
基于段落选择的分层融合阅读理解模型
2021-04-10 06:10:16杜军威李浩杰
青岛科技大学学报(自然科学版) 2021年2期
孙 驰,杜军威,李浩杰
(青岛科技大学 信息科学技术学院,山东 青岛266061)
近年来,自然语言处理的不同子任务中,基于深度学习的模型不断刷新相关任务的性能记录[1]。子任务中,机器阅读理解则一直被认为是NLP的标志性临界点,其目标是让机器同人一样,可以阅读并理解文本,回答有关该文本的问题。机器阅读理解在智能问答、智能搜索、语音控制、构建知识库等方面具有广阔的应用前景[2]。
从数据集的类型出发,可以将阅读理解划分成完形填空型[3]和区间抽取型[4]等。其中,完型填空类的代表数据集为CNN/Dailymail[5],而区间抽取型的代表包括斯坦福RAJPURKAR等2016年发布的SQu AD[4]以及微软发布的MS MARCO[6]。完形填空型数据集中的文本均经过精心处理,提前挖空。要求模型根据空位前后上下文预测缺失词,解决这类问题大部分只需获取空位局部的上下文就能很好解决问题,不需要捕捉文本全局信息。因此,模型离真正理解文本还有很大距离。而区间抽取型的数据集[7-8]则是基于真实问答数据集构建的,例如SQu AD数据集根据维基百科语料,采用人工提问题的形式进行构建。区间抽取型数据集要求模型根据问题从候选文本中抽取出答案区间,解决这类问题通常要捕捉全局上下文信息,对文本有全局理解。
SQu AD数据集发布之前,研究者在完形填空式数据集上展开工作。HERMANN等[9]借鉴机器翻译和计算机视觉领域的注意力机制,在模型中引入问题和文本对应向量的权重交互层,捕捉问题和文本之间的注意力信息,第一次将注意力机制引入到机器阅读理解领域。
在SQu AD发布后,WANG等[10]提出Match-LSTM模型,引入单词级别的权重匹配和信息交互。同时,结合指针网络预测答案的起始和结束位置。为捕捉每个注意力重要程度,CUI等[11]引AOA(层叠注意力机制),在注意力层上又引入一层注意力。微软研究人员设计的R-Net[12]则通过引入自注意力捕捉文本本身的重要特征。除了经典的时序模型,YIN等[13]在机器阅读理解中引入了卷积网络,利用卷积捕捉问题和文本特征。