
基于混沌映射的自适应樽海鞘群算法*
2021-04-08 08:38童斌斌何
传感技术学报 2021年1期
童斌斌何 庆*陈 俊
(1.贵州大学大数据与信息工程学院,贵州 贵阳550025;2.贵州大学贵州省公共大数据重点实验室,贵州 贵阳550025)
随着社会的不断发展,各种科学计算和应用问题的复杂性和规模也在日益增多,传统的数值优化方法难以在时间和求解精度上保持合理的平衡[1]。 近年来,群智能优化算法由于高效、易于实现、参数少等优点,受到了学者的广泛关注。 群智能优化算法作为一种仿生学优化算法,是通过模拟自然界生物的个体和群体行为发展而来,例如粒子群算法(Particle Swarm Optimization,PSO)[2]、 蝙 蝠 算 法(Bat Algorithm,BA)[3]、 正 弦 余 弦 算 法(Sine Cosine Algorithm,SCA)[4]、蜻蜓算法(Dragonfly Algorithm,DA)[5]、蚁狮算法(Ant Lion Optimizer,ALO)[6]、蚱蜢优化算法(Grasshopper Optimisation Algorithm,WOA)[7]等。
2017 年,Mirjalili 等提出了一种樽海鞘群算法(Salp Swarm Algorithm,SSA)[8],樽海鞘群算法是一种新型的群智能优化算法,通过模拟海洋中樽海鞘的个体和群体行为发展而来,在算法中由领导者和追随者两个子群组成,领导者处于樽海鞘链的前端,余下的作为追随者。
樽海鞘群算法由于参数少、计算量小、易于实现等优点[9-10],自提出后得到了广泛的应用,例如,张成军等[11]将混合樽海鞘差分进化算法应用于三维航迹规划;林国营等[12]将樽海鞘群算法应用于电网公司需求响应补贴定价;姚远远等[13]采用一种多目标樽海鞘群算法来解决TFT-LCD 面板阵列制程调度问题,并取得了较好效果。 Sayed 等人[14]把樽海鞘群算法和混沌理论相结合用于最小化所选特征的数目。
在算法层面上,虽然樽海鞘群算法与其他优化算法相比更加易于操作和理解,但算法仍然存在收敛速度较慢,迭代后期种群多样性较差、寻优精度不高等缺点。 针对上述缺点,很多学者对樽海鞘群算法进行改进。 刘景森等[1]针对基本樽海鞘群算法易陷入局部最优、寻优结果不稳定等问题,提出了一种面向全局搜索的自适应领导者樽海鞘群算法,通过在领导者位置上引入上一代位置和惯性权重,自适应的调整领导者和追随者的数量来提高算法的收敛精度。 