
基于特征降维和神经网络的电能表内异物声音自动识别
2021-04-02 00:55:30欧习洋
机械设计与制造 2021年3期
张 进,吴 健,欧习洋,欧 熙
(1.国网重庆市电力公司电力科学研究院,重庆 401120;2.四川福德机器人股份有限公司,四川 绵阳 621000)
1 引言
近几年随着国家电网和电力基础设施的建设,电子式交流电能表得到了广泛的应用。为确保电能表计量的精确性与可靠性,电能表在出厂之前都必需经过一整套检定项目的测试[1]。电能表异物检测的目的是检测电能表内部是否存在焊渣残留、松脂残留、脱落元器件、胶沫等异物或杂物。传统的人工电能表检测是按照一定的速度和旋转方向进行摇表听取声音判断电能表是否含有异物。针对现在人工摇表检测效率低、检测结果不稳定的问题,需要一种能自动检测电能表异物声音的系统方案。异物自动检测装置通过设计自动摇表结构和自动控制系统实现自动摇表和声音采集,利用声音识别技术实现异物检测。由于异物自动检测装置采集的声音信号是典型的非线性非平稳时变信号,频率成分非常复杂,对异物声音识别提出新的挑战。
随着声学检测和计算机技术高速发展,多通道的声音采集设备已广泛应用到各行业中并且技术稳定成熟。采用声学检测技术去识别电能表异物已经成为可能,但如何对电能表进行固定、如何屏蔽削弱电能表异物检测过程中的外界干扰噪声以及提高异物声音的识别率等问题亟待解决。目前异常声音检测主要采用特征参数与分类器结合进行识别,因此特征参数与分类器的选择将会直接影响异物声音的识别率。文献[2]将MFCC、差分MFCC 以及短时能量三种特征用于GMM 的训练与识别,虽然识别率可达90%以上但是在处理不同环境的声音信号时,需根据实验结果确定高斯混合模型的参数,所以对GMM 混合阶数的选择存在局限性;文献[2]提出了一种提取声音信号MFCC 系数的方法和实验装置,解决了用HTK 提取该系数的问题,采用非线性变换和离散余弦变换,优化了提取的MFCC 系数,提高了语音识别的准确率。文献[3]基于噪声特征统计量的矿山设备健康状态判决方法,通过计算的特征参数,计算出其均值和方差两个统计量,形成一维的特征统计向量,并利用改进的短时模糊C均值聚类算法实现测试样本状态的汇聚,从而实现设备健康状态的判决,由于仅存在特征统计量,判定的准确率不高。文献[4]通过BP 神经网络,结合小波特征参数对车辆车型进行了识别,识别率较好,但单一的BP神经网络很容易欠拟合,其次小波特征的提取需要确定小波基函数以及分解层数等,这都需要一定的人为经验。鉴于上述问题,采用一种结合时域特征、线性预测系数LPC 和倒谱特征MFCC 的混合特征作为分类器的输入,并对提取的混合特征结合PCA 进行降维消噪处理;其次分类器选择基于Adaboost 的BP 神经网络,以此完成电能表内异物的检测。
2 声音信号处理
本研究是利用在工业环境中用声卡自主采集的声音信号来实现电能表内异物的自动检测,如图1 所示。故在利用声音信号进行识别之前应对信号进行预处理和特征提取。
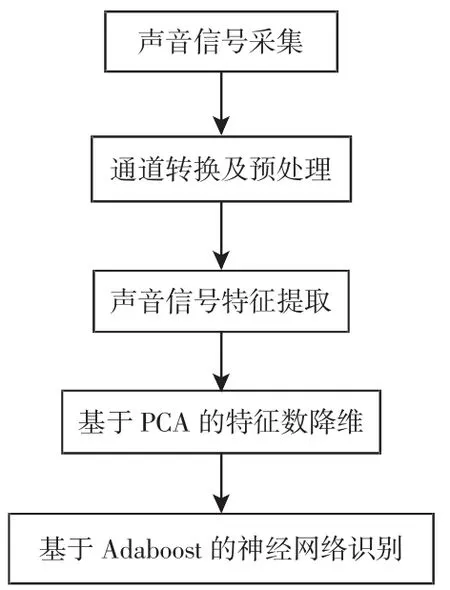
图1 一种基于声学检测的电能表内的异物声音自动识别方法Fig.1 Automatic Recognition of Foreign Object Sound in the Electricity Meters Based on Feature Dimension Reduction and Neural Network
2.1 声音信号预处理
常见的声音信号预处理流程包括:通道转换、归一化、预加重、分帧和加窗。
(1)通道转换:在采集的多通道声音中提取所检测通道的声音数据,并能有效减弱不同通道声音信号之间的干扰。
(2)归一化:消除不同样本声音信号之间的差异,并将其幅值限定在[-1,1]区间。
(3)预加重:声音信号通过高通滤波器滤波,其可以降低低频的干扰信号并加重突出高频部分的信号,还可以光滑信号的频谱。
(4)分帧和加窗:声音信号是一个非平稳过程,但是在较短的时间内可以视为稳态的。如果对声音信号直接切分成帧会造成Gibbs 效应,故为了减少声音信号的频谱泄漏和增加不同帧之间的连续性,对声音信号进行加窗处理。
设采集到的声音信号的序列为x(n),W(n)设为窗序列,h(n)是与W(n)有关的滤波器,则各帧经处理后的输出可以表示为:

