
基于B/S架构的超滤膜污染预测系统设计与实现
2021-03-29 05:41钱晨徐忻嵇达文
石油化工自动化 2021年2期
钱晨,徐忻,嵇达文
(光大环境科技(中国)有限公司,江苏 南京 210003)
在垃圾渗滤液处理中,膜污染已成为影响膜系统运行效率的重要因素,引起人们广泛的关注。目前很多研究者开展了有关膜污染防治、膜处理工艺和膜处理效果等方面的研究,并取得了实质性的进展。刘研萍等人对垃圾渗滤液处理项目进行了研究,从预处理、膜污染结构与形态、膜清洗等方面,探讨了膜污染的防治措施并取得了阶段性的成果[1];迟军永等人分析了膜污染的形成,并提出了判断清洗时机和评价清洗效果的方法,对超滤膜在渗滤液处理中的应用有一定的指导意义[2];罗丹等人论述了膜分离技术在垃圾渗滤液处理中的应用,并发现膜污染是阻碍其发展的主要原因,为此提出研发新材料,优化膜工艺才能使膜技术更好的为垃圾渗滤液处理服务[3]。由上述研究现状总结可见,对垃圾渗滤液膜污染的研究主要偏向于对膜污染的治理、膜工艺的改进和优化方面,而对膜处理过程中的自动化、信息化和智能化问题鲜有涉足。在该背景下,本文提出了评估超滤膜污染状况的方法并据此设计了一套系统,该系统基于浏览器/服务器(B/S)模式并结合神经网络算法以及当前主流的前后端框架,以网页形式展示预测结果,并以此为依据及时对膜进行清洗,从而提高超滤处理过程的效率。
1 算法设计
根据历史工况数据预测超滤膜污染情况,首先要获取超滤处理过程的历史数据,但由于现场很多情况下超滤循环泵都是满负荷运行,导致历史工况数据较为单一,直接使用这些数据建模可能会导致效果不佳,因此需要进行一段时间的实验来获取不同工况下的数据。实验中通过对超滤过程进行固定时间间隔取样,获取其中涉及的相关量并以此为依据选取距离上一次的清洗时间、COD值、氨氮比、污泥浓度、进水流量、温度、进水压力、产水流量、浓水压力作为样本。算法模型设计流程分三个部分。
1.1 对原始数据进行预处理
根据实际工艺,考虑到现场没有安装出水压力测量装置,因此只能根据原理得出超滤膜出水压力等于进水压力减去浓水压力,进而计算出超滤膜压差等于进水压力与出水压力的差值。再选取实验过程中运行最好的工况作为初始状态,对应的膜压差和膜通量作为初始膜压差和初始膜通量,并结合理论推导出膜污染指数公式[4]如式(1)所示:
(1)
式中:FI——膜污染指数,m2/L;J0——初始膜通量,L/(m2·h);J——膜通量,L/(m2·h);p0——初始膜压差,Pa;p——膜压差,Pa;Vsp——单位面积膜的产水量,L/m2。
