
基于改进U-Net的视盘视杯分割方法的研究
2021-03-29 02:52江旻珊
光学仪器 2021年1期
茅 前,江旻珊,魏 静
(上海理工大学 光电信息与计算机工程学院,上海 200093)
引 言
杯盘比是指眼底的视盘和视杯两者垂直高度的比,可以通过对眼底图像的视盘和视杯的分割计算获得。杯盘比是判断青光眼的重要参考指标,目前杯盘比通常是由眼科医生依靠多年的经验并通过观察彩色眼底照片获得。然而,人工观测存在诸多的缺点,如需要有丰富的专业知识,判断的一致性差,无法进行客观定量的分析等。因此,为了提高青光眼筛查和诊断的效率,本文开展了计算机辅助青光眼智能诊断方法的研究。
在研究中我们采用了一个基于U-Net改进的算法来分割视盘和视杯,以此进一步提高算法对于视杯和视盘的准确分割。与现有的一些算法相比,我们所提出的方法在分割结果上能够取得一定的提高。
1 视盘视杯图像分割原理
1.1 数据集来源
本文视盘视杯分割采用了一个公开数据集和一个非公开数据集,分别为来自上海市第一人民医院的彩色眼底照片以及DRISHTI-GS数据集[1]中的彩色眼底照片。其中,非公开数据中包含了300张彩色眼底照片,而DRISHTI-GS数据集包括了101张彩色眼底照片,彩色眼底照片的分辨率为2 896×1 944。
1.2 图像处理方法
