部分关键词无法通过通用知识图谱检索到相应实体,也就没有对应的实体属性,此时就直接用关键词本身作为其属性进行分类.
以实体属性为语料,利用DNN神经网络训练多分类模型Model,对违法主体实体进行分类,分类结果为 “网络运营者”、“产品/服务”、“其他”3类.具体来说,是将短语列表Keylist进行逐词分析,每一个词都经过通用知识图谱寻找对应的属性列表.以各个词对应的实体属性作为分类模型Model的输入,输出该词是否属于违法主体实体,如果是,则输出具体种类.
3.4 案件分类模型
本节主要介绍案例分类模型的构建,包括如何对数据进行预处理,模型的网络结构与训练参数.
3.4.1 预处理
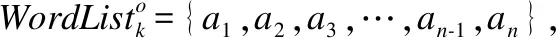
3.4.2 DNN模型构建
本文采用深度神经网络(DNN)进行案例文本分类.本文中DNN的结构如图4所示,该网络包括输入层,词向量规整层,句向量层和输出层4个部分.

图4 DNN网络结构图Fig.4 DNN network structure diagram
首先,将预处理后的案例,即WordListk′输入模型.当WordListk′经过词向量规整层,使用预先训练好的Word2Vec模型得到该案例中所有词的词向量表示.部分实体是使用短语或较长的词组表示的,需要先将这些实体分词,再使用分词后的词向量均值作为该实体的向量表示.对WordListk′中词与实体的词向量进行加权平均,并将得到的加权平均值作为整句话的句子向量.这样可避免不同句子长度不一造成的特征长度不一致的问题.通过句向量层后,所有案例均统一到同一个向量空间中,由长度相等的句子向量表示.将计算出的句子向量传递到接下来的隐藏层,本模型有两层隐层,隐层之间为全连接结构,激活函数为ReLU.另外,还在在隐藏层中加入了Dropout机制来防止过拟合.最后是一个神经元数量为8(与样本类别一致)的输出层,激活函数为Softmax.

表1 DNN算法流程Table 1 DNN algorithm flow
隐藏层的运作机理如表1所示,每次训练均根据训练集与结果的值,使用RMSProp算法不断迭代更新模型中的参数.
4 实验结果分析
4.1 数据集介绍,评测方法、指标等介绍
本文在实验中使用了两套知识图谱,第1套是复旦知识工厂提供的中文通用百科知识图谱CN-DBPedia[17].第2套为本文构建的针对《网络安全法》的小型知识图谱.
本文使用的原始数据分3个部分,一是《网络安全法》法律原文文本,二是社会案件,三是用于实体分类的数据.其中,法律原文文本来自中国人大网.社会案件为人工从互联网上收集,包括已经结案的与明显违背某项条款的,共61宗.根据案例的判决依据条例与处罚类型的不同分为8类,分别是:
1)未落实网络安全等级保护制度,未履行网络安全保护义务;
2)未履行个人信息保护义务;
3)未落实真实身份信息认证;
4)未履行网络信息内容审核义务;
5)网络产品和服务不符合法定要求;
6)传播不实信息和谣言,人身攻击;
7)计算机攻击行为;
8)网络诈骗,违禁物品售卖等涉及非法交易的行为.
实体分类数据以100个互联网公司名、50个产品名、50个其他名词(非公司非产品)为基础,通过通用知识图谱搜寻并筛选,排除特征不足3个的名词,最终得到包含实体名称与实体特征的85个公司实体、37个产品实体、260个其他名词实体(包括同名不同含义).部分数据摘录如表2所示.
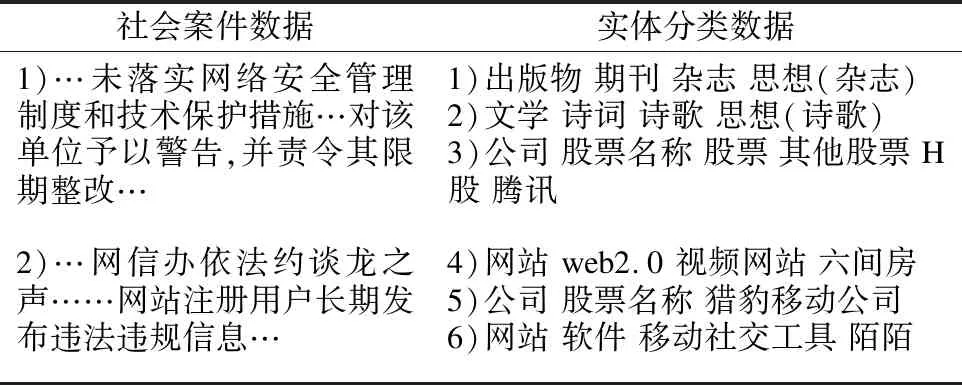
表2 数据集摘要Table 2 Data set summary
文本所用的词向量是由维基百科中文语料训练而来的通用词向量,维度为128.实验采用10折交叉验证(即每次抽取90%的数据作为训练集,剩余10%作为测试集,并记录平均测试结果).