NISHIDA等[14-17]则开始研究多文档阅读理解问题。中文数据集Du Reader[8]的发布,也推动了中文机器阅读理解的发展,郑玉昆等提出的T-reader[7],基于R-Net模型基础上引入人工特征并在Du Reader上做了探索,段利国等[2]则是针对Du Reader数据集中的观点类问题进行了探索。
上述模型在多段落数据集上存在的问题主要是未从正确段落抽取答案。原因在于不同段落都可能存在相似答案,而答案是从一个段落中抽取,一旦模型未选择正确答案所在段落,就会降低模型抽取答案的质量。而那些针对Du Reader设计的模型如Treader等,处理多段落方法主要分两种:多段落拼接为单段落和多段落均生成答案后进行答案筛选。显然,这两种方法都会增加计算量和模型复杂度。针对这一问题,本研究设计基于段落选择器的分层融合阅读理解模型。通过段落选择器从候选文档的多段落中选出最佳段落,然后分层融合阅读理解模型通过双向注意力[8]捕捉文本交互信息以及分层融入层级输入表示确保不同粒度特征不丢失。在Du-Reader数据集[8]上,本研究提出的模型取得了较好的效果。
1 模型设计
首先定义要解决的问题为在给定问题Q和段落集合P={p1,p2,…,p N}的前提下,经过输入层对Q和P进行词向量化,然后通过段落选择器选出最佳段落p,在p中通过分层融合阅读理解模型预测答案的起始位置和结束位置,使得和概率乘积最大。通过实验验证段落选择对分层阅读理解模型的性能是否有提升。
1.1 输入层
为消除多义词和未出现词干扰,输入层使用了上下文相关的ELMO[1]词向量模型。输入层的输入为问题q,q∈Q以及多个相关段落集合P={p1,p2,…,p N}。通过ELMO词向量模型获得问题和文档融合了上下文语义信息词向量。

1.2 段落选择器
段落选择器根据问题和段落关联度从多个段落中选择出最佳段落。段落选择器PSNet由BiLSTM编码层,自注意力层,拼接层以及归一化层四部分组成(见图1)。

图1 段落选择器Fig.1 Paragraph selector
首先,将输入层得到的问题和段落的词向量