陈雷等[15]为了进一步提升樽海鞘群算法的寻优效率和收敛精度,提出了一种基于衰减因子和动态学习的改进樽海鞘群算法,在领导者位置和追随者位置更新上各自引入衰减因子和动态学习策略,以提高算法的局部开发能力和全局搜索能力。陈忠云等[16]提出了一种多子群的共生非均匀高斯变异樽海鞘群算法,按适应度将种群分成三个子群:领导者,追随者和链尾者,对领导者进行新的位置更新策略,在追随者位置上加入共生策略以及对链尾者进行非均匀高斯变异操作,使改进的樽海鞘群算法具有更好的收敛速度和寻优精度。 张严等[17]提出了一种基于莱维飞行的改进樽海鞘群算法,利用莱维飞行策略对领导者位置进行随机更新,同时追加对追随者的更新条件来增强算法的全局寻优能力以及加快算法的收敛速度。 Hegazy 等人[18]提出了一种固定惯性权重的改进樽海鞘群算法,加快搜索过程中的收敛速度,并应用于特征选择问题。 上述算法均从不角度对樽海鞘群算法进行改进,虽然算法取得了较好的效果,但算法的求解精度和收敛速度仍需进一步提高。
综上所述,本文针对樽海鞘群算法收敛速度慢、易陷入局部最优等问题,提出了一种基于混沌映射的自适应樽海鞘群算法(CASSA)。 首先,将混沌映射代替原来的随机初始化种群方式,使得种群初始化阶段能够均匀的分布在上下限内,以增强种群的多样性,同时能使种群更快的接近食物源位置,加快算法的收敛速度;其次,采用自适应权重方式来更新领导者的位置,让领导者能更加快速的接近最好的食物源;最后,对原有追随者的位置进行新的更新策略,使其不再进行盲目跟随,同时更多的保留自身信息。 通过对10 个标准测试函数的仿真结果表明,本文方法相比于其他优化算法具有更高的鲁棒性。
1 基本樽海鞘群算法
樽海鞘群算法是Mirjalili 等人[8]通过模拟海洋中樽海鞘个体及群体行为发展而来的一种群智能优化算法。 将樽海鞘群分为两个子种群:领导者和追随者,领导者位于樽海鞘链的前端,其余个体作为追随者,樽海鞘群算法具体数学描述如下。
1.1 种群初始化
在樽海鞘群算法中,假设樽海鞘的捕食空间是N×D维,其中,N为种群大小,D为空间的维度,种群初始化的数学描述如式(1)所示:

式中:ub,lb 分别代表了捕食空间的上限和下限,种群初始化过程完全随机。
1.2 领导者的移动方式
在捕食空间中寻找到最优的食物源是种群的目标,在种群探索阶段,食物源的位置即是全局最优解,影响着领导者的位置移动,领导者的位置更新如式(2)所示:
