
基于样式生成对抗网络的视网膜OCT图像生成方法
2021-04-07 12:51高志军王新勃
黑龙江科技大学学报 2021年2期
高志军, 王新勃, 王 健
(黑龙江科技大学 计算机与信息工程学院, 哈尔滨 150022)
0 引 言
光学相干层图像(OCT)一直被认为是眼底及其相关疾病筛查和诊断的最重要测试手段之一,但由于视网膜OCT图像获取方式比较困难,且人工标注代价高昂,导致训练学习样本数量少,因此,视网膜OCT图像生成研究已成为计算机视觉和眼科领域的一项重要任务。深度学习兴起以来,正在彻底地改变着自动化图像分析的诸多领域,GPU硬件和新算法的发展使这些方法能够更有效地应用于医学图像处理等相关领域。生成式对抗网络(GAN)[1]提出后,在图像生成任务中表现突出。深度卷积生成对抗网络(DCGAN)[2]提出后,首次应用到视网膜OCT图像生成中,使自动生成视网膜OCT图像效果优于传统数据生成方法,取得了惊人的进步。LAPGAN等[3]网络的问世,在皮肤病图像数据合成取得了显著的成效, B.Christoph等[4]采用渐进式ProGAN合成皮肤病变的高分辨率图像,效果极佳,连专业的皮肤科医生都很难分辨是否为合成的。戚永军等[5]采用改进的DCGAN模型生成肺结节图像取得了很好的效果。
虽然DCGAN是比较好的网络模型,但是对GAN模型的稳定性还需进一步提升,且训练时仍需要平衡生成器和鉴别器的训练进程,其结果往往是生成器训练了多次,而鉴别器训练了一次,易导致生成图像结果不稳定。为了弥补上面的不足,笔者采用样式迁移生成式对抗网络(StyleGAN)框架[6],通过对StyleGAN网络结构上调节网络的超参数和优化激活函数,使StyleGAN生成视网膜各层生物解剖结构更佳逼近真实的视网膜OCT图像。
1 方 法
1.1 StyleGAN网络
1.1.1 模型结构
2019年,K.Tero等[6]借鉴风格迁移,成功地提出了基于样式的生成器,提供了一个升级版本的ProGAN图像生成器,如图1所示。StyleGAN网络的模型结构图包括两个阶段,第一阶段是由8个全连接模块、仿射变换和改进的ProGAN堆叠网络构成。