
基于开源处理器Rocket 的异构SoC 设计与验证
2021-03-29 06:31:24高营,刘德,鞠虎
电子与封装 2021年3期
高 营,刘 德,鞠 虎
(中科芯集成电路有限公司,江苏无锡 214072)
1 引言
图像处理技术的快速发展使卷积神经网络(CNN)算法得到广泛应用[1]。CNN 隐层数的增加需要硬件处理器具备更高的运算性能。当前,为加速神经网络的计算主要采用GPU 或者专用硬件加速器的方法来缓解卷积运算的压力[2]。由此,CPU 外加运算加速器的异构片上系统(SoC)是目前主要的研究热点之一。本文设计了激活函数(ReLU)和向量点积运算(VDP)硬件加速器,同开源处理器Rocket core、开源外设项目Si-Five Blocks 搭建成一个精简的异构SoC。该异构SoC 通过编译软件程序在FPGA 平台上的演示,在一定程度上表明了对CNN 加速的应用研究价值。
2 系统架构
异构SoC 的系统架构主要由Rocket core、ITCM、DTCM、SoC 总线、BootRom、SPI、UART、ReLU 协处理器和VDP 协处理器等部分构成,具体结构如图1 所示。
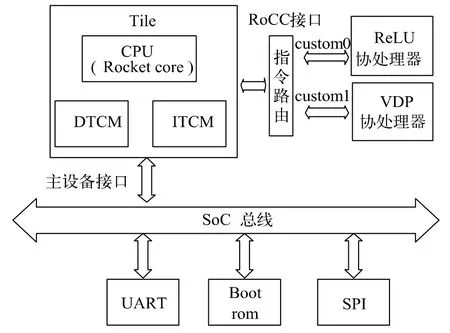
图1 系统结构
内存的映射关系如表1 所示。
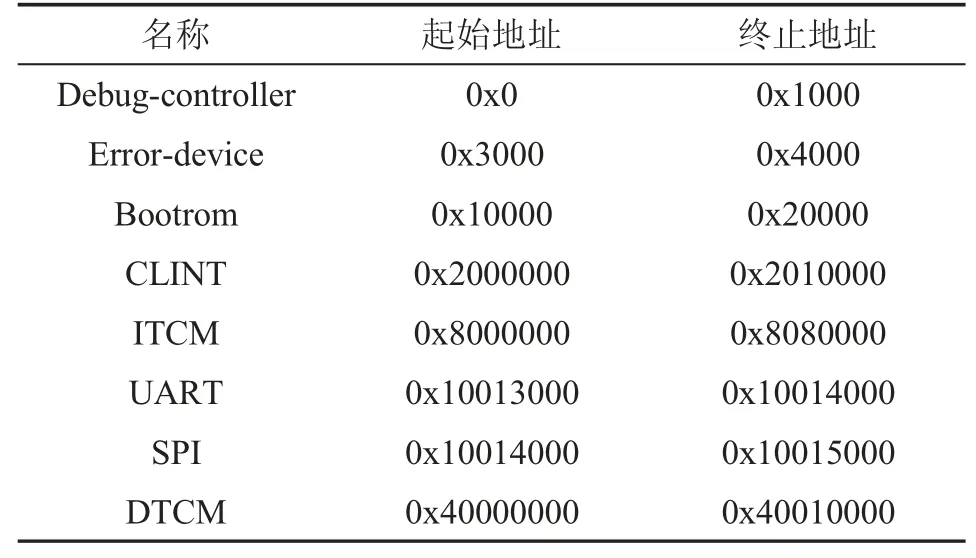
表1 内存映射
Si-Five Blocks 中通用外设 UART、SPI 等不再详细介绍,以下主要介绍两个加速器模块:ReLU 激活函数协处理器和VDP 协处理器。
2.1 ReLU 激活函数协处理器
CNN 隐层主要包含卷积层、激活函数、池化层以及全连接层[3]。其中激活函数作为增加神经网络模型非线性的手段,在算法中起到十分重要的作用[4]。当前常用的激活函数有sigmoid 和ReLU 激活函数。相对于sigmoid 激活函数计算量较大、收敛速度慢的问题,ReLU 激活函数只需判断输入是否大于零,计算量较小、收敛速度快且更符合生物学的神经激活机制[5],其表达式如下:

可以看出ReLU 激活函数为求最大值函数,x 小于0 时函数值为0,大于0 时函数值为x 本身,具体函数如图2 所示。
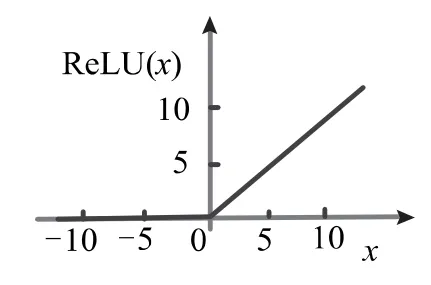
