
面向高性能图计算的高效高层次综合方法
2021-04-01 01:18:06汤嘉武廖小飞
计算机研究与发展 2021年3期
汤嘉武 郑 龙 廖小飞 金 海
(华中科技大学计算机科学与技术学院 武汉 430074) (大数据技术与系统国家地方联合工程研究中心(华中科技大学) 武汉 430074) (服务计算技术与系统教育部重点实验室(华中科技大学) 武汉 430074) (集群与网格计算湖北省重点实验室(华中科技大学) 武汉 430074)
(jiawut@hust.edu.cn)
最近10年来随着生物信息网络、社交网络、网页图等大数据分析问题的出现,图应用变得越来越重要,图是大数据关联属性的最佳表达方式,图计算则是基于图模式进行巨量、稀疏、超维关联的挖掘和分析过程,当前大数据的机器学习和深度学习都依赖于图计算,图计算已经成为大数据处理的主流模式之一.
图计算的复杂特性对当前硬件提出了新的挑战,CPU和面向吞吐量的架构都有各自的局限性[1].对于通用的CPU,大量研究表明,即使对于最优的图算法实现其指令级并行度仍然异常的低,绝大多数低于1.0,许多低于0.5[2].对于面向吞吐量的架构,比如GPU,按照单指令多数据(single-instruction multiple-data, SIMD)的方式执行,通过调度数以千计的线程来掩盖耗时的内存访问[3],虽然性能较高但是功耗巨大,图数据的幂律分布和图算法的不规则性天然对SIMD模式不友好,存在负载不均和低带宽利用率问题,研究表明只有低于16%的时间GPU得到完全利用,主要性能瓶颈在于访存单元在流水线中的停滞[4].
对于可重构硬件,例如现场可编程门阵列(field-programmable gate array, FPGA),由于其低功耗和可重构特性得到很大关注,研究人员在FPGA上针对图计算设计了诸多高效的处理架构[5-8],体现了FPGA在图计算领域的巨大潜力,而即使对于专业的研究人员,编写完整的图计算硬件代码也是十分耗时的事情,一方面是图计算自身的复杂性,另一方面是硬件编程过高的壁垒,表面上算法优化和架构设计是工作核心,实际上硬件语言的仿真测试、调试以及上板所必须的其他工作占了大量时间,因特尔公司指出1名资深的硬件工程师实现1个完整的最短路径算法也需要几个月的时间.
为了使FPGA开发人员从繁琐的硬件细节中解脱出来,专心于算法本身和架构的设计,许多HLS系统被提出,大部分都采用CC++作为输入并输出寄存器传输级(register-transfer level, RTL)代码,这极大地降低了硬件编程门槛并缩短了开发时间,HLS系统还提供了各种优化方法使得开发人员可以从高级语言层面对硬件结构进行优化,部分还提供了可视化的视图方便对每个时钟周期的电路行为进行分析,进一步提高了生成RTL的性能,但是目前与手动最优的RTL在面积和性能等多个方面有较大差距,特别地,针对图计算这种不规则的复杂关联应用,这一些现象尤为严重,这是由于HLS系统自身的结构特性造成的,具体而言:
1) 采用C或类C语言作为输入,从这种命令式语言中很难提取到结构信息和并行特性,难以发掘其中的优化机会.
2) 优化指令和算法杂糅在一起,如果要进行算法结构上的变更必须修改大量代码,编程效率低下,无法快速找到较好的算法结构和优化方案.
3) 优化指令不友好,由于输入语言的原因,只有开发人员对硬件底层细节十分了解才能写好优化指令,比如某一段程序想要并行执行,开发人员得自己设计好数据存储和划分,否则HLS系统会大量复制数据占用稀缺的片上存储或者因为存储空间不够而自动取消并行,但是这些对开发人员是隐藏的,只能在生成RTL后通过硬件代码或者资源利用情况判断.
4) 中间表示(intermediate representation, IR)粒度太细,输入的上层代码编译为最基本的操作,完全丧失了结构特性,底层硬件模板也是基本操作的简单实现,会造成电路逻辑的大量冗余和关键路径的延长,降低可读性,同时与手写代码相比也要逊色许多.
5) 调度算法不高效,系统最耗时的部分就是调度部分,由于FPGA的天然并行特性,没有依赖的逻辑是可以并行执行的,为了缩短关键路径提高系统频率,组合逻辑不应该过长,这要求可以并行的尽量放到同一个时钟周期中执行,由于IR粒度太细,指令数目巨大,现有调度算法只能在可接受时间内找到次优解,或者直接采用简单的启发式算法,面对潜在的依赖关系没有很好的方法解决或者直接串行执行,特别是图计算这类不规则应用,对优化指令也没有特定的支撑,这也是片上存储资源被不必要地大量消耗和表面并行实则串行的原因.
6) 不支持片外数据传输,HLS系统不能自动生成存储控制器和与主机端以及DRAM数据传输的接口,只能生成逻辑电路后手动编写添加相应模块,对于上板需求而言十分不便,同样要求开发人员对底层内存系统细节十分了解,没有从根本上提高硬件设计的抽象层次.
HLS系统整体流程也导致了编译和综合流程对开发人员不透明,难以通过在上层调整高级语言代码从而在底层实现特定硬件架构,底层低效的硬件模板既无法灵活表达上层需求,也不能达到高效性能,特别是对现在一些复杂的特定应用,HLS系统的作用非常有限.因此出现了一些领域特定语言(domain-specific language, DSL),对特定领域需求作了相应的优化,从上层编程语言到底层硬件模块都作了对应修改,取得了很好的效果,但是对于图计算这类非规则的复杂应用还没有很好的支撑,与其特性不能很好地契合,目前还没有一个专门面向图计算的HLS系统.
为了解决HLS系统缺乏对图计算有效支撑的根本问题,提出了一种面向图计算的高效HLS方法,通用自定义的编程原语编写图算法作为输入,自动输出RTL代码.本文主要贡献有4个方面:
1) 提出了一种面向图计算的高效HLS方法,采用数据流架构实现高效的并行流水执行.
2) 提出了面向图计算的函数式编程原语和对应的优化指令,可简洁高效地表达各类图算法.
3) 提出了模块化的数据流IR,细粒度地暴露出图算法中的点边不规则并行性.