在实验过程中难免会出现数据采集中断、人为误操作和仪器仪表故障等客观原因导致数据缺失,目前最常用的缺失值处理办法是删除法和填补法,其中填补法又包括替代法和模型预测法。模型预测法包含回归、灰度理论、极大似然估计、移动平均等算法[5-6]。根据现场实验情况发现超滤进水水质变化有一定的规律性,因此本文采用回归填补法,尽可能不失真地还原缺失数据。
除此之外,还考虑到仪器故障、系统采集信号延迟和网络丢包等因素造成的数据异常,目前对异常值的处理办法主要包括: 删除异常值、将异常值视为缺失值、用平均值修正等[5-8]。本文采用将异常值视为缺失值的方法。
1.2 采用预处理后的数据集训练神经网络模型
首先将预处理后的数据集划分成训练集和测试集;然后采用训练集对神经网络模型训练,同时利用测试集评估建立的模型[9]。反复执行上述步骤,优化模型参数以获取最优模型。本文在模型训练中采用梯度下降法[10],如式(2)所示:
(2)
式中:α——步长;θ——求解的待定系数;J(θ)——θ方差最小的损失函数。
本文通过采样时间内的数据训练得到3层神经网络模型如图1所示,输入层节点数为6,输出层节点数为1,隐藏层节点数为7。除输入层外,每一层的节点都包含了1个非线性Sigmoid变换[11],该变换呈现单增性,且可以将任何实数映射到0,1之间,但该模型需要根据具体工艺和具体采样时间更新模型参数以适应工况的变化。
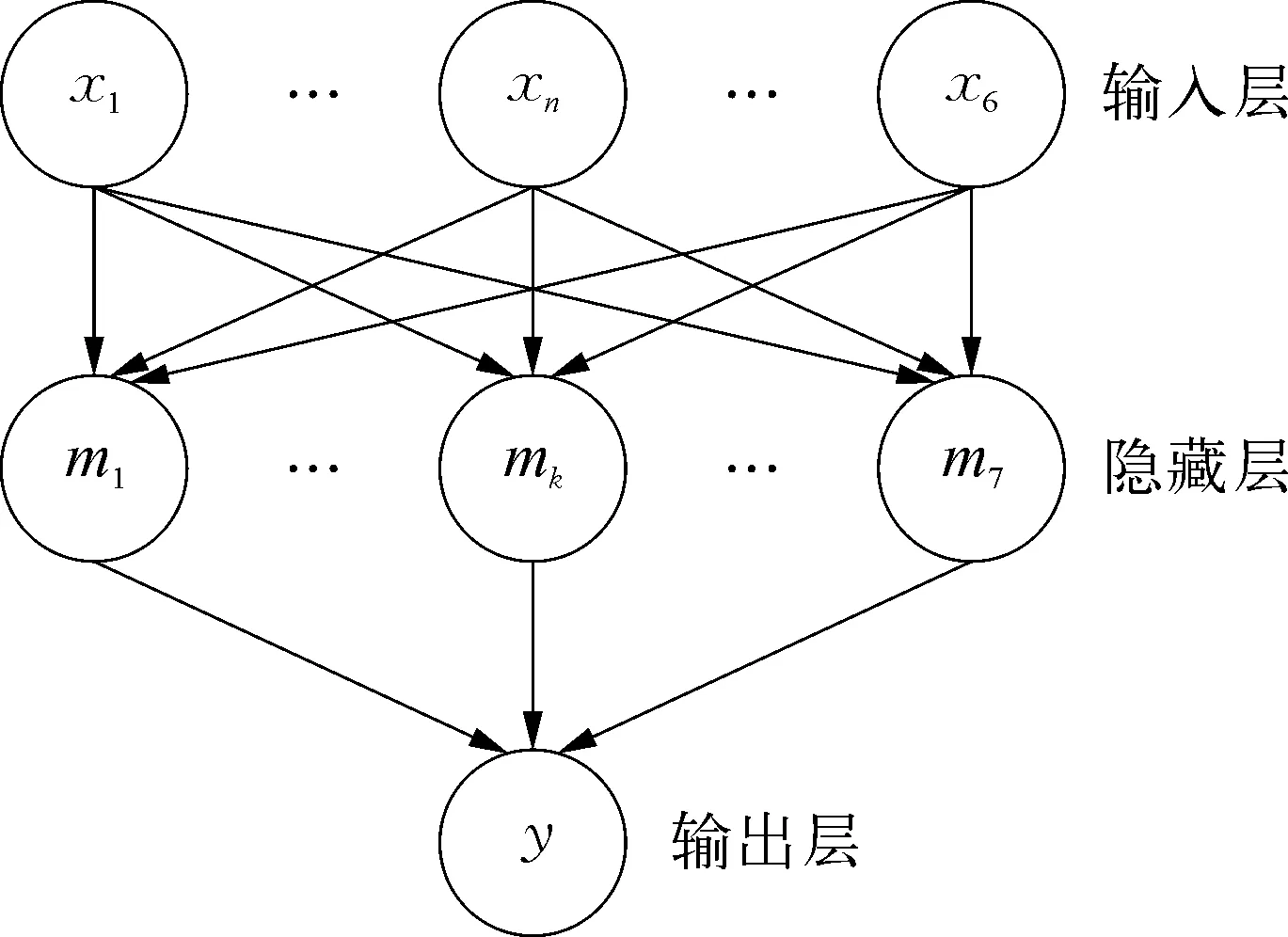
图1 神经网络模型示意
1.3 基于获得的神经网络模型预测膜污染
获取输入参数的最新数据输入神经网络模型中进行运算,产生唯一的输出用于预测超滤膜污染情况。
2 系统设计
该系统采用B/S模式,在该种模式下,用户通过浏览器发出请求,服务器对用户的请求作出响应。浏览器只负责将结果对外展示,而主要的事务逻辑均放在服务端统一完成[12]。B/S架构通常分为3层[13]: 第1层为表现层,只负责前端页面展示;第2层为业务逻辑层,起到承上启下的作用,向上接收前端用户请求,将逻辑处理后的结果返回给表现层,向下既要调用数据库访问层的接口,又要接收访问数据库返回的结果;第3层为数据访问层,负责对数据库进行增、删、改、查操作。
该系统以Linux操作系统为平台,以IntelliJ IDEA为Java语言开发工具。采用前后端分离的开发模式,模块化编程,前后端并行开发提升效率。系统架构如图2所示,其有四个部分: 前端、后端、数据库以及算法实现部分。其中前端由Jquery框架、BootStrap框架、ACE框架以及HighCharts框架构成,实现了Web页面的响应式布局、局部刷新和模块化展示。后端开发是以JDK8为开发工具包,使用SSM整合框架,并引入Shiro作为后端的安全框架进行身份认证和会话管理[14]。