
信息量支持下的随机森林模型的崩塌易发性评价
2021-04-07 12:12邓念东李宇新曹晓凡
科学技术与工程 2021年6期
邓念东, 石 辉, 文 强, 李宇新, 曹晓凡
(西安科技大学地质与环境学院, 西安 710054)
崩塌作为中国的第二大地质灾害,具有突发性强、影响范围大等特点,会造成大量的人员伤亡、财产损失及环境破环等。地质灾害易发性评价是地质灾害风险性评估的基础[1],可以为相关部门进行防灾减灾提供理论指导。
中外学者对地质灾害易发性评价方法主要分为三类:知识驱动方法、确定性方法及数据驱动方法[2]。其中,知识驱动方法又称定性评价方法,通过专家丰富的经验对影响地质灾害的各因子的贡献率进行打分来判断地质灾害的易发性;确定性方法通过室内外实验确定斜坡的岩土力学及水文等各参数来计算斜坡的稳定性[3],其真实可靠,但只适合单个斜坡,并不适用于大范围的斜坡稳定性分析;数据驱动方法又称定量评价方法通过反映出地质灾害易发性与影响因素之间的非线性关系,以判断地质灾害发生的概率,从而确定出地质灾害的易发程度。数据驱动方法不要求影响因素呈正态分布,适合于大面积区域[4],因此该方法越来越多的应用于地质灾害易发性评价中。常见的数据驱动方法有:信息量法[5]、人工神经网络法[6]、支持向量机法[7-8]、随机森林模型[9]和逻辑回归算法[10-11]等。其中,随机森林模型具有很强的非线性处理能力,且在处理大数据量、高维度数据方面具有很好的泛化能力[12],预测精度高,较适合于地质灾害易发性评价中。
为了利用分类模型进行地质灾害易发性评价,需要选取一定数量的灾害点与非灾点,灾害点根据已有历史灾害点数据获得,而非灾点数据的获取主要以主观推测或者随机选取的方式获得[13-14]。但随机选取或主观推测的非灾点可能位于灾点附近或潜在灾点上[15],并不能保证所选的“非灾点”易发性低,易造成样本数据选取不合理,为增加模型训练时灾点与非灾点的辨识度,减少分析误差,提高模型的预测精度。现使用数理统计方法中原理清晰且容易建模的信息量模型先进行易发性分析,再从信息量模型得到的较低及低易发区选取与灾点等量的非灾点,以保证所选的非灾点具有极低的崩塌发生概率。在此基础上,构建出信息量模型(information value model,IV)支持下的随机森林(random forests,RF)模型进行崩塌易发性分析。
崩塌是神木市最主要的地质灾害之一(占全区地质灾害的2/3),受人类工程活动及自然环境的影响,崩塌灾害发育频繁,严重威胁着当地居民的生命和财产安全。因此,以神木市为研究对象,利用IV支持下的RF模型对研究区进行崩塌易发性评价,并与随机选取非灾点的RF模型进行对比分析,探索更为理想的评价模型。
1 研究区概况
