
药膳大数据的平台构建与实现
2021-04-01 05:43孙慧婷
长春大学学报 2021年2期
方 晓,孙慧婷
(1. 安徽省中医药科学院 亳州中医药研究所,安徽 亳州 236800;2. 亳州职业技术学院 信息工程系,安徽 亳州 236800)
1 药膳大数据的分析
大数据是相对传统数据而言的,在获取数据、存储数据、管理数据、分析与挖掘数据、应用数据等方面规模上超过传统数据。在思维方式上也形成大数据范式,主要包括:(1)技术方面,因大数据中数据量规模是海量的、 数据结构和类型是多模态的、数据的产生是实时性的,为此产生与之相适应的采集数据、管理数据、分析数据。并行计算方面,从大数据产生角度分析,有面向批量数据计算模型、流式数据计算模型、图式数据计算模型。(2)存储方面,有HDFS、HBase、Tachyon 等分布式存储开源技术。(3)分析挖掘方面,传统数据挖掘、机器学习,深度学习等新技术。(4)思维方面,在现实生产生活中,把大数据作为生产资料,云计算作为生产力,人工智能算法作为生产关系,将结果作为传统企业的内在生产动力,发挥大数据价值[1]。
药膳大数据涉及多领域多学科知识,药膳的生产过程主要包括:中药材、烹饪、医学三个方面。药膳大数据是从药膳生产、药膳消费活动中产生的具有现实价值意义的数据集合。有学者从药膳的生命周期的角度分析,认为药膳大数据包含从药膳原材料生产、药膳生产、药膳消费等环节采集的数据;有学者从药膳数据的组合元素上分析,药膳大数据包括药材数据、组合配方数据、生产配方数据、消费群体等数据。本研究认为药膳大数据应包括:(1)药膳大数据指“大”的数据集合,有数据量大、结构复杂、类型多,又具有养生数据医学、时空和序列的领域特点。(2)从功能上包括:药膳大数据计算模型、药膳大数据存储技术和药膳大数据分析挖掘技术。(3)药膳大数据也指利用全量的、混杂的数据发现相关关系和规律,并以数据驱动的方式来助推养生经济和养生思维。药膳大数据生产应用,其关键在于药膳大数据平台的构建。
2 药膳大数据平台设计与构建
2.1 需求分析
药膳信息大数据平台融合药膳药材、生产配方、消费群体等数据,并且海量存储、深度挖掘这些数据,为药膳消费、药膳养生文化的推广提供支撑,该平台应具备下列功能性需求:
(1)药膳数据采集方面,药膳数据采集接口分为线上和线下。线上主要对第三方餐饮信息平台数据采集,具有实时性,线下对批量数据进行导入。采集接口支持结构化数据记录和非结构化数据记录。
(2)存储数据方面,支持多系统存储方式,以MapReduce模型为基础,对药膳数据的相关性进行存储优化,对药膳数据使用频率进行存储优化,均衡各数据节点计算复杂度。并提供高效的管理与快速查询功能。
(3)数据计算方面,面向海量药膳的数据,通过MapReduce并行计算引擎,对流处理大数据,大图数据以及内存的计算,可实现自定义配置。
(4)分析挖掘方面,应提供面向药膳领域的分析,利用统计学方法,对药膳数据进行计算与分析。通过深度学习算法建立学习模型,实现个性化数据的推送,面对数据应用层面,灵活配置算法,可视化挖掘结果。
2.2 平台架构设计
药膳大数据平台融合药膳数据采集、存储、计算与分析挖掘的整个生命周期。综合相关文献分析,研究其他平台的架构。对药膳大数据平台的架构进行了设计,如图1所示。

图1 药膳信息大数据平台的架构
(1)数据源
药膳大数据可分以下5种,如图2所示。
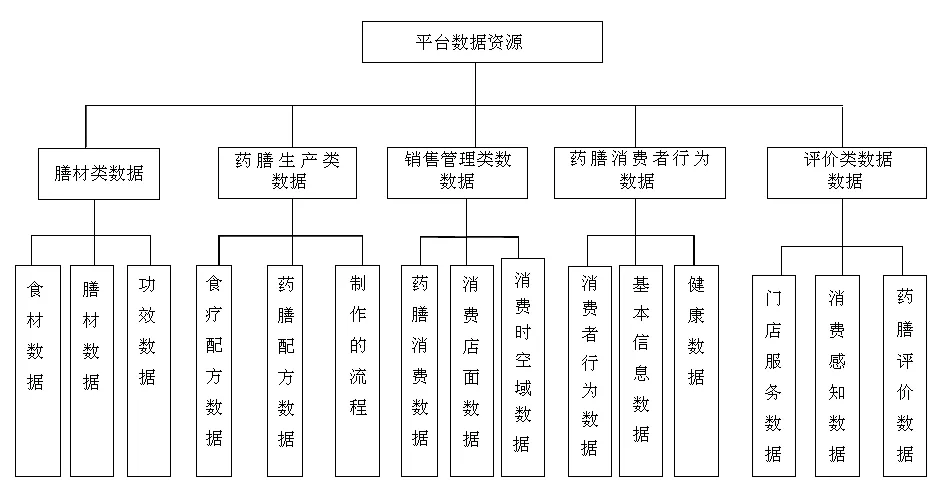
图2 药膳大数据平台数据资源体系
①膳材类数据,包括食材数据、膳材数据、功效数据、制作和加工流程数据等,这些数据大多以文本存储在系统中。
