
基于深度学习的图像隐写研究进展
2021-04-01 01:18付章杰李恩露黄永峰胡雨婷
计算机研究与发展 2021年3期
付章杰 李恩露 程 旭 黄永峰 胡雨婷
1(南京信息工程大学计算机与软件学院 南京 210044) 2(鹏城实验室 广东深圳 518066) 3(清华大学电子工程系 北京 100084)
(fzj@nuist.edu.cn)
隐写是一种将秘密信息隐藏于载体进行隐蔽通信的技术,在信息安全、数据通信等多方面都发挥着重要作用,对保障数据安全、维护社会稳定都具有重要意义.常用的隐藏载体包括文本、图像、音频、视频等,其中应用最广泛的是基于图像的隐写技术,嵌入秘密信息之前的原始图像称为载体图像,嵌入秘密信息之后的图像称为含密图像.
在图像隐写的第1阶段,研究者们通过特定的嵌入方式修改像素值[1-3],如最低有效位替换或修改,将秘密信息隐藏于载体图像中,达到隐蔽通信的目的.这种类型的像素修改一般发生在像素比特位的低位,低位的比特值反映图像的细节信息,因此替换为秘密信息并不会影响图像的整体效果.但是该类方法会对图像的统计特性造成明显的改变,随着专用型隐写分析方法与通用型隐写分析方法的出现,该类图像隐写技术难以满足隐蔽通信的安全性要求.
在图像隐写的第2阶段,研究者们考虑载体图像的自身属性,使用内容自适应的隐写方法.由于图像本身具有高度的复杂性、存在较多的冗余信息,对图像做微小的改动并不会引起人类视觉异常,如纹理复杂区域的统计特性难以被检测出异常情况,因此,在这些区域进行隐写就可以提高图像隐写的隐蔽性.内容自适应隐写又称为最小失真隐写,为每个像素分配嵌入成本,嵌入成本反映像素修改后被检测出的风险,该图像的隐写失真为所有更改像素的嵌入成本之和.内容自适应隐写的最终目标是找到合适的嵌入位置使隐写失真最小,研究的主要内容是隐写失真代价函数的设计,该函数用于衡量每个像素的嵌入成本.最常用的定义失真代价函数的准则是启发式原则,由于图像复杂区域的异常模式难以被检测,因此复杂区域的嵌入成本较小,HUGO(highly undetectable stego)[4]为此原则下第一个失真函数,WOW(wavelet obtained weights)[5],UNIWARD(universal wavelet relative distortion)[6-8],HILL(high-pass,low-pass,and low-pass)[9]等都是先进的内容自适应图像隐写方法.随着内容自适应隐写的出现,隐写分析器的检测能力也进一步提升,出现了捕捉图像高维特征的富模型隐写分析器[10-12],如空域富模型(spatial rich model, SRM)[10].通过特定的高通滤波器获得噪声残差的高阶统计量,以此作为隐写特征进行分析,富模型在传统隐写分析领域具有突出的性能,传统的图像隐写方法已经难以抵抗隐写分析的检测.
近年来,为了提升隐写的隐蔽性,研究者们致力于研究新的隐写技术.由于深度学习具有强大的特征学习能力,且在计算机视觉等领域产生了许多研究成果,研究者们将深度学习引入图像隐写中,用大量的数据训练神经网络,让网络学习更隐秘的隐写行为.最核心的转变是将传统的依赖手工、先验知识设计的隐写方法转化为依赖于数据驱动、网络自主学习的隐写方法,具体而言,深度学习的引入对载体图像本身、信息嵌入的原则、信息嵌入的方法等多方面都有较大的应用意义.为了增强隐写的隐蔽性,人们选择纹理丰富的图像作为隐写载体,随着深度学习的引入,载体图像的获取来源并不局限于图像库.生成对抗网络(generative adversarial network, GAN)[13]具有强大的图像生成能力,可以根据隐写的需要生成适合隐写的载体图像;结合生成对抗样本[14-15]的技术增强原始图像,使含密图像具有主动欺骗隐写分析器的能力,这些方法都使载体图像更适于隐写过程.为了设计合理的失真函数,制定更好的自适应嵌入原则,基于深度学习的失真函数设计方法,不根据先验知识设计失真函数,而是考虑统计上的不可检测性,在与隐写分析网络对抗学习的过程中,由生成网络自动学习图像中每个像素点的失真值.在自适应隐写方法中,隐写算法常常结合编码方法一起使用[16],研究者们大多采用伴随式矩阵编码(syndrome-trellis codes, STC)[17]的方式得到含密图像,STC编码方法可以在给定隐写容量和像素失真的前提下实现最小的嵌入失真,以像素值最少的修改实现秘密信息的嵌入.基于深度学习的含密图像生成方法,通过编码-解码网络就可以实现秘密信息的嵌入与提取,对于图像隐写的操作者而言,无需具备隐写的先验知识,同时可以实现大容量的图像隐写.
由此可见,深度学习为图像隐写方法带来了巨大的变革,但上述3种基于深度学习的载体图像获取、隐写失真设计、含密图像生成方法没有脱离隐写方法的本质,即载体修改,在隐蔽通信中只要图像被修改,就会使隐写分析有迹可循.除了通过修改载体图像实现图像隐写,还存在通过选择或者合成载体的无载体图像隐写方法.无载体图像隐写不需要原始的载体图像,更不需要对载体图像进行像素修改,通过与秘密信息构建映射关系来选择或者合成图像获得载体图像.由于没有动态的嵌入过程且所获得载体图像本身已经携带秘密信息,该类载体图像即含密图像.无载体图像隐写与上述3种基于深度学习的载体图像获取、隐写失真设计、含密图像生成方法相比最大的不同之处在于,隐写时不需要对载体图像做出修改,因此不会在图像上留下隐写痕迹,含密图像具有天然的抗隐写分析能力.随着研究的深入,出现了一些与深度学习相结合的无载体图像隐写方法,进一步提升了隐写的隐蔽性与容量.鉴于无载体图像隐写具有天然的抗隐写分析性能,尤其在结合深度学习之后又有了更大的发展空间,因此,该类隐写方式值得进一步研究.
本文从基于深度学习的图像隐写和无载体隐写2个方面对近期的图像隐写方法进行分析和总结,具体分类如图1所示.着重讨论基于深度学习的图像隐写技术,将基于深度学习的图像隐写分成3类:1)基于深度学习的载体图像获取;2)基于深度学习的隐写失真设计;3)基于深度学习的含密图像生成.最后阐述与分析无载体图像隐写方法的优缺点.
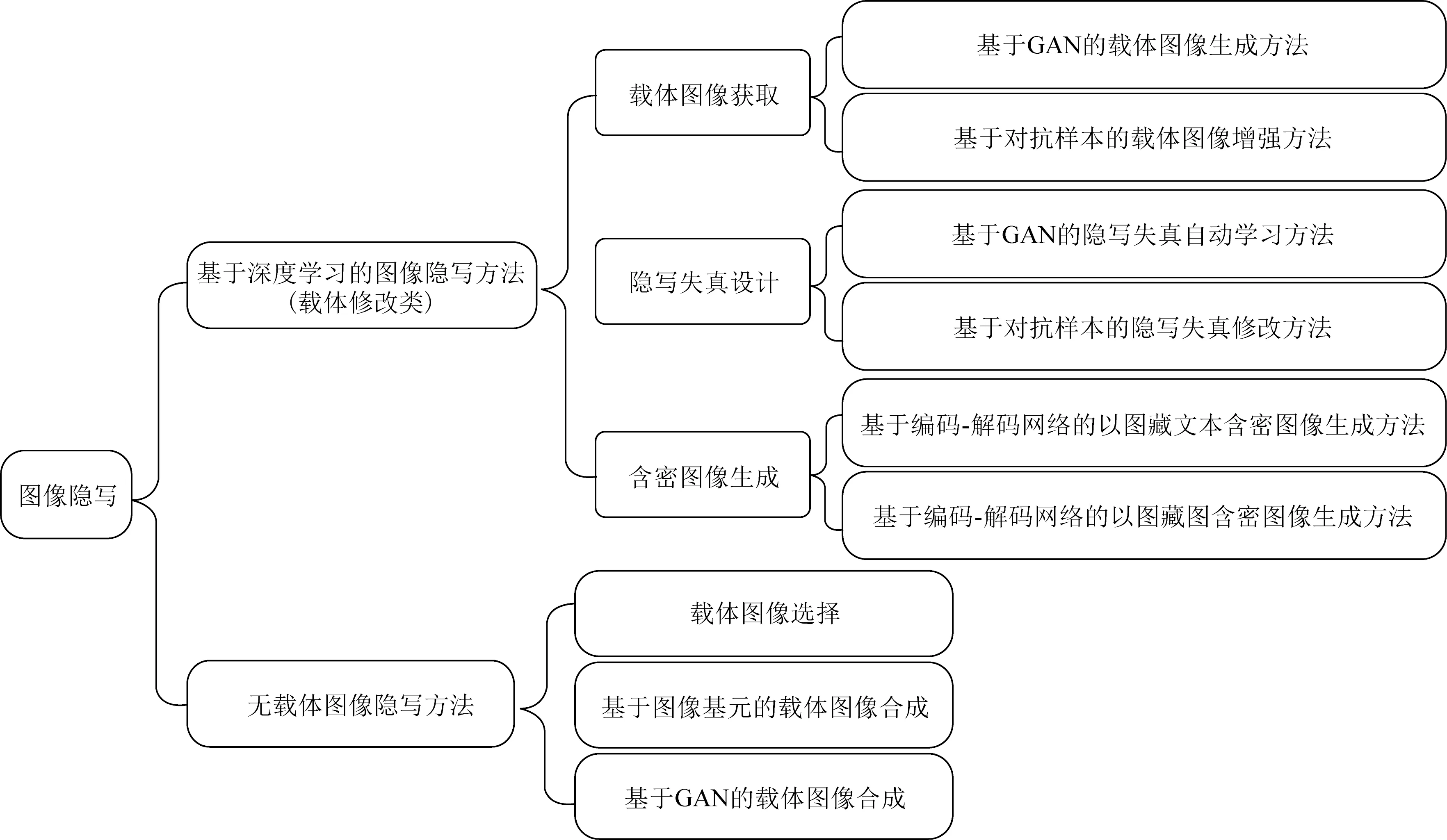
Fig. 1 The classification of recent image steganography图1 近期的图像隐写分类
1 基于深度学习的载体图像获取
随着LeNet[18]、AlexNet[19]、GAN[13]、VGG[20]、Inception[21-22]、残差网络(residual networks, ResNet)[23]等网络模型的提出,深度学习的研究与发展进入了爆发时期,在图像去噪、图像识别、图像分类等计算机视觉领域有成功的应用.其中,研究较为广泛的有生成对抗网络和对抗样本,二者在图像隐写领域的应用为隐写方法带来了巨大的变革.随着深度学习的引入,用于隐写的载体图像的获取来源并不局限于图像库,还可以借助深度学习技术获得更适合隐写的载体图像.根据获取方式的不同,本节从基于生成对抗网络的载体图像生成、基于对抗样本的载体图像增强2个方面分析深度学习在载体图像获取中的应用.
1.1 基于GAN的载体图像生成方法
基于生成对抗网络的载体图像生成方法,运用了GAN网络中对抗博弈的思想,网络训练的依据是2014年Goodfellow等人在文献[13]中提出的目标函数.将生成对抗网络引入图像隐写,目标是在对抗训练的过程中生成适于隐写的载体图像,嵌入秘密信息后使隐写分析器误判.
2017年Volkhonskiy等人[24]提出SGAN(ste-ganographic generative adversarial networks)网络模型,这是第1个基于生成对抗网络的图像隐写方法.生成网络在与判别网络、隐写分析网络的对抗博弈中调整网络参数,使得生成的图像在嵌入信息后达到自然图像真实的效果,可以欺骗隐写分析,换句话说,生成的图像更适用于隐写,该方法从载体图像的角度提高了隐写的隐蔽性.具体的网络结构如图2所示,在基础GAN的结构上,加入隐写分析网络,以生成网络生成的图像为载体,载体输入给判别网络,提高载体图像的真实性.在得到载体图像之后,用传统的隐写方法嵌入秘密信息,将得到的含密图像输入给隐写分析网络进行判别,根据判别结果优化生成网络,提高含密载体抵抗隐写分析检测的能力.在网络训练稳定后,生成的载体图像真实自然且适于隐写,判别网络无法正确地区分生成的载体图像与真实图像,隐写分析网络无法区分载体图像与含密图像,隐写的隐蔽性得到了保障.
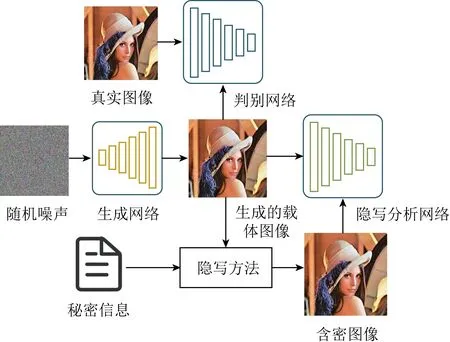
Fig. 2 The architecture of SGAN framework[24]图2 SGAN网络结构[24]
文献[25]指出不同噪声分布的载体图像对隐写安全性存在显著影响,因此使用适于隐写的载体图像极为重要.SGAN最早实现了基于生成对抗网络的图像隐写,对深度学习在图像隐写中的应用有着重大的意义,利用神经网络学习自然图像的分布特征,从而生成适用于隐写的载体图像.但是由于模型的限制,SGAN中的GAN网络结构难以使生成网络与判别网络的训练达到平衡状态,这造成生成图像的视觉质量不佳,影响了图像隐写的安全性能.
为了提升图像的视觉质量,Shi等人[26]提出SSGAN(secure steganography based on generative adversarial networks)图像隐写方法,保留SGAN的网络模型,修改了生成网络结构[27],生成的载体图像更自然更真实,使隐写分析的准确率下降了18%.