4) 提供参数化硬件模板,生成了BFS和PageRank算法的硬件实现,通过在不同数据集上的实验结果验证了方法的正确性和高效性.
1 相关工作
当前的FPGA设计工具支持相对原始的编程接口,需要大量的手动工作[9],Verilog和VHDL等硬件描述语言专为任意电路描述而设计.时序、控制信号和内存均由用户处理.而Chisel[10],MyHDL[11],VeriScala[12]这样的语言通过在软件语言(例如Scala或Python)中使用硬件描述语言来简化程序生成电路.Genesis2[13]为SystemVerilog添加了Perl脚本支持,以帮助推动程序生成.虽然与Verilog生成语句相比,这些改进允许更强大的元编程,但用户仍然在时序电路级别编写程序.
HLS系统提高了设计层级[14],比如LegUp[15],Lime[16],Vivado HLS[17],OpenCL[18],SDAccel[19],允许用户用类C语言或者OpenCL进行FPGA设计,存储单元用数组表示,整个应用不包含时序.但是对于图算法中的嵌套循环,使用这些工具进行内层循环流水执行、循环展开、内存划分、内存复制和建立缓冲区时,由于这些工作均由编译器完成,命令式的设计描述给编译器发现并行性、流水结构和内存访问模式带来了很大的困难,因此要求用户进行显示地标注,对用户提出了很高的要求,而且数组很难映射到图计算所需要的各种硬件存储单元.
有工作采用多面体工具在单循环嵌套中自动对仿射访问进行内存划分[20],但是不能解决图计算中非仿射访问的情况和多循环嵌套中访问相同存储单元的情况.也有工作可以辅助对HLS程序中的编译指示进行自动调整,但仍需要手动硬件优化.总而言之,HLS工具不能很好地挖掘粗粒度流水执行和嵌套循环并行的机会,同样简单的存储模型对高并行流水的支持也不足.
DSL在提高设计层级的同时对特定领域进行了相应优化,DHDL[21]可以描述无时序嵌套并行的流水结构并将其转化到硬件模块,Spatial[22]是DHDL的改良版本,可以支持有数据依赖的控制流和丰富的存储单元表达.但是对于图计算这种非规则的应用,当并行执行时产生大量数据冲突,Spatial的内存划分机制对其支撑不足,会简单地对片上存储单元进行复制操作,快速用完稀缺的存储资源,无法实现高并行度.
在HLS系统中使用动态调度可以实现更高效的流水结构,ElasticFlow[23]可以对一类特定的不规则循环进行循环流水化,Dai等人[24]通过调度流水结构的多个启动间隔实现流水线冲刷,他们后来开发了应用特定的动态冲突检测电路,但是有严格的约束.Nurvitadhi等人[25]通过假定数据通路已经划分到了流水线各个阶段来实现自动流水化.这些方法还是基于传统HLS系统中的静态调度,引入了一些动态行为,只能在特定的情况下得到性能提升.
目前还没有HLS工具可以从上层高级语言为图算法直接生成高并行度的高效流水结构,一方面因为其表达能力有限,用户很难准确描述所要的架构并指定微架构参数,另一方面对图算法指定高并行度后会产生大量数据依赖和冲突,没有足够的底层优化去实现高并行度所需的存储和计算结构,导致最后生成的硬件电路实际串行执行或者资源耗尽无法生成.
本文通过底层采用特定于图算法的优化数据流架构和定制的存储层级结构针对上述HLS工具中难以对图算法高并行度执行和存储模型低效的问题提出了解决方法,为从上层语言生成图应用RTL提供有效支撑.
2 系统设计
本节中主要包含3个部分,分别是上层编程模型、模块化数据流IR和底层参数化硬件模板与RTL代码生成,对应整个方法的执行流程.
2.1 上层编程模型
编程模型使用的是以点为中心的模型,图算法通过描述每个节点的计算行为描述整个算法逻辑,有较高的兼容性,在执行模型方面,图计算中常见的执行模型有push和pull这2种.本文选择pull作为执行模型.在pull模型中,图算法每轮迭代会调度所有节点,并处理其所有入边数据.选择它的主要原因是:1)PageRank类算法更适合采用pull[26];2)基于push的BFS需要同时获取源点和目标点数据,增加硬件开销;3)基于notify-pullpull和pushpull的BFS的性能差距较低.
算法1给出了基于以点为中心的命令式图算法伪代码,在详细解释之前先给出图术语,由于从数学到计算科学以及其他各个领域对图的研究非常广泛,标准的术语尚未确定,本文只简单介绍此处使用的描述.
算法1.基于以点为中心的命令式图计算伪代码.
输入:点数据VertexValue、边数据Edge、边偏移量EdgeOffsetTable;
输出:迭代收敛后的点数据VertexValue.