数据库采用MySql开源关系型数据库,以事务管理的方式保证数据存储的安全性和可靠性,同时采用目前性能较佳的数据库连接池技术druid,合理地配置数据库连接资源,提高数据库操作的性能。算法实现部分采用PyCharm集成开发工具编写Python脚本,以Json数据格式返回结果并写入数据库中。整个系统的管理采用Apache Maven工具,用于管理项目依赖的jar包、编译、文档及维护整个项目的生命周期(project lifecycle)。
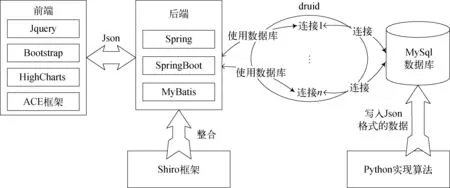
图2 系统架构示意
3 系统实现
由图2可知,按功能把系统分为登录模块、算法模块和Web展示模块。登录模块通过SpringBoot整合Shiro完成用户身份认证和会话管理。身份认证采用Shiro的过滤器设置过滤链表,使所有用户只有成功登录后才能访问主页,否则被拦截。会话管理是通过创建由Shiro统一管理的Session对象实现,每次http请求都会携带SessionID以保证同一会话,一旦Session过期失效,用户需要重新登录开启新的会话,否则用户发起的任何请求都会强制跳转到登录页。
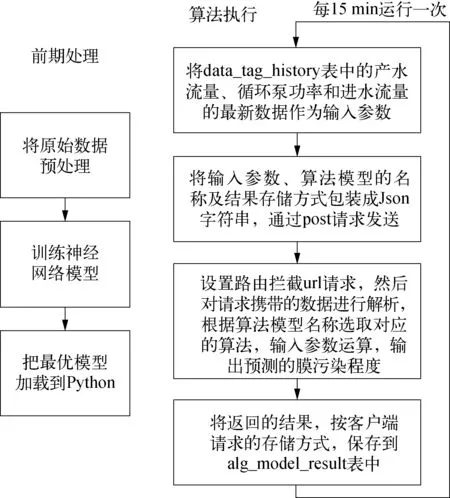
图3 算法模块执行流程示意
算法模块执行流程如图3所示。
该流程分为前期处理和算法执行两部分,其中算法执行部分采用Python语言实现,通过Crontab脚本将Python程序加入Linux定时任务列表循环执行,源源不断地将算法输出结果存入数据库,实现按时预测膜污染指数的功能。
Web模块执行流程如图4所示。
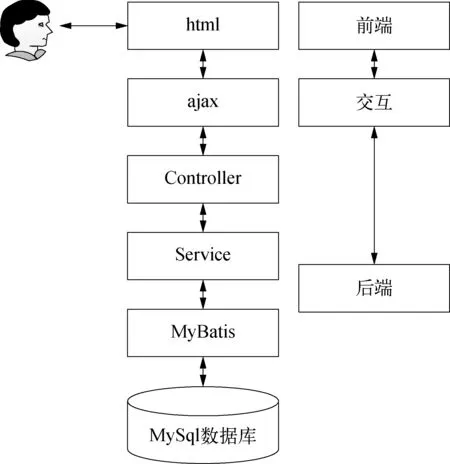
图4 Web模块执行流程示意
Web展示模块基于传统MVC模式,采用SSM轻量级复合框架搭建后端业务平台,通过灵活地使用Jquery,BootStrap和HighCharts框架对前端页面进行快速简洁地开发,同时合理地选用前后端衔接技术有效地降低系统的耦合度,提高代码的可复用性。由图4可知,点击膜污染指数评估菜单,通过ajax的GET方式发起异步请求,请求对应Restful风格的url: "optimization/mog1PollutionData/"+startTime+"/"+endTime。位于后端的DispatcherServlet接收到请求并进行解析,找到与之匹配的@RequestMapping("/optimization")控制器类后,进一步窄化请求找到与@GetMapping(value="/mog1PollutionData/{startTime}/{endTime}")对应的Restful方法。