②药膳生产类数据:包括食疗配方数据、药膳配方数据,制作的流程等数据,这些数据以文本、音频、视频非结构化的方式存储。
③销售管理类数据:包括药膳消费数据、消费店面数据、消费时空域数据等,这些数据多以结构化的形式存储在关系型数据库中。
④药膳消费者行为数据,即消费者的行为数据、基本信息数据、健康数据等。
⑤评价类数据,包括门店服务数据、消费感知数据、药膳评价数据,是以文本为主的数据。
(2)采集层
药膳数据的采集可以采用线上实时和线下批量两种方式进行。实时采集主要利用接口对第三方平台进行实时采集、爬虫技术采集网络隐藏的药膳相关数据。批量采集通过用户的导入、复制、录入等行为对系统操作的日志、其他后台记录、相关资源文件等数据进行采集;而对于线下传统消费环境中的数据可以利用药膳协会资源实现平台接口对接采集技术进行获取。
(3)存储层
不同的数据源采集的数据在结构、类别、规模上是不相同的。因此,在数据存储上采用不同的数据存储系统。对文本数据采用文件存储系统、结构化数据采用相关的数据库、数据仓库进行存储。对于零散、结构复杂的可以通过内存进行存储。为存储庞大的药膳数据,存储系统采用分布式架构。为后续的数据处理、数据挖掘提供支持。
(4)数据处理层
大数据管理平台的核心在于分析和挖掘价值高的相关关系,而实现这一目的的关键在于数据处理层的计算模型。本平台运用MapReduce计算架构,对于不同数据类别有相对应计算模型,对大规模历史数据采用批处理计算模型进行并行运算;对实时产生的流式数据采用流计算模型进行处理;对平台的计算结果以知识图谱形式可视化。对知识图谱的管理采用图计算模型。为提高平台响应实时性、提高数据计算的速度,利用内存计算模型进行内存管理。
(5)分析挖掘层
药膳大数据应用主要方面:①药膳经营统计,通过药膳消费和生产产生的数据,运用数据统计分析方法对药膳类别销售排名、药膳门店销售排名、用户消费排名、食材和药材消费排名,以及用户健康状况与药膳药用功能相关关系统计;②药膳消费行为分析,通过第三方餐饮平台的药膳消费数据、实体店独立点餐平台的数据库记录数据、在药膳网站网络爬取的日志数据,运用机器学习的深度学习算法,以及传统的挖掘算法如规则挖掘、聚类分析等算法进行挖掘分析,建立用户画像,主要包括口感、偏好、习惯、需求等方面,为药膳的营销、药膳文化传播与文化继承进行个性化推送奠定算法计算基础。
(6)应用层
大数据的价值在于应用。基于药膳经营数据统计分析可以对药膳产品进行数字画像,包括消费用户健康类别、体验度、评价情况、产品生产门店,发现药膳产品的消费群体、预测未来药膳市场需求;然后进行个性化推荐,并对药膳的生产药材、食材进消存情况进行干预管理。在药膳消费者方面,可对消费者行为进行指导,以便消费者调整消费行为、养生计划等。对药膳生产资源的挖掘,构建药材、药膳、养生的知识图谱。
3 药膳信息大数据平台的关键实现技术
3.1 药膳大数据EXL技术
因大数据平台数据的多样性特征,在数据采集模块上,针对类型不同的数据采取与之对应的采集技术。对半结构数据,采用xmL、Flume、Kafka等组件技术,但上述技术框架需要对数据的抽取、转换、加载。而EXL技术是实现这些处理的最佳选择。
对于药膳大数据平台而言,数据量大,传统的方案清洗数据导致性能下降,为应对此问题, 本系统利用 Hadoop 平台中的 Hive工具清洗数据。Hive工具的优点是对大量结构化数据进行存储和处理, 数据处理模块如图3所示。
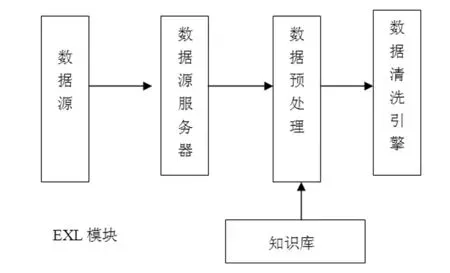
图3 药膳信息大数据平台的数据处理模块