Fig. 3 The architecture of Stego-WGAN framework[28]图3 Stego-WGAN网络结构[28]
2018年王耀杰等人[28]进一步改变了模型结构,提出Stego-WGAN(steganography based on wass-erstein generative adversarial networks)图像隐写方法,图3为该模型的结构框架图.对比图2可以看出,Stego-WGAN与SGAN最重要的不同之处在于,SGAN将载体图像与真实图像一起输入判别网络中,而Stego-WGAN将含密图像与真实图像一起输入判别网络中.这样做的目的在于,使生成的载体图像更适用于隐写嵌入的同时,使生成的载体图像在嵌入秘密信息后依然能呈现真实图像的视觉效果,进一步增加了隐写的安全性.为了直观地反映SGAN,SSGAN,Stego-WGAN 3种网络的隐写效果,表1列举了这3种网络在0.4 bpp(bit per pixel)嵌入率下隐写分析的准确率,数据集为CelebA,bpp表示秘密信息在每个像素中的比特数.可以发现,随着网络结构的优化,隐写分析的准确率在不断下降,但整体而言,隐写的隐蔽性仍有很大的提升空间.表1中的数据来源于文献[26].
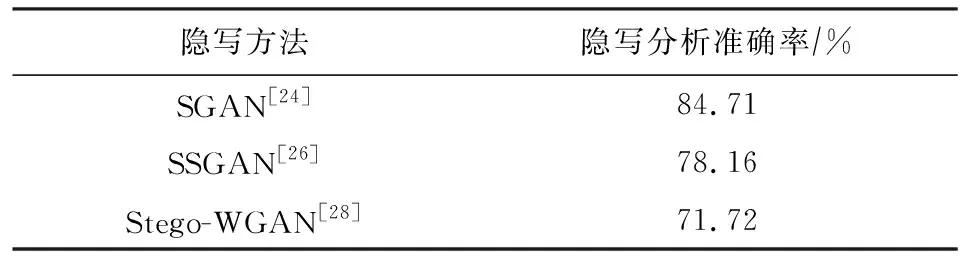
Table 1 Performance Comparison of SGAN,SSGAN,Stego-WGAN Against Steganalysis[26]
基于生成对抗网络生成载体图像的方法都运用了对抗博弈的思想,在基础GAN的基础上加入隐写分析模块,相当于对生成网络的优化加入了一个约束条件,使得生成的图像不仅自然真实而且可以提升抗隐写分析器检测的能力.尽管隐写分析的准确率随着网络的改进在不断下降,但含密载体对隐写分析的抵抗性仍然很差,网络训练不稳定,生成的载体图像的生成痕迹、含密图像的修改痕迹都会被隐写分析器检测.如果要提升该隐写方法的隐蔽性,可以使用特征学习能力更强的网络,获得图像的深层特征,提高图像的真实性.但该类方法对于深度学习在图像隐写领域中应用的意义是毋庸置疑的.
1.2 基于对抗样本的载体图像增强方法
为了增强对隐写分析器的抵抗能力,研究者们引入对抗样本增强载体图像.对抗样本指的是对原始图像做一些微小改动,在人眼看来图像没有变化的情况下,可以对神经网络的判断进行干扰.运用对抗样本的这个特征,将对抗样本引入图像隐写领域,在含密载体上添加微小的改动,使其伪装成自然图像,欺骗隐写分析器.