图2 ReLU 函数
ReLU 协处理器是以RoCC 接口协议与Rocket core 进行连接。RoCC 基本接口包括与处理器传递状态的CC(Core Control)接口,与一级数据缓存器(L1 DCache)传递数据的MEM 接口,以及与处理器传递指令的Core 接口;此外,还包含扩展接口:处理器获取协处理器状态信息的CSR 接口,协处理器与浮点运算单元(FPU)通信的接口,协处理器与页表查找模块(PTW)通信的接口。上述接口中,ReLU 加速器仅用到Core 接口、MEM 接口以及CC 接口,具体应用如图3所示。
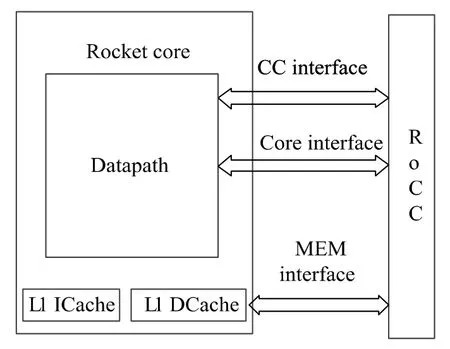
图3 RoCC 接口结构
Rocket core 判断是协处理器指令即ReLU 激活函数指令relui 后,通过Core 接口将该指令relui 发送到协处理器的译码控制单元。relui 指令格式如下:
custom0 rd,rs1,rs2,funct
custom0 为使用Rocket core 中RoCC 的首个接口(Rocket core 中默认实现了3 个自定义指令:custom0、custom1、custom2[6]),rd 为目标寄存器,rs1 和rs2 为源寄存器,funct 为额外的编码空间,便于实现更多的指令(funct 为指令的25~31 位,因此可以编码出128 条指令)。协处理器在计算完成后,将计算结果写回指定地址中断CPU,不再通过目的寄存器返回,因此rd 为零。rs1 和rs2 源寄存器的数据格式如表2 所示,表中rsltAddr 为存放计算结果数据的起始地址,srcAddr 为存放源向量的起始地址,vctSize 表示向量的大小。

表2 relui 源寄存器数据格式
ReLU 协处理器设计结构如图4 所示,主要由译码控制单元和比较器构成,图中输入、输出信号的定义如表3 所示。
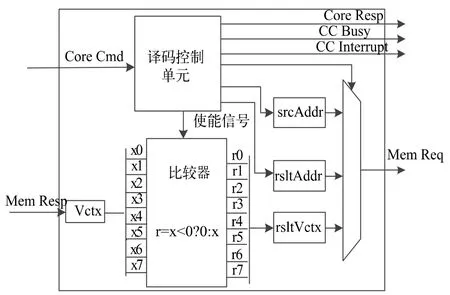
图4 ReLU 协处理器结构
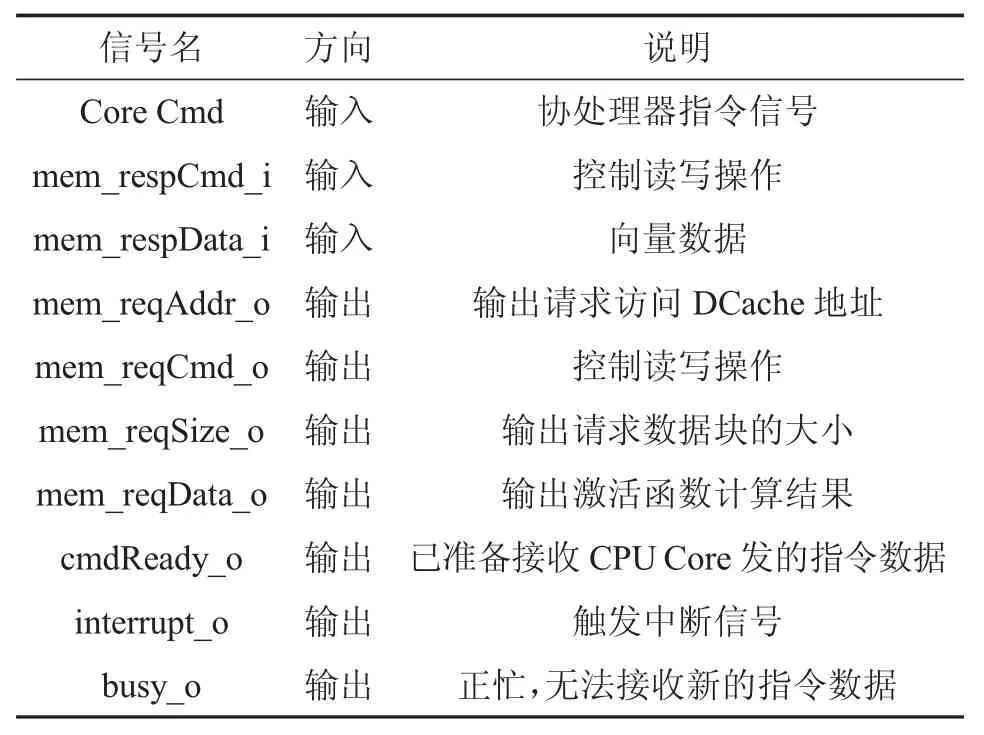
表3 ReLU 协处理器输入输出信号