2.2 声音信号特征提取
(1)声音的能量随时间而变化,经过前面的预处理之后计算第i帧声音信号xi(n)的短时能量的公式为:

式中:E(i)—声音信号的幅度或能量随时间缓慢变化的规律。
(2)声音信号的样值序列为x(n)。而p阶预测器是根据过去的p个信号样值的加权和而预测的当前信号值x(n),其称为p阶预测器。设为x(n)的预测值则有:

式中:ai—线性预测系数。
线性预测误差定义为信号x(n)与线性预测值之差,用e(n)表示。
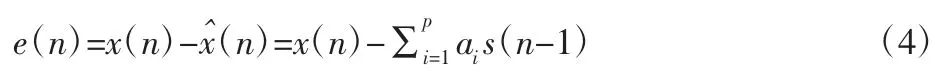
信号x(n)通过滤波器器的输出可以得到预测误差e(n),该系统的传递函数如下:

称系统A(z)为LPC 误差滤波器。在线性误差e(n)最小的准则下求解预测误差滤波器A(z)的预测误差系数ai,这个过程称为LPC 分析。
(3)通过Mel 尺度频率域提取出的梅尔倒谱系数(MFCC)具有较好的鲁棒性,能准确反映声音信号的特征。对每一帧信号进行快速傅里叶变换,将时域波形数据转换为频域能量信息并得到各帧信号的频谱。Mel 滤波器的频域响应为Hm(k),通过滤波器后:

声音信号x(n)的倒谱为:

式中:参数N—声音信号x(n)的长度;C(k)—正交因子。
计算得到MFCC 参数:
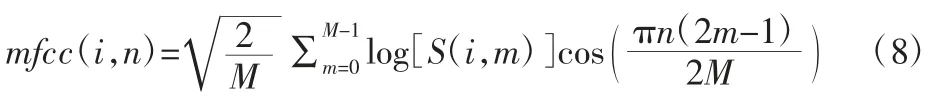
由于声音是时变信号,但标准的MFCC 系数只能反映声音信号的静态特性,故需要引入差分系数来表现声音信号的动态特性。将动、静态特征结合起来才能更全面的反应声音信号的整体特征,能有效的提高声音信号的识别率。采用下面的公式来计算帧间的差分参数:

式中:dt—第t个一阶差分;Ct—第t个倒谱系数;Q—倒谱系数的阶数;K—一阶导数的时间差,可取1 或2。
2.3 声音特征系数处理
为了使得到的声音特征参数能全面的反映声音信号的时、频特征,故对声音特征参数进行排列和处理。短时能量、LPC 系数和MFCC 系数构成混合特征矩阵,其第一维为短时能量,第二维为LPC 系数,第三维到第二十六维为MFCC 系数。采用主成分分析(PCA)对数据进行降维处理,计算主成分的目的是将高维数据投影到较低维空间,在一定程度上减少声音特征矩阵的维度,为声音信号识别减少计算量。以降维后得到的特征矩阵作为分类为器的输入特征,这样分类器不仅计算复杂度低而且计算量小。声音特征系数矩阵为xi,根据PCA 算法计算原理,分别计算其均值:
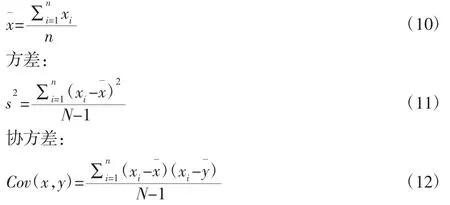
通过计算协方差矩阵的特征向量和特征值并舍弃最小的特征值重新构成特征矩阵。因为最小特征值往往与噪声有关,舍弃它们不仅能增加样本的采集密度还能起到一定的去噪效果,如图2 所示。

图2 声音信号特征系数降维示意图Fig.2 Schematic Diagram of the Dimensionality Reduction of the Characteristic Signal of the Sound Signal
2.4 声音信号识别
Adaboost 算法通过将多个弱BP 神经网络分类器组成强分类器,多次训练BP 神经网络来预测样本的输出,使输出正确率最高,如图3 所示。采用留出法将数据集分为互斥的两部分,一部分作为训练集(m组数据),一部分作为测试集。初始化测试集数据的分布权值和初始化BP 神经网络权值和阈值。
用训练集数据训练第i个BP 神经网络,得到训练数据集的输出、预测误差ei和预测序列g(i)。

根据预测序列的预测误差计算序列的权重ai。

然后根据预测序列调整新一轮训练样本样的权重,权重调整公式为:

式中:Bi—归一化因子,在不影响数据有效性的前提下使数据的权值和为1。
训练i轮之后的到i组弱分类函数f(gi,ai),由这些弱分类函数可以得到强分类函数h(x)。