方法中通过@PathVariable("")注解得到startTime和endTime并把它们作为实参传入Service对象的业务处理函数selectByModelIdandName(),通过在该函数中注入Mapper代理对象,调用其接口函数从数据库中查询到前12 h膜污染指数的预测结果,进而向上返回到Service层再到Controller层,最后成功地返回给ajax请求的异步函数,并结合Highcharts图表框架对前端页面进行局部渲染,同时通过BootStrap响应式栅格系统优化页面布局,使其结构清晰层次分明。
4 系统运用
该系统在光大环保能源公司渗滤液处理站部署以来运行效果良好,前12 h膜污染指数预测曲线如图5所示。
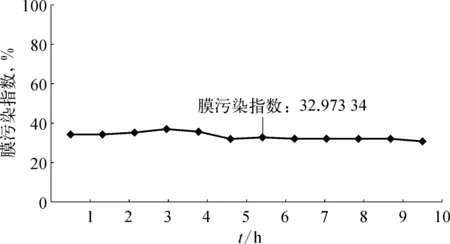
图5 膜污染指数预测曲线示意(2020-01-10)
由图5可知,由于短时间内膜污染程度变化不大,因此只展示出每小时的预测结果,通过这些数据操作人员便可直观地了解超滤膜污染情况,提前对膜进行处理,改善超滤产水水质,确保反渗透的正常运行。除此之外,还可以点击“实时推荐”按钮,系统立即执行算法预测出超滤循环泵推荐功率、超滤膜污染指数预测值及预期产水量,为现场技术人员及时决策提供了参考。以2020年1月10日某时刻为例,按下“实时推荐”按钮后,推荐功率为28.2 kw,膜污染指数为38.7%,预期产水量为6.1 L/m2。
5 结束语
本文基于B/S模式并结合神经网络模型,采用当前主流的前后端框架和Python智能化语言,开发了超滤膜污染情况预测系统,该系统通过登录模块、算法模块和Web展示模块为用户提供了身份认证、预测分析以及结果查询等功能,并且具有界面友好、操作简单和便于维护等优势。将该系统应用于光大环保能源公司项目中,为现场操作人员准确判断膜清洗的时机提供了依据,对推动渗滤液处理信息化有一定的现实意义。
猜你喜欢
资源节约与环保(2022年8期)2022-09-20
现代电力(2022年2期)2022-05-23
能源工程(2021年3期)2021-08-05
环境卫生工程(2021年3期)2021-07-21
环境卫生工程(2021年1期)2021-03-19
环境卫生工程(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
建材发展导向(2019年5期)2019-09-09
电子制作(2019年24期)2019-02-23
海军航空大学学报(2015年4期)2015-02-27