表3 中Core Cmd 即为relui 指令格式,包含执行操作和数据。mem_resp、mem_req 为DCache 和 ReLU协处理器耦合接口(具体方式为RoCC 接口,此处不再详述)。ReLU 协处理器工作流程如下:
接收到Rocket Core 发送过来的指令后,由协处理器译码控制单元解析自定义指令(Core Cmd)中的操作和源寄存器rs1 和rs2 中的数据,然后通过mem_respCmd_i 进行控制读写DCache 中的向量。每次从DCache 读取8 个字节向量存放于vctx 中,每个字节看作一个有符号的8 位定点数输入比较器。比较器判断输入的数是否大于零,如果小于零则输出零,大于零则输出数本身(ReLU 激活函数见图2)。做完比较操作后,协处理器将计算数据结果写回到指定地址位置,并根据rs2 源寄存器中vctSize 向量长度进行下一轮的计算操作。当完成所有的向量计算后,协处理器向Rocket core 发送一个中断信号以便CPU 读取计算结果。
2.2 VDP 协处理器
卷积神经网络中最多的计算是卷积运算。加快卷积运算速度是提高卷积神经网络计算的有效方式[7]。卷积运算的伪代码(其中矩阵A 和B 均为m 行m 列)如下:

由上述卷积运算的伪代码看出,可以将卷积运算分解成向量的内积(点乘)运算。卷积运算每次的计算均需要执行m2次乘法以及m2次加法。因此,卷积运算的计算复杂度为m2。将卷积分解成向量内积运算后,能够增加运算的并行度,从而取得加速卷积运算效果[8]。
VDP 协处理器与CPU 的连接方式同ReLU 一样,以RoCC 接口协议挂载到Rocket Core 上,vdpi 指令格式如下:
Custom1 rd,rs1,rs2,funct
Custom1 为使用 Rocket core 中 RoCC 的第二个接口,rd、rs1 和rs2 代表的意义同ReLU,这里不再赘述。VDP 协处理器也不需要将结果写回寄存器,因此rd 为0。rs1 和rs2 为源寄存器,数据格式如表4 所示,表中vctxAddr 和vctyAdd 分别表示向量x 的地址和向量y 的地址(该地址为协处理器内部存储地址),vctSize 为向量的大小,prdctAddr 为存放向量内积计算结果的地址(该地址为DCache 中的地址)。
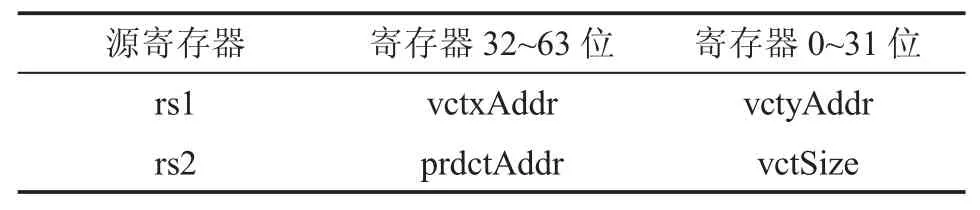
表4 vdpi 源寄存器数据格式