其中,改进的ProGAN堆叠网络是在ProGAN中相邻的两个卷积层之间添加一组样式转换模块而获得,每组样式转换模块又是由1个上采样模块、2个自适应实例规范化(AdaIN)和1个卷积模块组成,实现对样式的更精细和精确的控制,通过这样改进的ProGAN堆叠网络就是StyleGAN的生成器部分。第二阶段是采用ProGAN网络体系结构作为鉴别器来判断图像的真实性,而这也是StyleGAN的鉴别器。StyleGAN的鉴别器是由大小分别为256×256、64×64、16×16和4×4等四组卷积模块组成,鉴别器通过判断由StyleGAN生成器所生成的图像与由原图像经过下采样模块处理图像的真假,然后将结果再反馈给输出图像或StyleGAN的生成器。
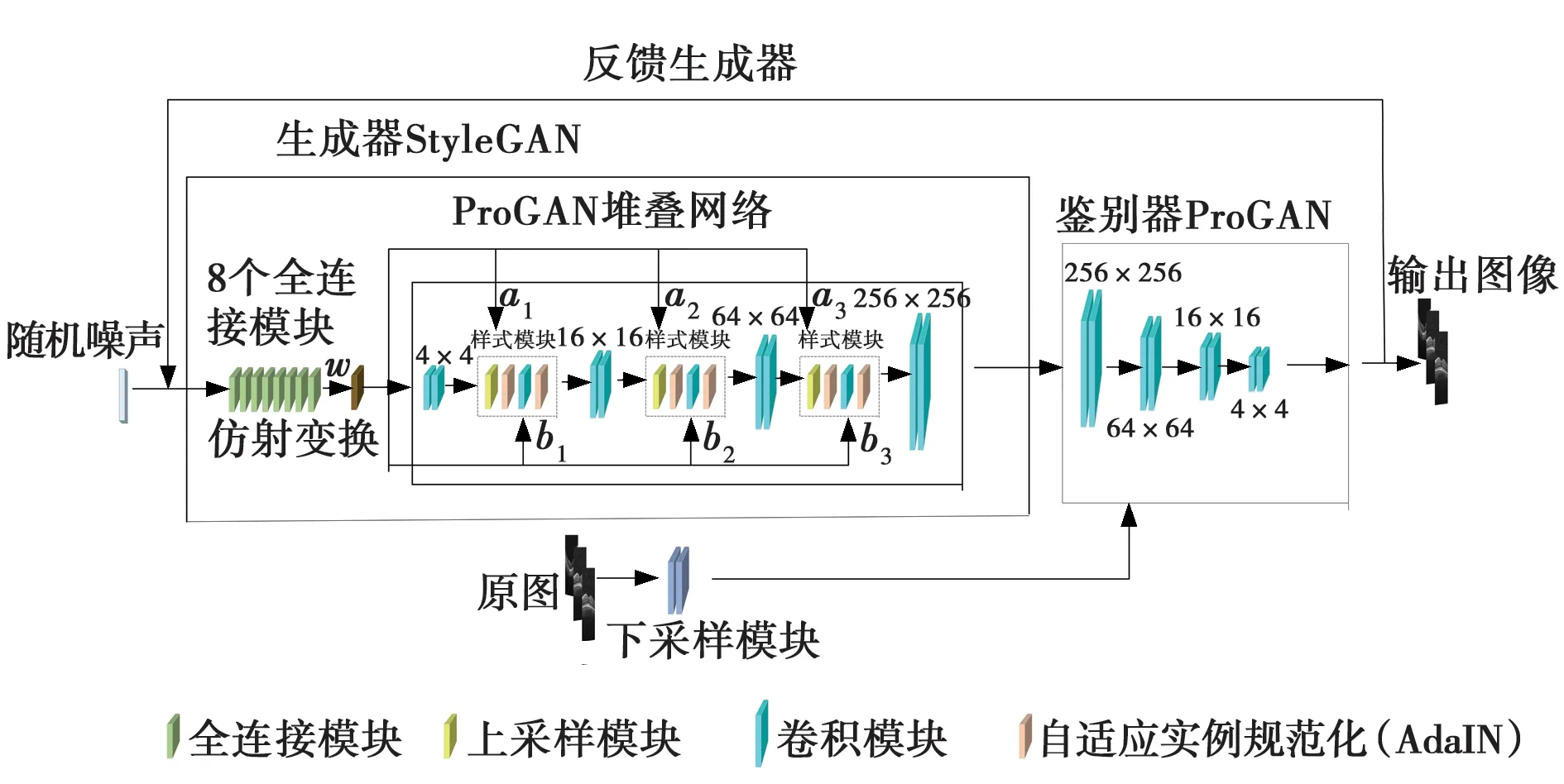
图1 StyleGAN 网络模型结构
在损失函数方面,StyleGAN采用GAN的损失函数为
Ez~Pz[lg (1-D(G(z)))],
(1)
式中:x~pd——真实样本分布;
z~pz——由噪音z产生的样本分布;
G(x)——生成器映射函数;
D(x)——鉴别器映射函数。
1.1.2 模型特征
StyleGAN网络主要在映射网络和样式模块等方面进行了改进,实现了无监督地分离高级属性、随机变化和对生成图像中特定尺度属性的控制,能生成更高质量的分辨率图像[6]。
映射网络图1中,StyleGAN的第一点改进是在网络输入与样式转换模块之间添加一个由8个全连接模块组成的映射网络,并且映射网络的输出与输入层随机噪音的大小相同。
添加这个映射网络的目的是将输入向量转化为中间变量,中间向量w会经过一个仿射网络得到ProGAN每个卷积层后面样式转换模块的2个中间向量ai和bi(i=1,2,3),不同中间向量能够控制不同的视觉特征。由于这 6个控制矢量之间会存在特征纠缠,文中通过控制矢量调整为64×64 分辨率(假设它能控制OCT图像生成的角度),但是文中发现16×16 分辨率上控制的视觉特征也已经更改,这种现象就称之为特征纠缠。映射网络的功能是为输入向量的特征提供学习的路径。