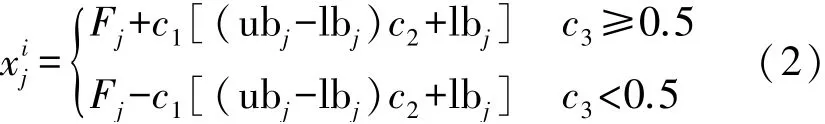
式中:代表领导者i在第j维的位置,Fj表示食物源在第j维的位置,c2,c3是[0,1]上的随机数,参数c1的数学描述如式(3)所示

式中:t和Tmax分别代表了当前迭代次数和最大迭代次数,m为常量的幂指数。 从式(3)可以看出,c1随着迭代次数的增加非线性降低,当c1值较大时,有利于种群的探索能力,反之,有利于种群的局部开发能力,系数c1使得种群的开发和探索能力处于较好的平衡状态,因此,c1是樽海鞘群算法最为重要的参数。
1.3 追随者的移动方式
在樽海鞘群算法中,追随者跟随领导者移动,移动方式满足牛顿第二定律,如式(4)所示。

式中:代表了追随者i所在第j维空间的位置,代表了追随者i-1 所在第j维空间的位置,a代表加速度,v0表示初速度,Δt即为迭代次数之差,故Δt=1,由于初速度为0,因此式(4)可以表示为式(7)。

2 改进的樽海鞘群算法
为了进一步提高樽海鞘群算法的求解精度和收敛速度,同时保证算法探索和开发能力的平衡,在保持种群个体不变的条件下,本文从种群初始化、领导者的位置更新和追随者位置更新三个角度改善算法性能,分别侧重于收敛速度、全局搜索和局部搜索,具体描述如下。
2.1 混沌映射
研究表明,种群初始化作为群能算法的重要环节,初始化的位置的好坏可以直接影响算法的收敛速度和解质量[19-20],例如,均匀分布比随机分布解空间的覆盖率更全,更容易得到好的初始解。 基本樽海鞘群算法采用随机种群初始化操作,无法覆盖整个解空间。 混沌序列在一定范围内具有遍历性、随机性及规律性的特点与随机搜索相比,混沌序列能以更高的概率对搜索空间进行彻底搜索,可使算法跳出局部最优,保持群体的多样性。
基于以上分析,为了更大几率的得到好的初始解位置,加快种群的收敛速度,本文采用具有较好遍历均匀性和更快迭代速度的Tent 混沌映射方法,提高初始解的覆盖空间,计算方法如式(8)所示。
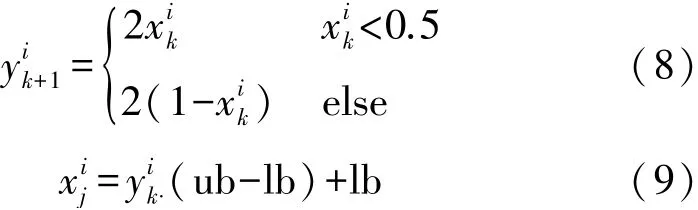
式(8)中:为区间[0,1]的混沌序列,再根据式(9)进行逆映射得到种群的初始位置,这样的混沌映射方法能够大幅度的增大初始解空间的覆盖率,让种群能够更快的靠近最优解,从而加快算法的收敛速度。
2.2 自适应权重变化