Fig. 4 The process of cover image enhancement[29]图4 载体图像增强的过程[29]
2018年Zhang等人[29]结合了对抗样本的方法,提出了一种有效抵抗隐写分析的图像隐写方法,使含密图像具有主动欺骗隐写分析器的能力.提出的方法为:在隐藏信息之前,用生成对抗样本的方法对载体图像做增强;在载体图像的基础上添加噪声,模拟信息嵌入,得到含密图像;在隐写分析网络判别时,将含密图像的标签设置为载体图像,根据反向传播时的梯度即可设定对抗噪声值,将对抗噪声添加到原始载体上得到增强的载体图像.对该载体采用传统的自适应隐写算法实现秘密信息的嵌入,若隐写分析网络将含密图像误判为载体图像,则得到了增强的载体图像,否则循环上述操作,继续对载体图像增强.载体图像增强的过程如图4所示.该方法改变了传统的图像隐写模式,化被动为主动,载体图像增强成为对抗样本,使图像嵌入秘密信息之后得到的含密载体仍然可以伪装为载体图像,达到了欺骗隐写分析器的目的.相比于基于生成对抗网络的图像隐写方法,该方法具有更强的安全性,但是每个图像都要经过不同的训练周期得到具有对抗样本性质的载体图像,训练具有复杂性.
2020年Li等人[30]同样也使用了对抗样本增强载体图像的方法,不同于Zhang等人[29]提出的方法,该方法对载体图像划分了区域,在部分图像中隐藏所有的秘密信息,对剩余部分的图像用生成对抗样本的方法进行增强,使整个图像具有欺骗隐写分析的能力.然而,这种方法随着欺骗隐写分析器成功率的提高,图像质量有所下降,由于只有部分图像进行了图像增强,会与另一部分图像在视觉上形成对比,更增加了被隐写分析器识别的风险.根据表2可以观察发现,随着被攻击像素点数量的增加,欺骗隐写分析器的成功率(含密图像被误判为载体图像的比率)在不断上升,用峰值信噪比(peak signal-to-noise ratio, PSNR)衡量图像质量,发现整体的图像质量在不断降低,这增加了含密图像被隐写分析器检测的风险.表2中用于实验的数据集为BOSSbase,数据来源于文献[30].
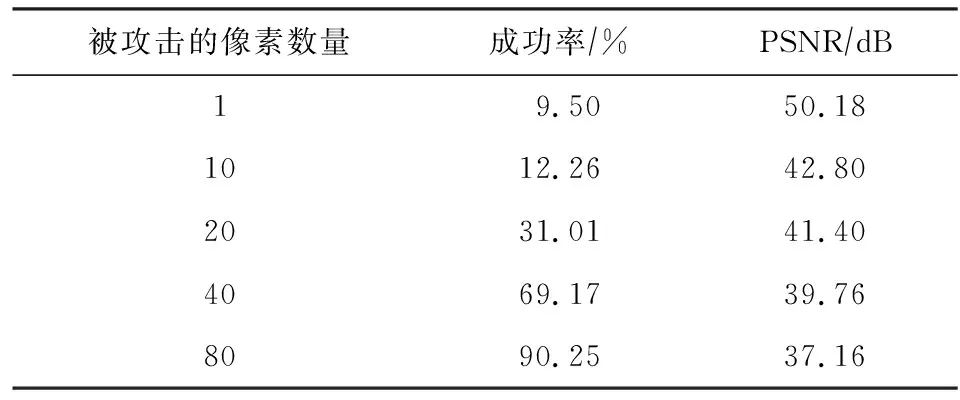
Table 2 Relationship Between Success Rate of DeceptionSteganalysis and PSNR Value[30]
1.3 载体图像获取方法的对比与总结
1.1节和1.2节所述2类方法基于深度学习从载体图像获取的角度,对传统的图像隐写做出了改进.分别借鉴对抗博弈的思想和对抗样本的思想,通过神经网络生成更适于隐写的图像或对已有的载体图像做出修改,达到提升隐写安全性的目的,但这2类方法仍然存在一些问题.表3是基于深度学习的载体图像获取隐写方法与传统图像隐写方法的对比总结,分别从安全容量、隐蔽性、鲁棒性、图像视觉质量、欺骗隐写分析器的方式、泛化性、计算效率、结构复杂度8个方面进行总结.在隐写安全容量方面,将所述方法的安全容量与传统图像隐写的安全容量0.4 bpp进行比较,分为没有提升、略有提升、大大提升3种情况.在隐蔽性方面,本文提到的每一类隐写方法中所有方法与传统内容自适应隐写方法S-UNIWARD(spatial universal wavelet relative distortion)进行对比,以S-UNIWARD隐写分析检错率作为参考值,观察每一个类别中大部分隐写方法的隐写分析检错率,高于参考值,则认为该类隐写方法隐蔽性好;低于参考值,则认为该类隐写方法隐蔽性差;与S-UNIWARD接近,则认为该类隐写方法隐蔽性一般.在鲁棒性方面,由于在真实环境下传输的图像都是经过压缩的,图像质量受损会造成部分信息丢失,影响秘密信息的提取,因此认为大部分图像隐写方法的鲁棒性弱.一些基于深度学习的图像隐写技术在网络训练时模拟了真实环境下图像压缩的过程,提升了图像受损的情况下秘密信息提取的准确度,这类隐写方法的鲁棒性较强.在图像视觉质量方面,使用PSNR作为衡量含密图像质量的指标,一般认为:PSNR值高于40 dB的图像质量好,非常接近原始图像;位于30~40 dB之间的图像质量一般,此时可以察觉图像失真,但失真效果可以接受;位于20~30 dB之间的图像质量差.欺骗隐写分析器的方法分为被动和主动,大部分隐写方法致力于将秘密信息藏得更隐蔽,我们认为这种隐写方法是防守的、被动的;而基于对抗样本的隐写方法通过微小地改动图像使隐写分析器误判,这种隐写方法具有主动攻击性.在隐写方法的泛化性方面,某些基于深度学习的隐写方法在训练时只使用了某个隐写分析器作为判别器,在测试时会对这个隐写分析器具有较强的抵抗作用,此时,观察其他隐写分析器的检测效果,如果该类隐写方法仍有较强的抗隐写分析检测能力,则认为泛化性好,否则认为泛化性能差.在计算效率和结构复杂度方面,综合考虑基于深度学习的隐写方法在构建网络、训练网络等过程中耗费的时间,与传统图像隐写进行对比,由于基于深度学习的图像隐写方法需要耗费大量的训练时间,一般认为基于深度学习的图像隐写方法计算效率低、网络结构复杂.