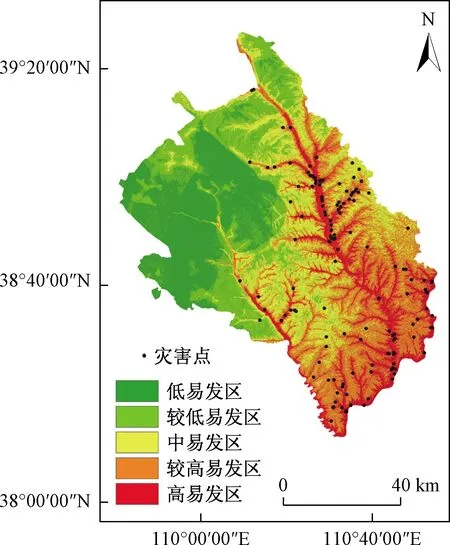
研究区地处陕北黄土高原沟壑区与毛乌素沙漠的过渡地区,西北高、东南低。地理坐标109°40′00″E~110°54′37″E、38°12′31″N~39°27′40″N(图1),总面积7 635 km2,属干旱大陆性气候,年平均气温8.90 ℃。神木市多年平均降水量为423.2 mm,年内降水量变化较大,主要集中在7—9月,占全年降水量的69%,降水量由南向北递减,降雨量以暴雨形式出现,易引发崩塌、滑坡等地质灾害。研究区构造简单,褶皱和断裂不甚发育。根据地貌形态特征及成因,将神木市划分为河谷阶地区、丘陵区和沙漠滩地区3个地貌单元。水系较发育,河网密集,岩土体主要以黄土和砂泥岩为主,人类工程经济活动频繁,触发了地质灾害的发生,致使地质灾害发育比较频繁。区内地质灾害主要为崩塌、滑坡、地面塌陷,其中崩塌地质灾害约占全市地质灾害的3/4以上,为区内的主要地质灾害。研究区地理位置及崩塌点分布如图1所示。

图1 研究区地理位置及崩塌点分布Fig.1 Geographical location and collapse points distribution of the study area
2 数学方法
2.1 信息量模型
信息量模型是以信息论为理论基础的一种预测方法,通过熵的减少来表征地质灾害发生的可能性大小[16]。各评价因子的信息量值预测地质灾害发生的难易程度,即评价因子的信息量值越大,该评价因子的影响越大,表示地质灾害越容易发生,反之,发生地质灾害的可能性小。其计算公式为
(1)
(2)
式中:A为研究区的地质灾害,即崩塌;Xi为不同的评价因子;I为各评价因子的信息量值;Ni为评价因子Xi中崩塌的个数;N为研究区总的崩塌个数;Si为评价因子Xi所占单元的面积;S为研究区总面积;Ii为各评价因子叠加后的总信息量值;n为评价因子的个数。
2.2 随机森林模型
随机森林是由Leo Breiman于2001年提出的一种集成分类器,是利用多棵树对样本进行训练并预测的学习方法。它的基本单元是决策树,每棵决策树单独完成分类任务后,由各个分类树的分类结果投票决定最终的结果[17]。
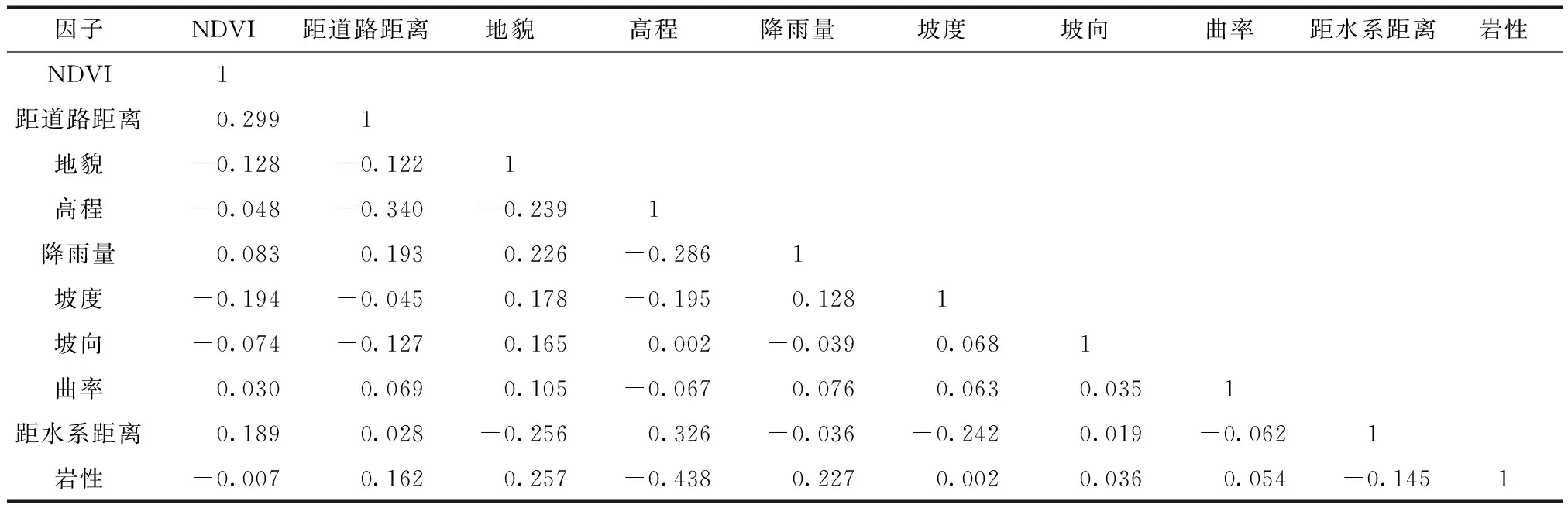
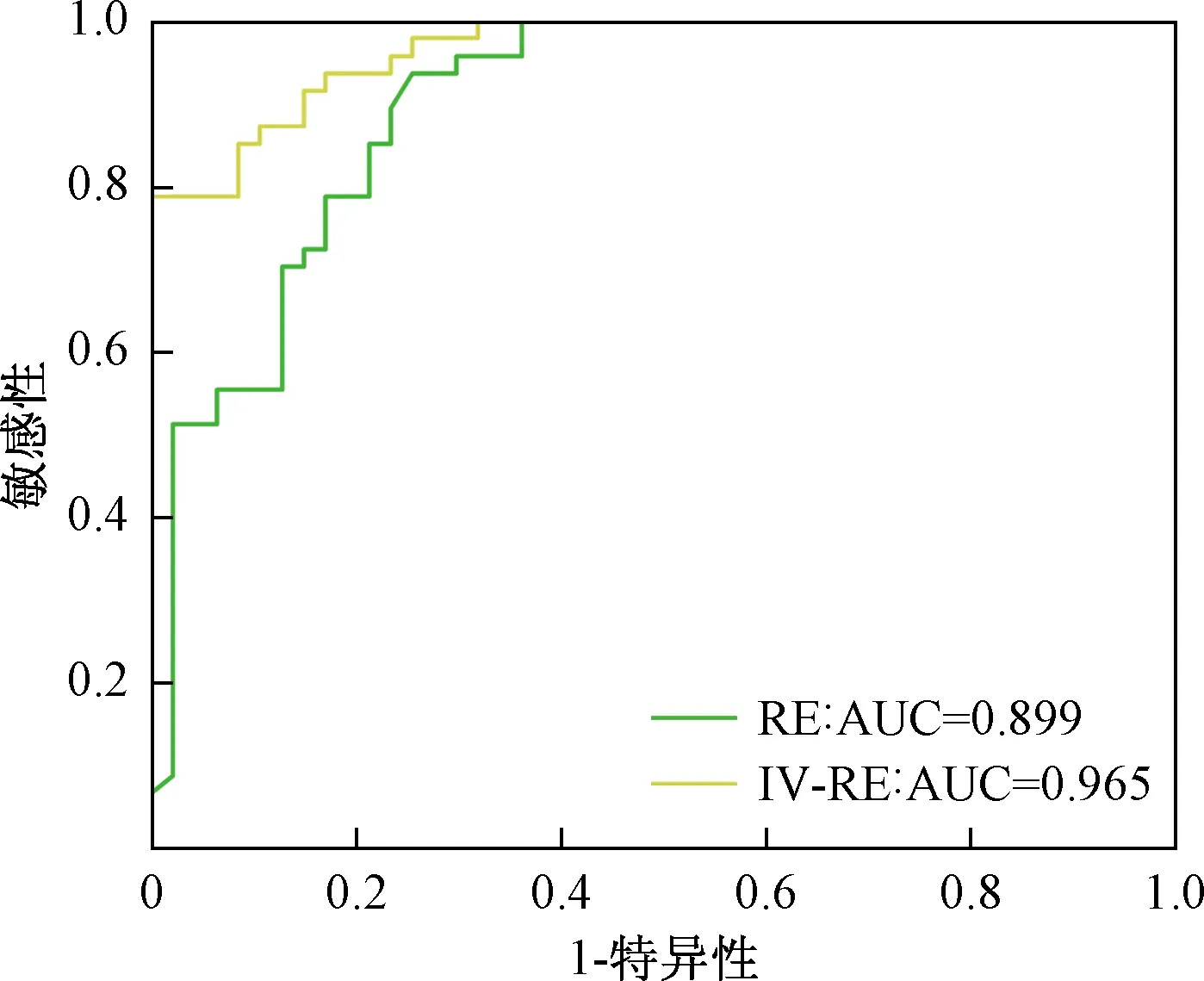