在基本樽海鞘群算法中,从领导者的位置更新方式我们可以看出,领导者的位置更新主要受到食物源和参数c1的影响,c1值越大时有利于算法的探索能力,c1值越小时,有利于算法的开发能力,同时领导者的位置移动还受到缩放因子c2的影响,c2为均匀分布的随机数,这样的缩放因子使得领导者的移动具有很大的盲目性,且c2的取值多为无效取值。 针对上述问题,本文提出了一种新的领导者位置更新方式,在食物源的位置添加自适应权重,算法前期权重较大,让算法有足够强的探索能力,随着迭代次数的增加,权重自适应减小,用于增强算法的局部开发能力,在算法的中后期,权重开始增大,使领导者具备跳出局部最优的能力,具体数学描述如式(10)所示。
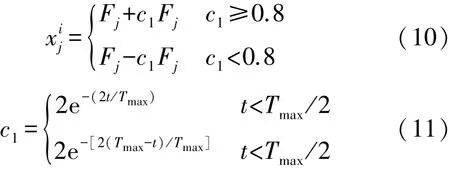
式中:表示个体i在捕食空间j维的位置,Fj为食物源位置,c1为先递减后递增的权重,t代表当前迭代次数,Tmax代表最大迭代次数。
2.3 追随者机制变化
在基本樽海鞘群算法中,追随者根据式(7)进行位置更新,从式中可以看出,第i只个体根据第i-1 只个体进行位置移动,而没有考虑上一个体适应度的好与坏,即追随者的位置移动具有一定的盲目性,追随者i的位置移动只与个体i-1 有关,缺乏与其他个体进行信息交流的能力,这种移动方式极易导致算法陷入局部最优。 针对上述缺点,本文提出了一种新的追随者移动方式,具体数学描述如式(12)所示。
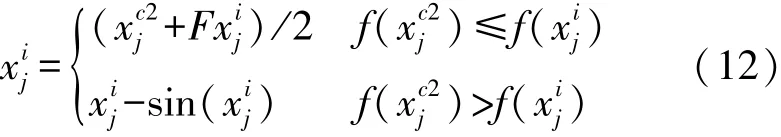
式中:表示追随者的位置,F是权重因子,随迭代次数逐渐递减,c2 代表了随机从领导者中选择的个体,如果当前个体i的适应度大于领导者c2 的适应度,则在适应度较大的个体位置上添加权重因子,用来降低较差位置个体的影响,进而提升了较优个体的权重;否则,个体i只在自己周围波动。 这种移动方式,可以大大的降低盲目追随性,增强了种群间的信息交流,同时还能保留追随者的自身信息,保证种群的多样性。
2.4 算法描述
本文通过添加混沌映射和自适应权重,同时改变领导者和追随者的位置更新方式,得到了改进的樽海鞘群算法(CASSA),平衡了领导者的探索和开发能力,降低了追随者盲目性,更好的保留了个体信息,同时保证种群的多样性,CASSA 的具体算法流程如下所示。
Step 1 参数设定。 包括最大迭代次数Tmax、种群规模N、上下界等。
Step 2 初始化种群。 改变原始的位置随机方式,采用混沌映射的方法,增大解空间的覆盖率。
Step 3 生成自适应权重c1,根据式(10),更新领导者位置。