Table 3 Summary of the Application of Deep Learning inthe Acquisition of Cover Images
根据这8种评价指标,我们对上述2种隐写方法进行如下分析:
基于生成对抗网络的载体图像获取隐写方法将深度学习引入图像隐写领域,对于图像隐写的发展具有重大的意义.但是,由于网络训练不稳定等因素,人眼直接能看出生成的载体图像异常,图像质量差.在相同情况下与S-UNIWARD进行对比,只有Stego-WGAN的隐蔽性优于S-UNIWARD,因此认为该类方法的隐蔽性一般,仍有较大的提升空间.由于在网络训练时,只有个别隐写分析器参与训练,含密图像难以抵抗多种隐写分析器的检测,隐写模型的泛化性较差.由于载体图像质量差、获取载体图像之后仍然使用传统的隐写方法等因素,隐写安全容量没有提升,同时由于前期构建网络结构、训练网络需要耗费一段时间,因此该类方法与传统隐写方法相比,计算效率较低,网络结构复杂.对于该类隐写方法,可以使用更稳定、更轻量级的生成网络模型和多种不同的隐写分析器,在隐蔽性、图像质量、泛化性、计算效率、结构复杂度等方面进一步做出提升.
对抗样本可以使神经网络分类器误判,基于对抗样本的图像隐写模型使载体图像具有主动欺骗目标隐写分析器的能力,提高了隐写分析器的检测错误率,隐写的隐蔽性好.网络结构复杂度与基于生成对抗网络的载体图像获取隐写方法相似,都比传统隐写方法复杂.目前,该类图像隐写方法存在3个主要问题:1)在训练过程中,容易对某种隐写分析器过度适应,使对抗样本具有特异性,但是很可能被其他隐写分析器检测出异常,难以抵抗多种类型隐写分析器的检测,隐写方法的泛化性差;2)随着对抗样本对神经网络欺骗能力的增强,图像的视觉质量受到影响,会出现清晰的图像噪声而被人眼察觉;3)每次隐写前都要对载体图像进行增强,使载体图像具有对抗样本的性质,计算效率低.为了解决第1个问题,一方面可以在训练过程中增加隐写分析器的类型;另一方面增强对抗样本的泛化性;为了解决第2个问题,在生成对抗样本的过程中,只对小部分像素进行修改,减少对图像全局的改动;为了解决第3个问题,可以寻找生成可分离对抗样本的方法,将对抗噪声与图像分离,在不同载体图像结合的同时保持对抗样本的性能,减少隐写过程中的计算效率.
2 基于深度学习的隐写失真设计
对于传统的自适应隐写框架,除了利用深度学习的方法得到更适合嵌入的图像,还可以考虑利用神经网络设计更好的失真函数,使信息嵌入后含密图像的总隐写失真最小,减少由像素修改引发的图像统计异常.从使用生成对抗网络和对抗样本2个不同的角度,深度学习在隐写失真设计中的应用可以分为:利用生成对抗网络自动学习图像失真、利用对抗样本修改已有的失真值.无论是哪种方法,在得到图像失真之后,都利用STC编码方法找到最优的嵌入策略,实现最小嵌入失真情况下修改最少的图像隐写.
2.1 基于GAN的隐写失真自动学习方法
现有的基于生成对抗网络的隐写失真代价设计主要包括ASDL-GAN(automatic steganographic distortion learning using a generative adversarial network)[31],UT-SCA-GAN[32-33]等.在对抗训练中,利用生成网络得到每个像素的嵌入改变概率,使用网络学习或公式推导的方法将嵌入改变概率转化为像素修改图,最终根据像素修改图修改载体图像即可得到含密图像.该类方法的框架如图5所示:

Fig. 5 The basic architecture of automatic steganographic distortion learning using GAN图5 基于生成对抗网络的隐写失真自动学习方法基本框架
2017年Tang等人[31]首次使用生成对抗网络自动学习图像的隐写失真,改变了传统根据先验知识设计隐写失真的方法,在生成网络与隐写分析网络对抗训练的过程中,提高含密图像统计上的不可检测性,因此该隐写模型可以有效抵抗隐写分析器的检测.图6为所提出的ASDL-GAN的网络结构,生成网络的输入是原始载体图像,输出修改概率图,图中每个像素对应的值pij表示的是该像素被修改的可能性,但不确定像素具体的修改方向.为了在神经网络训练过程中模拟信息的嵌入,在像素修改的前提下,默认+1,-1修改的可能性相同,像素值的修改可以表示为

(1)
其中,rij为0~1之间的随机变量,根据rij的随机取值和像素修改概率,确定像素具体的修改方向.
根据这个原则,ASDL-GAN设计了TES(ternary embedding simulator)激活函数,是一个小型的神经网络,网络结构如图6所示.生成网络输出修改概率图,XuNet[34-35]作为判别网络,在对抗训练中不断调整生成网络输出的修改概率值,经过TES网络模拟信息的嵌入得到含密图像,将原始图像与含密图像共同输入判别网络中,根据判别结果优化生成网络.在实际嵌入的过程中,得到修改概率值之后,利用STC编码嵌入秘密信息.
利用生成对抗网络设计隐写失真代价的方法值得进行深入研究和优化,减少了传统隐写失真设计过程中的人为参与,利用生成网络与隐写分析网络的对抗训练,自主学习图像像素的修改可能性,提高含密图像统计上的不可检测性,从而增强对隐写分析器的抵抗能力.但是,该方法与经典的自适应隐写方法S-UNIWARD[6]相比,性能还有一定差距,对隐写分析器的抵抗能力有待提高;另外该网络模型的训练时间较长,远远大于传统自适应隐写模型中失真函数的设计过程,且TES网络需要提前训练,增加了时间开销.

Fig. 6 The architecture of ASDL-GAN framework[31]图6 ASDL-GAN网络结构[31]
为了减少训练的时间,2018年Yang等人[32]使用tanh模拟器作为激活函数来代替ASDL-GAN中的TES激活函数,代替网络模拟信息的嵌入.tanh模拟器在式(1)原则下设计为
mij=-0.5 tanh(λ(pij-2×rij))+
0.5 tanh(λ(pij-2×(1-rij))).
(2)
UT-SCA-GAN与ASDL-GAN最大的不同是:用公式代替网络模拟修改像素的过程,减少了ASDL-GAN中TES网络预训练的时间开销;在判别网络的设计中选择通道,即考虑嵌入改变概率,使学习到的失真代价能够抵御基于通道选择的隐写分析检测;以U-Net这种紧凑网络结构作为生成网络,在捕捉图像细节信息、低频信息方面具有较好的性能.因此,在学习图像像素的修改概率时有更好的表现,进一步提升了网络隐写的隐蔽性,图7为该网络模型.

Fig. 7 The architecture of UT-SCA-GAN framework[32]图7 UT-SCA-GAN网络结构[32]
在使用相同数据集(BOSSbase)训练的情况下,将UT-SCA-GAN与S-UNIWARD,ASDL-GAN相比,对比结果如表4所示,包括了隐写分析器检测的错误率和训练时间(以epoch=1为例).可以发现,无论是0.1 bpp还是0.4 bpp的嵌入量,UT-SCA-GAN的安全性比ASDL-GAN更高,甚至超过了S-UNIWARD的安全性,这得益于UT-SCA-GAN的网络结构,生成网络捕获更细节的图像信息,在判别网络的设计中考虑通道选择,因此利用网络学习的嵌入改变概率值得到的含密图像更能抵抗统计检测.除此之外,由于设计了tanh函数,模型的计算效率得到了提高.表4中数据来源于文献[32-33].

Table 4 Security Performance Comparison of AutomaticSteganographic Distortion Learning Methods Using GAN[32-33]
2.2 基于对抗样本的隐写失真修改方法
2018年Tang等人[36]利用对抗样本来调整隐写失真代价,提出了ADV-EMB(adversarial embedding)模型.该方法的训练目标是选择合适的像素修改方向,在信息嵌入的同时得到具有对抗样本性质的含密图像,使隐写分析器将该含密图像误判为载体图像.首先,输入原始载体图像,此时判别的标签为载体图像,计算反向传播过程中每个像素点对应的梯度值,得到1张梯度图.然后,给定1个已知的失真函数,计算图像的隐写失真,每个像素点都有对应的失真代价.最后,根据梯度图和失真图,以及对抗样本的计算规则,更新每个像素的失真代价.若像素修改方向与梯度的反方向相同,则减小该方向的失真代价,若像素修改方向与梯度的反方向不一致,则增大该方向的失真代价:

(3)
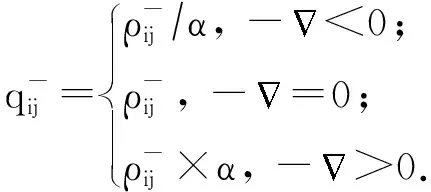
(4)

根据调整后的隐写失真代价,采用传统的自适应隐写框架实现秘密信息的嵌入,这种对抗嵌入的方法很大程度上提高了隐写的安全性.根据自适应隐写失真找到嵌入的位置,接着利用对抗样本的生成方法,更新这些像素的失真代价,在没有额外修改像素的情况下,使含密图像具有对抗样本的特性,从2个方面增强了抗隐写分析检测的能力.
使用BOSSbase数据集训练,针对于空域和JPEG域,该方法与S-UNIWARD,J-UNIWARD(jpeg universal wavelet relative distortion)在隐写分析器检测错误率方面的对比如表5,6所示.表5,6中的数据表示隐写分析器(XuNet)的检测错误率.可以发现,ADV-EMB方法提高了隐写分析的检测错误率,图像隐写的隐蔽性更高.
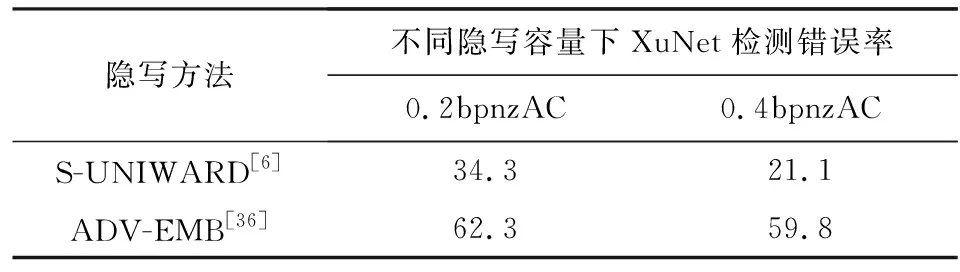
Table 5 Security Performance Comparison of ADV-EMB,S-UNIWARD Against Steganalysis[36]

