
基于Lab颜色空间的分类器研究与设计
2021-04-09 05:11吴俊雄
北京信息科技大学学报(自然科学版) 2021年1期
吴俊雄
(北京信息科技大学 自动化学院,北京 100192)
0 引言
在光学字符识别中针对不同类别文本图片进行分类可以提高识别率。如果待识别图片中存在被红色印章覆盖的部分,比如发票类图片,则将这类图片分离出来单独处理能够改善识别效果。
目前图像分类技术大体可以分成3类。第1类是基于图像处理的方法,即根据不同类别图像的特征,人工设计分类器对各类图像进行分类。颜色、形状、纹理是图像常用的3大特征,其中颜色特征由于直观且易于提取而被广泛应用于图像处理领域。这类方法应用简单,但是泛化性能较差,且设计的分类模型依赖于设计者的经验[1-2]。
第2类是基于机器学习的分类方法,代表性的机器学习方法有k均值聚类法、支持向量机法(support vector machines,SVM)等[3-4]。这类方法通常是将输入图像的特征通过数学的方法转换成低维度的特征,再将低维度的特征输入机器学习模型中进行训练,使用完成训练的模型对图像进行分类。这类方法的优点是泛化能力强,数学理论完备,对于特征不明显的图像也有较好的分辨率,缺点是精度依赖于特征的提取,并且精度通常不够高。
随着卷积神经网络在计算机视觉中的大量应用,第3类方法即深度学习的分类方法由于其自身的优越性能,越来越受到学术界和工业界的青睐。该方法的优点是泛化能力强,鲁棒性强,准确率极高。分类的过程是将不同类型的图像打上标签,再将图像缩放到固定尺寸送入深度卷积网络中进行训练,将训练好的模型用于分类。这类方法通常需要大量的训练数据,小数据集上的分类效果不够好[5]。
在实际工程中分类方法的选择应该综合考虑多个方面。由于图像数据较少,本文没有使用基于深度学习的方法构建卷积神经网络,而是考虑到两类图像颜色特征鲜明,基于Lab颜色空间设计了一种分类器,用于区分出被红色印章覆盖的文本图片,识别正确率达到98.33%。
1 基于Lab颜色空间的分类器
本文中两类图像如图1所示,(a)为文字信息未被红色印章覆盖的图像,用A类表示;(b)为文字信息被红色印章覆盖的图像,用B类表示。识别中需要将这两类图像进行分离,方便后续对B类单独进行处理。

图1 A类和B类图像
1.1 Lab颜色空间
常用的图像颜色空间有RGB颜色空间、HSV颜色空间和Lab颜色空间。RGB颜色空间适合显示与存储图像数据,但不适合进行图像处理。
HSV颜色空间通过3个颜色分量来定义颜色:色调H代表不同的颜色;饱和度S代表颜色的纯度;亮度V 代表颜色明亮的程度。从该模型的定义可以看出3个分量对颜色的贡献度不同,H分量对颜色的贡献度最大,S分量其次,V分量最小。HSV颜色空间被广泛地运用到彩色图像处理中,包括颜色分类、颜色识别等[6]。
Lab颜色空间是由国际照明委员会所制定的具有国际标准的色彩模式,也称为CIELab。Lab由一个亮度通道(L)和两个颜色通道(a和b)组成,L代表亮度,a代表颜色从绿色到红色的转变,b代表从蓝色到黄色的转变。用这3个分量的不同取值就可以排列表示出自然界中存在的任意一种颜色[7]。
HSV和Lab两种颜色空间均适用于颜色分类,由于B类图像相比于A类,红色特征明显,而Lab空间中a分量对红色很敏感,所以本文基于Lab颜色空间对图像进行分类处理。
1.2 图像预处理
图像预处理的目的是为了增强图片的特征信息,有利于后续区分。首先将图片进行统一的缩放,缩放的尺寸为训练集的平均尺寸。其次,使用伽马变换提高图片中红色印章与白色背景的对比度。伽马变换作为一种图像增强的方法,常用来改变图片的对比度。其公式为
s=crγ
(1)
式中:c为常数,一般设置为1;r为像素值;γ为可选择的参数;s为新的像素值。由式(1)可知伽马变换会对图片的像素值做非线性变换。
设置γ值为0.7,对图片进行伽马变换,效果如图2所示,(a)为原始图片,(b)为经过伽马变换后的图片。由图2可知,伽马变换之后,红色印章与白色背景的对比度有所增强。

图2 伽马变换效果
1.3 设计分类器
先将RGB颜色空间表示的图片转换成Lab颜色空间表示,再单独将a分量取出来。由于A类图像没有红色印章,其a分量的值较小;而B类图像a分量的值较大。
图3(a)为A类图像的a分量直方图,横坐标代表像素值,即亮度,纵坐标代表像素点数目;图3(b)为对应图片的a分量灰度图,A类图像对应的a分量较小,表现为a分量灰度图没有高亮值。观察a分量直方图可知,其灰度图像素多分布在120至140之间。

图3 A类图像的a分量图
图4(a)为B类图像的a分量直方图,图4(b)为对应图片的a分量灰度图。由于a分量对红色敏感,表现为红色印章部分a分量值很高。

图4 B类图像a分量图
根据这一特性,设计分类器,算法步骤如下:
1) 将图片由RGB颜色空间转化成Lab颜色空间,并得到图像的a分量直方图。
2) 由1)可得图片不同像素值的像素数目,设定阈值ret。统计训练集中少数图片,大致观察ret在0~15之间,分别取阈值ret为3、5、7、9、11。找出图片a分量像素数目大于此阈值的像素值。
3) 设定阈值ret2,设定方法同ret。由2)可以得到图片a分量中大于阈值ret的像素值,取这些像素值的最大值,如果最大像素值>ret2,判断为B类,反之判断为A类。
4) 为了找到最优ret和ret2,对ret和ret2建立笛卡尔坐标系,采用网格搜索的方式在训练集中寻找最优参数。
5) 在最优参数的情况下,使用测试集验证结果。
1.4 结果分析
取ret分别为3、5、7、9、11,取ret2分别为162、165、168、171、174,对参数ret和ret2建立笛卡尔系,则一共有5×5种组合。
训练集为两类图片各70张,测试集为两类图片各30张。表1为设定不同参数时,对训练集中B类的识别正确率。例如设定ret2=165,ret=5,表示以像素值>165且像素数目>5为判断条件,满足此条件的图片被分类器判断为B类。