然后,经过自注意力[12]层,提取问题和段落各自句子中的重要特征。自注意力本质上是句子内部所有的词语参与投票并为每个词都进行打分,从而获得句子内布所有词语的重要程度。最后得到蕴含自注意力的问题和段落的向量表示。打分,计算重要度,融合自注意力向量分别与下列公式依次对应:
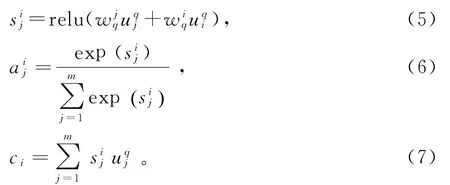
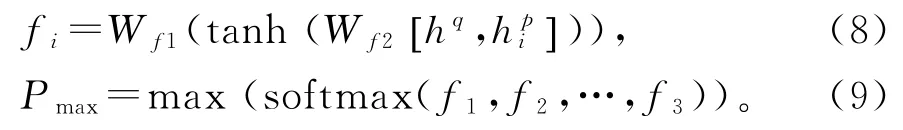
段落选择器损失函数为交叉熵。因为段落选择器模型本质上为一个二分类问题。训练数据集上,答案所在的段落是可以明确。因此,可以将每个问题的答案所在段落作为训练标签。同时,为避免过拟合,引入Dropout机制[18]以及L2正则项[19]。损失函数中y i取值为0或者1,1表示是正确的段落,0表示不是正确的段落。

1.3 分层融合阅读理解模型
为了不丢失每层问题和段落向量表示的部分特征,本研究设计分层融合的阅读理解模型(见图2),在每层的向量经本层处理后,把本层的初始输入向量的与输出向量进行拼接一起输入到下一层。在特征提取阶段,模拟人类带着问题阅读段落以及读完段落重新审查题目的过程,本研究引入了问题和段落的双向注意力[1]。
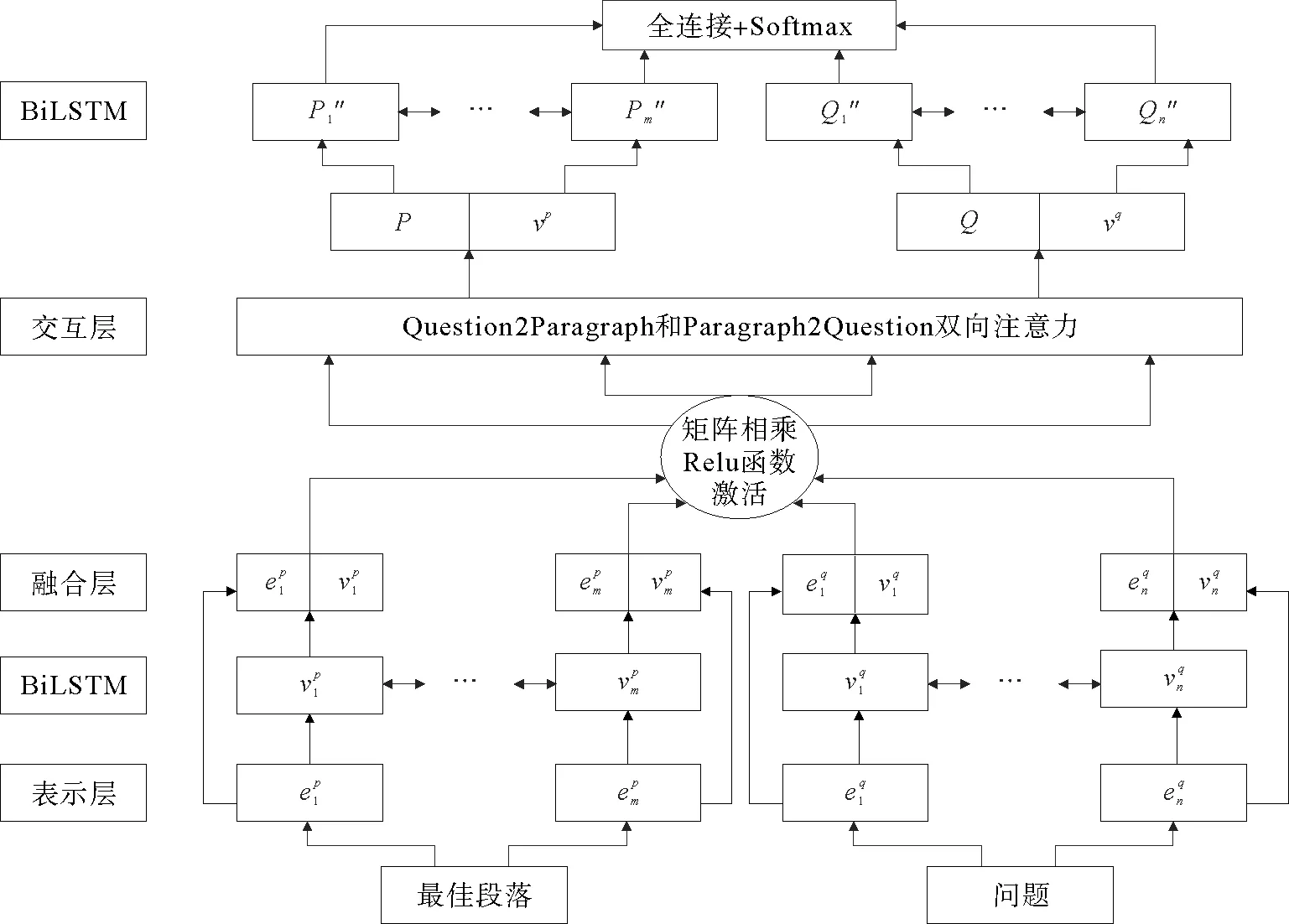
图2 分层表征融合阅读理解模型Fig.2 Hierarchical representation fusion reading comprehension model
分层融合阅读理解模型包括Bi LSTM层,通过从前往后和从后往前两个方向的阅读捕捉句子级别信息。根据公式(11)和(12)分别处理问题和段落。再将原始输入的向量q′和p′分别与v q和v p拼接。更新v q和v p。
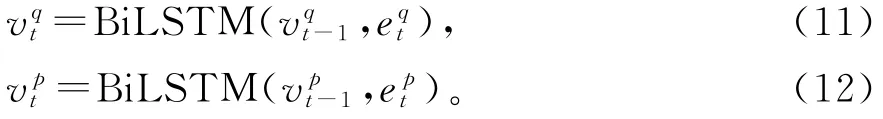
更新v q和v p后,根据公式(13)求相似度矩阵。其中,Sij代表的是问题中的第i个词与段落中的第j个词之间的相似度,WS是个待训练的参数矩阵。
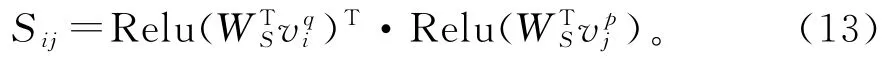
