
基于统一数据模型的电力现货市场清算方法及其应用
2021-03-30 01:32龙苏岩盛祥祥周天翔王一凡许玉洁
电力系统自动化 2021年6期
龙苏岩,盛祥祥,周天翔,王一凡,许玉洁
(中国电力科学研究院有限公司,江苏省南京市210003)
0 引言
市场结算机构会依据市场主体的计量数据、交易结果等数据,按照结算规则定期进行市场结算与费用收取及支付。由于计量数据差错、历史数据修正、结算规则调整或合同发生变更等原因,需要对已经财务支付的结算账单进行历史数据的追补重算,重算结果须与历史结算单据进行对比,形成追补清算账单,实现对偏差费用的处理。
中长期市场下,结算是以月度为周期开展,由于结算数据规模小、结算周期长,月度数据出现差错的机会也较小,因此在中长期市场,数据清算处理频率与难度都较低,即使出现清算也是采用追补的方式进行处理。随着中国电力现货市场的快速推进[1-3],电力交易结算、清算数据粒度由月度发展为以15 min或1 h 为周期,业务处理周期由月度发展为按日清分计算,同时需要对分钟级的计量、分时交易等数据进行完整的数据版本管理。另外,各省受电网结构、供需水平、历史问题等影响,电力现货市场清算规则复杂且不统一,给清算系统研发也带来较大困难,相比于中长期市场,现货市场清算系统需要解决数据的版本化、复杂规则的灵活计算及分钟级数据的高频日清计算、大规模数据的高性能快速计算等问题。因此,亟须研究面向现货市场大规模数据的高性能、通用型清算系统构建方法。
文献[4-6]研究了基于模块化的清算系统实现方法;文献[7]通过建立构件化分层模型,实现对清算业务的灵活适应;文献[8]提出了面向服务的组件化方法以便于功能扩展。上述清算系统设计基于传统行式数据库进行存储,未考虑面向大规模数据的计算效率问题。另外,在业务扩展方面,虽然有一定灵活性,但面临变化的需求,仍需重新建立模型及进行软件升级,带来了较高的系统维护代价。文献[9]采用分布式数据库存储提升清算的计算性能,通过并行处理可以一定程度上缓解性能问题,但其在内在的计算逻辑上依然存在计算效率较低的问题。目前全国统一市场正在建立,也对未来技术支持系统的发展方向作了顶层设计[10-12],各省电力市场发展迅速[13-14],同时现货试点省份在前期的基础上还要进一步开展现货市场连续试结算[15-17],因此亟须研究一套有效的方法解决灵活清算、快速清算这一系统难题。
本文提出了基于统一数据模型的沙盒式清算方法,可解决上述技术面临的局限。通过运用多维数据立方体模型实现清算数据的模型标准化,引入沙盒原理[18-19]实现清算数据与生产数据的隔离,利用列式计算技术实现清算的快速对比计算,同时解决清算的灵活性问题与计算性能问题。最后,通过上述技术研制了清算系统,实际应用也证明了该方法的有效性和可靠性。