在使用神经网络进行学习时,为了保证网络的学习效率以及得到更高的准确率,实验前先对输入网络的图像进行预处理。首先,针对对比度弱的彩色眼底图像,使用限制对比度自适应直方图均衡(CLAHE)技术,该技术是将每个图像切割成8×8的64块,并且对每一块使用直方图均衡化处理。其次,调整图片大小,将输入的图片调整为512×512。再次,采用数据扩增技术将训练集中的图像进行翻转、平移、旋转等操作,使得训练集中的数据量扩大,防止在训练中出现过拟合、数据不平衡等现象。最后,将训练集中的彩色眼底照片和标签融合至同一张图片,如图1所示,确保彩色眼底照片与标签一一对应。
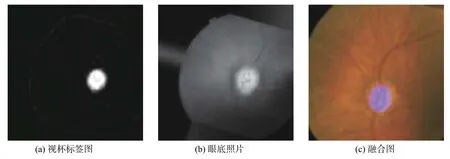
图 1 训练图片与标签相融合Fig. 1 Merge of the label and training image
1.3 网络结构
本文基于传统U-Net网络架构[2]提出了一种改进型的U-Net网络架构。该架构包含了残差块,同时采用了卷积、池化等操作,原始的和改进的U-Net网络结构如图2、图3所示。
图中,每一个长矩形对应着一个图像或者是图像的特征图,长矩形中的数字代表着图像的像素,各种颜色的箭头代表着不同的卷积、反卷积以及池化等操作。在本文所改进的网络中,原始U-Net中的下采样部分被残差块所代替[3]。此外,我们还对网络的跳跃连接做了改进,将原始U-Net中的跳跃连接使用一个3×3的卷积层和一个1×1的卷积层所代替。改进后的跳层连接能够让下采样部分的特征信息更加充分地融合至上采样部分,使得网络获得多种维度的图像特征信息,帮助提高网络的分割结果,图4为本文所采用的跳跃连接。网络中所使用的损失函数为二元交叉熵损失函数,其表达式为
