
基于RetinaFace 的人脸多属性检测算法研究
2021-04-07 00:41随玉腾阎志远戴琳琳
铁路计算机应用 2021年3期
随玉腾,阎志远,戴琳琳,景 辉
(1.北京经纬信息技术有限公司,北京 100081;2.中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
人脸识别技术经不断发展,已广泛应用于支付、身份核验等多种场景。从图像中快速、准确检测到人脸是人脸识别的基础,识别的准确率受到人脸质量的影响,其中,人脸遮挡是影响较大的一个因素。当旅客佩戴口罩、墨镜等出行时,人脸信息被严重遮挡,这对铁路实名制进站核验系统的人脸算法提出了挑战[1]。现有人脸检测算法存在遮挡人脸检出率低,不能区分出人脸有无遮挡的问题。且在遮挡情况下,人脸识别算法不能快速、有效完成人脸识别,造成进站闸机识别通过率下降,导致旅客进站时间增长等情况,影响旅客出行体验。因此,在人脸检测算法中添加对遮挡类型(墨镜、口罩等)和遮挡程度的判断功能,从而对不同遮挡类型和不同遮挡程度的人脸进行分别处理,提高算法的识别成功率和可靠性。
由于进站闸机设备计算能力有限,对人脸算法要求更轻量、高效、多功能,需要一种计算开销较小、同时满足多任务识别的算法。目前常用的检测算法主要有:双阶段目标检测的R-CNN[2]系列算法,使用区域建议网络生成一系列候选区域,对这些候选区域进行更细致的边框回归和分类,精度较高但是推理速度较慢;单阶段目标检测的YOLO[3](You Look Only Once)算法,将图像分为多个小的区域,并在每个小区域上使用不同形状和大小的目标框进行回归,推理速度较快,但存在小物体检测能力较差等精度问题;单阶段目标检测的SSD[4](Single Shot Detector)算法,通过使用不同层级的特征图,结合不同大小、形状的目标框对物体进行匹配,提高了对小物体的检测能力,但没能较好地利用特征信息。
其中,单阶段目标检测算法在速度方面较优秀,更适合进站闸机这种要求在工控机上完成人脸检测、识别等一系列任务的资源受限设备。本文基于Retina-Face 单阶段目标检测算法,设计了一种能区分遮挡类型和遮挡程度的人脸检测模型。
1 算法原理
1.1 RetinaFace 算法概述
RetinaFace[5]是一种专门检测人脸的单阶段目标检测算法,在多级特征图信息的基础上使用了特征金字塔网络[6](FPN,Feature Pyramid Networks)的方法,更充分地使用特征信息,网络结构如图1 所示。RetinaFace 使用多级特征的特征图(P2~P6)构成特征金字塔,在不同层级的特征图上设计了大小不同、数量众多的锚点框,使其获得了出色的检测性能。
RetinaFace 的主干网络使用了ResNet152[7]网络结构,特征金字塔中的P2~P5 层级对应ResNet152的C2~C5 层级残差网络模块,P6 则是使用步长为2、卷积核大小为3×3 的卷积对C5 的特征图进行卷积计算后得到的特征图。P6 层级采用Xavier[8]方式对参数进行随机初始化。并对特征金字塔的每一层使用独立的语义模块,提高感受野并增强刚性语境的建模能力。

图1 RetinaFace 算法网络结构
1.2 损失函数
RetinaFace 采用多任务损失函数,对于训练阶段的每一个锚点框,使用优化算法寻求如式(1)的多任务损失函数的最小化。

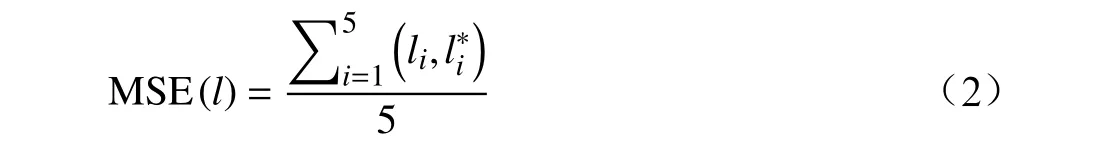