1 沙盒技术
沙盒(Sandbox)[20]是一种安全机制,目的是为运行中的程序和资源提供隔离的环境,运行过程和运行结果对沙盒以外的系统环境不会产生任何影响。本文应用沙盒技术理念,提出了沙盒式的清算系统设计,将清算的数据资源、业务动作、算法逻辑重新定向到沙盒环境中,与生产系统相对独立,可实现隔离式的数据版本化。
传统清算方式是利用生产环境资源,通过修正前置数据、补增数据或调整计算逻辑规则等直接修改生产环境数据并进行数据重算,从而对生产数据产生冲击。在沙盒清算方式下,将数据划分出隔离区域,将历史结算的数据模型、逻辑算法与业务数据重载至沙盒环境,由于将清算行为封闭在固定的隔离环境中,因此不会对生产系统产生影响。当清算发生时,沙盒环境可与生产环境并行处理,清算计算完成后,将生产系统的历史结果与清算重算结果进行偏差计算,形成追补清算数据账单。清算系统的沙盒数据原理如附录A 图A1 所示。
2 基于数据立方体的算子库模型
2.1 维度分解
电力现货市场中的数据具有周期时变、维度复杂、口径多样等特征,为实现清算的灵活计算,必须要实现数据模型的统一构建,则前提是先建立维度集合及维度之间的关系。因此,首先参考数据仓库的典型建模方法,建立面向主体、属性和业务的概念模 型[21],然 后 依 据 维 度 交 织 的 特 点,建 立E-R 模型[22-23],如 附 录A 图A2 所 示,该 模 型 以 星 形 模 式(star schema)为基础,按照维度建模法[24]对电力市场交易维度建立维度集合。
2.1.1 市场维度类
市场类型:电能市场、辅助服务市场、容量市场、输电权市场等。
2.1.2 交易维度类
1)交易周期:中长期交易、日前交易、日内交易、实时交易等。
2)交易方式:双边协商、集中竞价、挂牌交易、省间交易、转让交易等。
2.1.3 主体维度类
1)发电类主体:发电企业、发电机组等。
2)用电类主体:电力用户、售电公司等。
3)输电类主体:电网公司、地方电网、独立配电网售电商等。
4)计量类主体:计量关口、负荷单元等。
2.1.4 口径维度类
1)电量口径:上网、发电、下网。
2)计量口径:增量数据、底码数据。
3)价格口径:批复价格、合约价格、交易价格、环保补贴价格、考核价格等。
文中仅列举部分维度,鉴于电力交易维度的复杂性,需要研究建立多维数据的管理模型,实现对电力交易维度进行统一建模与灵活扩展。
2.2 多维数据立方体