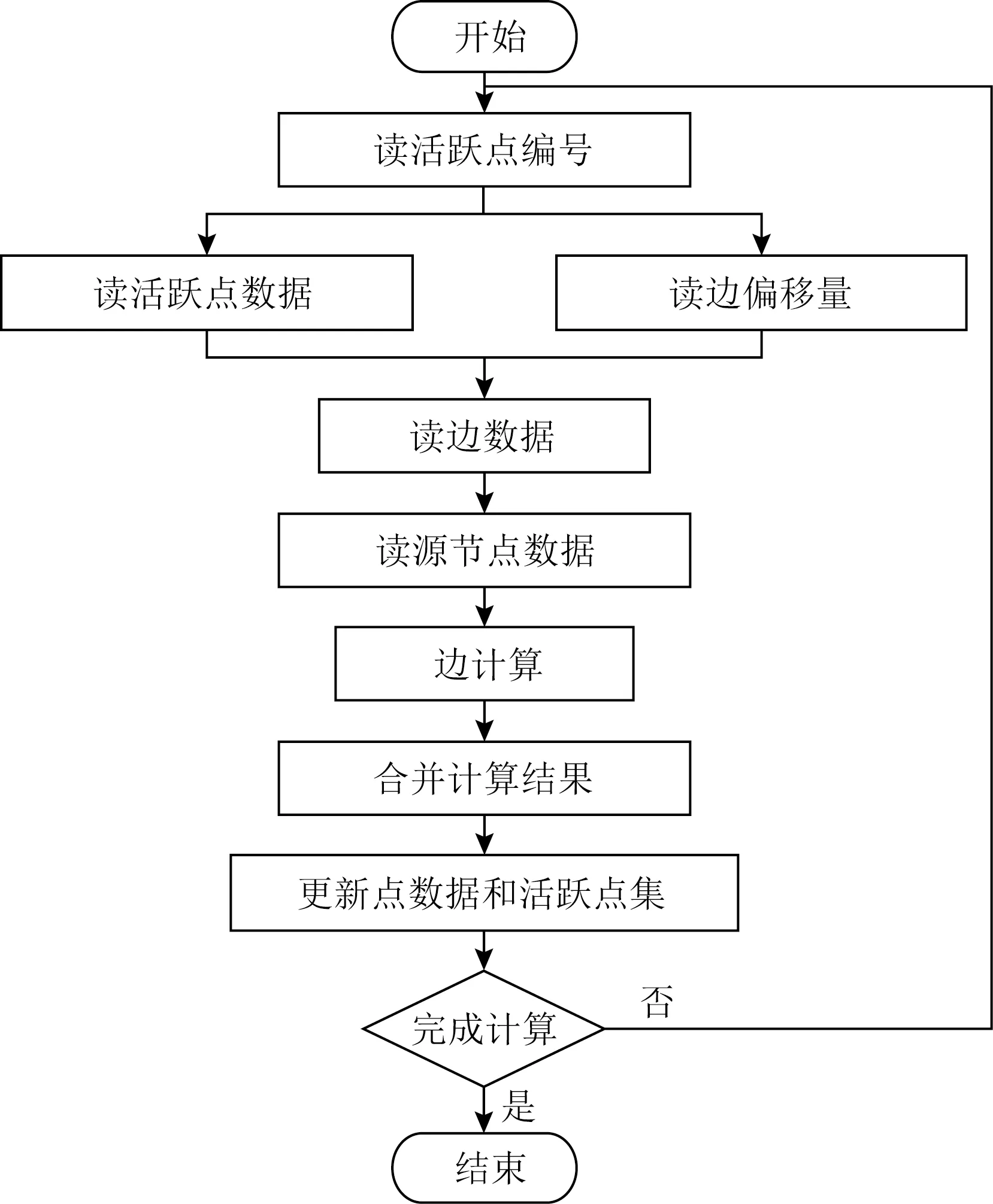
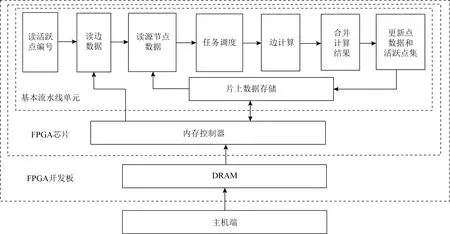
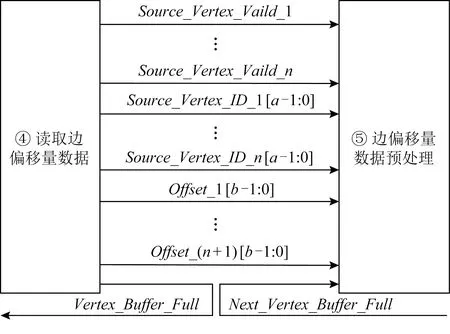
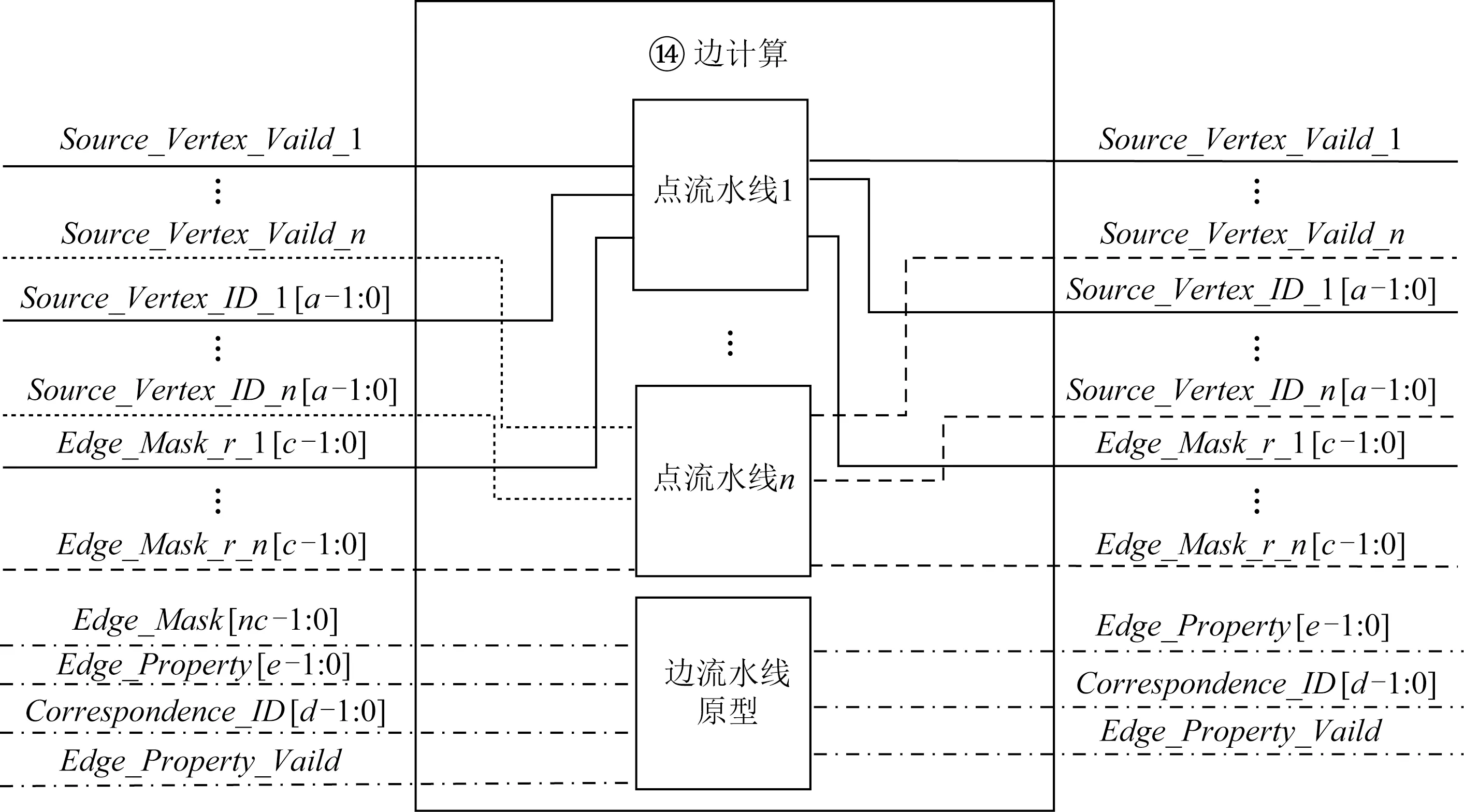
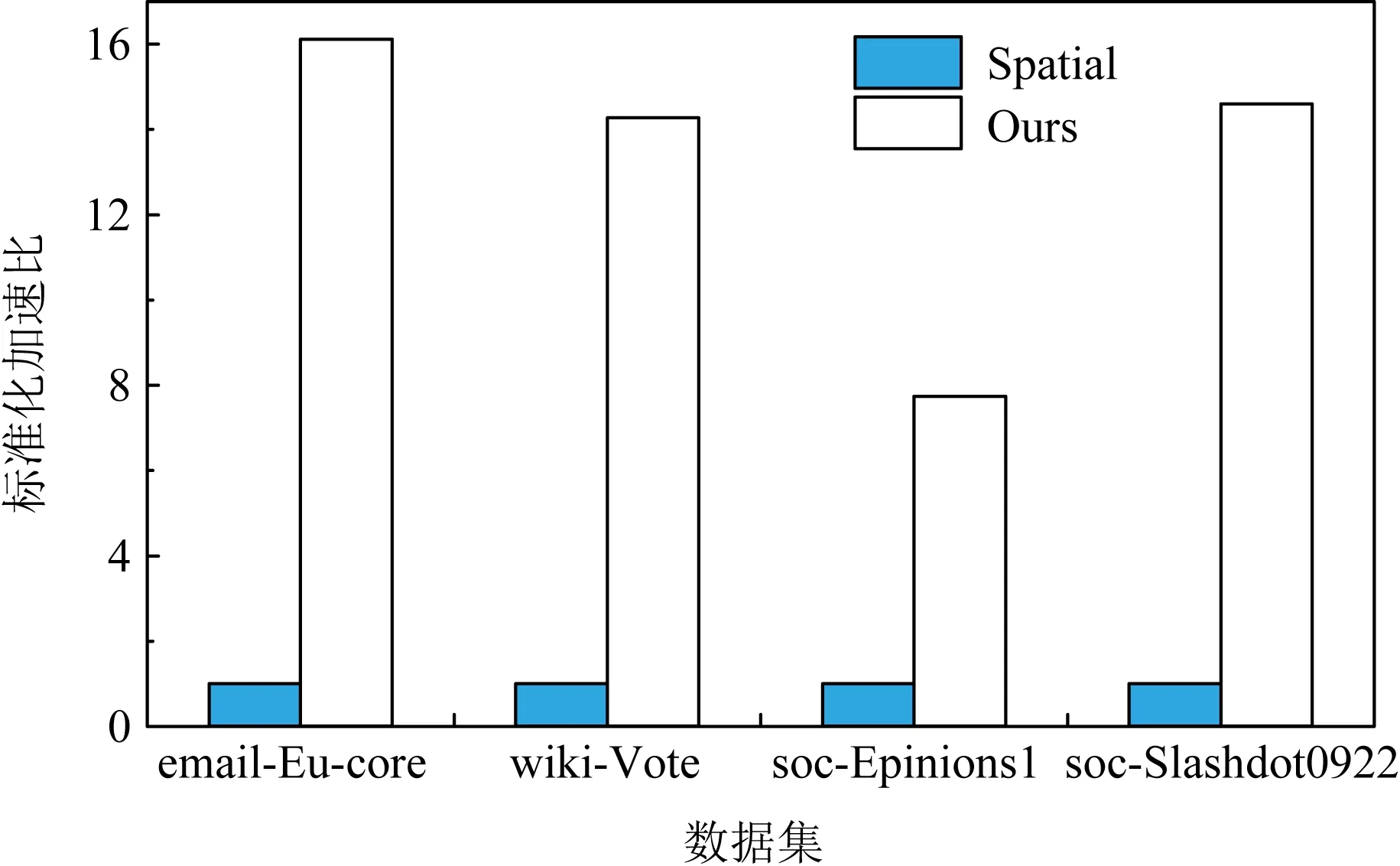
① for (inti=0;i ② Vertexv=ActiveVertex[i]; ③ EdgeOffseteoff=EdgeOffsetTable[v.id]; ④ for (intj=eoff.l;j ⑤ Edgee=Edge[j]; ⑥ Valueu.val=VertexValue[e.uid]; ⑦ Valuetmp=Process(e.weight,v.val,u.val); ⑧ Valuenewval=Reduce(tmp,newval); ⑨ endfor ⑩ UpdateVertex(v.val,newval); 图数据结构建立在反映现实世界的基元上,包括顶点(vertex)、连接不同顶点的边(edge)和属性(property),节点和边均有自己的属性,属性可以是任意类型的任意数据.编程模型要求输入格式为压缩稀疏行(compressed sparse row, CSR),引入了Offset的概念,即当前顶点对应边在边表中的偏移量,在具体算法实现中一般还会建立1个活跃点集(ActiveVertex),目标节点表示为u,属性值表示为Value. 对算法1中的图计算伪代码,行①的循环代表依次处理所有活跃顶点,行④的循环代表依次处理当前活跃顶点的所有边.首先考虑对嵌套循环进行粗粒度流水,即行②③作为1个流水阶段,行④~⑨的循环整体作为1个流水阶段(目前只有Spatial可以实现任意位置的粗粒度流水),接着对行④~⑨代表的循环整体进行细粒度流水,即使达到了HLS工具最大的流水能力,高并行度情况下依然会有严重的流水停滞.之后考虑添加并行指令,分为点间并行和点内并行,分别对应于行①的循环并行和行④的循环并行,两者可同时添加. 首先考虑点内并行,对于高并行度的点内并行(图加速器可达到并行度为16或32),在顶点度数较小时每个周期都有许多计算资源空闲.首先分析行⑤,边数据存放在Edge数组中,因为采用CSR输入格式,此处边是连续的,可以通过划分支持高并行访问,第1节提到有HLS工具对这类访存行为可以自动进行内存划分,许多也支持手动划分.之后行⑥通过边数据访问目标点属性,由于每个顶点所连结的目标节点是不可预测的,此处会存在大量的数据冲突,对于这种访问模式现有工具不能进行自动划分,由于图数据的幂律分布,少量顶点会连接大量的边,这些顶点的访问会尤其频繁,Spatial不允许手动的内存划分,其自动划分机制此处支持有限,从而选择简单的内存复制导致片上稀缺的存储资源大量消耗.行⑦是特定于图算法的处理操作,行⑧计算得到更新值,此处由于每条并行的流水线都会读同一个变量然后向其中写入,有的HLS工具为保证结果正确性会串行执行,有的没有检测到这个依赖问题会产生错误的结果(多条流水同时往同一个地址写入时只会写入第1条流水的数据). 点间并行情况与点内并行类似,由于图数据的幂律分布特性,并行流水线间存在负载不均的问题.