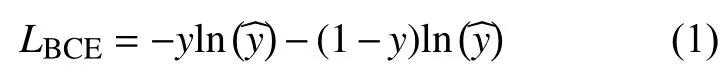
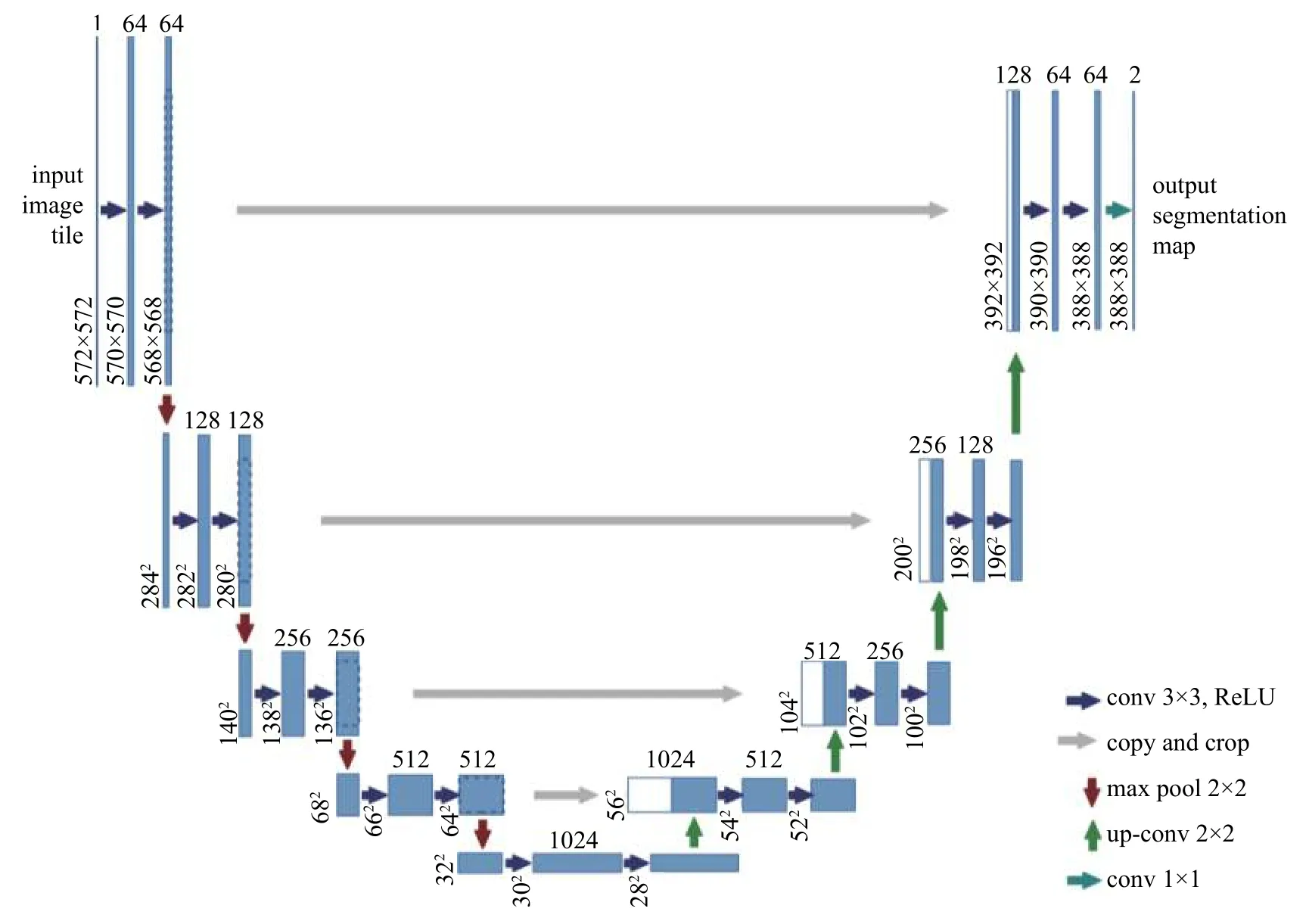
图 2 原始 U-Net的网络结构图Fig. 2 Original U-Net
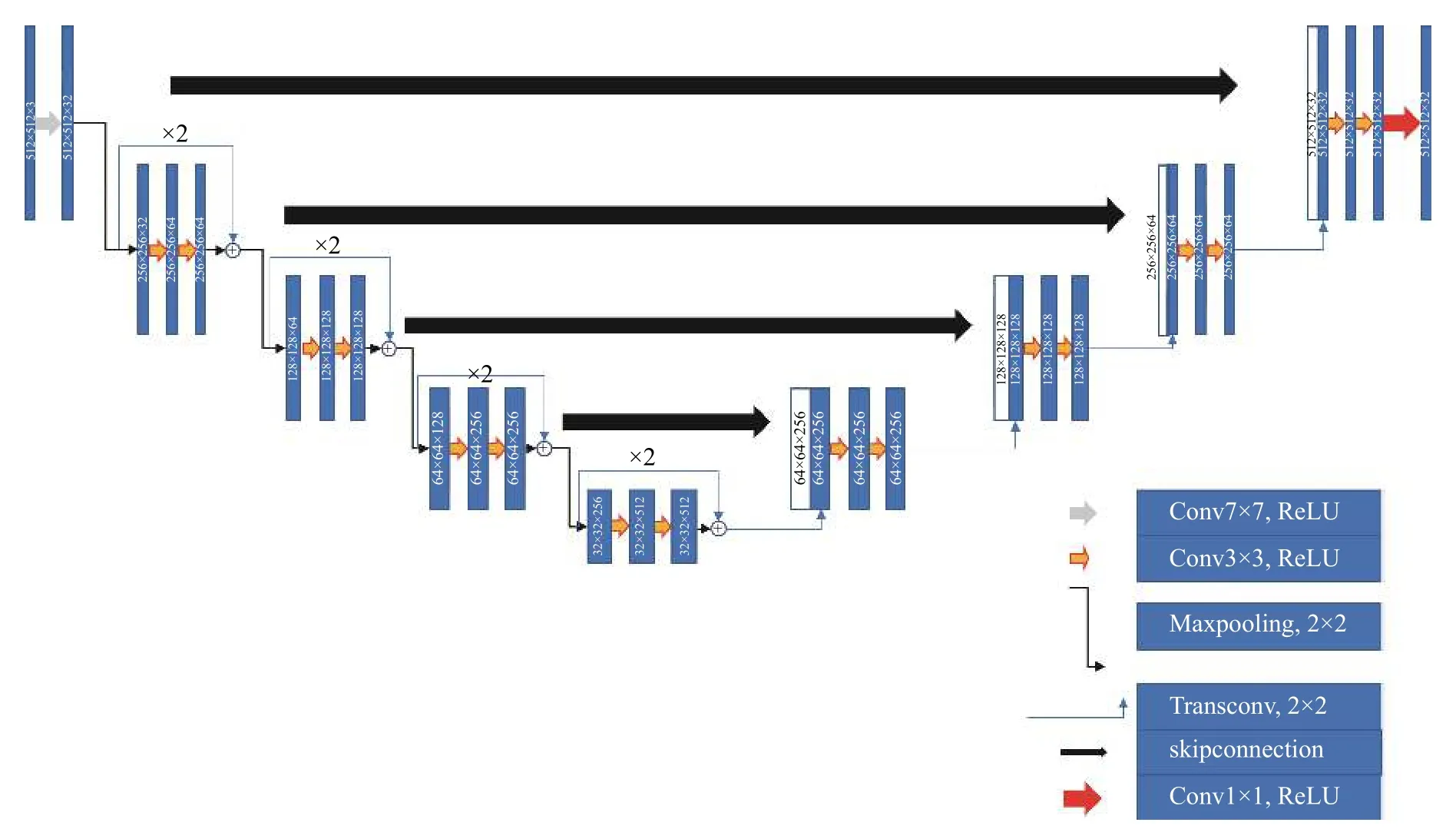
图 3 改进型的 U-NetFig. 3 Modified U-Net
在训练过程中,本文网络使用了adadelta 优化器。adadelta优化器能够自动调节学习率,通过引入动量来调节梯度下降速度,实现快速收敛。在模型训练阶段,选取80%图片用于每一轮训练,训练时将数据分批次输入模型中以减少训练时长,剩余的20%图片用作测试。

图 4 U-Net中跳跃连接结构Fig. 4 Skip connection in the modified U-Net
1.4 训练和测试
在硬件环境上,本文采用了GPU进行训练。此外,配置了128 G的内存以及512 G的固态硬盘,以满足深度学习的训练要求。
在软件环境上,本文采用TensorFlow平台,并辅以python软件。在深度学习实验中,用到的库有CUDA、cudnn、NumPy等。训练过程中,模型的步长为2,模型一共经历了100轮的训练,并且每一步的训练时间都在1 min以内。