数据源主要包括数据库 、数据仓库 、数据表和其他类型的数据集合。数据源服务器通过用户的请求对数据源提取相关的数据。按照预定义的数据结构进行抽取、通过数据清洗引擎并对数据进行分析、识别噪音、合成。用户可以定义知识库编辑和定义数据清洗规则。
3.2 药膳大数据存储设计技术
药膳数据的集中存储平台的关键性问题随着数据结构的复杂化,数据存储由关系型数据库转到可扩展的 NoSQL 型分布式数据库。构建在 HDFS 之上的分布式数据库HBase具有可伸缩性动态模式特点,对于实时读写大规模的数据是最优选择[2]。
3.2.1 数据库部署设计
本平台数据存储设计由ZooKeeper 独立部署到两台机器上,负责协调 RegionServer服务器集群和Hmaster服务器集群、meta 表信息的存储和感知 RegionServer 的状态,这样部署有以下优点:第一,HBase 和 ZooKeeper 的强耦合,方便后期对 HBase 集群的升级、管理以及大数据平台的扩展。第二,ZooKeeper 作为配置中心,一旦配置信息发生改变或突发崩溃,能提供自动容错的时间,重新选取候选者执行未处理完的作业。第三,ZooKeeper通过上层的索引支持,实现自动负载均衡。
3.2.2 药膳数据 rowkey 的设计
为了避免“热点”问题。我们将HBase 与 Solr 相结合进行解决。HBase 解决方法将风格口味数据进行随机散列,并提前为药膳产品信息数据表建立预分区,随机散列化风格口味数据采用MD5 算法[3]。风格口味数据由风格口味FID和类别CID两部分组成, 数据缺失情况下有正常ID进行补充。由于药膳产品查询模块会根据药膳类别号直接索引,因此行键末位风格口味FID,将药膳产品类别CID数据转换为哈希值再转换为Bytes 类型,加上风格口味FID转为 Bytes 类型的值,即组成行键。最后生成 rowkey 的函数如(1) 所示:
rowkey = MD5Hash. getMD5AsHex(CID) +CID + FID,
(1)
3.2.3 药膳产品数据列簇的设计
药膳产品数据主要字段包括: 生产门店、产品类别号、产品号、风格口味类别、生产时间、消费时间、制作主厨ID、食材1、食材2、药材1、药材2等最少20个字段,至多42字段。生产时间与消费时间采用 4 位时间占位符进行存储,精确到分钟级别。其他字段统一解析成字符串类型存储。因为列簇规模与 region 刷新I/O开销是成正比的,且药膳产品数据各字段应用较统一,所有字段共同构成药膳产品数据唯一列簇 FProperties。药膳产品数据列簇设计如表 1 所示。

表1 药膳产品信息数据表结构
3.2.4 文本药膳数据存储技术
药膳大数据平台的思路是将若干个小规模文本文件组合成大规模文本文件,减少小规模文件的数量,从而减小内存占用率提高文件的读取速度。运用HAR、Sequence File 和 Map File技术方法把药膳配方数据文件、药膳功效数据文件、药膳药材功效数据文件合并成规模大的文件,在完成对小规模数据文件的冗余压缩后,将处理后的文件存储在HDFS中,同时进一步降低Name Node节点的数据规模,降低Name Node的内存使用率。
3.3 药膳大数据的分析挖掘技术
药膳大数据的核心是综合运用数据挖掘技术对药膳数据进行预处理、精准分析,通过分析与挖掘手段,把数据变成有价值的信息,以此促进药膳生产管理的优化、药膳文化传承与推广、促进药膳消费。本平台对目前可用的药膳大数据分析和挖掘,所用到的算法与应用总结如表 2 所示。

表2 药膳大数据平台的相关数据分析技术一览表