在行②读活跃点数据和行③读边偏移量以及后面的操作冲突同样很严重.当边数量太大无法存放在片上时会将其存放到片外动态随机存取存储器(dynamic random access memory, DRAM)中,一般在行③和行④之间增加1个通过Offset去片外取边的操作,不改变行⑤取边数据的冲突本质. 现有HLS系统虽然可以实现图算法的粗细粒度流水结构,但是在指定高并行度时缺乏访存和并行更新操作的支持,其生成的硬件逻辑依赖于用户的输入,但是高级语言对硬件描述能力有限,即使用户熟悉底层硬件也很难在上层描述出特定的硬件结构,对算法1的分析可以发现在整个遍历过程中可以将图算法的操作分为读活跃点集合、读边偏移量、读边数据、读目标点数据、边数据计算、合并计算结果和更新节点和活跃点集7个主要操作,但是针对于循环而展开的各种优化手段无法针对性地切实地解决这些操作中存在的依赖和冲突问题,其作用于循环内包含的多种操作,无法为每个操作生成特定的支持. 本文提出的编程模型突出了7个主要的图操作,允许用户直接在每个操作上添加特定的架构和微架构参数,包括并行度、数据位宽、数据类型和格式调整.如算法2所示的伪代码. 算法2.基于以点为中心的函数式图计算伪代码. 输入:点数据VertexValue、边数据Edge、边偏移量EdgeOffsetTable; 输出:迭代收敛后的点数据VertexValue. ①ReadGraph(address); ② Foreach (ActiveVertex){i=> ③v=GetVertex(i); ④off=GetOffset(v); ⑤ Foreach (off){j=> ⑥e=GetEdge(j); ⑦u=GetNeighbor(e); ⑧tmp=Process(v,e,u); ⑨newval=Reduce(tmp,newval); ⑩ } 根据图计算的依赖关系,算法2的数据流图如图1所示,算法2中行①由用户指定输入的CSR格式图数据的地址,读入图数据,将根据后面的代码自动决定数据的存放方式和地址;行②③对应图1中读活跃点数据,由于是pull执行,所有点都是活跃点,其中行②实际上作为本轮迭代是否完成的信号,此处可以选择读点的并行度;行④对应图1中读边偏移量,同样可以指定并行度,默认和点并行度保持一致;行⑤无实际作用,如2.1节所述此模型不依赖循环驱动执行;行⑥对应图1中读边数据,可以指定边并行度,由于是顺序读边不依赖于源点数据,当顶点度数较大时相当于点内并行,顶点度数较小时相当于点间并行,保证了硬件资源的持续运行和解决了点间度数不均匀带来的负载均衡问题;行⑦对应图1中读目标点数据,由于此处存在大量随机访存,将根据读边并行度生成对应数量的缓冲区,对片上点数据划分的同时也对访存请求实施调度保证较高的吞吐量.行⑧对应图1中的边计算,可以指定数据位宽和数据类型;行⑨对应图1中合并计算结果,用户只需编辑合并的逻辑操作,具体架构根据读边并行度按照文献[5]中并行累加架构产生;行对应图1中更新结果和活跃点集,同样用户只需在行编辑合并的逻辑操作即可,此处更新结果操作并行度不大于读点并行度,且会对片上点数据存储作相应设置,不会产生读写冲突问题. Fig. 1 The data flow diagram of algorithm 2图1 算法2的数据流图表示 基于图1所示的数据流图,本文设计了如图2所示的模块化数据流IR用以高效支撑图1中的各个操作高并行度流水实现.IR分为17个模块,每个模块对应图2中的1个节点,编号和数据流动方向如图2所示,不同于将上层语言编译为细粒度的中间表示后再去挖掘其中的并行机会,模块化的IR通过更高抽象层次的表达将图算法中如2.1节提到的关键点针对性地用特定的模块显式表达,精准地提供了优化支持,避免了大部分数据冲突.