Table 6 Security Performance Comparison of ADV-EMB,J-UNIWARD Against Steganalysis[36]
传统的自适应图像隐写方法在确定需要修改的像素点位置之后,并不会指定像素修改的方向.Tang等人[36]提出的方法在此基础上,根据对抗样本的梯度方向对像素修改的方向进行了建议,增大了其中1个方向上像素修改的概率,使其成为对抗样本.该方法本身并不会对图像造成过多的干扰,且该方法同时适用于空域和JPEG域的隐写失真代价更新.但在对抗样本的生成过程中,图像像素的全局平衡遭到破坏,这会引起统计异常,也会出现对某种隐写分析方法过度适应的情况,在未来的研究中这些问题都是需要解决的.
2.3 隐写失真设计方法的对比与总结
2.1节和2.2节所述2类方法都从深度学习的角度对隐写失真的计算有了新的定义,提高了隐写分析的检测错误率.深度学习在失真函数设计中的应用总结为表7,从安全容量、隐蔽性、鲁棒性、图像视觉质量、隐写失真的设计是否考虑统计上的不可检测性、欺骗隐写分析器的方式、泛化性、隐写适用的域、计算效率这9个方面进行总结.其中,在隐写失真的设计是否考虑统计上的不可检测性上,如果设计过程是基于先验知识手工设计的,则没有考虑统计上的不可检测性;如果在设计过程中,加入了对图像统计特征的衡量,则认为考虑了统计上的不可检测性.

Table 7 Summary of the Application of Deep Learningin Distortion Designing
根据这9种评价指标,我们对上述2种隐写方法进行分析:
1) 基于生成对抗网络的方法抛弃了传统的根据先验知识设计失真的方法,在学习隐写代价的过程中,根据隐写分析器的检测结果,对抗地调整每个像素的改变概率,在此基础上使用传统的隐写方法实现秘密信息的嵌入.由于设计隐写失真时考虑了统计的不可检测性,因此隐蔽性更高,同时可以保证含密图像与传统内容自适应隐写方法得到的含密图像具有类似的视觉质量.但是隐写安全性的提升以复杂的网络结构和长时间的训练过程为代价,网络学习合理的像素改变概率花费了大量的时间.在训练时,虽然只有单个隐写分析器参与训练,但是在传统隐写分析器检测时仍然表现出较好的抵抗性,泛化性能好.在训练的过程中,可以使用多种隐写分析器集成的方法,进一步提高抵抗多种隐写分析器的能力.除此之外,由于训练的网络较为庞大,在实际使用过程中会花费较长的时间,因此,可以使用该网络的蒸馏模型或设计轻量级的网络计算隐写失真,提高效率.
2) 基于对抗样本的隐写失真修改方法适用于空域和JPEG域任何已有的自适应隐写框架.根据传统的方法计算得到像素失真,ADV-EMB就可以根据对抗样本的梯度方向更新失真,使得含密图像具有对抗样本的性质,主动欺骗隐写分析器,提升了隐写的隐蔽性.由于生成对抗样本的过程并没有对图像做额外扰动,图像上不会出现对抗噪声,因此不会对图像视觉质量产生影响.与基于生成对抗网络的隐写失真设计方法类似,在训练的过程中使用单个隐写分析器,对抗样本具有特异性,容易对某种隐写分析器形成过度适应,模型的泛化性能差,可以在训练时增加隐写分析器的种类解决该问题.由于在实际的隐写过程中需要对每张载体图像的隐写失真进行修改,因此计算效率低.另外,由于对抗样本的生成过程破坏了像素修改的随机性,因此含密图像可能会引起图像统计特性上的异常.
3 基于深度学习的含密图像生成
在传统的隐写方法中,自适应隐写将信息隐藏在图像内容复杂的区域或边缘区域,隐写分析难以发现这些区域的异常.通过设计失真函数,为每个像素分配嵌入成本,减少信息嵌入引起的图像失真;利用编码方法减少信息嵌入时像素的改动,STC编码可以做到在给定隐写容量和像素嵌入成本的基础上,用最少的改动逼近失真函数的最小值,这是传统的隐写中含密图像生成最主要的方式.在深度学习中,编码网络的作用类似于传统的编码算法,可以直接实现文本与图片、图片与图片的结合,因此将编码网络引入图像隐写,隐写方与解密方可以在没有图像隐写先验知识的情况下完成信息的隐藏与提取,同时,该方法实现了更大容量的隐写.本节从以图藏文本、以图藏图2个方面分析基于深度学习的含密图像生成方法,相比于其他图像隐写方法,隐写内容更丰富,隐写容量更大,该类隐写方法基本的网络模型框架如图8所示:

Fig. 8 The basic architecture of image steganographybased on encoder-decoder network图8 基于编码-解码网络的图像隐写基本框架
3.1 以图藏文本含密图像生成方法
2017年Hayes等人[37]提出了以图藏文本的图像隐写框架HayesGAN,网络结构如图9所示,第1次用编码网络实现图片隐藏秘密信息.秘密信息与载体图像共同输入给编码网络中,得到含密图像;隐写分析网络,也相当于判别网络,对生成的含密图像和原始载体图像做分析检测;信息的接收方通过解码网络可以得到解密信息.损失函数:
L=α×LCC+β×LSS+γ×LG.
(5)
通过欧氏距离LCC,LSS衡量载体图像与含密图像、秘密信息与解密信息之间的损失,保证载体图像与含密图像的相似性、秘密信息与解密信息的一致性,通过编码网络与隐写分析网络的对抗损失LG保证图像隐写的隐蔽性.α,β,γ为权重参数.

Fig. 9 The architecture of HayesGAN framework[37]图9 HayesGAN网络结构[37]
在该网络结构中,秘密信息提取的准确率是衡量该类网络性能的重要指标,神经网络提取秘密信息不同于传统的信息嵌入与提取,网络的学习过程具有不可解释性,信息提取的过程不完全可控,如何设计提取网络的结构,控制训练过程以提高秘密信息恢复的准确率是修改网络结构的关键.在实际的图像传输过程中,图像往往会因为几何攻击或通信压缩而受损,如果含密图像在传输过程中受到了攻击,则信息的准确提取会更加困难.因此如何保证生成的含密图像有效抵抗隐写分析检测,同时保证秘密信息提取的准确率,是该类图像隐写方法面临的重大挑战.
为了增加隐写的鲁棒性,2018年Zhu等人[38]提出HiDDeN(hiding data with deep networks)图像隐写方式,在网络训练的过程中加入了噪声层,模拟真实情景下含密图像传输过程中所遇到的噪声攻击、压缩等情况,将攻击后的图像放入解码网络中提取秘密信息.该网络考虑到含密图像的真实性、秘密信息提取的准确性、隐写的隐蔽性,进一步增强了隐写的鲁棒性,为后续隐写方法提升鲁棒性提供了思路.
为进一步增大隐写容量,2019年Zhang等人[39]提出了SteganoGAN(steganography with generative adversarial networks)隐写模型,将判别网络改为评分网络,评价含密图像的真实性,同时修改了生成网络的网络结构,最终实现了4.4 bpp的大容量图像隐写.与前2种网络模型的隐写容量对比如表8所示,该网络还可以有效抵抗YeNet[40]的隐写分析检测.表8中数据来源于文献[37-39].
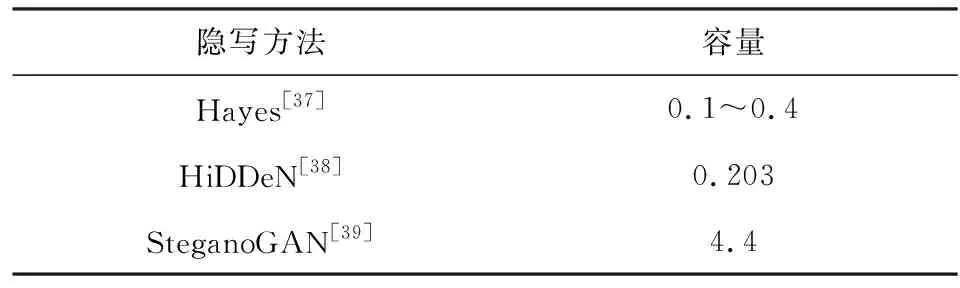
Table 8 Steganography Capacity Comparison of Stego Image Generation Methods for Hiding Text Within Images[37-39]
3.2 以图藏图含密图像生成方法
2017年,Baluja[41]首次提出以图藏图的隐写模型,实现了在彩色图像中隐藏彩色图像.所提出的网络模型包括预处理网络、编码网络和解码网络.预处理网络将秘密图像变换为载体图像的大小,将基于色彩的像素转化为利于编码的特征;秘密图像与载体图像经过编码网络得到含密图像,在视觉上与载体图像没有差异;解码网络将从含密图像中提取秘密图像,网络结构如图10所示.在训练时,通过控制载体图像与含密图像的距离,保证二者的相似性,减少秘密图像嵌入引起的图像变化;通过控制秘密图像与解密图像的距离,保证图像重构的准确性.