进而引入问题到段落(Question2Paragaph)的注意力机制,为问题中的每一个词捕捉段落中与其最相关词的注意力信息。从Sij的定义可以得出,S矩阵每一行代表的是问题中的某个词与段落中的所有的词,S矩阵的每一列则代表的是问题中的所有词以及段落中的某个词。要从段落词中找到与当前问题词最相关的词,只需根据公式(14)将段落中所有词与当前问题词的相似度用softmax归一化,算出每个段落词对当前问题词贡献的权重值。再将所有段落词与其对应的权重值相乘后相加就得到该问题词的问题到段落注意力向量Qi。
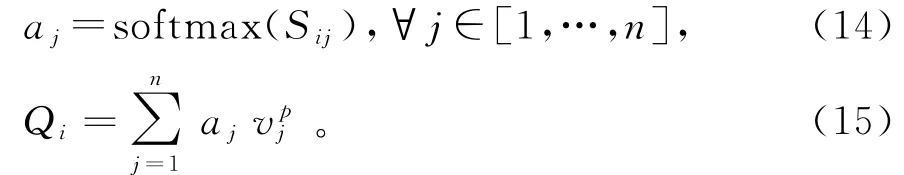
同样利用段落到问题(Paragaph2Question)的注意力机制,为段落中的每一个词捕捉问题中与其最相关的注意力信息。这里的计算步骤跟上面计算问题到段落的注意力向量时基本相同,只是计算的方向正好反了过来。这里不再展开。
得到带有段落到问题的注意力向量段落P以及带有问题到段落的注意力向量问题Q后,将本层输入向量v p和v q分别与段落向量P和问题向量Q拼接融合,得到P′和Q′。

将P′和Q′再经过BiLSTM整合语义信息得到P″和Q″,根据公式(18)和(19)预测答案的起始位置和结束位置。
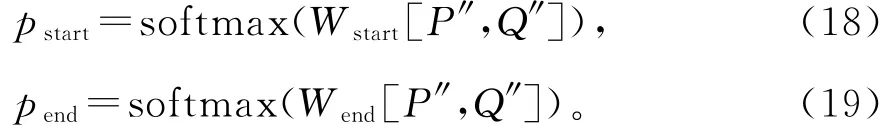
式(18)和式(19)中的Wstart和Wend分别是预测开始位置和预测结束位置的权重矩阵。当pstart和pend乘积最大,此时的pstart和pend对应位置就是模型预测的答案起始位置和结束位置。
2 实验部分
2.1 数据集
实验数据采用百度NLP团队发布的Du Reader数据集。通过统计分析,发现在Search部分有1.5%没有答案,36.3%为单个答案,62.2%有多个答案。而在Zhidao部分多个答案的现象更加明显,9.7%没有答案,19.5%为单一答案,70.8%为多个答案。数据集中每个数据样本包括问题,问题的类型,段落集合以及人工生成的标准答案集合。实验从原数据集中选取了25万条数据,其中训练集为21万条,开发集1万条,测试集3万条。样例数据如表1所示。同时统计整个实验数据中各个文档段落数目的分布。如图3所示。
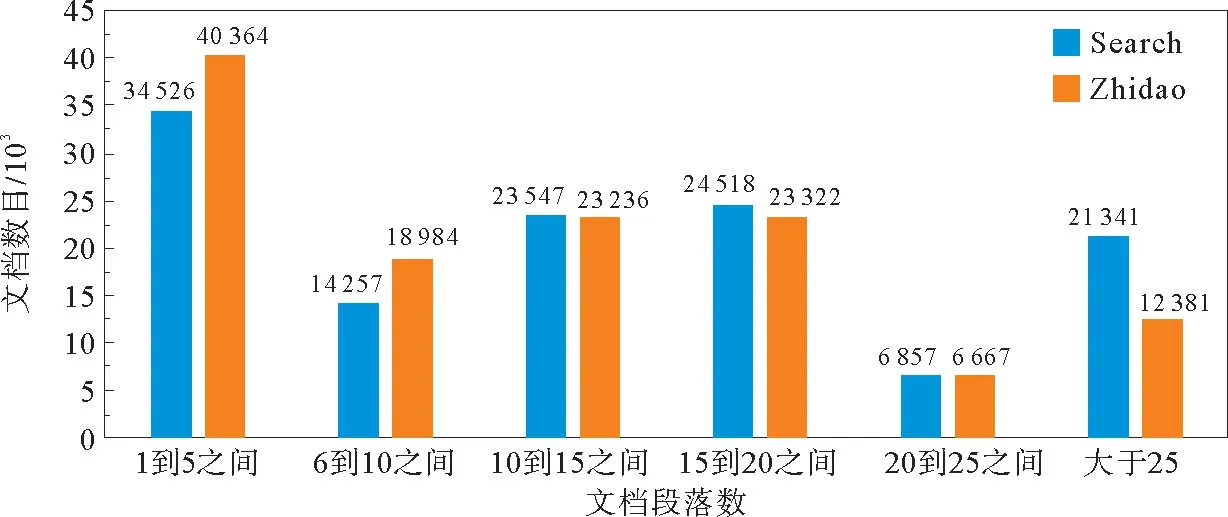
图3 文档段落数分布Fig.3 Document paragraph number distribution