其中每个模块都有2种缓冲区,其一接收上一模块传递的数据并指示溢出情况,另外还有缓冲区存入本模块产生的结果供下一模块读取,根据缓冲区的溢出信号产生控制信号.接下来按照图1各个图操作的连接顺序依次说明IR中的对应模块在每个时钟周期的操作是如何进行支撑的,还会说明IR中各个模块的实现细节. Fig. 2 Modular data flow IR图2 模块化数据流IR 1) 读活跃点数据 模块①对应读活跃点数据.由于pull模型所有顶点都是活跃点因此可以顺序读取源节点,实现逻辑为1个源节点计数器按照读点并行度每个周期生成对应数量的源节点编号存入输出缓冲区,输出缓冲区有溢出信号控制源节点计数器,输出缓冲区的大小根据指定的位宽和点并行度实例化.假设点并行度指定为n. 2) 读边偏移量 模块②③对应读边偏移量.模块②从模块①的输出缓冲区读取n个点,传递源节点信息,同时顺序生成节点边偏移量的访存请求,同样受到溢出信息的控制.模块③处理边偏移量的访存请求和边数据访存请求,各有对应的访存请求输入缓冲区和数据输出缓冲区,大小由访存请求并行度和读边数据并行度决定. 3) 读边数据 模块③~⑧对应读边数据.模块④从模块③中边偏移量输出缓冲区接收边偏移量,同时从模块②中读取n个点信息继续传递.模块⑤从模块④中读取边偏移量和源点数据并进行匹配,在节点信息中添加其对应的边偏移量. 模块⑥按照读边并行度顺序生成边访问请求,假设读边并行度为m,不同于根据源节点对应的边偏移量来生成边访存请求,模块内有读边计数器,此处需要做1个调度.首先从缓冲区中取n个源节点,由于源节点是连续的,所以其对应的边偏移量也是连续的,若读边计数器的值加上m大于最大的边偏移量,即将取的m条边包含了n个源节点的所有邻边,还存在不属于这n个点的边,那么此次时钟周期传递n个源节点和m个边访存请求,但是边计算器不增加,即下一时钟周期依然生成这m条边的访存请求.若恰好相等,则传递n个源节点和m个边访存请求,边计数器增加m;若小于,说明将取的m条边不能完全包含这n个点的所有边,根据源节点信息中包含的边偏移量计算出哪些源节点的边完全包含在这m条边中,传递这些源节点并用无效点补充为n个,其余的源节点存入缓冲区中等待下个时钟周期处理,传递m个边访存请求,边计数器增加m.即此模块根据实际节点度数可以处理大度数节点的多条边,相当于点内并行,也可以处理多个小度数节点的所有边,相当于点间并行. 模块⑦对边数据产生控制信息,即当点度数较小时m条边中存在边不属于这n个源节点,需要标记这些无效边,同时需要给边加上标记指示属于的源节点编号,向后传递节点信息和边控制信息.模块⑧从模块③接收边数据,从模块⑦接收节点信息和边控制信息,根据控制信号传递这3类信息. 4) 读目标点数据 Fig. 3 Hardware architecture of graph processing accelerate图3 图计算加速器的硬件架构 5) 边计算 6) 合并计算结果 7) 更新结果和活跃点集模块 基于图1的数据流图,硬件架构如图3所示,片上流水主要包括读活跃点集合、读边数据、读目标点数据、任务调度、边计算、合并计算结果和更新节点和活跃点集.