Fig. 10 The architecture of the hiding images within images proposed by Baluja[41]图10 Baluja提出的以图藏图网络结构[41]

Fig. 11 The architecture of ISGAN framework[46]图11 ISGAN模型[46]
Baluja[41]提出的网络模型中,含密图像与重构的秘密图像视觉质量较差,图像的平滑区域存在许多噪声,会引起数据统计异常且容易被人眼察觉.为了解决上述问题,2018年Wu等人[42]提出了StegNet(steganography with deep convolutional network)的网络模型,修改了损失函数,Duan等人[43]修改了编码网络的网络结构,2种方法都有效改善了图像的质量.Wu等人[42]通过设计新的损失函数,最小化加权损失,控制含密图像中的噪声,使这些噪声均匀分布在图像中,而不是集中在容易发现的平滑区域:
其中,载体图像与含密图像的L1范数LCC和方差损失Var(LCC)、秘密图像与解密图像的L1范数LSS和方差损失Var(LSS),保证载体与含密图像、秘密与解密图像在图像高度、宽度等多方面的相似性,这使噪声分布在图像的整个区域内.
U-Net[44]作为编码网络的网络结构,借助了U-Net网络自身的优势,上采样与下采样的网络结构有连接操作,保存了图像浅层与深层的特征,因此重构的解密图像与原始秘密图像具有较高的相似性,且图像质量相较于Baluja的方法更佳.
除了彩图藏彩图,还有彩图藏灰度图的图像隐写方法[45-46],值得注意的是2019年Zhang等人[46]所提出的ISGAN(invisible steganography via generative adversarial networks)模型.将彩色载体图像分解为3通道UVY,其中通道UV包含图像的色度信号,Y通道包含图像的亮度信号,利用人眼对亮度信息不敏感的特性,将代表秘密图像的灰度图像与载体图像的Y通道进行通道堆叠,通过编码网络得到Y通道的含密图像,与UV通道结合得到彩色的含密图像.如果要提取秘密图像,则先将含密图像的Y通道剥离,然后通过解码网络得到秘密图像,图11为该网络模型.通过这种方法,载体图像除了亮度信息有所损害之外,保留了原图的色彩信息,这增强了秘密图像的隐蔽性.
以ImageNet[47]为数据集,对上述5种模型的隐写效果进行总结,含密图像与载体图像的峰值信噪比、结构相似度、解密图像与秘密图像的峰值信噪比、结构相似度,结果如表9所示,表9中的数据来源于文献[41-46].基于编码-解码网络的以图藏图含密图像生成方法在隐藏容量方面都有巨大的提升,但是在嵌入秘密信息后,图像的PSNR值都有所下降,图像质量有所影响,但秘密图像的恢复度较高,且与原始秘密图像保持较高的相似性.
根据表9可以看出,无论是彩图藏彩图还是彩图藏灰图,隐写的容量都得到了大幅度提升.但该类图像隐写模型都面临2个问题:1)嵌入秘密图像后,图像的视觉质量受到影响,可能引起隐写分析者的注意;2)在传输过程中,由于信道压缩等因素含密图像一定会受损,导致秘密信息丢失,这会使秘密图像的准确恢复面临更大的困难.
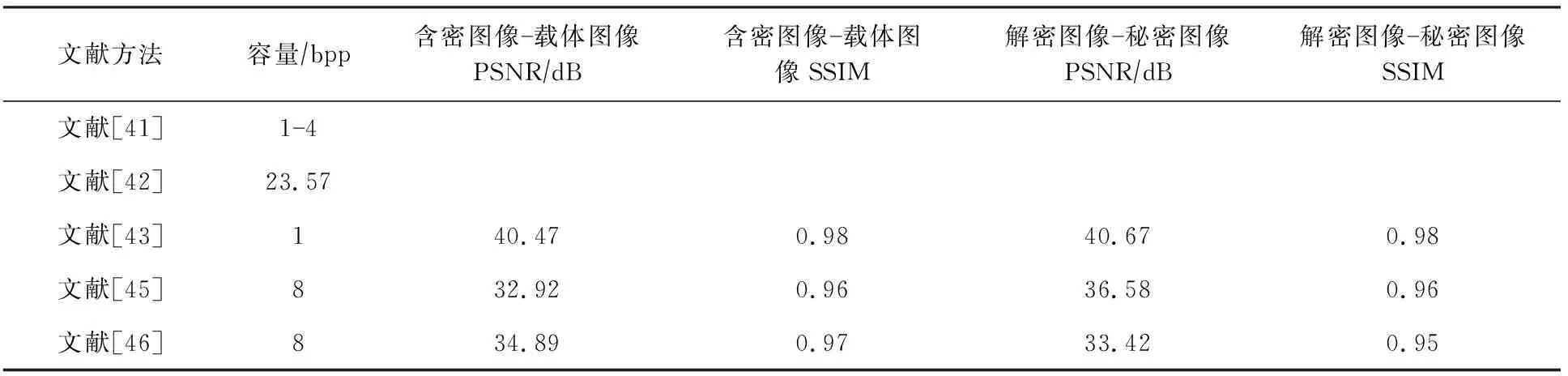
Table 9 Performance Comparison of Stego Image Generation Methods for Hiding Images Within Images[41-43,45-46]表9 以图藏图含密图像生成方法的性能对比[41-43,45-46]
3.3 含密图像生成方法的对比与总结
基于编码-解码网络的图像隐写颠覆了传统的图像隐写模型,不需要手工设计具体的嵌入方法,也不需要设计失真函数来衡量修改像素引起的失真,是图像隐写领域的创新.依靠网络强大的学习能力,实现秘密信息与图像的结合以及秘密信息的再次提取,大大降低了人为参与.将上述2种基于编码-解码网络的含密图像生成方法的主要特点总结至表10,从隐写安全容量、隐蔽性、鲁棒性、图像视觉质量、是否需要先验知识、计算效率、结构复杂度这7个方面进行总结.其中,是否需要先验知识从隐写者是否需要掌握隐写知识的角度进行判断.使用基于编码-解码网络图像隐写方法的隐写者可以没有任何图像隐写的先验知识,拥有编码网络与解码网络就可以实现秘密信息的嵌入与提取.

Table 10 Summary of Stego Image Generation Methods表10 含密图像生成方法总结
以图藏文本的含密图像生成方法将隐写的安全容量从0.4 bpp提升至4.4 bpp,与传统内容自适应的隐写方法相比,相同隐写分析检测率下隐写容量更高,相对地,隐写的隐蔽性更高.以图藏图的含密图像生成方法将秘密图像作为秘密信息嵌入载体图像中,大大提升了隐写的容量,同时保持了与传统隐写方法相近的隐蔽性.但与传统隐写方法相比,构建的信息嵌入与提取网络较为复杂,构建合适的网络也占用了一定的时间开销,为了提高秘密信息的恢复准确率和图像的视觉质量,网络训练的时间一般较长,隐写方法整体的效率较低.这2种基于编码-解码网络的含密图像生成方法存在2个共同的问题:1)在藏入信息之后,图像的亮度、色调等都会发生较大的变化,影响视觉质量;2)由于信息的嵌入与提取都依靠网络,过程不可逆,秘密信息提取的准确率难以保证,损失使信息的准确提取更加困难,隐写方法的鲁棒性弱.对于第1个问题,可以调整网络的损失函数,加入图像质量评价指标,使信息与图像编码后仍保持良好的图像质量;对于第2个问题,文献[38]给出了很好的解决方案,在秘密信息提取之前添加噪声层,模拟图像传播过程中信息受损的情况,以此提升含密图像的鲁棒性,提高信息恢复的准确率.
4 无载体图像隐写方法
无论是基于深度学习的载体图像获取、隐写失真设计、含密图像生成都借助网络强大的学习能力实现了图像隐写,进一步减少了隐写过程中的人为参与.但由于在信息嵌入的过程中都修改了载体图像,图像的视觉质量或统计特性不可避免地受到了影响,使隐写分析器有迹可循.无载体图像隐写针对载体修改隐写定义了一种新型的隐写模式,由于不存在对图像修改的过程,具有天然的抗隐写分析能力.无载体图像隐写并不是完全不需要载体,而是根据秘密消息选择载体或者生成载体,在图像隐写的过程中,没有像素修改的操作.可以将现有的无载体隐写分成2类[49]:基于载体选择的无载体图像隐写、基于载体合成的无载体图像隐写,后者根据载体合成方法的不同又可以分成:基于图像基元合成载体的无载体图像隐写和基于生成对抗网络合成载体的无载体图像隐写.无载体图像隐写在与深度学习技术结合之后有了更广阔的发展前景.
4.1 基于载体选择的无载体图像隐写方法
基于载体选择的无载体隐写方法通过构建信息与图像之间的映射关系,传递秘密信息前根据映射关系在图像库中进行搜索,传递1张或多张图片,信息接收方根据相同的映射表还原秘密信息.2016年周志立等人[50]提出了一种基于图像词袋模型(bag-of-words, BOW)[51]的无载体图像隐写方法,图12为提出的隐写框架图.创建图像库,使用BOW模型提取图像中的视觉关键词,并构建词汇的单词表,然后构建字典中的词和国标一、二级字库中的字与视觉关键词的映射关系,在进行秘密通信时,根据映射表找出与传递字段对应的视觉关键词,从图像库中挑选含有该视觉关键词的图,将这些图作为含密图像进行传递.实验表明,该方法可以有效实现无载体图像隐写,并且可以较好地抵抗现有隐写分析算法的检测.但是从隐写容量角度分析,该方法的隐写容量远远小于传统的隐写方法,由于映射关系是该方法中传递秘密信息的关键,因此扩大隐写容量的方式较为局限,不能有效实现较大容量的信息隐藏.