多维数据立方体[25-26]是基于维度和量度(即事实)组合形成的多维矩阵,通过提取各维度间的主外键特征关系及量度间的层次关系,将电力交易E-R模型转换成多维度、多层级的数据立方体。数据立体维度可高于3 维,本文以3 维为例,建立如图1 所示的多维数据立方体模型。图中数据表示2019 年10 月1 日至5 日期间每天10:30 的现货市场交易电量,单位为kW ⋅h,交易品种包括基数合约、直接交易、日前交易、实时交易。现货批发市场中发电机组同时参与合约,机组发电类型包括火电、新能源。交易结果的E-R 模型建立好之后,将其转换为多维立方体模型,通过多维立方体形成的统一数据结构,可以快速找出数据之间的关联关系,为后续的数据计算提供统一的模型支撑。当出现增加新的交易品种或交易周期等情况时,会在维度分解中增加相应的维度,从而实现模型的灵活适应。完整的多维数据立方体模型由多维数组、属性数据、量度数据及数据内部对象之间的关系构成,包括模型元数据和业务数据。

图1 多维数据立方体模型Fig.1 Cube model of multidimensional data
2.3 算子库模型
将输入/输出(I/O)模型的多维立方体数据描述为一个4 元数组C={ D,M,V,r },其定义为:①D={d1,d2,…,di}为维度集合;②M ={m1,m2,…,mj}为量度集合;③V={v1,v2,…,vk,…,vt}为值集,代表量度的实际值;④r 表示维度对应到值集的映射关系,即{d1,d2,…,di}→vk。
计算模型f 描述为输入到输出数据模型之间的逻辑计算关系,定义f 为:

式中:{i1,i2,…,im}为输入多维数据立方体的数据集合;{o1,o2,…,on}为输出结果的多维立方体的数据集合;{ p1,p2,…,pr}为计算参数集合,通常为维度对应的已知量;{b1,b2,…,bs}为约束条件集合,一般为数据模型的筛选或过滤条件,实现了数据立方体之间的逻辑运算,整体框架如图2 所示。
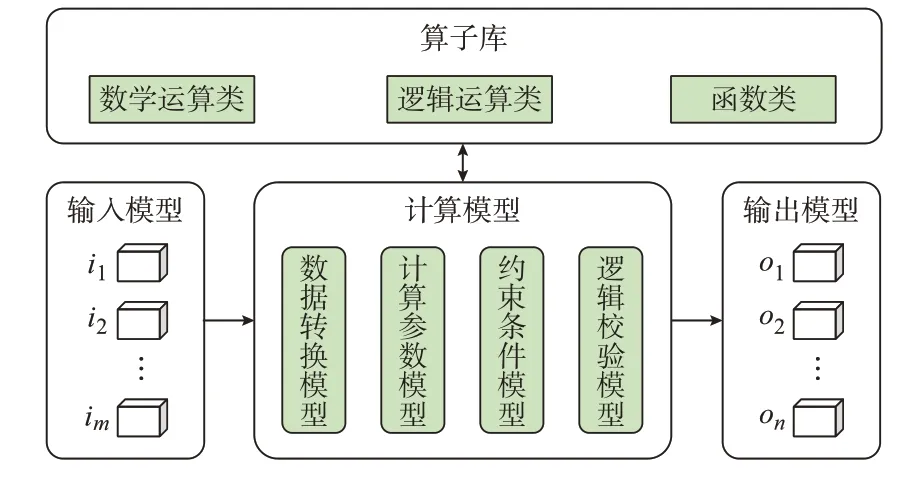
图2 基于算子库的多维数据立方体模型Fig.2 Operator base-based cube model of multidimensional data
计算模型f 引用算子实现数据立方体之间的逻辑运算,为集中管理算子集合,建立算子库实现统一管理与定义,具体见表1。同时可对基础算子进行扩展,通过算子之间的组合配置建立形成复合函数或复杂运算逻辑下的扩展算子。由于数据立方体和算子都采用了统一的元数据定义,因此可通过灵活定义的方式实现数据立方体之间的逻辑运算,并由此灵活支撑电能、辅助服务及不平衡费用等结算规则。