随机森林通过bootstrap重采样技术从原始训练样本随机有放回的抽取N′个样本,作为新的训练集,并用每一个独立抽取的训练样本来训练一棵决策树。决策树在进行特征分裂时从每个样本的M个特征中随机抽选m个(m 在结合相关文献、研究区的地质条件、崩塌形成条件及发育特征等分析的基础上,初步选取高程、坡度、坡向、曲率、距水系距离、距道路距离、地层岩性、地貌、降雨量、归一化植被指数(normalized vegetation index,NDVI)10个影响因素作为评价因子。 数据来源为历史崩塌数据库、神木市地质灾害详查报告、地理空间数据云获取的研究区30 m×30 m精度的数字高程模型(digital elevation model, DEM)数据、比例尺为1∶50 000的地质图、降雨量数据。崩塌编录数据来源主要为:①利用Arcgis软件处理得到研究区坡度、坡向、高程、曲率4个地形地貌专题图层;②利用91卫图获得研究区水系及路网图,③通过1∶50 000地质图矢量化得到地层岩性及地貌;④利用神木市气象数据经克里金插值法获得降雨量专题图;⑤利用landsat8影像获得该区的归一化植被指数(NDVI)专题图。 影响崩塌的评价因子存在着一定的关系,但是,并不是所有的评价因子都对评价结果产生积极的影响。当评价因子间存在多重共线问题时,会使模型变得复杂,从而降低模型的预测精度。为了避免这种影响,利用SPSS软件对各评价因子进行相关性分析,若相关性系数的绝对值大于0.5,说明因子间有较强的相关性,反之,相关性较弱。在进行相关性分析后,得到结果如表1所示。由表1可知,各评价因子之间相关系数的绝对值均小于0.5,表明各因子间相关性较弱,所有评价因子均可用于崩塌易发性分析。部分因子专题图层如图2所示。 表1 评价因子间的相关系数Table 1 Correlation coefficient among evaluation factors 根据研究区地质环境和崩塌空间分布特征,对各评价因子进行分级。评价因子分为连续性和离散型。对于连续型评价因子进行等间隔及自然断点法划分,对于离散型评价因子按照其原有的分类方式进行分级,最终得到各评价因子的分级状态如表2所示。其中,坡度、坡向、距断层距离、距水系距离以及距道路距离按照等间隔划分;高程、曲率、NDVI、降雨量按照自然间断点法划分;地层岩性分类编号如下:1为全新统冲积物、2为三叠系砂泥岩、3为全新统风积物、4为中上更新统风积物、5为上更新统冲积与湖积物、6为新近系红黏土、7为全新统湖积物;地貌类型分类编号为:1为丘陵区、2为沙漠滩地区、3为河谷地区。 在进行崩塌易发性评价之前,需要对研究区进行单元网格划分。中小比例尺(1∶50 000及以下)通常采用栅格单元划分[19]。研究区在小比例尺(1∶50 000)的基础上进行崩塌易发性分析,因此采用栅格作为评价单元。结合汤国安等[20]的DEM经验公式:Gs=7.49+0.000 6S-2.0×10-9S2+2.9×10-15S3,其中S为地形图比例尺,将研究区划分为30 m×30 m精度的栅格单元,共计8 306 349个栅格单元。 