Fig. 12 The architecture of coverless image steganography based on bag-of-words of image[50]图12 基于图像bag-of-words模型的隐写框架图[50]
文献[52-54]在1张图像中的多个子图像中隐藏秘密信息.文献[52]提出基于鲁棒图像散列的无载体图像隐写,分别计算9个子图中的尺度不变特征变换点(scale-invariant feature transform, SIFT),选取每个子图中特征点出现最多的方向与长度为2的比特串形成映射.SIFT特征点满足空间内位置、尺度、旋转的不变性,因此保证了秘密信息再次提取的准确性,且可以有效抵抗隐写分析的检测,唯一的不足是隐写容量较小,1张图只能传递18 b信息.
2018年Cao等人[53]对该方法做出了改进,将0~255的像素取值划分为16个区间,与长度为4的比特串构建映射关系.将图片分为9个子图,计算每个子图的平均像素值,对照映射表,得到秘密消息.因此,1张图片的隐写容量为36 b,此方法的隐写容量是文献[52]中容量的2倍,同时也具有鲁棒性且能抵抗隐写分析的检测.
4.2 基于图像基元合成载体的无载体图像隐写方法
2009年Otori等人[55]最早提出在纹理合成过程中嵌入秘密信息的方法.在小纹理图像中选择若干像素点,通过局部二值模式(local binary patterns, LBP)构建像素点与二进制数据的映射关系,该方法属于基于像素的纹理合成方法,虽然隐写的安全性有所提高,但是隐写容量小、提取误码率较高.2015年Wu等人[56]提出基于块的纹理合成方法,提高了隐写容量.但是Zhou等人[57]在文中指出该方法存在安全漏洞,可以根据含密图像中块与块之间的关系重建源纹理图案,进而模拟含密图像的生成过程,恢复出秘密信息.
Xu等人[58]模仿计算机生成真实纹理的过程,将秘密文字或者图案绘制在白纸上,通过一系列可逆的变形公式,使含密图像旋转、平移,最终达到真实纹理的效果,如果要恢复秘密消息,只需要依次进行公式的逆变换操作即可.该方法只适用于具有含义的图案、文字等,并不适用于二进制数.2016年潘琳等人[59]又对此方法进行了改进,构建形状、颜色等图形特征与二进制数之间的映射关系,在白纸上绘制形状和颜色,接着使用可逆变形公式得到纹理图像,为二进制数据也量身定制了秘密通信的方式,同时该方法达到了较高的隐写容量.
2019年Li等人[60]提出了基于指纹构造的信息隐藏方法,指纹构造包含2个阶段:螺旋相位合成与连续相位合成,该方法在合成螺旋相位时将秘密信息映射在指纹的细节信息中,具体表现为指纹的脊尾和分叉,基于指纹构造的隐写框架如图13所示.合成的指纹图像鲁棒性高、隐蔽性好,但是指纹图像只能传递短小的信息,如加密解密密钥,不能满足较大的隐写容量.

Fig. 13 Architecture of coverless image steganographybased on fingerprint construction[60]图13 基于指纹构造的无载体图像隐写框架[60]
与传统隐写方式相比,基于图像基元合成载体的无载体图像隐写方法隐藏容量较小,虽然提高了隐蔽性,可以有效抵抗隐写分析的检测,但是每次传递的信息容量较小,如果传递的信息较多,需要生成多张含密图像,这增加了被隐写分析者检测的风险.
4.3 基于GAN合成载体的无载体图像隐写方法
由于GAN具有强大的图像生成能力,研究者们开始研究基于GAN的无载体图像隐写.利用生成对抗网络模型本身的特点,将秘密信息的映射融入图像生成的某个步骤中,如图像标签的设定、输入噪声的获取,一旦图像生成,即可将图像作为含密图像进行传递.在这个过程中,只存在图像是否真实的问题,不存在图像是否含密的判断问题,巧妙地抵抗了隐写分析的检测.
2018年Hu等人[61]提出了一种基于深度卷积生成对抗网络(deep convolutional generative adversarial networks, DCGAN)[62]的无载体图像隐写方法,将秘密信息映射为噪声向量,用DCGAN和卷积神经网络(convolutional neural network, CNN)训练生成网络和提取网络,生成无异于真实图像的含密图像.和现有的基于图像基元合成载体的无载体图像隐写方法相比,隐写容量得到了很大的提升,图14为该隐写模型.但是在该方法中,尽管噪声向量由秘密信息映射而来,其本质仍然是随机无规律的,网络难以稳定地恢复噪声向量,因此秘密信息不能准确重构.
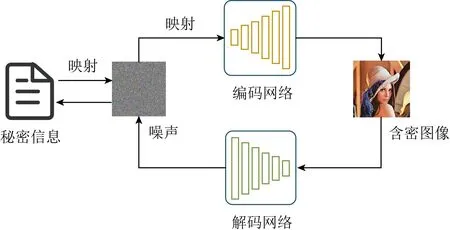
Fig. 14 Architecture of coverless image steganographybased on DCGAN[61]图14 基于DCGAN的无载体图像隐写框架[61]

Fig. 15 Architecture of coverless image steganography based on O-GAN[63]图15 基于正交GAN的无载体图像隐写框架[63]
2019年朱翌明等人[63]在此基础上提出基于正交生成对抗网络(orthogonal generative adversarial networks, O-GAN)[64]的无载体图像隐写方法,在目标函数中加入约束条件,使得模型训练更加稳定,秘密信息的提取更加稳定.图15为所提出的基于O-GAN的无载体图像隐写框架,按文献[61]中的映射规则将秘密消息映射为-1~1之间的噪声,输入生成网络中得到含密图像,将含密图像输入提取网络,提取特征码向量,根据约束条件,该向量与输入噪声有较强的相关性,最后经过U-Net[44]将特征码转化为噪声,根据映射关系实现秘密消息再次提取.基于O-GAN的图像隐写方法对Hu等人[61]提出的方法做了有效的优化,对含密图像的特征添加约束,建立了噪声向量与特征之间的内在联系,使网络模型训练更加稳定,提高了秘密信息提取的稳定性.
文献[61,63]都建立了噪声与秘密信息的映射关系,除此之外还要建立图像标签与秘密信息的映射.文献[65]提出了一种基于辅助分类生成对抗网络(auxiliary classifier generative adversarial networks, ACGAN)[66]的无载体图像隐写方法,建立秘密信息与图像类别标签的映射关系.类别标签和噪声作为ACGAN网络的输入部分,生成含密图像,提取秘密信息时,通过ACGAN的判别网络提取图像的类别标签,根据映射关系实现秘密信息的恢复.但是由于类别标签数量有限,该方法的隐藏容量仍然较低.
4.4 无载体图像隐写方法的对比与总结
将无载体图像隐写方法在隐写容量、隐蔽性、秘密恢复准确率的对比总结至表11.无载体图像隐写没有像素痕迹,隐写的隐蔽性强,且可以抵抗隐写分析的检测,大部分无载体图像隐写方法信息恢复的准确率高.主要缺点是隐写容量特别低,难以与传统的图像隐写容量或基于深度学习的图像隐写容量相比较,无论是载体选择、图像基元合成还是基于生成对抗网络的无载体隐写,隐写容量最多只能达到10-3数量级,表11中列出了每种无载体隐写方法的隐写容量.因此,传递的信息有限,如果要传递大容量的信息,需要传递较多的图片,这会降低隐写的安全性.由此看来,在无载体图像隐写中,尚未出现可行的方法能够在隐写容量上实现突破性进展,即使是基于生成对抗网络合成载体的方法也难以在隐写容量和信息提取准确率二者上同时取得良好的性能.总体而言,隐写的隐蔽性好,信息恢复的准确率较高,但是隐写容量较低,难以达到基于修改的图像隐写的容量.