1.5 评估指标
在进行视杯以及视盘的分割后,采用了两个衡量指标,即DICE系数和IOU来评估所提出算法的性能。DICE系数是一种集合相似度的度量指标,而IOU则是表示目标预测框和真实框的交集和并集的比例。各指标的计算公式如下:
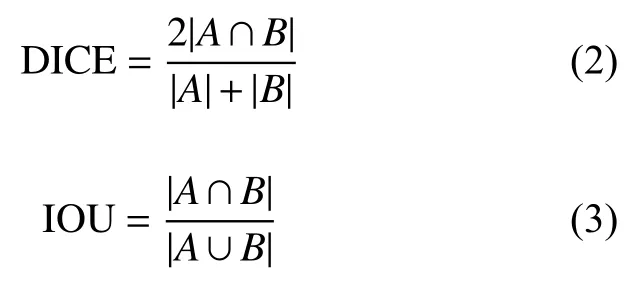
式中:A为目标区域;B为预测区域。
2 结果与讨论
2.1 实验结果分析
图5为训练集中的彩色眼底图和标签图。首先使用非公开数据集对网络进行训练,在视盘分割实验中,设置实验轮次为100次,每次步长为2。图6为视盘训练的loss曲线图,从图中可以看出,网络在训练阶段,曲线收敛速度较快,表明网络学习效率较高。随着训练轮次的提高,模型曲线的斜率逐渐减小,当训练轮次达到20时,训练曲线开始趋于水平,说明网络的学习能力开始饱和,并且开始呈现微小的波动。图7为视杯训练的loss曲线图,在视杯分割中,同样把实验设置为100次,每次步长为2。从图7中可以看出,曲线在达到30轮次时,开始趋于水平。图8和图9分别为视盘和视杯经过网络训练的准确率曲线图。

图 5 训练集中彩色眼底图与标签图Fig. 5 Label and color fundus image in training dataset