StyleGAN 的第二点改进是将映射网络输出的中间向量w转换为样式控制向量,会影响生成器网络的生成过程。由于生成器从大小4×4的变换到大小16×16,最终变换到大小 256×256,因此,它由 3个生成阶段构成,并且每个生成阶段都将受到两个控制向量ai和bi的影响,其中一个控制向量会在上采样之后对其影响一次,另一个控制向量会在卷积操作之后对其影响一次,影响的方式是自适应实例规范化(AdaIN),因此,中间向量w被转换为6个控制向量并发送给生成器。AdaIN 的具体实现过程:将可学习的仿射变换扩展为放缩因子y与偏差因子y′,这两个因子会与归一化卷积输出做一个加权求和,完成一次影响原始输出x的过程。这种影响方式可以实现样式控制,主要是因为它(变换后的y与y′)影响图像的全局信息,关键信息由上采样层和卷积层来决定,因此,只能够影响到图像的样式信息。
2019年,StyleGAN的提出后,被证实在CT胸透扫描瘤图像、显微镜里的细胞核图像、腹部CT的肝脏图像生成任务中比ProGAN及GAN衍生网络有更好的生成效果[7]。
1.2 视网膜OCT图像生成模型
针对视网膜OCT图像视网膜层间明暗交替的生物结构特征,文中构建了基于StyleGAN网络的视网膜OCT图像生成模型,优化了激活函数与调节StyleGAN网络的超参数两个方面进行了网络改进优化。
1.2.1 网络模型
基于StyleGAN网络的模型结构,StyleGAN视网膜OCT图像生成的网络模型是由StyleGAN的生成器和鉴别器构建,主要由三个步骤组成。
步骤1输入随机噪音进入到8个全连接模块层,完成输入随机噪音到中间向量w的转变。
步骤2中间向量w经过个仿射网络得到ProGAN每个卷积层后面样式转换模块的2个中间向量ai和bi(i=1, 2, 3), 接着进入改进后的ProGAN生成器部分,生成模拟数据图像G(x)。
步骤3真实OCT图像数据经过下采样过后与生成图像G(x)一同喂入右端的鉴别器中,判断生成图像数据的真假,若判断为真,则直接反馈给输出图像,否则,再反馈给StyleGAN的生成器,最后循环训练生成器和鉴别器直到模型达到纳什均衡,反馈输出图像。
1.2.2 激活函数的改进
StyleGAN网络原始的激活函数为Relu函数,但是经过文中实验发现激活函数存在计算量大,神经元死亡依然存在。采用LReLU激活函数为
(2)
式中,yi——第i层神经元的值。
对于非线性函数而言,LReLU的表达能力更强,尤其体现在深度网络中,使模型的收敛速度维持在一个稳定状态。