表1 算子库定义Table 1 Definition of operator base
3 构建列式数据仓
传统关系型数据库是2 维的数据结构,按行进行存储。为了提高访问性能,一般需要在主体、时间、科目数据列建立索引,对于复杂查询要占用更多的I/O 资源。即便采用读写分离以及分区分表等性能提升技术,一定程度上能缓解读写数据效率问题,但随着数据量的快速增长,限于关系数据库行存储的技术特性,数据库性能仍然不易稳定控制,必须配备足够的技术团队随时进行性能调优与应急处理,系统建设与后期维护的代价随之升高。因此,随着电力现货市场数据的快速膨胀与复杂度的不断提高,对于面向海量数据的清算计算,必须从技术方法上解决数据处理的性能瓶颈问题。
3.1 列式存储结构
列式数据库[27]是以数据列为单元进行数据存储的数据库,每个单元单独存储,其数据本身即是索引,减少了额外索引的空间开销。
将多维数据立方体模型中的维度和量度集合作为属性列按列存储。将机组、时间、科目、电量等分别作为独立的数据块依次进行存储。在查询时通过数据索引访问指定列,快速定位到某一数据块,提高检索效率,避免全表扫描,从而显著降低系统I/O。现货市场结算列存储结构如附录A 图A3 所示。
3.2 维度编码压缩法
为保证各省数据进行全网汇总时具有唯一性,需要采用较为复杂的编码体系,编码为位长相同、字符序列含义明确的字符串标识,在计算过程中为大幅减少磁盘占用空间,降低物理磁盘到内存的I/O传输量,提高系统访问性能,本文采用了数据压缩[28-29]方法,在列式数据库按列存储,在内部迭代计算过程中通过超短字段对长字段进行压缩替代,可以显著提升计算中的数据存储性能。
本文设计的多维数据立方体模型基于维度集合将常规业务数据转换为统一的立体数据结构,并且对维度数据进行编码,通过“原始值-编码值”的转换实现多维数据的压缩替代。维度编码压缩法结构如附录A 图A4 所示。
3.3 模型转换服务
模型转换服务是构建列式数据仓的基础,其核心是将源数据库中的分时计量结果、现货出清结果等立方体数据,转换为列式数据,并存储于列式数据仓中,以便于通过列式比对与列式计算实现快速清算。
模型工作台提供多维建模功能,为模型转换服务提供元数据管理,以实现模型转换灵活性。如图3 所示,首先进行维度和扩展子维度的定义,基于此,模型转换服务组合匹配源表,生成多维数据立方体模型,然后加载源表数据到模型中,并存储到列式数据仓中,最后根据维度编码压缩法进行数据压缩,实现数据聚合从而节省存储空间。
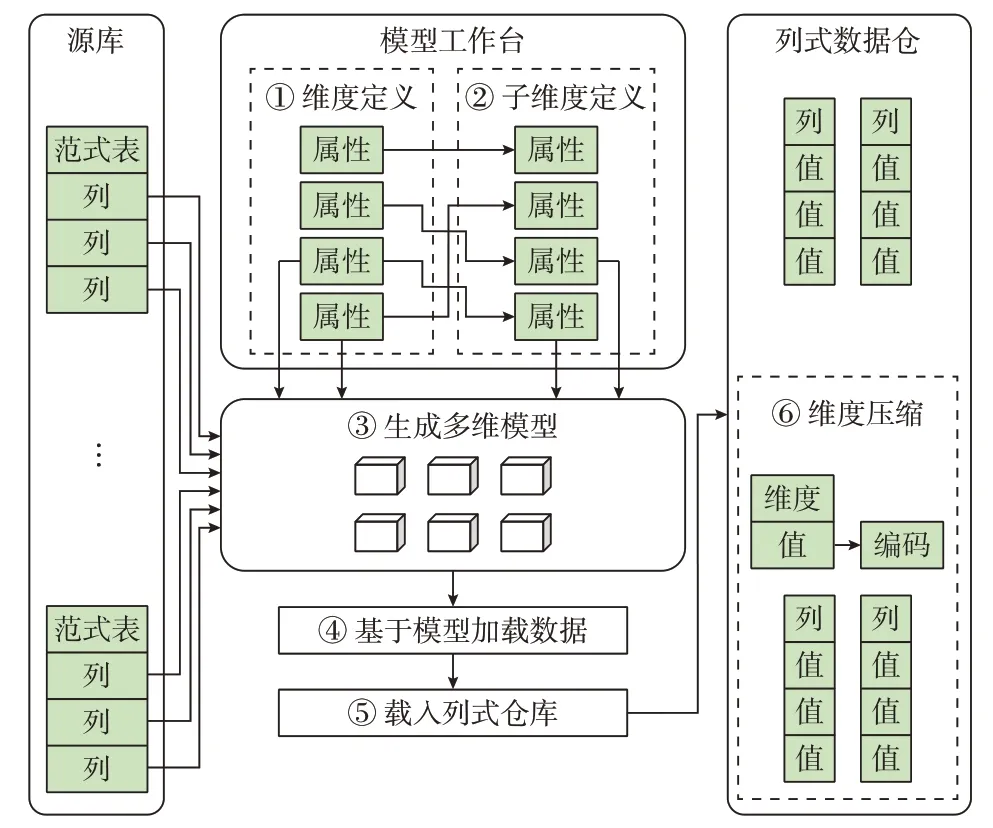