实际流水按照IR分为17个模块,每个模块有参数化的硬件模板支撑,按照2.2节所述各个模块完成的功能不同,对应硬件模板内部结构包括外层接口也不相同,但是2个确定的硬件模板间传递的数据类型是确定的,主要包括源节点有效性信号、源节点编号、后续流水级溢出信号、内存控制器溢出信号、边偏移量数据、边数据、边数据有效性、边数据属于的节点编号、目标点数据等等.而对于源节点编号、边偏移量这类非控制性数据可以根据指令生成多个并行连线.硬件模板内部参数主要包括各类数据的位宽、缓冲区大小、点边流水线个数等. 以模块④和模块⑤对应的硬件模板之间的连接为例(省略时钟信号和重置信号),如图4所示.模块④输出n个源节点有效性信号、源节点编号、n+1个边偏移量、1个缓冲区溢出信号,其中源节点有效性信号和溢出信号位宽默认为1,源节点编号和边偏移量位宽根据指令设置;模块⑤接收对应数据并从下一流水级接收缓冲区溢出信号. 对于图算法无关的模块,其对应的硬件模板基本功能完备,只需根据用户指定的并行度和数据位宽类型等要求实例化对应的点传递流水线、边传递流水线、边控制信号传递流水线和缓冲区的大小以及各个模块内部控制信号的参数.对于图算法相关的模块,包括图2中模块,以边计算对应的硬件模板为例(省略时钟信号和重置信号),如图5所示.图5中输入接口包括源节点有效性信号、源节点编号、边控制信号、边属性等;内部结构包括单个点传递流水线和多边操作模块,源节点信息和边控制信息通过单个点传递流水线向后续流水级传递,边属性进入多边操作模块处理得到更新值;输出接口包括源节点有效性信号、源节点编号、边控制信号、更新值等. Fig. 4 The connection diagram of edge offset reading hardware template ④ and ⑤图4 边偏移量读取的硬件模板④和⑤连接示意图 Fig. 5 The diagram of edge process hardware template图5 边计算硬件模板示意图 除了多边操作模块内部与图算法相关的部分外,输入输出接口和单个点传递流水适用于不同图算法,同样只需按照用户指令参数实例化,包括各类数据的位宽以及单个点传递流水线的个数等,边属性数据中包含多条边,根据边并行度决定,依照相应的位数在多边操作中并行处理.由于用户只需编写计算操作,不包含控制和访存操作,根据其计算操作生成相应的基本硬件计算器在多边操作模块内连接即可.完成各个硬件模板的实例化和相应的连接后生成最终的Verilog代码. 图算法根据计算特点被分为2类:遍历为中心和计算为中心,其中BFS和PageRank分别是这2类图算法中最常用并且最具代表性的图算法.在本节中,我们使用本文提出的方法生成了BFS和PageRank硬件实现,并且在4个不同类型的数据集上测试了硬件实现的性能,我们还使用特定于并行模式优化的DSL Spatial生成了手动调优的BFS和PageRank硬件实现,在相同数据集上进行了比较,验证了本文中面向图计算的HLS方法的有效性. 本文从SNAP网站上下载了4个不同类型的数据集,均为自然图,如表1所示.