图像在进行卷积操作时,每一次卷积都能够提取原始图像中的一种特征,这些特征除了对我们有用的特征信息之外,还可能包括一些无用的特征信息,例如背景特征、噪声等。这些无用的特征信息同样会被当做输入进入下一层的网络中去,但是,随着网络层数的加深,我们所需要的特征信息会自动强化,而那些背景信息或噪声则会被弱化。使用评价指标对训练后的模型进行评价,评价结果如表1所示。在视盘分割中,网络的准确率ACC达到了99.96%,验证集的DICE系数达到了97.3%,IOU系数达到了95.2%;在视杯的分割中,网络的准确率ACC同样达到了99.91%,而验证集的DICE系数达到了92.6%,IOU系数达到了87.8%。
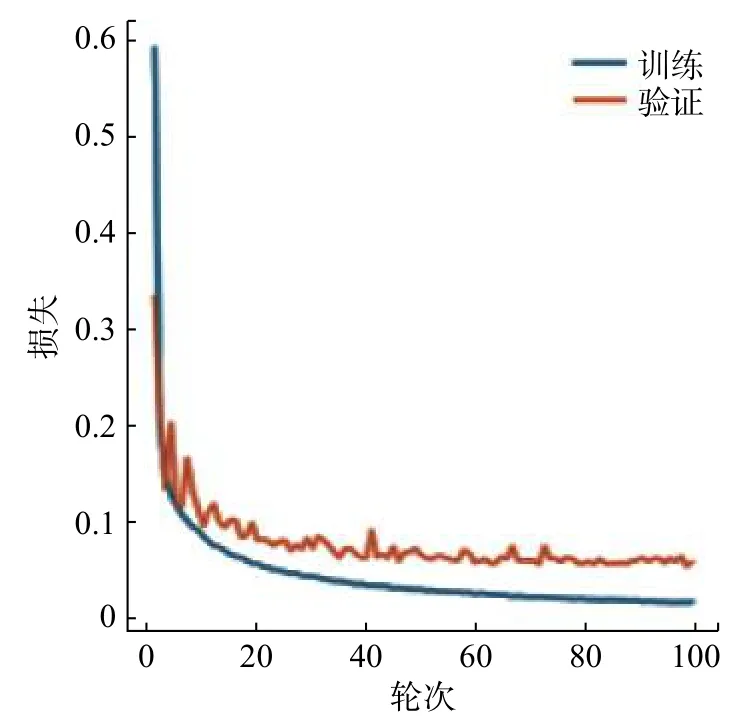
图 6 视盘训练 loss 曲线图Fig. 6 Loss curve in the optic disc training
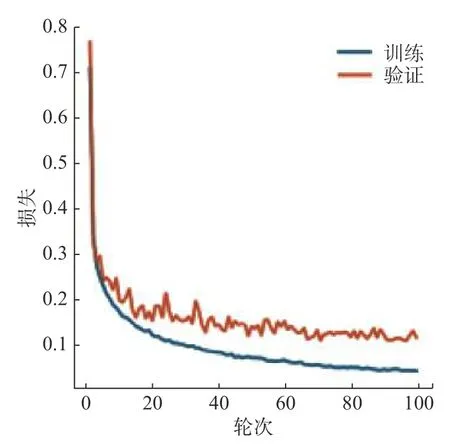
图 7 视杯 loss 曲线图Fig. 7 Loss curve in the optic cup training
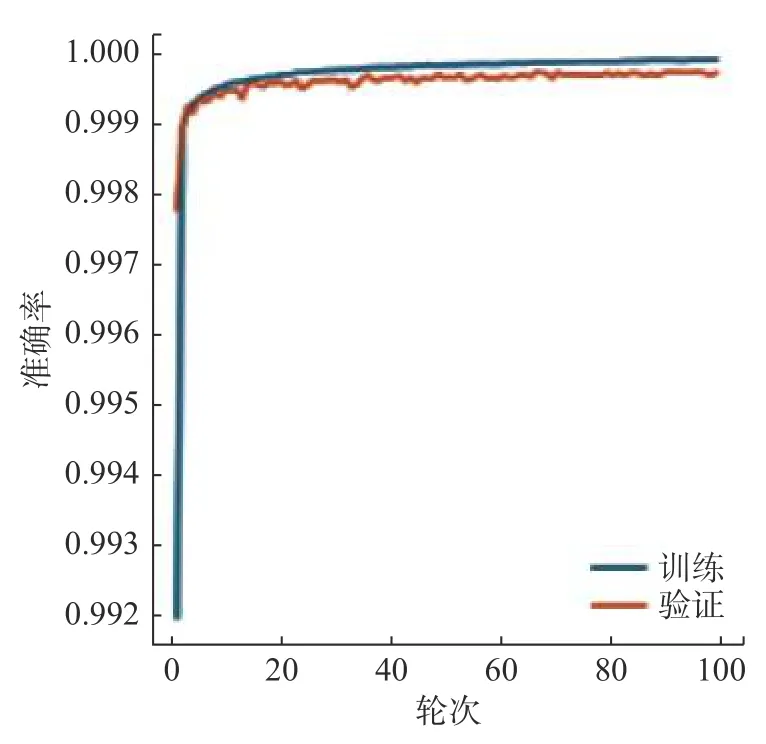
图 8 视盘准确率曲线图Fig. 8 Accuracy curve in the optic disc training
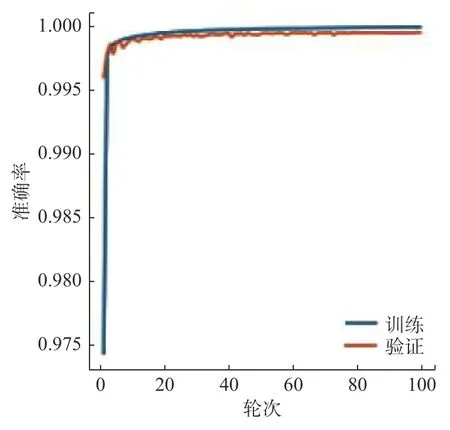