Step 4 随机产生领导者c2,跟随式(12),更新追随者位置。
Step 5 判断结束条件,若满足条件,则输出最佳食物源位置;否则,执行step 3。
CASSA 的伪代码如下所示:

3 实验仿真及结果分析
3.1 函数说明及实验参数设置
为了检验本文方法的性能,通过选择多组标准测试函数进行验证,函数的具体形式如表1 所示,测试函数集中的函数包含单峰、多峰、高维、低维等特征,该测试函数集能够全面客观的反映算法的寻优性能,其中,F1~F5 为单峰函数,只有一个全局最优值,能很好的反映算法的收敛性能,F6 ~F10 为多峰函数,有很多局部最优值,能很好的反映算法跳出局部最优的能力。 仿真实验环境是基于Windows 10操作系统,8 GB 内存,利用MATLABR2016b 进行编程测试。 仿真测试中,CASSA 算法的最大迭代次数M为1 000,种群大小N为30,所有为了消除算法的偶然性,每个测试函数独立运行30 次,得到每个测试函数的最佳值、平均值、标准差、运行时间,记只改变追随者位置移动方式为CASSA1、只改变领导者位置移动方式为CASSA2,结果如表2 所示。
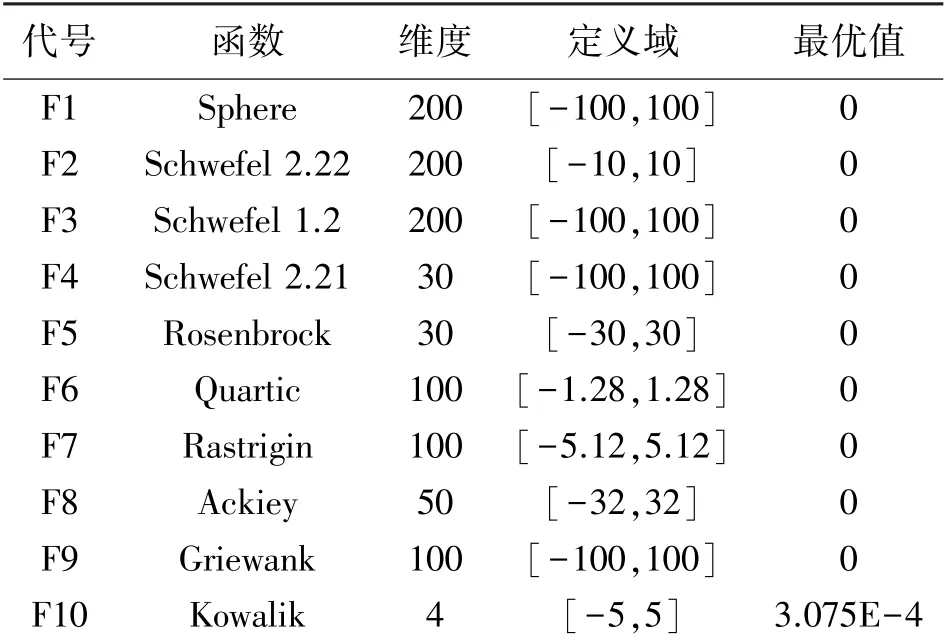
表1 基准函数
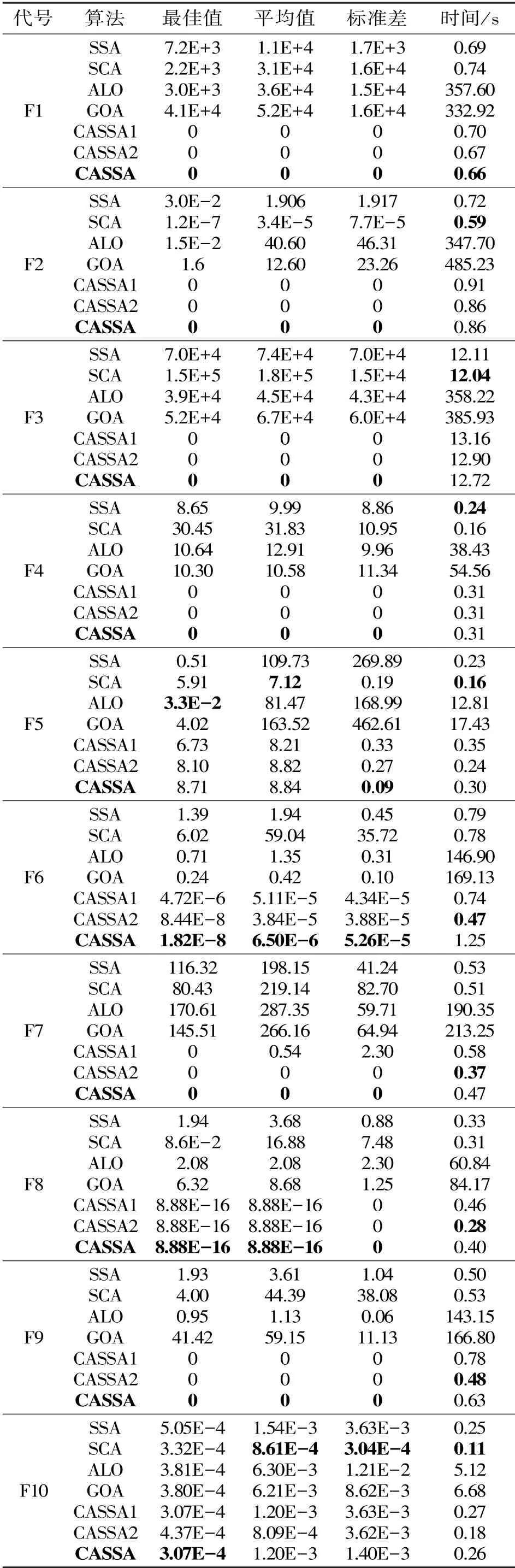
表2 基准函数结果对比
3.2 实验结果及分析
随着搜索空间维度的增加,算法的求解难度会呈指数级递增,为了验证CASSA 算法的寻优精度,对于F1 ~F5 单峰函数分别设置了200 维、200 维、200 维、30 维、30 维进行实验分析,从表2 的实验结果可以得到,在求解这5 个函数最优值时,SSA、SCA、ALO、GOA 算法求解精度较差,30 次独立重复实验,上述算法均无法找到理论最优值,且存在10+3 级误差,本文提出的CASSA 算法在F1~F4 函数求解上的最佳值和平均值在30 次独立重复实验中都能达到算法的理论最优值,同时,4 个单峰函数求解的标准差均为0,证明了算法具有很好的稳定性。从图1(a)、1(b)、1(c)、1(d)上可以看出,在单峰高维求解问题上,CASSA 算法均在400 代以内得到收敛,再次证明了CASSA 算法具有很好的收敛精度和收敛速度,函数F5 虽然不能找到理论最优值,但算法的标准差最小,算法更为稳定。