对药膳大数据分析挖掘有两个方面的研究工作:(1)对挖掘算法的研究;通过海量、高速、多样药膳大数据处理需求,解决药膳养生信息化问题;(2)充分挖掘药膳数据的领域特征,以深度学习算法结合消费认知、消费习惯构建精准度高、适应性强的个性化推送系统。
4 平台的实现
药膳大数据平台开发运用当前Java的主流技术,Hadoop技术是该平台核心技术,主要以半结构化和非结构化数据为主存储大量数据,批量处理海量数据,建立数据处理系统。平台支持Windows和Linux(CentOS Linux 6.3 x86_64版本)操作系统。
该平台分为药膳配方数据分析、消费用户社交网络分析、药膳数据挖掘、用户画像、个性化推送五个模块。药膳配方数据分析包括食材配方数据、功效数据、制作和加工流程数据等,这类数据多以文本、音视频等非结构化的形式存储在文件系统中,主要采用Text Categorization、Concept Extraction等算法,结果如图4所示。

图4 药膳配方数据分析
药膳消费后,带来用户健康指数的变化,用户对药膳的效用产生评价。效用评价数据与药膳配方以及生产流程数据、食材数据,四者间关联关系挖掘和分析如图5所示。消费用户社交网络分析,该模块主要采用Community Discovery、Page Rank等算法计算消费用户社群关系,对消费用户社群网络中关系进行分析。
图5 消费用户社交网络分析
数据挖掘模块即从数据库中大量的数据揭示出隐含的、潜在的信息的过程。通过自动化地分析数据,作出相关的归纳性的推理,并进行可视化展现,如图6所示,如通过Association Rule Minin算法分析药膳功效与疾病关联挖掘、药膳功效与养生部位关联挖掘、构建药膳、疾病、部位关系图。
图6 药膳数据挖掘
利用聚类、分类等相关数据挖掘方法分析每种药膳消费用户群特征,以主成分分析方法挖掘消费用户群的主从属性特征(年龄、职业、收入等)。再以关联规则挖掘消费用户群与药膳种类、效用、价格之间的关系,最后构建每个品种药膳的用户画像并可视化,如图7所示。该模块包含内容有:(1)消费用户分类,根据用户画像推荐药膳产品;(2)根据用户消费记录和信息阅读记录,利用朴素贝叶斯判断用户的消费习惯;(3)采用人工神经网络算法,为高纬度特征数据相关学习。
图7 药膳数据挖掘
5 结语
构建药膳大数据平台是消费者个性化推送、药膳门店精准化管理的要求,是量化药膳生产企业管理、深入研究药膳文化传承与推广的需求。药膳产业的发展应以药膳大数据平台为依托,以破解当前旅游养生产业信息化孤岛问题,通过海量药膳数据的采集、存储与计算、分析挖掘,驱动药膳在个性化消费、精准生产、科学管理、药膳研究、养生文化等多方面的变革与创新,促进大数据与养生旅游的深度融合。本研究按照软件工程的思路,从解决药膳养生信息化问题出发设计并构建了药膳大数据平台,并对涉及的关键实现技术进行了详细阐述。后续研究将基于该平台完善个性化推送模式、精准生产与管理模式的实践应用,以期为药膳生产者、消费者、文化传承者提供更精准性的个性化支持。
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
中老年保健(2021年8期)2021-08-24
小康(2021年1期)2021-01-13
现代装饰(2020年8期)2020-08-24
人大建设(2018年3期)2018-06-06
瞭望东方周刊(2018年8期)2018-03-08
瞭望东方周刊(2017年35期)2017-09-22
非公有制企业党建(2016年1期)2016-07-19
大社会(2016年6期)2016-05-04
饮食科学(2009年1期)2009-03-27