图3 模型转换服务示意图Fig.3 Schematic diagram of modeltransformation service
4 列式计算引擎
4.1 内存计算服务
内存计算技术[30-31]主要是将底层数据从硬盘整合后加载在内存中,利用内存数据的高速访问能力,实现清算快速计算。内存计算服务架构如附录A图A5 所示。
内存计算服务实现了基于列式内存的数据运算功能,其核心组件包括接口层、执行控制层、数据库引擎、持久层等。
1)接口层:提供外部对计算服务的访问接口,创建和管理连接和会话,并将请求传导到执行控制层。
2)执行控制层:对请求进行分析和执行,调用数据库引擎加载多维数据立方体,基于算子库运算聚合并输出逻辑结果。
3)数据库引擎:提供对数据的存储和读取,访问列式数据仓,基于多维模型按列加载数据到内存中。
4)持久层:提供了数据的安全性,定义数据卷(data volume)和恢复日志卷(log volume),服务运行过程中写入数据卷和恢复日志卷中。当系统重启时,可通过卷中数据还原到内存中,避免内存数据丢失。
4.2 清算计算与列式对比
使用列式数据仓,可利用列分块存储的特性,高效利用多维立方体数据模型,从而有效提高系统处理性能。
以某现货试点省日前电能市场结算规则为例,日前市场结算电费Rd为:
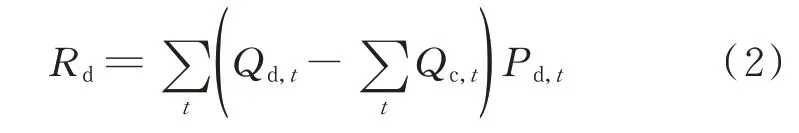
式 中:Qd,t为t 时 段 日 前 市 场 出 清 电 量;Qc,t为t 时 段合约电量;Pd,t为t 时段出清电价。
基于多维数据立方体模型和算子库模型,定义扩展算子如下。
1)定义合约电量求和汇总
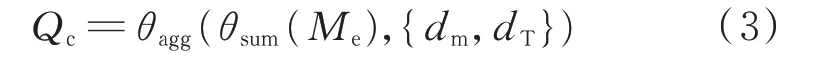
式中:Qc为合约电量合计值;θagg(⋅)为聚合函数,表示基于维度属性进行数学运算后的聚合;θsum(⋅)为求和函数;Me为电量量度属性且Me∈Cc,其中Cc为合约分解数据集;dm和dT分别为市场主体维度和时间维度。
2)定义电量求差并乘以价格
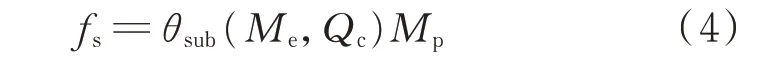
式中:Me∈Cd,其中Cd为日前出清数据立方体数据集;fs为乘积拓展函数;θsub(⋅)为求差函数;Mp为电价量度属性且Mp∈Cd。
3)以主体、时间循环处理得到结算结果
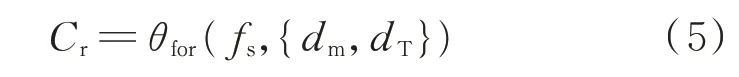
式中:Cr为日前市场结算结果数据;θfor(⋅)为基于约束条件进行迭代运算的函数。