4.2 违法主体实体链接性能测试
本实验测试本文提出的基于分类的违法主体类型识别模型.本文提出的模型最主要的创新为在分类模型中引入了通用知识图谱特征,因此将本文提出的模型与直接分类模型(即不引入通用知识图谱特征的分类模型)进行对比.文本采用十折交叉验证(Cross Validation)计算正确率(Accuracy)、召回率(Recall)、精度(Precision)与F1-Score四项数值指标,并绘制ROC曲线.测试得到各项指标结果如表3所示,ROC曲线见图5.其中class 0:其他,class 1:网络运营者,class 2:产品/服务.

表3 违法主体类型识别模型对比测试结果Table 3 Result of illegal subject type recognition model
从表3与图5可以看出,对于违法主体类型识别,在引入了通用知识图谱特征后,分类效果得到了显著的提升.这是由于原始词汇指代对象十分模糊、语义很弱,但利用通用知识图谱则能够获得原始词汇中包含的概念特征,这些概念特征使得词汇指代的对象变清晰、语义变得明确.即,若不同词汇通过知识图谱查询到数个共同特征,则可以判断这些词汇属于同一类的可能性很大.
举例来说(表4), “新浪”,“腾讯”与“智联招聘”三者在词的层面没有相似特征.如果转换成词向量,“新浪”与“腾讯”的相似度高达74.9%,这是由于预训练词向量的语料中涉及大量描述“新浪”与“腾讯”的文档.但是,由于描述“智联招聘”的文档极少,因此预训练词向量中无法找到“智联招聘”的词向量表示,无法通过词向量度量其与“新浪”与“腾讯”的相似度.引入通用知识图谱特征后,三者分别增加了表4右侧的内容.这些高辨识度共同概念特征的加入,有效地提升了模型的准确率.
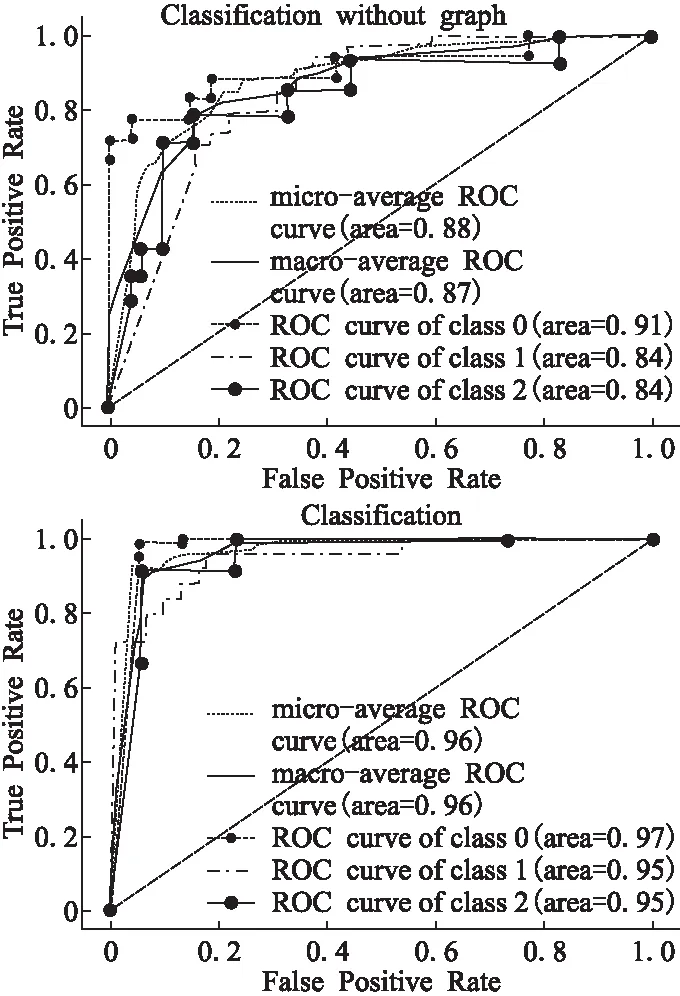
图5 违法主体实体分类的ROC曲线Fig.5 ROC curve of illegal entity classification

表4 使用知识图谱扩充语料实例Table 4 Examples:using knowledge graphs to expand corpus
4.3 案例文本分类实验
为对本文的案例分类方法(称为TCSE)性能进行评测,本文将其与以下4种方法进行对比,其中包括一个传统的检索方法与3个文本分类方法:
SM:即基于信息检索的方法.给定一个案例文本,首先使用TextRank算法从中提取top-K关键词与各关键词在句子中所占权重,然后基于这K个关键词在历史案例库中进行全文检索(实验中,K=10),并制定规则为给定案例与候选结果的相关程度进行打分,选择得分最高的作为检索结果.该检索结果对应的类别即判定为给定待检索案例的类别.使用公式(1)进行打分:
(1)
其中,Score表示某候选案例的的得分,Weighti表示案例中第i个关键词的权重(由TextRank算法得到),Counti表示第i个关键词在该结果中检索到的次数,Counti允许为0.