1.2.3 网络权重的超参数优化
StyleGAN网络采用了DiffGrad优化器来寻找网络的最优权重。DiffGrad优化器是Dubey等于2020年在Adam优化器的基础上,开发了一种自适应的新优化器,它能够自动监测随机梯度的局部变化,以避免Adam等动量优化器易跨过最优最小值的梯度优化方法[8]。文中对DiffGrad优化器中的学习率和第一阶矩学习率衰减值进行了优化,优化学习率为0.001和一阶矩学习率衰减值为0.94,以便更好地抑制模型过拟合现象的产生,以能够获取高质量的视网膜OCT生产图像,如图2所示。

图2 调整网络超参数及激活函数的生成图像
由图2a可见,真实视网膜OCT图像,明暗交替,层间解剖结构清晰。图2b为通过直接采用原始StyleGAN来生成的视网膜OCT图像,层间解剖结构略显模糊不清,其效果并不是很理想。图2c为文中提出的通过调整StyleGAN的网络超参数和优选激活函数后,逐步生成的视网膜OCT图像,其视网膜层间解剖结构较为清晰,逼近于真实视网膜OCT图像,获得到了较好改进。
日军见偷袭不成,恼羞成怒,一起朝最近的女兵石屋扫射。子弹已经在李晓英居住的石屋周围迸出了火花。陈山利飞奔的脚步,恨不得一下飞到李晓英面前,为她挡枪遮弹。
2 实验与结果分析
2.1 实验环境与数据集
CPU为Intel Core i5-7580@3.2 GHz,GPU为NVIDIA GeForce GTX 1050 Ti,内存为16 GB,显存为4 GB。操作系统为Ubuntu 16.04, 64位,Python 2.7,Pytorch 1.1。
文中的方法在Kaggle上公开数据集中选取100例共752幅正常视网膜OCT图像作为数据集,每幅图像大小为512×740,将70%作为训练集,30%作为测试集,对训练集进行100次的迭代训练,网络每次训练2个图像。
2.2 评价指标
文中采用初始分数、模式分数、核最大均值差异、推土机距离、峰值信噪比和结构相似性等GAN的6种评价标准作为图像生成质量的评价指标[9]。
2.2.1 初始分数
初始分数也被称为Inception 分数,它是图像生成质量评价最常用的度量指标为
I(G)=exp(Ex~pgDKL(p(y|x)‖p(y))),