图 9 视杯准确率曲线图Fig. 9 Accuracy curve in the optic cup training
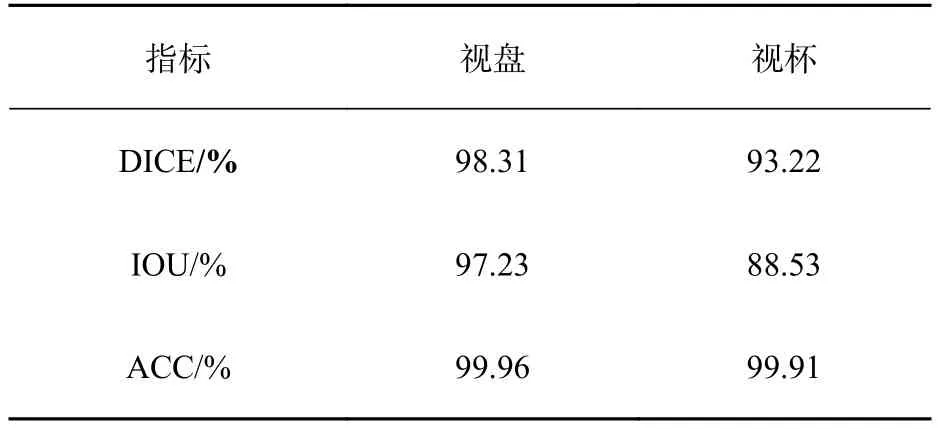
表 1 视盘视杯分割评估指标Tab. 1 Evaluation metric of optic disc and cup segmentation
在使用非公开数据集完成训练后,本文使用了DRISHTI-GS数据集对网络进行测试。表2和表3分别是视盘和视杯用不同处理方法得到的分割结果。将DRISHTI-GS数据集中的彩色眼底图像作为测试集中的输入,观察输出的分割效果图以及分割指数,并与其他的一些同样使用本数据集的网络(如FCN、 Small scale U-Net、MNet)进行对比。由表2和表3可以看出,本文提出的方法在DICE和IOU系数方面均有一定程度的提高。此外,网络训练的时间也有一定程度的减少,100轮次花费了110 min左右。其主要原因在于:1)模型中改进了跳跃连接,使得模型在跳跃连接时把有效的分割信息传递给上采样的对应层,增加了模型的准确率;2)本文下采样部分所使用的残差18模块能够较为有效地减少过拟合现象;3)改进型的U-Net网络相较于原始的U-Net网络参数较小,训练时间相比原始U-Net耗时更少。图10为分割成功的视杯图片,图11是将OC分割测试结果与标签、彩色眼底图融合后的结果图,其中中心黑色圈为标签,白色圈为测试结果。图12为测试集中分割成功的视盘图片,图13是将视盘分割测试结果与标签、彩色眼底图融合后的结果图,其中中心黑色圈为标签,白色圈为测试结果。