在求解F6~F10 多峰函数的问题上,F7、F9、F10的维度分别设为100 维、100 维、4 维,CASSA 算法均能找到理论最优解,其中F7 和F9 在30 次独立重复实验中均能找到理论最优值,平均值及标准差都为0,在求解时间上也具有很强的竞争性,在函数F10 求解上,CASSA 算法能找到理论最优解,算法的平均值和标准差也较小,从图1(g)(i)可以看出,函数F7 和F9 均能在200 代以内得到收敛,证明了算法具有很好的收敛性能,从图1(j) 可以看出,CASSA 算法的收敛曲线呈现阶梯状下降,在100 ~200 代陷入第一次局部最优,在200 ~400 代陷入第二次局部最优,在400 代之后多次陷入局部最优,但算法都能很好的跳出当前局部最优,也证明了领导者自适应更新策略的有效性。 在函数F6、F8 求解上分别设置了100 维和50 维,从表2 可以看出,在上述2 个测试函数中,CASSA 算法均不能找到理论最优值,但和原始的SSA 算法及其他优化算法相比,具有更好的寻优性能,在平均值和标准差方面也比其他算法好,再次证明算法具有一定的稳定性,从图1(f)、1(h)可以看出,CASSA 算法的寻优虚线呈阶梯状下降,在图1(f)表现的更为突出,寻优曲线呈现多个阶梯,再次证明CASSA 算法策略具有跳出局部最优的能力。

图1 CASSA 算法的收敛曲线图
为分析改进策略的有效性,表2 给出了两种改进策略的寻优结果,记只改变追随者位置移动方式为CASSA1、 只改变领导者位置移动方式为CASSA2,对于单峰函数F1 ~F4,CASSA1 和CASSA2都能找到理论最优值,同时改进策略的平均耗时,平均值和标准差都为0,表明算法具有很好的性能,在F5 函数的求解上,CASSA1、CASSA2 算法均不能找到理论最优值,但算法的标准差较小,算法具有很强的稳定性。 对于多峰函数F6 ~F10,在F7、F9、F10三个函数求解问题上,CASSA1、CASSA2 都能找到理论最优值,在求解函数F6、F8 时,均能提升十个左右的数量级,同时两种改进策略相比其他优化算法的平均耗时、均值和标准差都较小,再次证明了两种改进策略的有效性。
从平均耗时上来看,SSA 和SCA 平均耗时最短,ALO 和GOA 的平均耗时最长,本文所提CASSA算法在时间上具有很强的竞争性,在F1 和F2 函数求解上耗时最短,效果最佳,在F3~F10 函数求解时间上相当,出现这种情况是合理的,因为算法引入了混沌映射,使得算法前期解空间的覆盖率更大,导致运行时间变长,总体来看,CASSA 算法的平均耗时增加幅度不大,但寻优性能更好,达到了求解精度和求解时间的平衡。