利用信息量模型式(1)~式(2),将各因子的属性值导入Excel中可计算得到分级状态下的信息量Ii(表2)。信息量值越大,表示越容易发生崩塌,负值则表示发生崩塌的可能性小。由表2可知,坡度在40°~50°范围内,降雨量在大于425 mm的河谷地区信息量值最大,表明此条件下容易诱发崩塌地质灾害。 将研究区各评价因子分级后的信息量值经地理信息系统(geographic information system,GIS)加权求和后,得到研究区的总信息量值,其取值范围为-7.36~5.39。利用自然间断点法将总信息量值划分为5个等级,即低易发区、较低易发区、中易发区、较高易发区、高易发区。最终生成崩塌易发性图(图3)。 图3 基于IV模型的崩塌易发性图Fig.3 Collapse susceptibility map based on IV model 由于崩塌往往发生于暂未发生崩塌的区域,为了避免随机选取的非崩塌点落到潜在崩塌上,利用Arcgis在已生成的信息量模型的较低及低易发区选取与崩塌点等量的非崩塌点。将崩塌点与非崩塌点合并之后,利用Arcgis多值提取至点工具得到研究区各专题图层的属性值,建立崩塌属性数据库,用于构建模型。 在研究区随机选取和历史崩塌点等量的非崩塌点,与历史崩塌点(共156个)一起作为崩塌易发性区划的样本。其中,将崩塌点设定为“1”,非崩塌点设定为“0”。分别随机选取崩塌点及非崩塌点样本中的70%(218个)作为训练样本,剩余的(94个)作为测试样本。借助MATLAB软件,将训练样本带入编好的代码进行训练,训练之后的模型用来测试样本集,得到模型的测试精度为89.9%,随后将整个区的崩塌属性值代入建好的模型,得到研究区的崩塌易发性指数,利用Arcgis软件的自然间断点法将易发性指数划分为5类,即低易发区、较低易发区、中易发区、较高易发区和高易发区。最终生成崩塌易发性图,如图4所示。 图4 基于RF模型的崩塌易发性图Fig.4 Collapse susceptibility map based on RF model 将信息量模型得到的非崩塌点,与历史崩塌点(共156个)一起作为崩塌易发性区划的样本。再进行随机森林模型训练,得到模型的预测精度为96.5%,将整个区属性值带入模型,得到崩塌易发性指数,同样采用自然间断点法将易发性指数分成5类,分别为低、较低、中、较高及高易发区。生成最终的崩塌易发性图(图5)。 图5 IV支持下的RF模型的崩塌易发性图Fig.5 Collapse susceptibility map based on RF model supported by IV model 采用ROC曲线对两种不同模型进行检验对比,通常用曲线下面积(area under curve, AUC)来说明模型的评价性能。