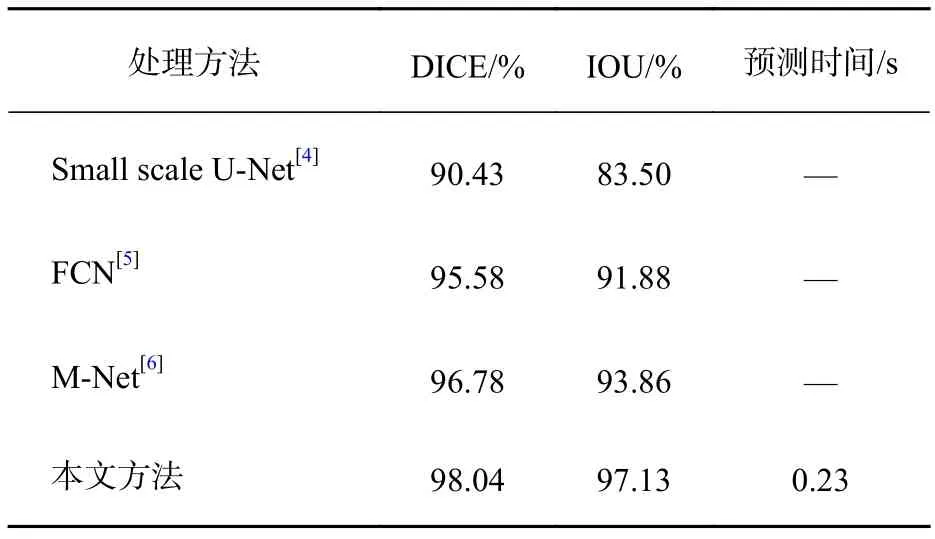
表 2 视盘分割比较结果Tab. 2 Comparison of optic disc segmentation
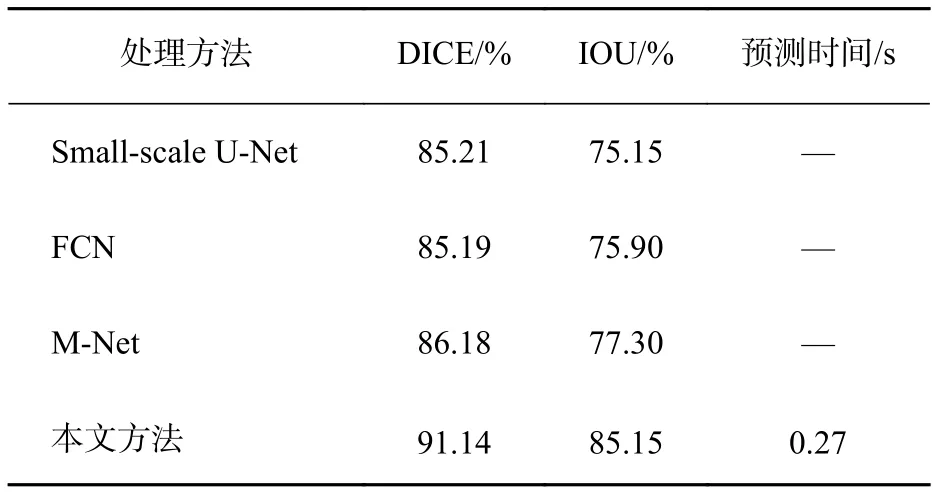
表 3 视杯分割比较结果Tab. 3 Comparison of optic cup segmentation
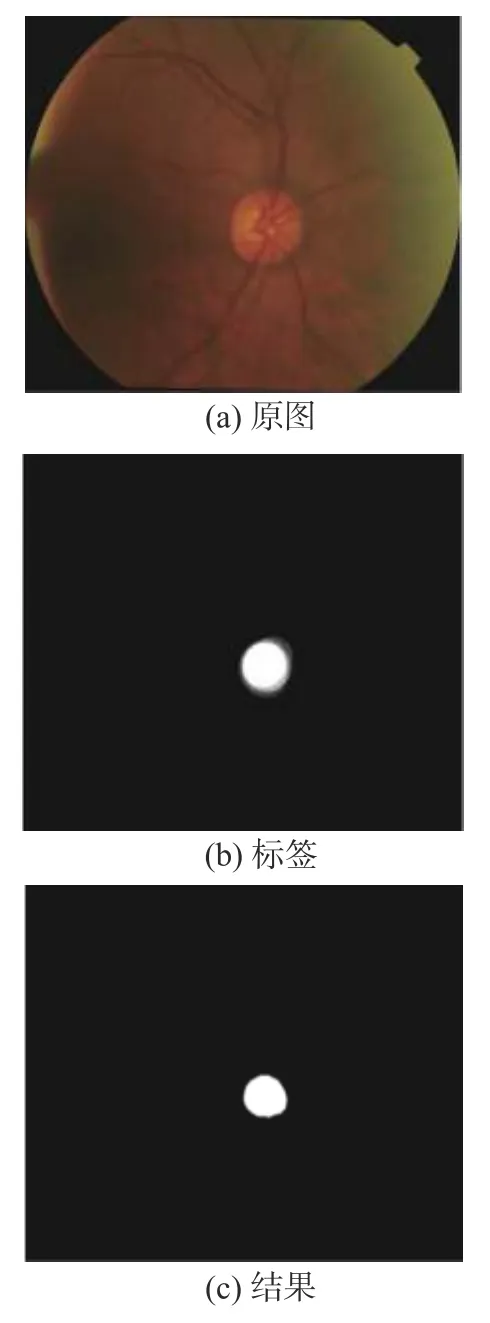
图 10 在 DRISHTI-GS 数据集中视杯分割结果Fig. 10 Result of the segmentation of the optic cup in DRISHTI-GS datasets
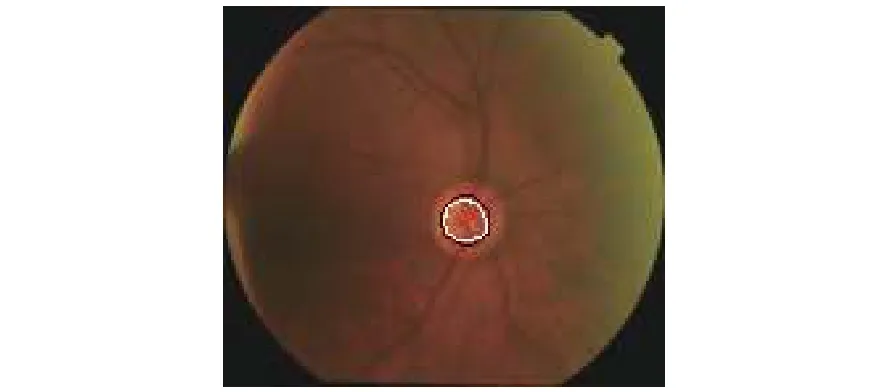
图 11 视杯 OC 融合后的结果图Fig. 11 Result of the merging image of the label, OC segmentation result and color fundus images