按照边数目大小分别为email-Eu-core,wiki-Vote,soc-Epinions1,soc-Slashdot0922,平均度数区分明显,可以验证硬件实现在不同度数下的表现,平均度数最大的email-Eu-core达到了25.4,平均度数最小的soc-Epinions1为6.7.将所有数据集预处理为图计算中流行的CSR格式,包括边偏移量文件(Offset)和边表(edge).本方法和Spatial生成的硬件实现使用完全相同的输入,包括格式和数据. Table 1 Datasets Used in Our Experiments表1 实验数据集 本文按照Graph500的计算标准测试BFS硬件实现的性能,计算方法为:图的边数除以BFS运行时间,由于采用pull执行模式,BFS需要多轮迭代才能收敛,此处采用图的边数进行计算而不是多轮迭代的总边数,剔除了迭代中无效的吞吐量.由于PageRank在每轮迭代中所有边均为有效边,因此通用的PageRank性能计算方法为:图的边数除以PageRank 1轮迭代时间,所有硬件实现使用Xilinx Virtex UltraScale+XCVU9P进行验证. 本方法的优化参数设置为读点并行度为4,读边并行度为16,其余各模块并行度与其匹配,数据位宽设置为32 b,边偏移量预处理模块输出的边偏移量数据位宽为4 b,设置时钟频率为200 MHz. Spatial优化参数按照2.1节中描述的流水方式,首先将内层循环当做整体放到外层循环的粗粒度流水中,然后对内层循环内部进行细粒度流水,考虑到片上存储资源的数量,设置内层循环并行度为2,即点间流水并行度为2,按照其默认的150 MHz时钟频率运行. 根据FPGA上运行时间按照评估方法分别计算2类硬件实现在4个数据集上的吞吐量,通用指标为每秒遍历百万条边数(million traversed edges per second, MTEPS),PageRank性能如表2所示,BFS性能如表3所示,本方法硬件实现和Spatial硬件实现分别简称为Ours和Spatial.为了更直观地体现性能优势,图6和图7中以Spatial实现的性能为基准分别给出了PageRank和BFS性能加速比图. Table 2 Performance Comparison of PageRank 表2 PageRank性能比较 Table 3 Performance Comparison of BFS表3 BFS性能比较 Fig. 6 Performance speedup of PageRank图6 PageRank性能加速比 Fig. 7 Performance speedup of BFS图7 BFS性能加速比 Spatial非常适合挖掘出深度学习、矩阵相乘这类规则访存应用中的并行性,其自动内存划分机制在其中发挥巨大作用,但是如2.1节中提到的原因,在图算法中不规则访存使其自动划分不能发挥太大作用,大量复制存储单元导致其并行度难以提升. 我们的实验结果相比于Spatial有很大的性能优势,BFS在不同数据集上有7.9~16.1倍的性能提升.对于以遍历为中心的图算法而言,由于底层优化后的架构各个模块的时序约束较为宽裕,主要问题集中在图2中的模块边处理模块,因为这类图算法边处理模块内的逻辑相对简单,实际上整个设计可以采用更高的时钟频率,给性能带来进一步提升. 