(3)
式中:x~pg——生成样本分布;
p(y|x)——各个类别样本的概率分布;
p(y)——生成样本的边缘分布;
2.2.2 模式分数
模式分数也被称为Mode 分数,它是 Inception 分数的改进版为
M(G)=exp(Ex~pgDKL(p(y|x)‖p(y))-
DKL(p(y)‖p(yr)),
(4)
式中,p(yr)——真实样本的边缘分布。
2.2.3 核最大均值差异
核最大均值差异为

(5)


Xr——真实样本;
Xg——生成样本;
k——给定核函数。
在给定一些固定的核函数k下,它度量了真实分布pr与生成分布pg之间的差异。给定分别从pr与pg中采样的两组样本,两个分布间的经验性可以通过有限样本的期望逼近计算。
2.2.4 推土机距离
推土机距离通常称为Wasserstein距离(EMD),它等价于解最优传输问题。
(6)
式中:γ∈Γ(pr,pg)——真实样本分布pr和生成样本pg组合形成联合分布的集合;
d(Xr,Xg)——真实样本和生成样本的距离。
式(6)表示实践中W(pr,pg)的有限样本逼近,与 MMD 相似,推土机距离越小,两个分布就越相似。
2.2.5 峰值信噪比
峰值信噪比经常用作图像压缩等领域中信号重建质量的测量方法,它通过均方误差(MSE)进行定义。两个m×n单色图像I和K,如果一个为另外一个的噪声近似,那么它们的均方误差定义为
峰值信噪比为
(7)
式中:I——未压缩的原图像;
E——均方误差。
2.2.6 结构相似性
结构相似性是一种衡量两幅图像相似度的指标。给定两张图像, 两张图像的结构相似性可表示为
(8)
式中:μx——图像x的像素灰度平均值;

μy——图像y的像素灰度平均值;

σxy——图像x和图像y的协方差;
c1、c2——用来维持稳定的常数。
2.3 实验结果
文中提出的StyleGAN方法与随机森林和上下文的图像合成算法(SRF+)[10]、DCGAN在相同数据集上进行了学习训练和测试比较。表1为3种方法在6种量化指标上的对比情况,与SRF+和DCGAN两种方法相比较而言,文中提出的方法在初始分数I为1.564、模式分数M为1.249、核最大均值差异D为1.135和推土机距离W为322均取得了最小值,且文中方法的峰值信噪比P为35.36和结构相似性S为0.36均取得了最大值的良好的效果,表明文中生成的视网膜OCT图像具有较好的平滑性和锐化性。