Table 11 Comparison and Summary of Coverless Image Steganography Methods[50-61]表11 无载体图像隐写方法对比与总结[50-61]
5 总 结
本文从基于深度学习的图像隐写和无载体图像隐写2个方面对近期的图像隐写方法进行了分析与总结.基于深度学习的图像隐写方法大部分都应用了生成对抗网络中对抗博弈的思想,在隐写与隐写分析对抗的过程中提高隐写隐蔽性.除了对抗博弈,另一类隐写方法借鉴了对抗样本的思想,使含密图像具有对抗样本的性质,在图像上添加微小的扰动达到使隐写分析器误分类的目的.事实表明:基于深度学习的图像隐写技术在不断取得突破,并且仍有较大的发展空间.区别于通过修改载体实现信息隐藏的图像隐写方法,无载体图像隐写通过载体选择、载体合成等方式实现信息隐藏,该类方法最大的特点是隐写隐蔽性高,但隐写容量低.本文从4个方面对基于深度学习的图像隐写和无载体图像隐写进行总结,并将不同类型隐写方法的优缺点归纳如表12所示.
1) 基于深度学习的载体图像获取.载体图像的获取可以分为利用生成对抗网络生成适合嵌入的载体图像和利用生成对抗样本的方法增强载体图像,在获得载体图像之后,使用传统的图像隐写方法进行信息隐藏.由于生成图像的质量不佳,基于生成对抗网络生成载体图像的隐写方法不能有效抵抗隐写分析的检测,该类方法提出的意义在于将深度学习引入图像隐写领域,为图像隐写方法开拓了新的研究方向.基于对抗样本增强载体图像的隐写方法,使含密图像具有对抗样本的性能,可以主动欺骗隐写分析器.虽然隐写的安全性得到了一定的提升,但图像的视觉质量会随着对抗样本性能的提升而下降,且可能对参与训练的某种隐写分析器具有较强的抵抗作用,产生过度适应的效果.

Table 12 Comparison and Summary of Different Types of Image Steganography Methods表12 不同类型隐写方法的比较与总结
2) 基于深度学习的隐写失真设计.使用传统的最小失真隐写框架,但隐写失真的设计由网络自主学习.基于生成对抗网络的隐写失真设计方法相较于传统的失真函数设计已经逐渐展现出优势,改变了根据先验知识设计隐写失真的方法,根据统计上的不可检测性,在生成网络与隐写分析器的对抗博弈中,得到每个像素的嵌入改变概率,主要的缺点在于网络训练时间开销较大.基于对抗样本的隐写失真代价设计方法,巧妙地将对抗样本引入到传统的失真设计中,可以应用于空域与JPEG域任意的失真函数设计中.
3) 基于深度学习的含密图像生成.摒弃了传统的隐写框架,由神经网络直接生成含密图像.可以认为该类方法取代了传统的编码方式,通过神经网络中的编码-解码网络实现信息的嵌入与提取,该类方法可以实现大容量的图像隐写.但在这类图像隐写中,隐写的隐蔽性常常受图像质量影响,尤其在以图藏图的含密图像生成方法中,在载体图像中隐藏秘密图像的过程会使图像亮度、色调等多方面出现异常变化,容易被人眼检测.另一方面,含密图像在传输过程中会受到信道压缩和噪声攻击,秘密信息的准确提取成为一大挑战.
可以发现,在基于深度学习的图像隐写中,图像质量与隐写隐蔽性密切相关,直接影响图像抗隐写分析检测的能力.在对抗样本应用于图像隐写的方法中,除了要考虑图像质量,还需要考虑该方法生成的含密图像是否可以抵抗多类隐写分析和经过对抗样本训练的隐写分析器的检测.
4) 无载体图像隐写.通过载体选择和载体合成的方法实现信息隐藏,对隐写分析具有较强的抵抗能力.存在的最主要的问题是隐写容量远远低于基于图像修改的隐写方法的容量.基于生成对抗网络的无载体图像隐写除了需要提高隐写容量之外,还需要提高信息提取的准确率.
6 未来展望
深度学习的发展为图像隐写领域带来了巨大变革,同时也使之面临更多技术上的挑战:1)无论是基于生成对抗网络还是基于对抗样本,生成的含密图像往往会因为视觉质量不佳而引起隐写分析者的注意,甚至难以抵抗人眼检测,图像质量与隐写隐蔽性已经产生了密不可分的关联性;2)对抗样本已经展现出抵抗基于深度学习的隐写分析器的优势,但是面对多种类型的隐写分析器和受过对抗样本训练的隐写分析器,对抗样本的泛化性还有待提高,需要让含密图像在不损失图像视觉质量的同时对多种隐写分析器具有主动欺骗和抵抗分析的能力;3)在利用神经网络提取秘密信息的隐写模型中,需要考虑含密图像的鲁棒性,因为在图像传输过程中,难免会受到噪声攻击与信道压缩,在这种情况下,保证信息恢复的准确率是鲁棒隐写的一大难题.针对这3个挑战,本文对图像隐写的发展前景做出4个方面的展望:
1) 生成高视觉质量的含密图像.在网络训练的过程中,应用人类视觉模型对含密图像的视觉质量进行评估与约束,从提高含密图像视觉质量的角度增强隐写的隐蔽性.在具有对抗样本性质的含密图像生成过程中,使用迭代攻击等方法减少对原图的扰动.由于基于对抗样本的隐写失真设计方法在生成对抗样本时对图像的修改相对较小,且能达到主动欺骗隐写分析的目的,因此,这种类型的高视觉质量含密图像的生成方法值得继续研究与学习.在对含密图像进行隐写分析的过程中,结合图像取证的方法评估含密图像,在保证图像视觉质量的同时减少图像修改的痕迹,增强图像隐写的隐蔽性.
2) 生成强泛化性的对抗式含密图像.为避免出现对某种隐写分析器产生过度适应的情况,在训练与测试的过程中,使用多种隐写分析器对含密图像进行分析,另外可以使用经过对抗样本数据训练的隐写分析器对对抗式含密图像进行判别,以此增强含密图像主动欺骗多种隐写分析器的能力.
3) 提出高鲁棒性隐写网络.在图像传输的过程中,信道压缩、噪声攻击无可避免,为了提高隐写的鲁棒性和信息恢复的准确性,在网络训练时加入约束条件,建立秘密图像、含密图像与重构图像之间的相关性.除此之外,在训练时通过加入噪声层对含密图像进行噪声攻击,使解码网络根据约束条件和对抗训练提高信息恢复的准确率,增强图像隐写的鲁棒性.
4) 设计轻量级隐写网络.随着隐写网络深度和复杂度的不断增加,网络训练的时间消耗在不断增加,为了提高网络使用的灵活性,在实际隐写的过程中,使用网络的蒸馏模型代替原模型,简化网络层数和网络参数,提高隐写的效率.
综上,深度学习为图像隐写方法提供了新的隐写理念与技术,但在提高隐写的隐蔽性、鲁棒性、安全容量、计算效率等方面仍然存在很多问题亟待解决,努力开展基于深度学习的图像隐写研究对网络空间中信息的安全传输具有重要意义.
猜你喜欢
华人时刊(2022年9期)2022-09-06
小哥白尼(军事科学)(2022年2期)2022-05-25
三悦文摘·教育学刊(2021年52期)2021-04-27
华人时刊(2020年15期)2020-12-14
红领巾·萌芽(2019年8期)2019-08-27
人大建设(2018年6期)2018-08-16
小溪流(画刊)(2016年11期)2017-01-05
CHIP新电脑(2016年3期)2016-03-10
作文与考试·小学低年级版(2015年22期)2015-12-07
小学科学(2015年11期)2015-12-01