表1 初始数据样例表Table 1 Initial data sample table
从图3看出,在实验数据上段落数目大于5的文档数超过了17万,占总数的68%,表明在实验数据中一大半的文档都是多段落的,也为段落选择实验提供了可能。
由于本研究选择的数据集多文档,多段落的现象突出,表1所示,该问题的候选文档共有5个,每个文档都有多个段落。本研究实验按照两步走进行设计。
1)通过段落选择器在多个文档、多段落中选择最佳段落。例如,在表1中5个候选文档中,通过段落选择器选择到第一个文档的第一段为最佳段落。
2)将选择的最佳段落送入到分层融合阅读理解模型,提取参考答案所在的区间。例如,在表1中,第1个文档中的第1段为最佳段落,输入到分层融合阅读理解模型,输出起始位置。
为了证明本研究提出方法的实验效果,设计3个实验进行对比分析。
1)本研究提出的模型与Dureader推荐的基准模型BiDAF,Match-LSTM和主流模型R-Net的实验效果对比。
2)本研究提出的段落选择器在段落选择上与BLEU-4选择器进行对比分析。
3)本研究模型、BiDAF,Match-LSTM和R-Net在有无段落选择器的实验效果对比。
4)段落选择器选择段落数目对比实验。
2.2 实验设置
本实验的硬件环境如下,处理器为Intel I7 9700 k,内存大小为32 G,显卡为NVIDIA GTX1080。开发语言Python 3.7,深度学习框架为Pytorch 0.4.0。系统为Ubuntu 16.04。模型使用到的超参数见表2。
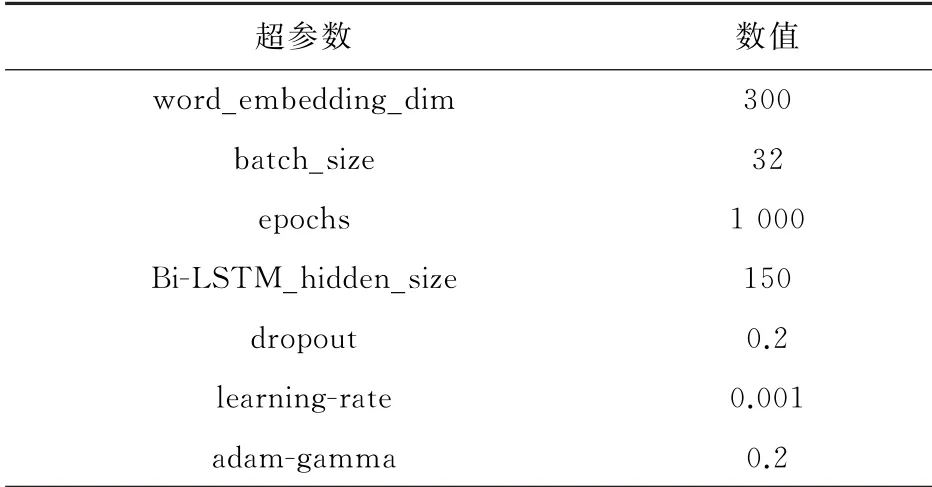
表2 模型超参数Table 2 Model superparameters
2.3 实验结果及分析
Du Reader的数据来源为Search和Zhidao,且两部分文档差别较大。实验对比时,分别在这两个数据集上做实验。并与基准模型BiDAF,Match-LSTM进行对比,同时引入R-Net做对比,表中准确率指模型抽取的答案在参考答案所在段落比率。
观察表3,发现所有模型在Zhidao数据集上的评价指标都好于Search上,原因是Zhidao数据来自百度知道问答社区,对已回答的问题,答案显示存在段落中。相比BiDAF和Match-LSTM基准模型,本研究提出的模型在总数据集上Rough-L,Bleu-4以及准确率分别提升大约11%,12%以及14%。