TC:直接使用案例文本进行文本分类.将现有语料分词,对分词结果分别计算词向量的词向量统一长度后作为神经网络的输入进行分类.
TCS:在方法TC的基础上,仅加入违法主体实体链接模块,先得到语料中的违法主体类型,再将违法主体类型作为附加特征,结合词汇特征与附加特征后再进行分类.
TCE:在方法TC的基础上,仅加入违法事件实体链接模块,利用法律知识图谱将违法事件实体链接到合适的法律概念上,并将这些概念所属的违法事件类型也视为特征,结合词汇特征与附加特征后再进行分类.
因检索方法与分类方法得到的结果形式存在差异,在检索方法中一个待检案例可能有多个检索结果,无法计算召回率、精度和F1分数,故结果分开描述.如表5、表6所示.在表5中的数据为10次实验的平均值,正确率(Accuracy)即检索到的结果与测试案例的真实类别严格属于同一类的比例.包含率(Include rate)即检索到的结果包含测试案例真实类别的比例.误检率(Error rate)即检索到的结果与测试案例的真实类别均不一致的比例.

表5 检索方法(SM)实验结果Table 5 Result of SM
由表5结果知,检索方法SM存在一个待识别案例会检索到多个答案的情形,且整体正确率偏低.

表6 分类方法性能测试结果(含SM)Table 6 Results of classification tests(include SM)
表6可以看出,文本分类方法整体优于传统检索方法.4个文本分类方法有随着特征量变大正确率升高的趋势.
相较于基础文本分类模型(TC),在使用违法主体识别模型对原数据进行处理后(TCS)分类结果提升并不明显,甚至在精度上还有所下降.经过分析,我们发现造成这种结果的两个原因:一是因为违法行为一致而违法主体不同的案例非常少见,即使成功识别出了违法主体的差异并使原来有误判的案例分类正确,对整体的正确率提升仍然不大.二是因为违法主体识别模型从社会事件中识别出违法主体特征并根据规则赋予较高权重后,违法主体部分较高的权重也会使原本相同违法主体但违法事件不一致的案件归为一类,即向原始数据加入一个高权重的新特征在某些情形下对原来的模型有些矫枉过正.
当基础模型增加了违法事件实体识别的特征后(TCE),分类结果获得了明显的提升.这是由于在各案例中都普遍存在使用日常口语来表述违法事件的情况.将这些口语对应的法律专业用语识别出来,并与图谱中的法律概念实体进行正确的链接之后,待分类事件的有效法律概念特征显著增加,使得案件分类的正确率改善明显.
当同时考虑违法主体特征与违法事件特征后(TCSE),两种新特征共同使用使得原本TCS中矫枉过正的问题被解决了.因为原始数据被加入了一串高权重的新特征,新特征之间对被赋予的高权重平均分配,冲淡了每个单个特征的影响力,使得模型更加稳定.即除了违法事件特征以外,还充分地利用到了违法主体实体这一特征.从结果上来说,TCSE的综合表现也确实优于其他3个对比试验.