VDP 协处理器主要由译码控制单元、8 位有符号乘法单元和8 位加法器构成,具体结构如图5 所示。
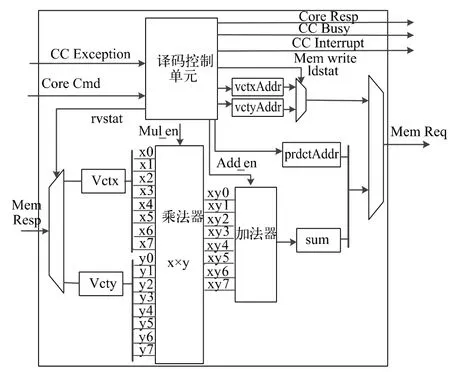
图5 VDP 协处理器结构
运算流程如下:Rocket Core 解析指令为Custom1,将 Cmd 指令发送给 VDP 协处理器。VDP 译码控制单元解析Cmd 中rs1 和rs2 源寄存器的数据,然后从Mem 接口中读取向量x 和向量y。一次读取8个字节的数据,每个字节看作一个有符号的8 位定点数,输入到8 位有符号的乘法运算单元,然后将对应相乘的8 个积累加到sum 中得到两个向量的内积。根据rs2 源寄存器中vctSize 向量长度来判断下一轮的状态,未完成时进行下一轮读取计算;如果判断两个向量的点积计算完成,则通过RoCC 的Mem 端口将计算数据写到DCache 的指定地址,并根据Cmd 指令决定是否发送中断给处理器。
3 FPGA 原型验证
为检测协处理器功能以及加速性能指标,在VC707 FPGA 平台上进行原型验证[9]。测试程序通过串口UART 获取上位机(PC 机中的串口助手)发送过来的指令或者数据。当处理器接收到指令并译码之后,判断这条指令是否为协处理器指令,若为协处理器自定义指令,便将指令发送给ReLU 激活函数处理单元或者VDP 加速器单元,当完成计算之后,将结果再通过串口反馈到上位机中。原型验证如图6 所示。
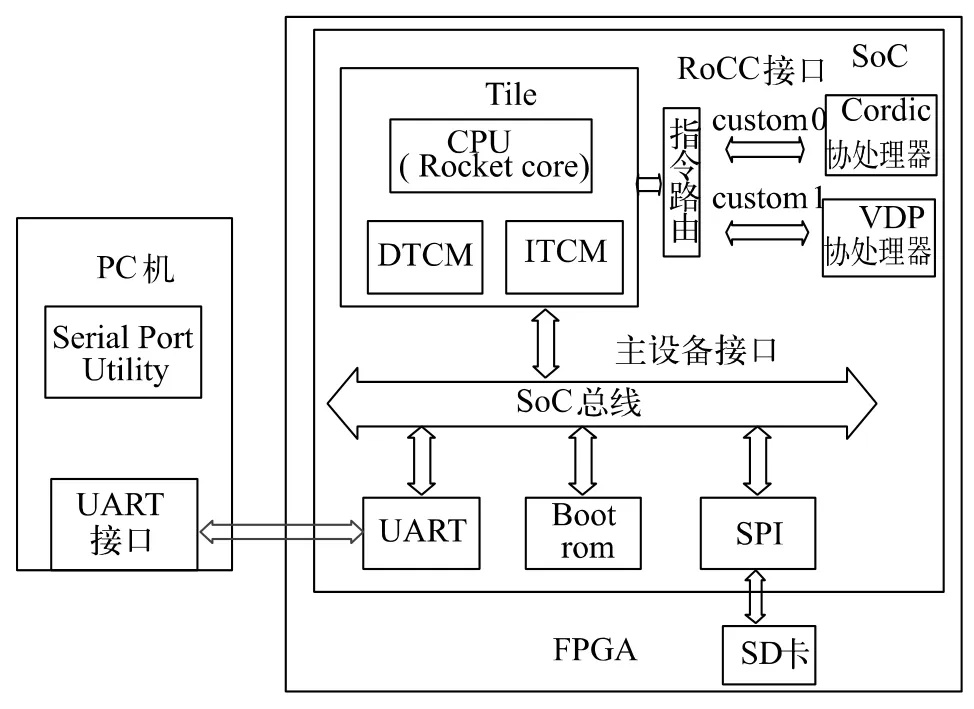
图6 FPGA 原型验证平台
为更好地体现硬件加速器的加速效果,ReLU 激活函数分别用CPU 和硬件加速单元运算同一向量,来对比计算所需的时间;而向量内积则通过计算同一矩阵,来进行计算性能对比。ReLU 和VDP 加速单元均为协处理器,硬件加速需调用协处理器专用指令,具体的指令格式前文已给出,这里不再赘述。CPU 计算ReLU 激活函数的伪代码如下:

其中m 为向量的长度,data 为计算前的向量数据,data_relu 为计算后的向量数据。CPU 计算向量内积的代码如前文卷积计算的伪代码,此处不再赘述。串口输出的结果如图7 所示。