表3 不同模型的结果Table 3 Results of different models
然后对比不同的段落选择方式对模型的影响。同时将基于Bleu-4[8]指标的段落选择器命名为Bleu-4选择器。
观察表4,基于Bleu-4的段落选择对模型的性能有提升,对比无段落选择器提升幅度在2%~3%。表明段落选择器起到作用。所有选择器中,本工作设计的PSNe提升提升最大。原因为,PSNet试图从语义理解层面去计算匹配度,而其他段落选择器只是捕捉文本浅层信息,并未对文本进行理解。
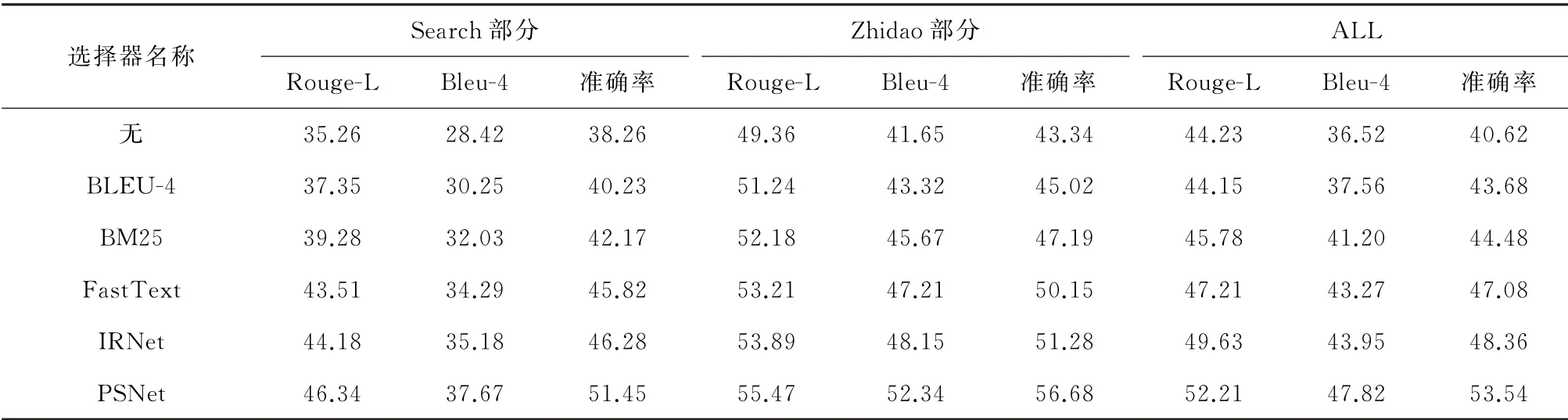
表4 不同段落选择器的结果Table 4 Results of different paragraph selectors
最后,限定模型从参考答案所在的段落中定位答案区间。实验在ALL数据集上进行对比。
观察表5,为模型指定参考答案所在段落后,表5中前3个模型均有至少10%左右的性能提升。本研究模型在直接指定最佳段落时,模型Rough-L指标以及Bleu-4指标分别提升了大约6%以及4%。
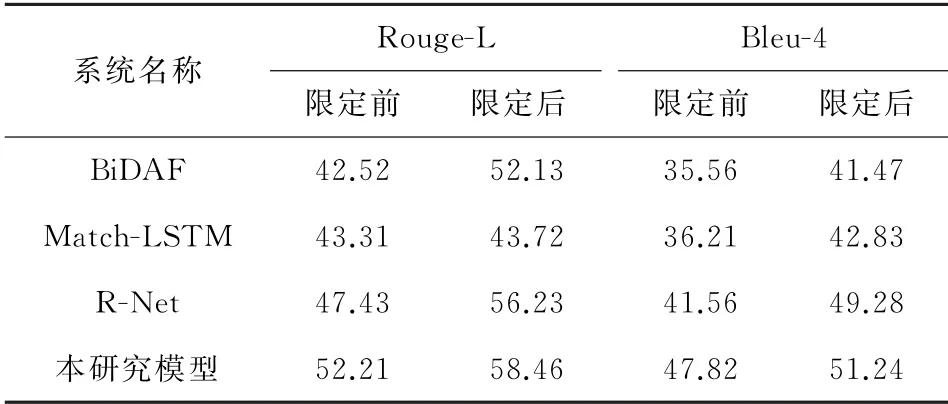
表5 不同模型指明参考答案所在区间前后的性能对比Table 5 Performance comparison before and after the interval of reference answers indicated by different models
本研究段落选择器只选择了关联度最高的段落,为了观测关联度前3,前5段落对模型的影响,本研究设计了段落选择器topk实验。实验结果见表6。
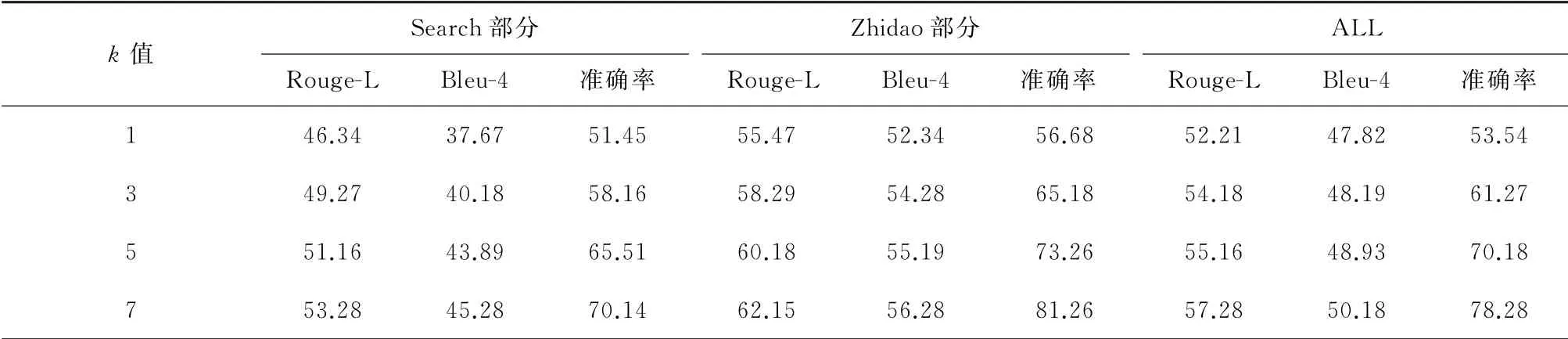
表6 不同模型指明参考答案所在区间前后的性能对比Table 6 Comparison of experimental results of paragraph number selection by paragraph selector