图 12 在 DRISHTI-GS 数据集视盘分割结果Fig. 12 Result of the segmentation of the optic disc in DRISHTI-GS datasets
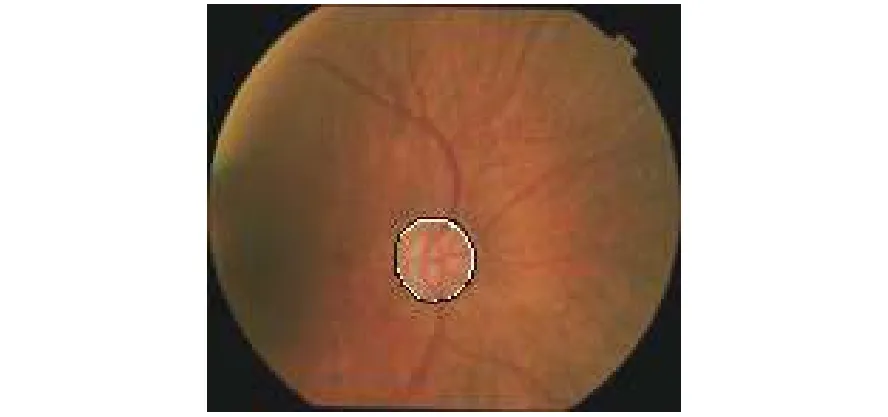
图 13 视盘融合后的结果图Fig. 13 Result of optic disc fusion
3 结 论
分割彩色眼底照片在计算机辅助医学诊断方面具有广泛的发展前景,但也面临着许多的挑战和不足。本文采用的网络是在现有的U-Net网络上对其进行改进实现的,主要改进了U-Net网络下采样部分和跳跃连接部分,充分利用了每一层的特征信息。通过与目前主流的网络结构进行对比,证明了本文网络能获得较好的分割效果,减少了分割眼底图像的时间,可以为青光眼的大规模筛查提供参考。
猜你喜欢
国际眼科杂志(2023年3期)2023-04-15
小主人报(2022年24期)2023-01-24
儿童时代·快乐苗苗(2022年6期)2022-08-06
矿山安全信息(2021年21期)2021-07-04
临床眼科杂志(2021年2期)2021-05-26
矿山安全信息(2020年37期)2020-12-26
矿山安全信息(2020年2期)2020-03-05
矿山安全信息(2020年3期)2020-03-04
学生天地(2019年33期)2019-08-25
小天使·二年级语数英综合(2018年7期)2018-09-11