AUC越大,模型的评价性能越好。当AUC<0.5时,说明模型无预测价值;AUC在0.5~0.7时,模型的评价性能较一般;AUC在0.7~0.9时,模型的评价性能较好;AUC>0.9时,模型的评价性能很好。 利用SPSS软件以未发生崩塌被正确预测的概率为自变量,以发生崩塌被正确预测的概率为因变量绘制ROC曲线。分别用训练样本与测试样本结果绘制成功率与预测率曲线,得到两种不同模型的成功率与预测率,如图6、图7所示。 图6 成功率曲线Fig.6 The success rate curve 图7 预测率曲线Fig.7 The prediction rate curve 由图6、图7可知,RF模型及IV支持下的RF模型成功率分别为94.5%、96.9%,预测率分别为89.9%、96.5%。由此可知,IV支持下的RF模型的预测精度优于单一的模型。 以神木市为研究对象,基于前人研究成果及灾害发育特征,选取了10类评价因子。基于GIS平台,分别采取IV模型,RF模型及IV支持下的RF模型对研究区崩塌进行易发性评价,并得到如下结论。 (1)研究区崩塌受坡度、距道路距离、NDVI及距水系距离的影响较大,崩塌高易发区沿水系及公路相对发育;在坡度较高、植被覆盖率低的区域也有较高的崩塌发生率。 (2)对于非崩塌点的选取,为避免随机选取和主观推测的非崩塌点具有较高的崩塌发生率,从信息量模型形成的较低及低易发区选取非崩塌点,构建IV支持下的RF模型,经ROC曲线对两种评价模型进行检验,结果表明,IV支持下的RF模型在进行崩塌易发性评价时,比单独的RF模型的成功率和预测率分别提高了2.4%和6.6%,表明IV支持下的RF模型能更准确地选取非崩塌点,适合于此研究区的崩塌易发性评价。3 评价因子选取及分级
3.1 评价因子选取与图层制作
3.2 评价因子相关性分析
3.3 评价因子分级
4 崩塌易发性分析结果
4.1 信息量模型
4.2 随机森林模型

4.3 信息量支持下的随机森林模型

5 模型的检验与对比

6 结论
猜你喜欢
西北林学院学报(2022年5期)2022-10-04
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
房地产导刊(2022年1期)2022-02-28
今日农业(2021年10期)2021-11-27
今日农业(2021年1期)2021-03-19
中等数学(2020年1期)2020-08-24
华人时刊(2018年17期)2018-11-19
成才之路(2016年18期)2016-07-08
试题与研究·教学论坛(2015年5期)2015-09-02