另一个重要影响因素即图数据,图7中实验结果表明对不同的图数据性能差别较大,主要与图2中的模块⑥生成边数据访存请求和模块片上数据缓存有关,当节点平均度数较大时,模块⑥访存的全是有效边,性能较好,email-Eu-core,wiki-Vote,soc-Slashdot0922节点平均度数都大于11;而节点平均度数较小时,受限于读点并行度,会产生许多无效边导致性能较差.此外虽然在模块⑩中做了调度允许不同时钟周期到来的邻点访存请求同时执行,但是如果邻点访存行为不规则程度较大,对性能也会造成影响. 本文采用的pull编程模型最适合PageRank类型的图算法,其在不同数据集上有26.19~30.57倍的性能提升,因为PageRank 1轮迭代里面所有边都是有效边,而BFS这类图算法1轮迭代里面只有很少一部分是有效边,由于我们是按照有效边进行计算,剔除了遍历的无效边,因此PageRank性能会比BFS好很多. 2.2节提到边处理模块会影响时钟频率,因为PageRank需要复杂的浮点计算,频率很难进一步提升,虽然可以采用流水线方式进行浮点计算,使得其启动间隔为1个时钟周期,即和BFS的边处理模块达到同样的处理速度,但是由于流水线长度更长,当模块停顿时,需要更多的时钟周期才能重新启动.类似地,图数据也会对PageRank性能产生影响,由于边处理并行度设置为16,当平均度数低于16时,由实验结果可知更高平均度数的图数据会有更高的性能. 针对通用HLS系统缺乏对不规则图算法有效支撑的问题,提出了一种面向图计算的高效HLS方法.结合图算法固有的嵌套循环、大量随机访存、数据冲突以及图数据幂律分布等特性,设计了数据流驱动的处理架构,实现高效的并行流水执行,保证了处理单元的负载均衡.通过自定义的编程原语,可快速定制现有图算法,并将其转化为模块化的数据流中间表示,进而映射到参数化的硬件模板,最后生成RTL. 未来计划考虑提供更丰富的编程原语和编译支持,使得用户可以在上层表达出现有各主流图计算加速器的底层架构特性.2.2 模块化数据流IR
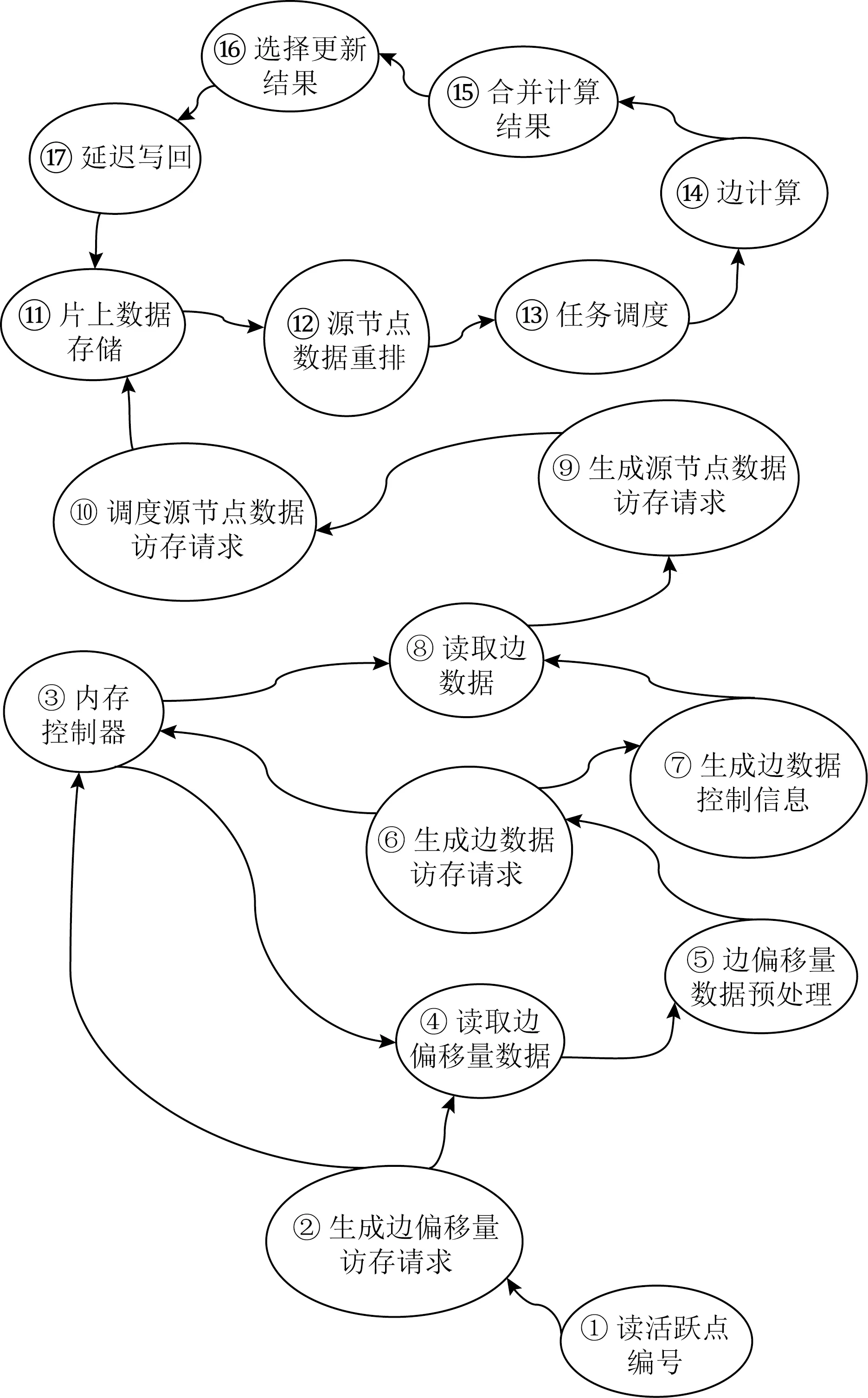
2.3 底层参数化硬件模板和代码生成
3 实验与结果
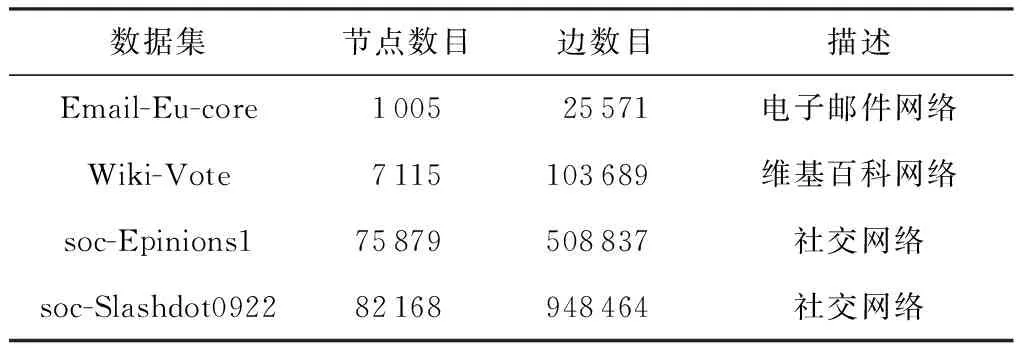
3.1 实验数据集
3.2 实验评估方法
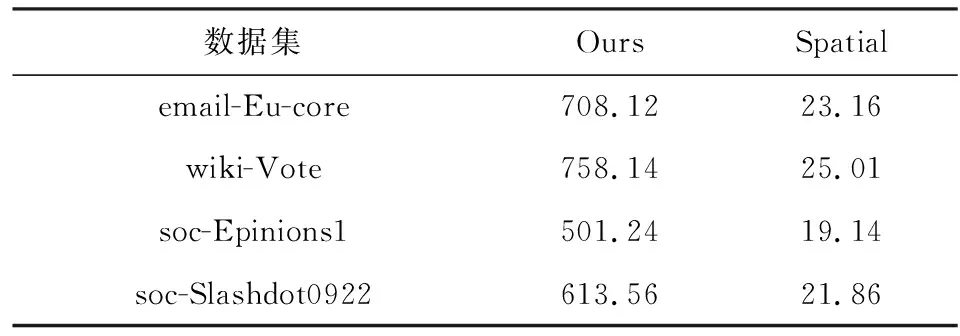
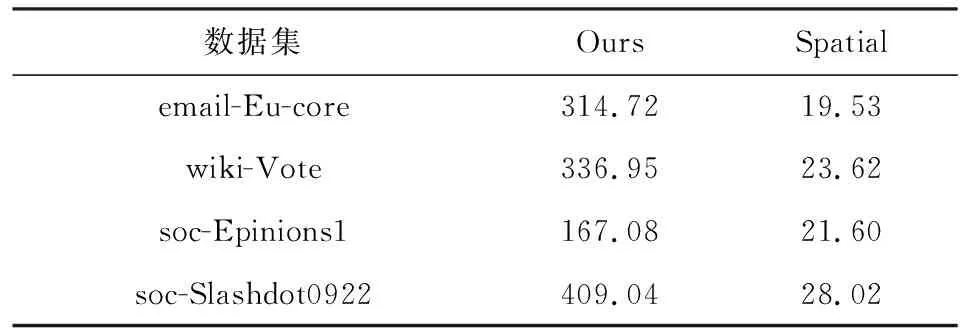
3.3 实验结果

4 总 结
猜你喜欢
北京工业职业技术学院学报(2024年1期)2024-01-14 06:35:14地理空间信息(2022年3期)2022-04-01 14:16:14文苑(2020年10期)2020-11-07 03:15:26制造技术与机床(2017年7期)2018-01-19 02:29:53测绘工程(2017年3期)2017-12-22 03:24:50天津诗人(2017年2期)2017-11-29 01:24:12视野(2015年6期)2015-10-13 00:43:11项目管理技术(2015年3期)2015-04-23 08:44:29海峡姐妹(2014年5期)2014-02-27 15:09:38计算机工程与设计(2012年3期)2012-07-25 11:05:00