表1 对B类的识别正确率 %
表2为设定不同参数时,对训练集A类的识别正确率。
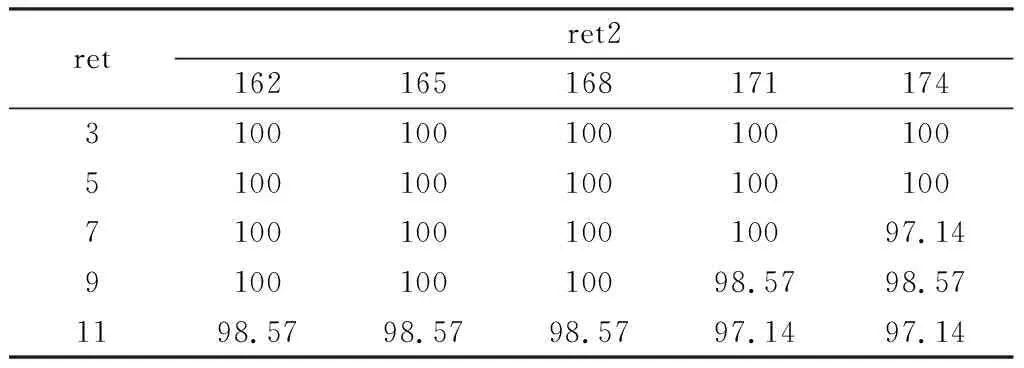
表2 对A类图像的识别正确率 %
从表1和表2可以看出,ret2=168时,训练集中A类和B类的识别率都比较高。取ret2=168,ret分别为3、5、7、9、11,用测试集验证两类图片的识别正确率,结果如表3所示。从表3可知,平均正确率达到98.33%
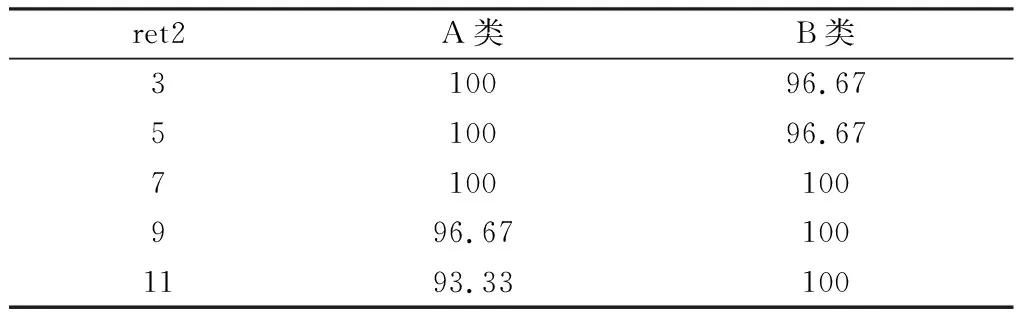
表3 测试集中两类图片的识别正确率 %
1.5 与基于SVM识别方法的对比
SVM是一种经典的机器学习方法,其原理是通过构建超平面将不同类别的样本进行分离,同时保证分隔的距离最大。SVM被广泛地运用到模式识别的手写数字识别、文本分类、图像分类与识别等众多领域中[8]。
为了验证本文方法的效果,使用SVM方法区分两类图像,比较两种方法的识别正确率。基于SVM的分类模型[9]步骤如下:
1) 图像缩放预处理。取训练集图片的平均尺寸为缩放尺寸,将图像扁平为一个特征向量;
2) PCA降维。为了防止维度灾难,先将特征向量进行降维得到低维度的特征;
3) 训练模型。使用sklearn库中SVM的相关函数,可直接调整核函数、惩罚因子等;
4) 寻找最优参数。采用网格搜索的方法自动寻找SVM的最优参数[10];
5) 模型持久化:对训练完成的模型进行参数固定。
在与本文方法训练集与测试集相同的条件下,通过调整超参数、调整核函数等,可以观察到基于SVM识别的正确率始终在82%~84%之间变化,无法超过85%。
2 结束语
本文提出了一种考虑图片颜色特征的分类方法,适用于数据集较小、颜色特征鲜明的图片分类场景。该方法与支持向量机方法相比性能更优。
本文的方法设定了两个阈值ret和ret2,并使用像素个数与像素值作为判断依据。算法的不足之处在于,像素个数与像素值在某些情况下会出现跳变,可能导致识别错误;由于数据集较小,也可能存在过拟合现象。
后续可以对本文方法继续优化,比如只设定一个阈值ret3,图像a分量的像素值大于ret3的部分做积分操作,使用积分后的值作为分类的依据;收集更多的数据图片训练验证等。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
医学食疗与健康(2022年3期)2022-04-23
电子产品世界(2022年4期)2022-04-21
健康体检与管理(2021年6期)2021-11-17
计算机系统应用(2021年2期)2021-02-23
读者·校园版(2020年19期)2020-09-16
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
计算机测量与控制(2019年4期)2019-05-08
英美文学研究论丛(2018年1期)2018-08-16