在进行清算时,内存计算服务的执行控制层解析算法转换为索引指针,将索引指针代入列式数据仓中,即可快速检索相关业务数据并读入内存中,显著提升清算效率,如附录A 图A6 所示。
在追补清算计算完成后,再对清算结果数据和历史结算数据进行偏差对比,形成追补偏差数据。由于2 类数据的多维模型完全一致,在列式数据仓中,根据维度编码对2 类数据的结果列进行对比求差,不需要行式映射和逐条匹配,能够快速得到追补清算偏差结果。电力交易清算流程如附录A 图A7所示。本文方法有效利用了列式数据库的技术特征,较好地解决了清算计算性能问题。
5 基于统一数据模型的清算系统实现
以统一的多维数据立方体模型为基础,基于列式数据仓的内存计算引擎为核心软件,研发构建了一整套支撑灵活、复杂业务规则下的沙盒式清算系统。
清算系统首先将生产数据的数据资源、计算资源重载至沙盒隔离环境,然后通过模型转换将关系数据结构转换为统一多维立方体数据结构,再基于算子库建立基于立方体模型之间的计算逻辑,最后通过数据同步转换服务,将数据加载到列式数据仓,再通过内存计算引擎与列式比对计算,形成追补清算结果,整体功能架构如附录A 图A8 所示。
6 算例验证
选取中国山西2019 年12 月7 日现货试结算的实际数据作为算例进行验证。山西现货结算最小时间间隔为15 min,每日按96 点结算,品种包括基数、直接交易和外送等合约结算以及日前、实时等现货电能与不平衡费用分摊结算。参与现货市场的机组合计401 台,其中风电和光伏等新能源机组272 台,电力用户和售电公司合计215 个,参与现货市场的发用两侧市场主体总数为616 个。
以2019 年12 月10 日实际的现货试结算数据为例,选取其中10 台机组进行计量电量等数据修正,并进行当日的清算计算,其中包括6 台火电机组,4 台新能源机组,合计关口表计为22 个。其中,计算火电机组上网电量需要用到12 个主变压器高压侧表计电量,计算新能源机组上网电网需要用到该机组的发电量数据,10 台机组各有一笔基数合约,另有108 笔直接交易合约和6 笔外送合约。依据山西市场规则,机组启停补偿按次计算,中长期阻塞费用需要用到基数、直接交易和外送这3 类合约,合计124 笔。发用双轨偏差需要用到全市场的626 个市场成员的计量电量进行计算,分摊计算按日进行,其中的补偿费用、阻塞费用由发、用两侧同时分摊,双轨偏差费用由所有发电侧市场主体分摊,新能源日前预测偏差费用由新能源机组分摊,具体见表2。
基于上述实际案例数据,分别采用传统清算方法和本文提出的清算方法2 套系统进行对比,计算时间如表3 所示。