表1 6种量化评价指标对比情况
由SRF+、DCGAN与StyleGAN的生成的一组效果图对比,图3a为真实OCT图像,图3b为SRF+生成的图像,图3c为DCGAN生成的图像,图3d为文中方法StyleGAN对应的生成效果图。由图3可见,SRF+生成的图像仍然模糊;DCGAN生成的图像虽然不模糊,但视网膜层间不够清晰;而文中StyleGAN生成的眼底OCT视网膜图像各个内视网膜层更加清晰,层间明暗交替,特别是在外感光层与视网膜色素上皮层(图中红色箭头所指的灰度值较大的明亮层)附近,像原图像一样呈现出了一定的边界线,在拓扑结构上,StyleGAN生成的视网膜OCT图像比DCGAN生成的视网膜OCT图像效果更接近于原图像。图4分别给出了DiffGrad优化器中的学习率和第一阶矩学习率衰减值等两个超参数与峰值信噪比和结构相似性等两个图像生成质量评判指标的迭代变化情况。
图4a、b呈现出学习率为0.001时,峰值信噪比和结构相似性两个值均取得最大值。图5a、b也呈现出学习率衰减值为0.94时,峰值信噪比和结构相似性两个值也均取得最大值。由图5可知,表明文中优化DiffGrad优化器中学习率和第一阶矩学习率衰减值等两个超参数分别为0.001和0.94,能够获取高质量的视网膜OCT生成图像。图6为文中方法与DCGAN方法在6种量化指标上随着学习训练迭代次数变化的对比情况图,对比图3b和3d呈现出,在训练迭代20轮之前,DCGAN的学习指标优于文中方法,而在20轮之后,文中方法的学习指标一直优于DCGAN;且在其它学习指标对比情况图中,文中方法的学习指标一直优于DCGAN,表明文中方法在视网膜OCT图像生成上具有较好的迭代收敛性能。

图3 生成图像可视化对比图
文中的方法能够生成比较真实的视网膜OCT图像,各个视网膜边界层的生成效果也比较清晰,传统DCGAN生成图像比较模糊,看不清视网膜OCT各个层的边际,而SRF+生成的图像则是一片模糊的图像,完全看不出图像的纹理细节。

图4 峰值信噪比和结构相似性随学习率初始值迭代的变化