由表6可以得出,k值越大,最后选择的段落数越多,准确率也随着提升。表明,选择段落数越多,包含正确段落概率就会越大。准确率的提升可以提升模型的Rough-L指标以及Bleu-4指标。
实验结束后,统计是否引入段落选择器模型的训练时间,结果见图4。
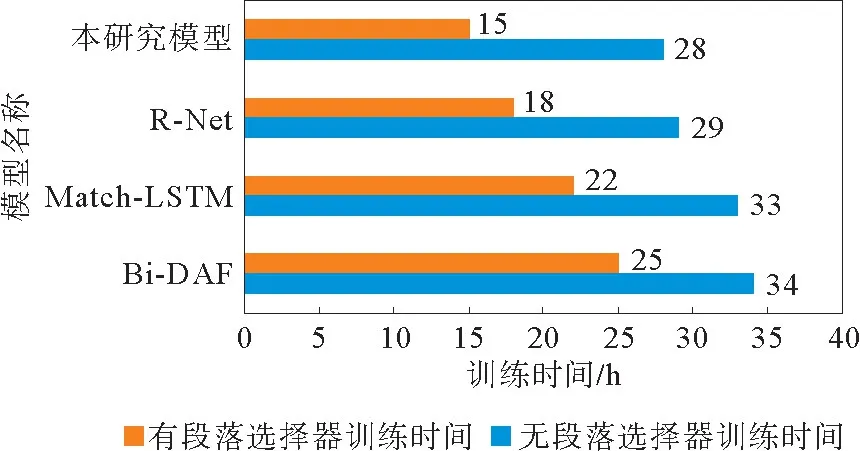
图4 有无段落选择器训练时间对比Fig.4 Comparison of training time with and without paragraph selector
观察图4,引入段落选择器后模型的训练时间均大幅降低,降幅最多为46%。表明模型确实能降低计算量和复杂性。
3 结 语
传统端到端的阅读理解模型在处理社区问答、搜索引擎等存在多个相似候选答案,而答案往往存在某一个段落的数据集时,存在段落选择困难、计算复杂度高和性能指标低的问题。针对这些问题,提出了一种基于段落选择的分层融合阅读理解模型,并且通过多组实验对比,验证了增加段落选择器能够显著提升机器阅读理解模型性能,为将来复杂机器阅读理解问题提供一种可行的途径。
但由于首次提出融合段落选择的阅读理解模型,其各项性能指标并不是最优,存在因为段落选择器不准确带来的预测不准确的风险,后期将考虑进一步提高段落选择器的预测精度和与阅读理解模型联合学习的方案。
猜你喜欢
电子工业专用设备(2024年1期)2024-02-29 02:24:46
中国新闻周刊(2021年26期)2021-07-27 04:02:12
小学阅读指南·低年级版(2020年9期)2020-10-12 02:43:08
阅读(快乐英语高年级)(2020年9期)2020-01-08 02:20:52
散文诗(2017年17期)2018-01-31 02:34:11
电脑与电信(2017年6期)2017-08-08 02:04:22
信息安全研究(2016年4期)2016-12-01 06:06:54
读写算(下)(2016年11期)2016-05-04 03:44:07
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
大学物理实验(2015年2期)2015-10-22 01:04:39