由表3 可知,相比于传统方法,文本所提计算方法可明显缩短计算时间,显著提高清算计算效率,在数据量逐步增加的情况下优势更为明显。
该方法在中国浙江2020 年5 月、8 月,中国山东2020 年12 月 以 及 山 西2020 年8 月、12 月 等 现 货 试结算清算中也都进行了实际应用,列式计算虽然会产生业务库到列式库之间结构转换的门槛时间,但在转换后可直接进行多列之间的偏差计算,省去更多的数据检索与匹配时间,从而显著提升计算效率。该方法还可在清算数据与原始数据之间进行隔离,既可以保障数据安全,也可以方便实现二次清算甚至多次清算。另外,利用算子库进行数据转换的方法来实现清算计算,不仅适用于4.2 节中提到的结算公式,对于其他市场的计算规则也均可通过算子组合配置来实现,使得系统在灵活性等方面,也明显优于传统清算方法。
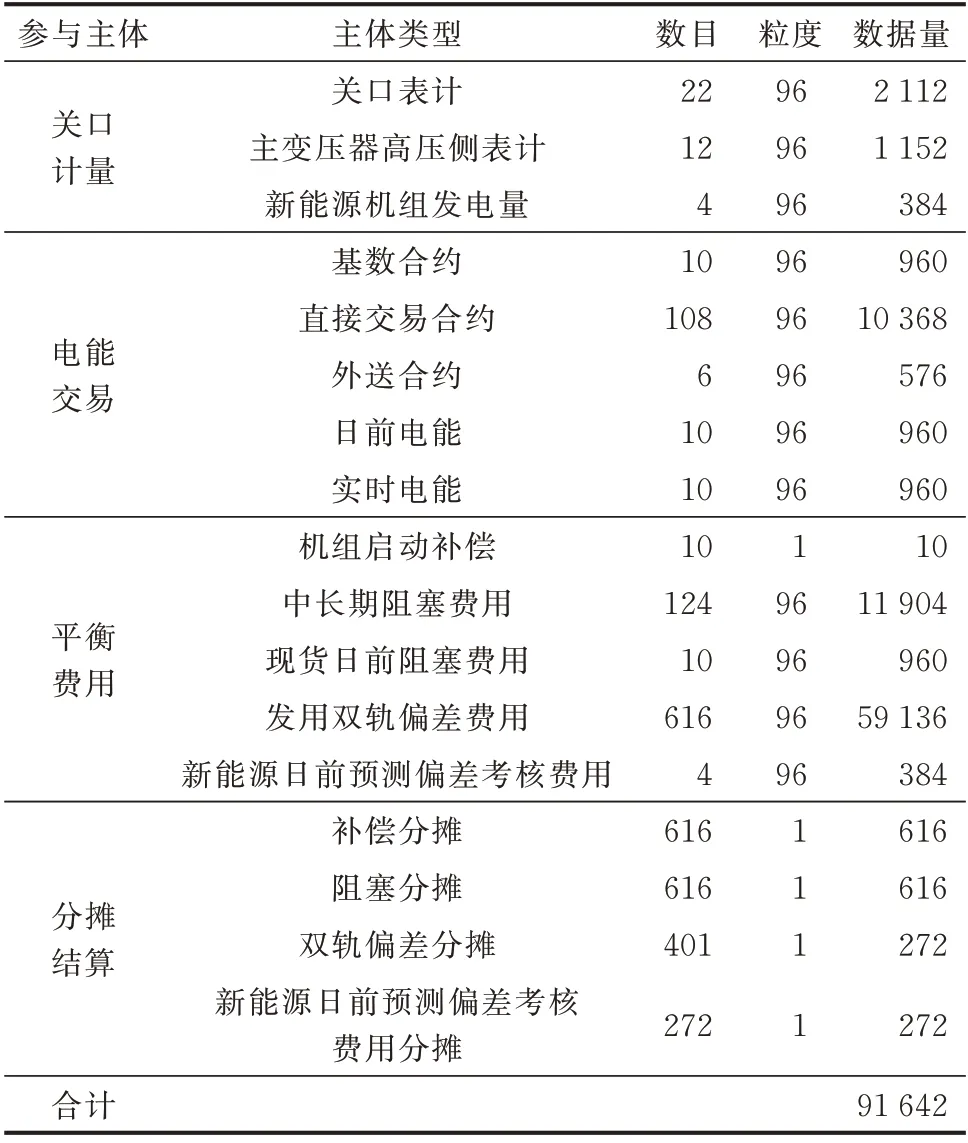
表2 市场清算数据案例Table 2 Data case of market clearing

表3 不同清算方法的计算时间对比Table 3 Comparison of calculation time of different clearing methods
7 结语
本文提出了基于统一数据模型的沙盒式清算方法,在浙江、山西、山东等电力现货市场试点单位的清算系统中进行了工程应用。所提方法对电力交易领域的复杂业务维度进行统一建模,构建形成了标准化的数据立方体,并进一步基于算子库实现了多类数据立方体之间的数据转化,最后通过列式计算与列式对比,实现了高性能清算计算。清算系统采用沙盒技术,保障业务系统和生产数据的环境隔离与数据安全。经实际应用,证明了该方法能够适应电力现货市场下业务规则复杂性与灵活多变,同时显著提升系统清算计算性能,大幅降低系统后期运维成本,并为支撑电力现货市场的常态化清算业务提供可靠保障。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
猜你喜欢
学苑创造·A版(2022年6期)2022-06-20
证券法律评论(2019年0期)2019-07-24
网络安全和信息化(2019年5期)2019-06-04
读者(2018年15期)2018-07-18
教师·下(2017年10期)2017-12-10
中学生天地(A版)(2017年6期)2017-06-23
读写算·小学低年级(2017年1期)2017-02-06
信息安全与通信保密(2016年3期)2016-08-23
太空探索(2016年9期)2016-07-12
小学生导刊(低年级)(2016年6期)2016-07-02