图3 基于Adaboost 的神经网络识别图Fig.3 Adaboost-based Neural Network Identification Map
3 实验验证
通过设计和定制夹持机构对电能表进行固定,然后通过控制伺服电机按照一定的速度整体摇动被夹持的电能表。利用罗兰声卡和得胜DM-24 麦克风进行声音信号采集。采用的持表装置,如图4 所示。为了检验主成分分析(PCA)对特征系数降维的效果,将原始混合特征矩阵和降维后的特征矩阵分别输入基于Adaboost 的BP 神经网络并测试识别速率,如表1 所示。

图4 声音信号采集装置图Fig.4 Sound Signal Acquisition Device Diagram

表1 特征降维与不降维的识别速率对比表Tab.1 Comparison of Calculation Rates of Feature Dimensionality Reduction and Non-Dimensionality Reduction
分别将100、500 和1000组声音信号输入已经训练好神经网络进行测试。在测试数组小的时候,使用主成分分析(PCA)对特征系数进行降维和不降维对识别速率的影响不大。但是随着测试数组的增加,降维后的声音信号由于计算量小故识别速率快。
为了验证本方法的有效性,采用不同的声音特征参数同时输入基于Adaboost 的BP 神经网络和BP 神经网络,并对比分析其识别率。由于采集的电能表声音信号只需要判断是否含有异物,不需要判断具体的异物种类。由表可知,短时能量是识别率最低的特征参数,因为其只反应了声音信号的时域特征没有频域特征。传统的LPC 和MFCC 虽然比单一的时域特征识别率高但是计算量大识别率不高。提出的降维后的混合特征参数不仅计算量小而且识别率高,如表2 所示。。

表2 不同特征参数的识别率表Tab.2 Identification Rate Table for Different Characteristic Parameters
用提出的方法对电能表进行识别,实验采用留出法将数据集分为互斥的两部分,一部分作为训练集,一部分作为测试集,经过重复实验1000 次,通过图发现每一次的识别率在90%左右甚至100%,计算1000 次得到的平均识别率在96%左右,如图5 所示。
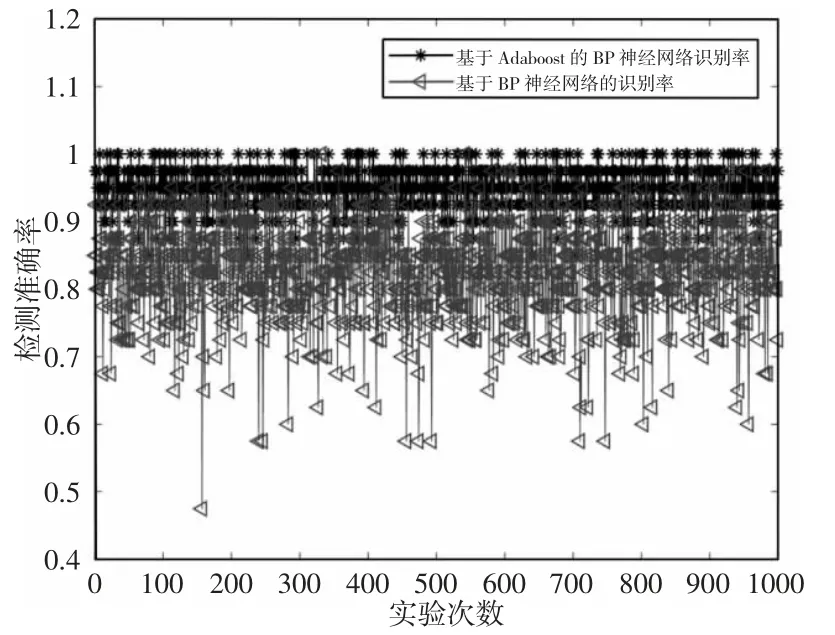
图5 基于Adaboost 的BP 神经网络和BP 神经网络识别对比图Fig.5 Comparison of BP Neural Network and BP Neural Network Based on Adaboost
4 结语
根据电能表内异物声音信号的基本特点提出了一种基于特征降维和神经网络的电能表内异物声音自动识别方法。首先比较了混合特征经由PCA 降维处理前后的识别速率,结果表明经PCA 降维处理后识别速率有所提高,并一定程度消除了混合特征中冗余信息;其次比较了单一特征参数与混合特征参数在BP 神经网络下的识别率及基于Adaboost 的BP 神经网络下的识别率,其结果是混合特征参数明显较优,基于Adaboost 模型组合成的强分类器也明显优于单一的神经网络,此方法避免了单一参数及单一神经网络不能很好拟合数据的缺点,提高了识别准确率,在电能表内异物检测中具有较好的应用价值。
猜你喜欢
车主之友(2022年4期)2022-08-27 00:57:12
数学小灵通(1-2年级)(2021年11期)2021-12-02 01:30:12
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
海峡姐妹(2019年12期)2020-01-14 03:24:40
中学生数理化·中考版(2019年12期)2019-09-23 06:23:50
制造技术与机床(2017年11期)2017-12-18 06:46:39
电测与仪表(2015年7期)2015-04-09 11:40:04
电测与仪表(2014年16期)2014-04-22 05:20:28
电测与仪表(2014年6期)2014-04-04 11:59:34