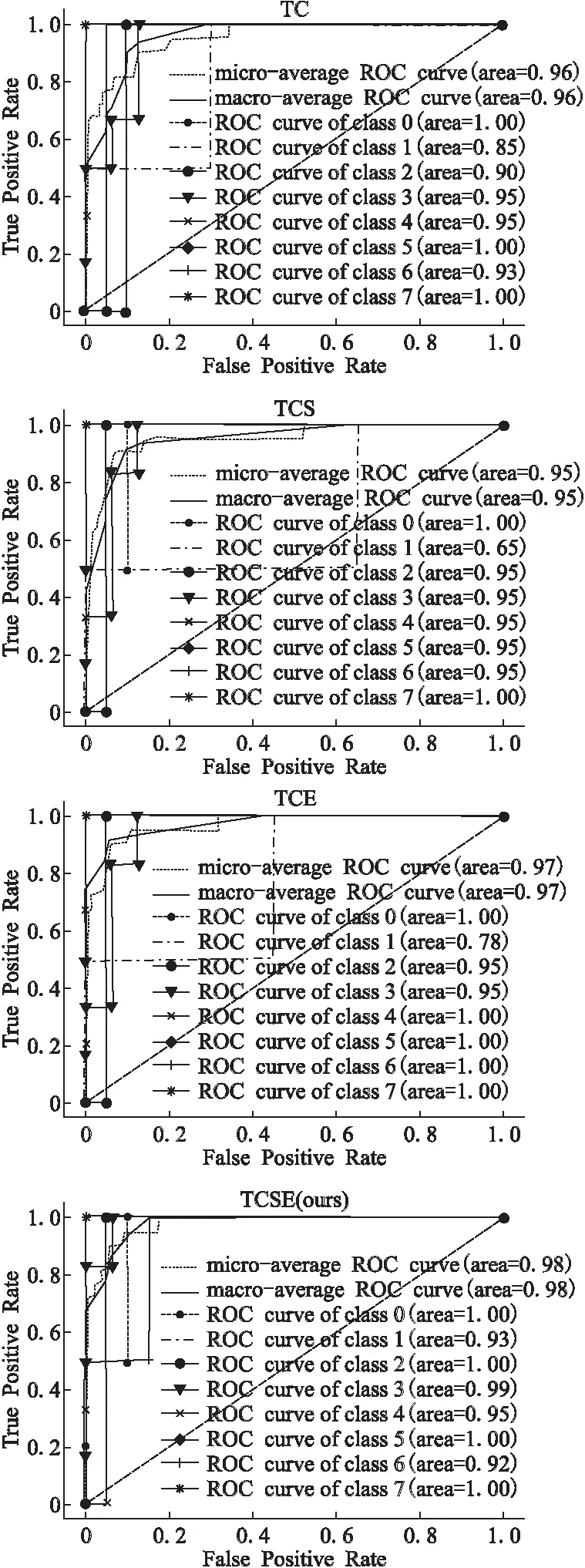
图6 4组案例分类实验的ROC曲线图Fig.6 ROC curve of case classification
以上结论在ROC图中一样能够观察到,4组实验的ROC图像如图6所示.
class 0-7分别为:未落实网络安全等级保护制度,未履行网络安全保护义务;未履行个人信息保护义务;未落实真实身份信息认证;未履行网络信息内容审核义务;网络产品和服务不符合法定要求;传播不实信息和谣言,人身攻击;计算机攻击行为;网络诈骗,提供,售卖违禁物品等行为.
从图6中可以看出,有些类别的分类结果一直很好,如未落实网络安全等级保护制度(class 0),网络欺诈、售卖违禁物品(class 7)等.这是因为这些类别与其他类别的重点不一样,本身就有着明显的特征.有些类别的分类状况较不稳定,其中尤以类别1、2、3最易混淆.这是因为这3类违法类型的违法主体相同(网络运营者),违法情形相似(平台或服务方面的信息准入与审核制度不完善).这就导致了这些案例在描述时语言的选用与组织形式可能都十分相似,也就使分类变得困难.尤其是当仅仅使用违法主体识别模型而不用法律知识图谱对案例进行处理时,“违法主体”这一特征被识别出来,并被赋予较高的权重在分类中起作用,这样的处理使这3类的相似度进一步提高,分类结果就更差了.在此基础上加入法律图谱,则一方面使相对过高违法主体特征的权重被削弱,另一方面提取了不同类别中的其他特征,使不同的类别之间的区别变大,从而优化了分类结果.
5 总 结
多年来,法律领域已有各种违法行为识别系统,但大多都是通过传统的检索方式来完成,这种方式不仅效率低,且常常需要专业的背景知识来利用特定的法律关键词进行检索.近年来,随着机器学习技术的发展,出现了一些基于机器学习和深度学习的违法行为识别系统,但这些系统依赖大量高质量的历史案例,在新兴的法律领域难以发挥作用.针对上述问题,本系统基于知识图谱设计面向《网络安全法》的违法行为识别系统,首先构建网络安全法知识图谱,在此基础上利用知识图谱将法律概念术语与日常用语关联,从而极大的强化了案例特征,使得基于少量样本就可以训练出泛化能力较强的模型.实验结果表明,相比于传统的检索方式,或是基础的深度学习文本分类,本文的系统都能取得更好的效果.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
新传奇(2022年12期)2022-04-20
计算机系统应用(2021年11期)2022-01-06
证券市场红周刊(2021年42期)2021-10-30
当代陕西(2019年5期)2019-03-21
新城乡(2018年6期)2018-07-09
环境(2018年2期)2018-03-17
21世纪商业评论(2018年3期)2018-03-02
环境(2016年6期)2016-05-14