Lpixel是人脸密集点回归损失函数;λ1∼λ3为损失函数权重,控制每一个损失函数在多任务损失函数中的贡献,在RetinaFace 中将4 个任务的权重分别设置为1、0.25、0.1 和0.01。
1.3 锚点框设计
对于输入大小为640×640 的图像,在P2~P6 构成的特征金字塔中共生成102300 个锚点框,每个层级的锚点框大小如表1 所示。设置锚点框大小按照的比例逐步递增,长宽比均为1∶1,锚点框的大小从16×16 到406×406,适应原图中不同大小的人脸。其中,P2 层级共生成76800 个锚点框,占据了所有锚点框个数的75%。通过设计P2 层级使用较低级别的特征图和密集的锚点框,旨在提高模型对面积较小、质量较差的人脸的识别能力,进而提高人脸检测模型在Wider Face 数据集[10]上的成绩,但这种方式会带来更多的计算开销和更高的假阳性的风险。
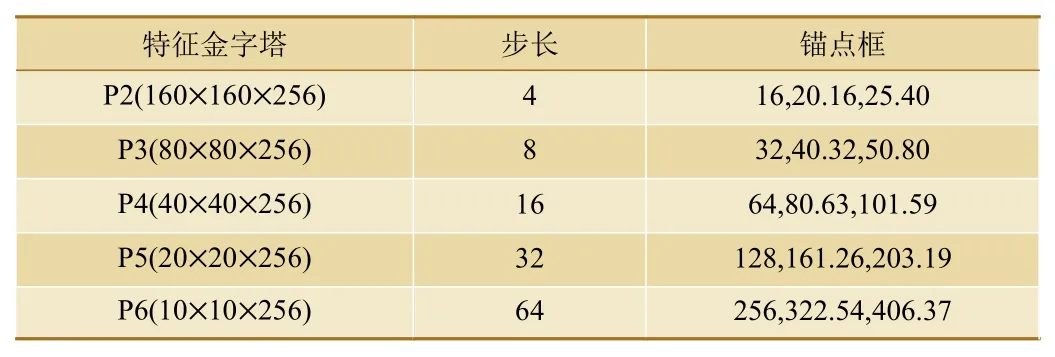
表1 各个层级目标框的数目
2 算法设计改进
2.1 损失函数设计
一般而言,人脸检测网络只区分人脸和背景,为了提高检出率,对被遮挡的人脸及遮挡物不做细致的区分,然而受到遮挡的人脸会造成识别准确率下降。本文提出的模型可增加检测的类别输出,在一个模型中实现口罩、墨镜等遮挡类别的检测,以便直接、有效地对存在人脸遮挡的旅客进行相应处理,降低遮挡对人脸识别的影响,加快旅客进站过程,提高旅客出行体验。考虑到密集损失函数在原损失函数中贡献较少,在移除密集点回归损失函数后,本文优化后的损失函数为:
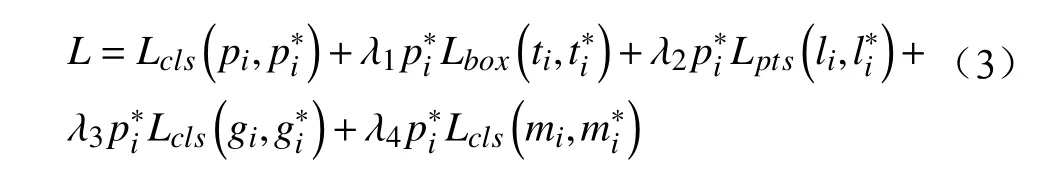
其中,gi,分别为预测佩戴墨镜的概率和佩戴墨镜的真实标签,根据是否佩戴墨镜,标签∈{0,1};mi,分别为预测遮挡的概率和遮挡的真实标签,根据遮挡程度的不同,标签∈{0,1,2};λ1∼λ4为第2~第5 个任务的权重,本公式中共有5 个学习任务,权重分别设置为1、0.25、0.1、1、1。
2.2 网络结构设计
对神经网络而言,轻量化网络的研究目的是在模型识别准确率接近大型网络的前提下,通过一系列方式提高模型参数的有效性,得到参数量、计算开销均较小的模型。常见的提高模型参数有效性的方式包括使用特殊的卷积核(深度可分离卷积和分组卷积)和特殊网络结构等。MobileNet[9]是一种适用于资源受限设备的深度学习网络,该网络使用了深度可分离卷积代替标准卷积,在ImageNet 数据集的验证集上取得70.6%的准确率。为进一步减少计算开销,本文采用0.25 倍通道数量的MobileNet 作为骨干网络。
通过对闸机场景下采集到的带有人脸的图像进行分析,检票的旅客人脸面积在原图中占比适中,因此移除P2 和P6 这两部分结构,可在不过度降低模型精度的前提下,大幅提高模型推理速度。综上,本文改进算法的网络结构如图2 所示。
3 实验过程及分析
3.1 实验数据
目前,常用的人脸检测质量评估数据集是Wider-Face[10]数据集,但是Wider Face 中存在大量小的、质量差的人脸,与闸机的使用场景较为不同。目前并无该场景的公开数据集,因此,本文仿照闸机使用场景搭建实验平台,进行数据采集。共采集、标注10000 张图,得到12601 张人脸,并对于每一张图像的人脸标注了人脸框的左上点和右下点、遮挡程度、是否佩戴墨镜,并根据不同遮挡情况标注关键点信息。不同类型的样本如图3 所示。