ReLU 输入的值为-10~14,VDP 的输入向量 A 为0~63 即(0,1,…,62,63),求得向量内积为 A·A。由图7 可以看出,软硬件在功能上均实现了ReLU 和VDP计算。FPGA 原型验证采用的输入时钟为50 MHz,由此 CPU(Rocket core 性能参数为 5 级流水线、64 位、单发射顺序执行的处理器)的运行周期为1/(50×106)s。图7 中串口输出的消耗时间值即为运行的CPU 周期数,可以得出软硬件的执行效率如表5 所示(表中同时给出了其他向量长度的运算结果,由于数据过大不利于串口显示且限于篇幅没有给出串口截图),由表中的数据可以看出,针对于卷积神经网络中的激活函数和卷积运算,ReLU 加速器和VDP 加速器相比于CPU运算均具有不错的加速效果,且随着向量长度的增加,加速效果越来越明显。

图7 验证串口输出
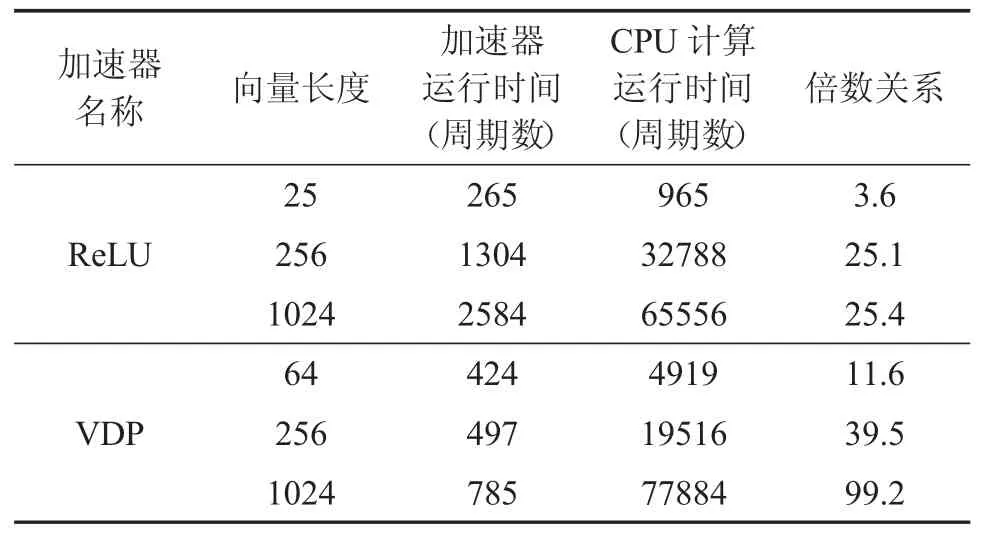
表5 运算结果对比
4 结论
本文基于开源处理器Rocket、开源项目Si-Five Blocks 添加了激活函数ReLU 加速器和VDP 加速器,搭建了简易的异构SoC。通过FPGA 原型验证表明,相比于CPU 的运算,ReLU 和VDP 协处理加速器能够在一定程度上增加卷积神经网络的运算。协处理器与CPU 紧密耦合通信消耗较小,具有很强的灵活性,因此不限应用于加速卷积神经网络的计算,可适用于对连续地址空间非突发传输访存的任何具体应用。开源处理器Rocket core 默认含有3 个协处理器接口,易于对于异构SoC 的设计和研究。
猜你喜欢
故事作文·高年级(2024年5期)2024-06-04 23:39:22
高中数理化(2024年8期)2024-04-24 16:58:14
少先队活动(2021年6期)2021-07-22 08:44:24
科学与财富(2021年4期)2021-03-08 10:14:32
计算机应用(2020年5期)2020-06-07 07:06:44
科学与财富(2020年34期)2020-03-11 18:58:06
软件导刊(2018年3期)2018-03-26 02:14:46
单片机与嵌入式系统应用(2017年7期)2017-07-31 21:57:23
少年博览·小学低年级(2016年5期)2016-05-14 11:59:03
网络安全与数据管理(2011年24期)2011-08-08 02:31:52