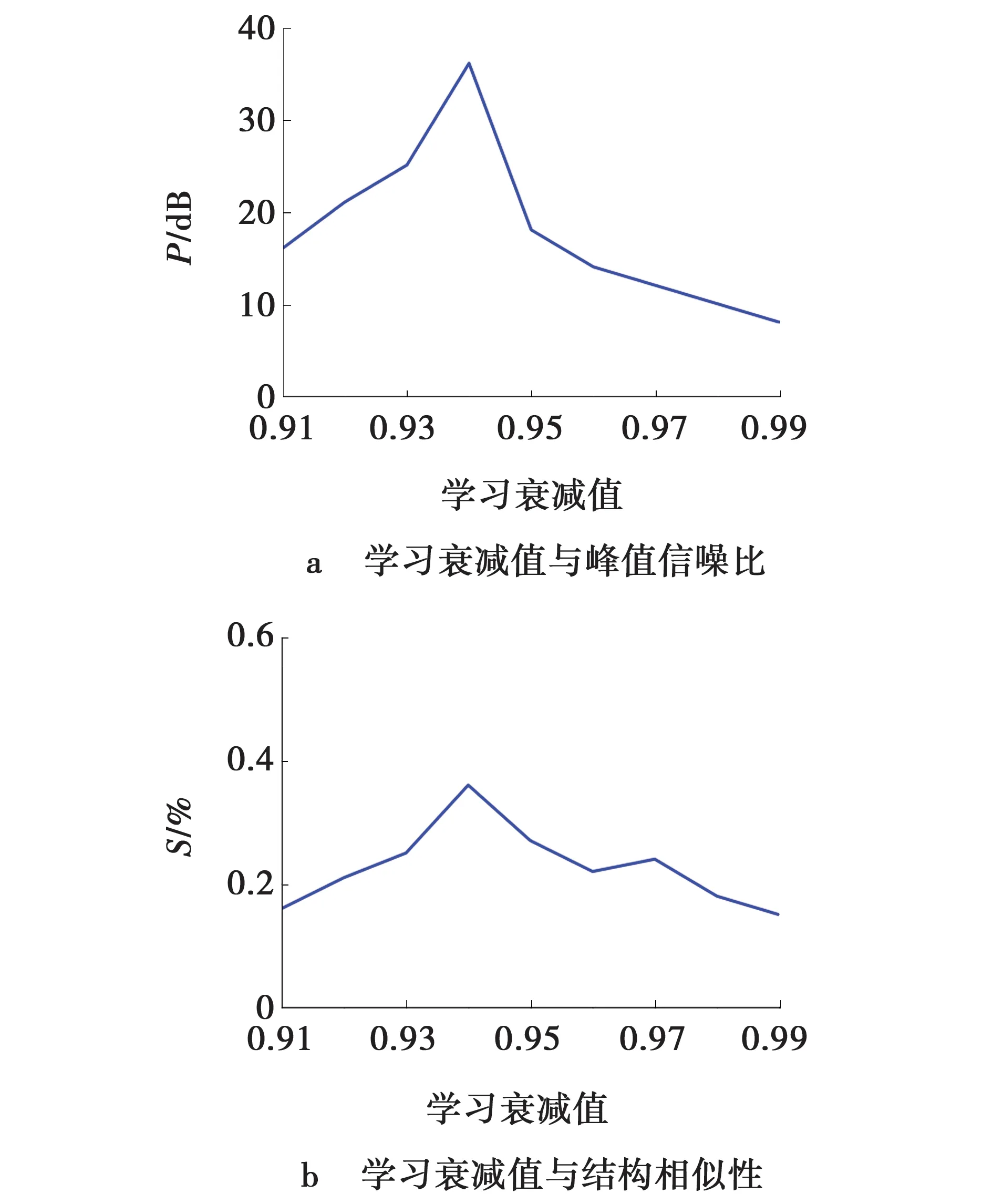
图5 峰值信噪比和结构相似性随第一阶矩学习率衰减值的迭代变化
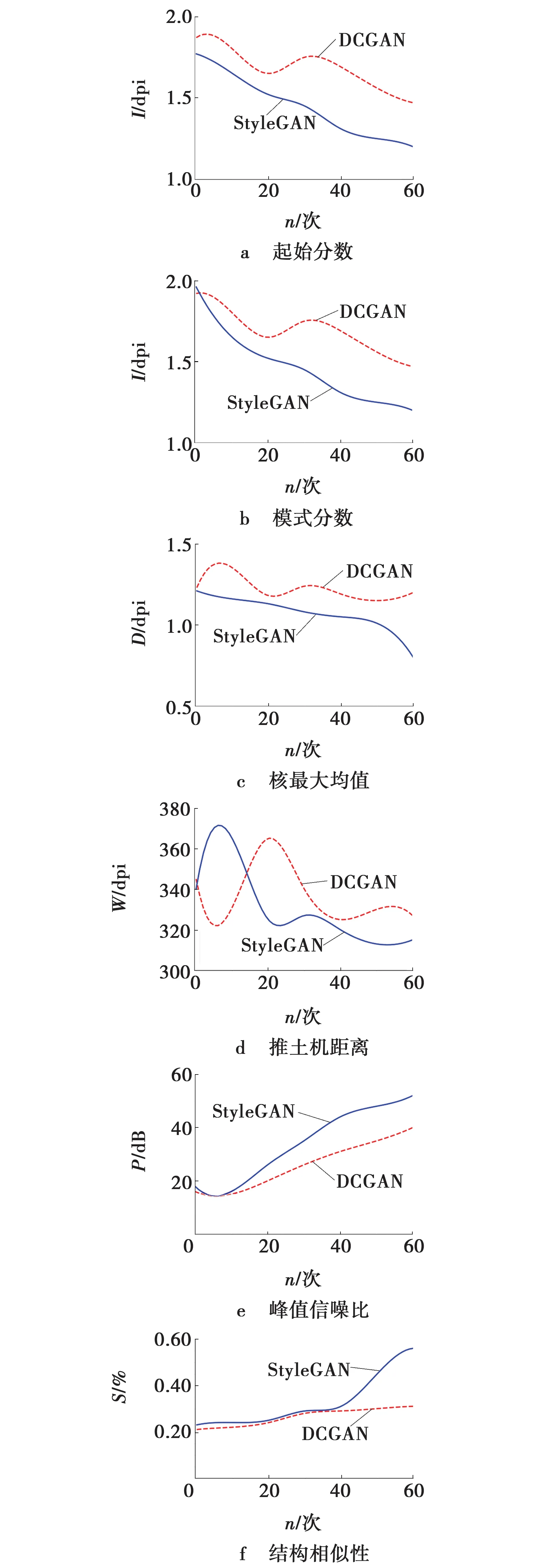
图6 6种评价指标下的迭代对比情况
文中方法和DCGAN、SRF+的ROC曲线如图7所示。它们的AUC值分别为0.78、0.62和0.56,表明文中方法在视网膜OCT图像生成上的泛化性能优于DCGAN和SRF+两种方法。

图7 文中方法和DCGAN、SRF+的ROC曲线
上述实验证明了文中方法在生成视网膜OCT图像上的优越性能,无论是比较文中方法和DCGAN、SRF+方法在生成实际图像的可视化效果,还是通过图6中生成图像的评价指标进行对比,文中的方法都比DCGAN、SRF+效果要好,从文中方法和前2种方法的ROC曲线可以看出,文中方法的AUC数值为0.78,DCGAN与SRF+的AUC数值分别为0.62和0.56,远远小于文中方法的AUC数值,可知文中方法的生成效果是优于DCGAN和SRF+的生成效果。
3 结 论
(1)文中在样式生成对抗网络框架基础上,调整和选取了网络超参数和激活函数,提出了一种基于样式生成对抗网络框架的视网膜OCT图像生成方法,应用于OCT图像生成。
(2)文中方法与SRF+和DCGAN两种方法在100例视网膜OCT图像上进行了训练、测试和比较,实验结果表明,文中方法取得了更好的OCT图像生成效果。
将对含有病变的视网膜OCT图像进行生成和分类,能够更好地辅助于眼科医生对眼部疾病患者的筛查和诊断。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
老友(2022年4期)2022-05-18
现代仪器与医疗(2022年1期)2022-04-19
北京理工大学学报(2021年12期)2022-01-13
电脑爱好者(2021年2期)2021-01-22
农村百事通(2021年12期)2021-01-17
舰船电子对抗(2020年1期)2020-04-27
北京航空航天大学学报(2019年9期)2019-10-26
保健与生活(2019年12期)2019-07-31
课堂内外(初中版)(2015年9期)2015-09-10