图3 各类型样本示意
3.2 实验环境
本文算法在Ubuntu18.04 操作系统环境下运行,基于PyTorch 深度学习框架,使用Python3.6 进行编程。机器硬件部分参数:CPU 为Inter Xeon Gold5218@2.3GHz ×2,GPU 为NVIDIA TeslaV100@16GB ×4,R AM 为250GB。
3.3 实验过程
(1)训练过程采用带有动量的随机梯度下降优化算法,动量大小为0.9,权重衰减系数为0.0005,批次大小为16×4。学习率下降采用热身的方式,在初始的10 个轮次学习率设置为10−3,随后加大到10−2,在第75 轮、100 轮、115 轮时分别下降10 倍,在120 轮停止训练。
(2)训练过程中,当锚点框与标签中人脸框的交并比(IoU,Intersection over Union)大于0.5 时认为是正样本,IoU 小于0.3 时认为是负样本,其余的锚点框训练时被忽略。这种策略会导致超过99%的锚点框为负样本,存在样本不均衡现象。因此本文采用在线难例挖掘方式,将训练过程中正负样本的比例控制在3∶1。
(3)因数据增广能有效提高模型表现,本文按原图短边长度0.3~1 的大小裁剪一块方形区域,并将图像缩放到640 ×640,通过这种方式产生更多的人脸图像,提高模型的鲁棒性。
(4)对于每个训练样本,本文以50%的概率进行随机水平镜像或颜色失真处理。使用相同的训练方式和数据集对骨干网络为MobileNet-0.25 的Retina-Face 算法进行训练,得到一个输出人脸坐标和5 点信息的模型。
3.4 实验结果与分析
为验证算法在铁路场景下的可靠性,按照铁路使用场景建立一个标准测试数据集。该数据集按照人脸检出难易程度分为简单和困难数据集,其中,简单数据集的人脸较清晰、无面部遮挡,困难数据集存在较为严重的人脸遮挡。使用铁路人脸标准数据集对本文提出的改进算法和RetinaFace 算法模型分别进行测试,在推理速度几乎相同的情况下,本文提出的改进算法不仅能准确检测出被遮挡的人脸,且能识别出是否佩戴眼镜、遮挡程度。对各个任务的表现如表2 所示。
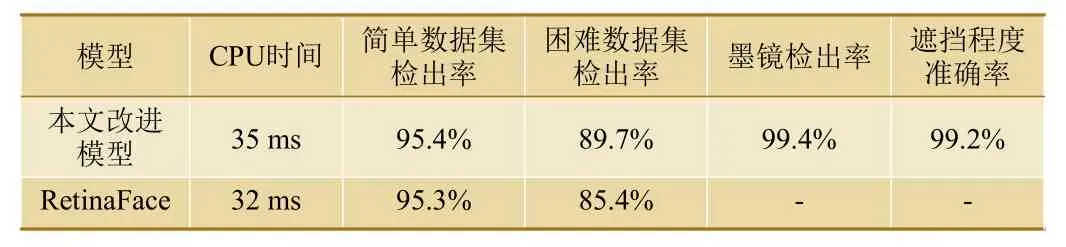
表2 实验结果
4 结束语
本文基于对RetinaFace 算法的研究与改进,对闸机使用场景进行分析后,提出了一种基于Retina-Face 的人脸多属性检测算法。该算法不但能输出人脸框位置而且能准确检测人脸是否佩戴墨镜和遮挡程度等。在自建数据集上人脸检出率为95.4%,推理速度35ms,同时能准确识别遮挡程度,从而对不同遮挡方式的旅客进行不同的处理,有效提高旅客进站效率,提升旅客使用体验。在接下来的研究中,可以对数据集的标注信息进行优化,增加人脸角度、性别、年龄等标签,对人脸质量进行更加细致的区分。
猜你喜欢
——《艺术史导论》评介
美育学刊(2022年5期)2022-10-18
中国典型病例大全(2022年13期)2022-05-10
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
电子技术与软件工程(2020年22期)2021-01-30
数字技术与应用(2020年12期)2021-01-22
航天工业管理(2020年9期)2020-12-28
军事运筹与系统工程(2020年1期)2020-09-11
移动通信(2020年5期)2020-06-08