3.3 与其他改进算法的比较
为了进一步验证CASSA 算法的收敛精度和收敛速度,将CASSA 算法与目前最新的增强型SSA 算法:RDSSA[14]、MSNSSA[15]、ALSSA[16]进行平均值和标准差的比较,结果如表3 所示。
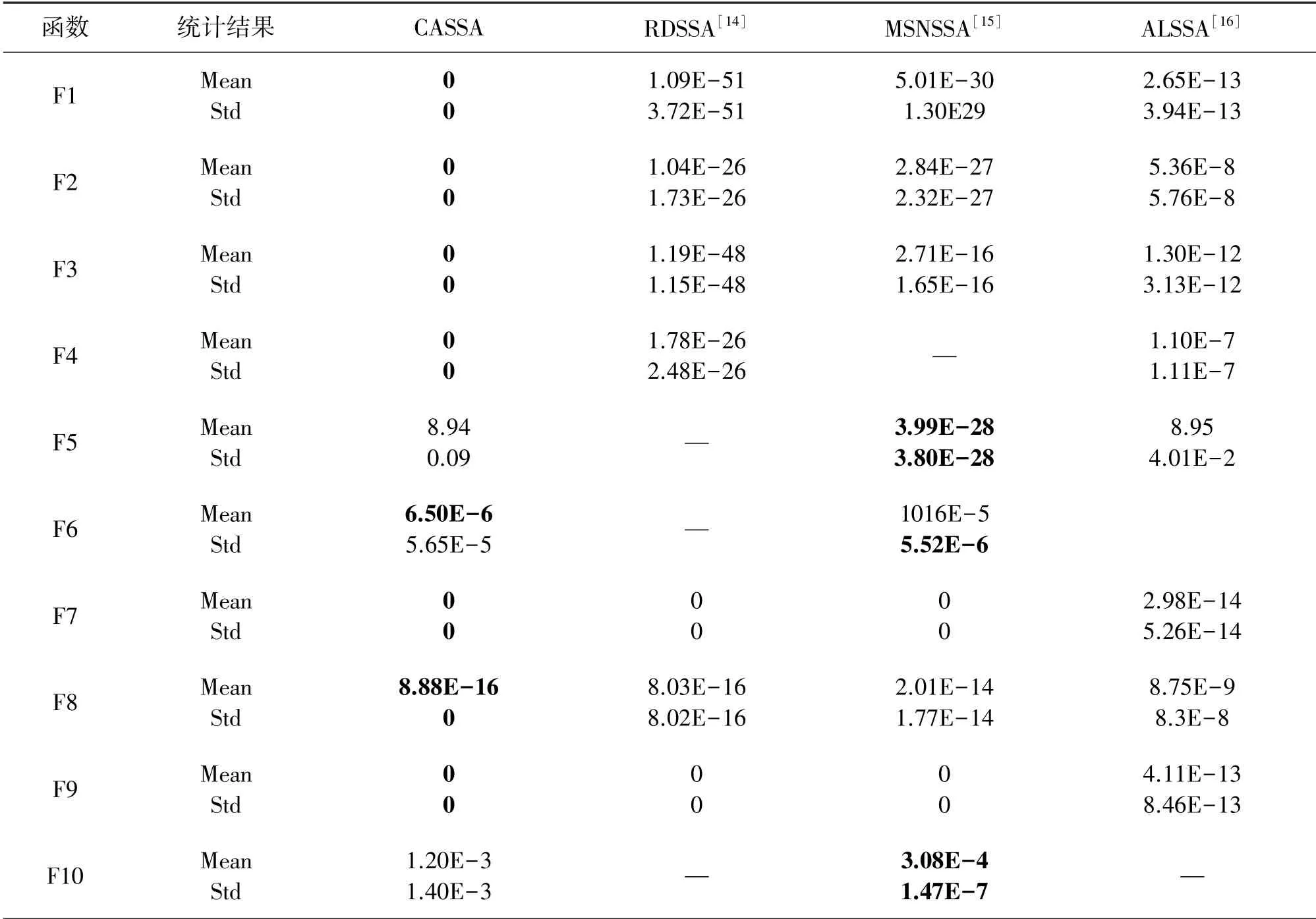
表3 与参考文献中算法的对比
从表3 可以看出,在F1~F4 单峰函数中,CASSA算法在收敛精度能找到理论最优值,要优于其他3 个算法,同时通过参考RDSSA[14]、MSNSSA[15]、ALSSA[16]的收敛曲线图发现,CASSA 算法能在400 代以内得到收敛,而其他3 个算法都要到500 代以后才能收敛,且无法找到理论最优值,尤其是RDSSA 在30 维F1~F4函数求解问题上没有CASSA 的100 维高维寻优好,但是对于函数F5,CASSA 要比MSNSSA16 的寻优结果差,但耗时更短,出现这种情况也是合理的,MSNSSA 算法引入了更多的算子,使得算法能搜索到更多的解,同时也导致了运行时间边长。 在多维函数F6~F9 求解问题上,CASSA 算法的平均寻优结果都要优于另外3 个算法,虽然在函数F6 和F8 上无法找到理论最优值,但标准差更小,算法更为稳定。 在求解函数F10 问题上,CASSA 算法的寻优结果和MSNSSA[15]算法平均值上仅差1 个数量级。
综上所示,通过对F1 ~F10 函数求解的结果比较可以得到,CASSA 算法在高维单峰函数上比其他3 个算法具有更好的性能,同时算法的平均耗时短,收敛速度更快;在高维多峰函数求解问题上,CASSA算法也能找到理论最优值,同时算法的标准差更小,算法更加稳定,具有很强的竞争力。
3.4 CASSA 算法的时间复杂度分析
除了算法的收敛精度和收敛速度,时间复杂度更是检验算法性能的关键指标,用符号O表示。 在SSA 算法中,假设算法的种群数为N,维度为n,参数设置和产生随机数的时间分别为t1和t2,求解适应度的时间为f(n),对适应度排序时间为t3,那么,种群初始化时间为:
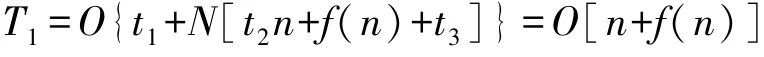
进入在算法迭代阶段,领导者和追随者的数目都为N/2,假设计算c1的时间为t4,随机数c2,c3生成时间与t1保持一致,领导者和跟随着更新每一维的时间为t5,那么迭代时间的时间复杂度为:
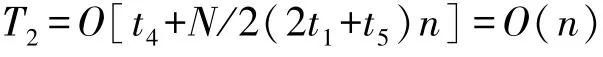
在更新食物源和边界处理阶段,设求解适应度的时间仍然为f(n),每一维边界处理时间为t6,食物源位置替换时间为t7,那么此阶段的时间复杂度为:

综上,SSA 算法的时间复杂度为:
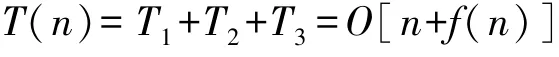
在改进的CASSA 算法中,设种群初始化,求解适应度时间,参数设置时间等与SSA 算法保持一致,每一维混沌映射的时间设为t8,则CASSA 算法种群初始化阶段的时间复杂度为:

在领导者和追随者位置更新阶段,设由式(11)产生自适应权重c1的时间为t9,追随者随机选择领导者C2 的时间为t10,适应度比较的时间为t11,则该阶段的时间复杂度为:
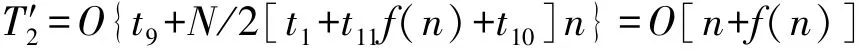
在更新食物源和边界处理阶段,由于CASSA 算法跟SSA 算法相比没有任何改变,所以该阶段的时间复杂度为:
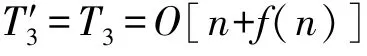
综上,CASSA 算法总的时间复杂度为:

综上所述,本文所提CASSA 算法和基本SSA 算法在时间复杂度相同,并未降低算法的执行效率。
4 结束语
本文提出了一种基于混沌映射的自适应樽海鞘群算法(CASSA),将混沌映射引入种群初始化,使得算法在解空间的覆盖率更大,以使种群更快的接近食物源位置,加快算法的收敛速度,改进领导者和追随者位置的位置更新方式,使得算法具有更强的收敛精度和跳出局部最优能力。 通过使用最佳值、平均值、标准差等指标在10 个标准测试函数对算法进行检验,结果表明,本文方法相比于其他优化算法具有更好的鲁棒性。 在后续的研究中,将考虑将CASSA 算法应用于工程实践问题中。
猜你喜欢
井冈教育(2022年2期)2022-10-14
幼儿100(2022年23期)2022-06-10
包装工程(2022年9期)2022-05-14
当代医药论丛(2021年3期)2021-03-17
生态科学(2018年1期)2018-03-26
大自然探索(2015年10期)2015-09-10
赤峰学院学报·自然科学版(2015年15期)2015-03-21
爱你(2014年13期)2014-08-09
决策(2013年4期)2013-12-19
医学理论与实践(2012年4期)2012-12-09
