
基于Spark的气象数据处理与分析系统的设计与实现
2021-03-28 23:13刘海王明珠刘世超石钊宇刘明阳孙浩然
河南科技 2021年29期
关键词:网络爬虫
刘海 王明珠 刘世超 石钊宇 刘明阳 孙浩然

摘 要:将智能化信息应用于天气信息领域,是当今社会发展的必然趋势。通过使用中央气象台官方网站中的数据,利用爬虫技术提取各个城市的天气状况,基于Spark技术对数据进行处理分析,利用SSM框架实现分析结果数据的可视化,设计了基于Spark的气息数据处理与分析系统。系统的实现将对人们的日常生产生活产生积极的影响。
关键词:Spark技术;气象数据;SSM框架;网络爬虫
中图分类号:TP311.52 文献标识码:A 文章编号:1003-5168(2021)29-0026-03
Design and Implementation of Meteorological Data Processing and
Analysis System Based on Spark
LIU Hai WANG Mingzhu LIU Shichao SHI Zhaoyu LIU Mingyang SUN Haoran
(Anyang Normal University,Anyang Henan 455000)
Abstract: The application of intelligent information in the field of weather information is the inevitable trend of today's social development. By using the data from the official website of the Central Meteorological Observatory, uses crawlers to extract the weather conditions of each city, processes and analyzes the data based on Spark technology, and uses the SSM framework to realize the visualization of the analysis result data. The realization of the system will have a positive impact on people's daily production and life.
Keywords: Spark technology;weather data;SSM framework;web crawler
天气与人们的日常工作和生活息息相关。因此,要了解天气信息,对可能发生的暴雨、大风、冰雹、台风等灾害提前采取措施,最大限度地减少灾害给群众生命财产造成的损失,保证人们的生活质量[1]。随着科技的发展,天气预报的准确率和精确率都在不断提升,而随着手机移动APP的出现,天气预报的实时性也已经实现。技术的发展丰富了天气预报的功能,人们不必像过去一样守着电视观看天气预报,通过手机APP就能随时随地查看不同地点不同时间的天气信息。但技术的发展也带来了大量冗余的天气数据。那么,如何从大量冗余数据中分析出更有价值的信息就成为一个新的研究课题。大数据技术能帮助人们在看似毫不相关、冗余无序的大规模数据信息中提炼出有用的信息,从而使其发挥出相应的应用价值[2]。基于此,笔者设计了一个气象数据处理与分析系统。
1 系统需求分析
在系统设计之前,首先要确定天气信息的数据来源。本系统所采用的天气信息数据主要来源于中央气象台官方网站(http://www.nmc.cn/)。中央气象台网站上有全国2 412个城市最近24 h的整点天气数据,每条数据又包括详细的整点气温、整点降水量、整点风力、整点气压和整点相对湿度等详细数据。在明确数据来源的情况下,要根据研究背景和数据现状确定系统的需求。
数据来源已知,如何获取全部2 412个城市24个整点的57 888条数据是面临的首要问题。通过大数据采集中的数据爬虫技术完全可以实现这一需求。需要特别说明的是,本次爬取的数据没有得到中央气象台官方授权,使用范围仅限本次系统设计与实现过程,没有用于商业用途。数据获取完毕后,要做好数据的存储和分析工作。但是,像MySQL这种关系型数据库,只适用于增、删、改、查操作,进行数据统计等操作时速率非常慢,并且只能处理结构化数据[3]。而采用大数据技术中的HDFS数据存储技术和Spark数据框架处理技术完全可以实现大规模数据的分布式存储和快速处理。处理和分析完数据后,要选取可靠的可视化技术,实现对分析结果的展示。
2 系统设计的可行性
在经济性方面,本系统由专业指导教师领导学生团队利用所学专业知识开发,所使用的开发平台都是开源的,技术方面并未耗资。所用設备是学生自己的电脑,开发地点是学校内部。目前,该系统虽然没有产生经济效益,但是其可用性和实用性良好,在日常生活和抗洪救灾中具有潜在的应用价值和良好的发展前景。
从操作方面来看,本平台采用了交互性较强的Web界面,操作简单、直观,对使用者的技术要求不高[4]。系统也不存在复杂的模块,对普通用户来说,并不需要很专业的操作技术,只要具备上网能力就可以熟练使用本系统。
在技术方面,在系统开发过程中,团队计划利用网络爬虫技术实现原始数据的获取,使用Spark技术进行数据分析,利用SSM技术将所得结果可视化。以上涉及的各种知识均是团队所学专业知识,技术并不复杂,研究者能将其熟练地运用到系统开发中。
3 系统设计与实现
3.1 数据处理流程设计
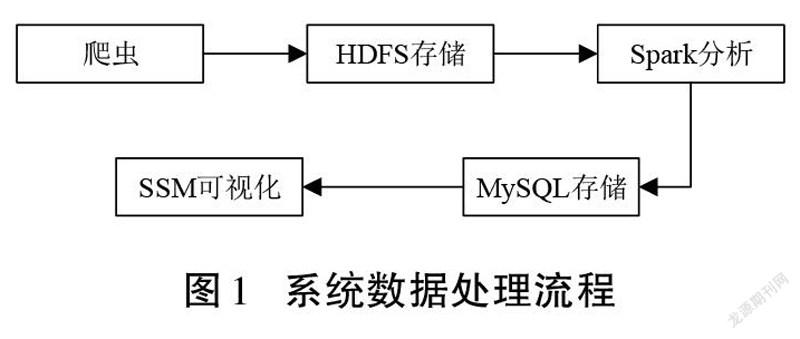
本系统主要涉及大数据的采集、存储、分析和可视化4个部分。首先,要利用网络爬虫技术获取原始数据。其次,使用HDFS对所获得的数据进行分布式存储。再次,使用Spark技术快速高效地分析数据,分析得到的结果存储到MySQL中。最后,利用SSM技术将结果进行可视化展示。图1为系统的数据处理流程。
3.2 数据采集
数据采集涉及所有城市24 h整点天气数据。从中央气象台官方网站Web控制台的切换过程可以发现,只有获取了省份和城市编码,才能获取各个城市24 h整点天气数据。本次大数据分析所需数据量较大,同时原始数据也较多,使用网络爬虫技术可以快速、高效地获取数据。通过调用Python的urllib2库中的相关函数,可以直接访问通过请求URL,请求成功后传回的响应json格式数据即是系统所需的原始数据。但是,由于涉及2 412个城市及不同天气状况,所获取的信息数据较为复杂,且某些因素可能会导致部分数据丢失甚至不存在,为此需要进行一次过滤,防止出现数据错误。
3.3 数据存储
3.3.1 HDFS存储。不同类型的数据采用不同的存储方式,结构化数据可采用分布式关系型数据库PostgreSQL等进行存储,半结构化数据可采用ElasticSearch、HBase进行存储,非结构化数据可采取文件型数据库HDFS进行存储,以保障不同类型数据能根据其数据特性和应用场景,采用合适的存储介质,实现数据的便捷管理与高效應用[5]。在本系统中,利用网络爬虫技术在中央气象台官方网站上得到的数据是较为庞大而复杂的非结构化数据,因此采取文件型数据库HDFS进行存储。HDFS分布式存储有利于原始数据存储和后续分布式数据分析。
3.3.2 MySQL存储。存储在HDFS中的原始数据经过大数据处理框架技术Spark分析处理后会得到最终结果,利用MySQL对处理后的数据进行存储,便于使用SSM技术对结果进行可视化展示,可以实现前端与后端的分离。也就是说,后端大数据系统只负责对数据的分析与处理,数据处理完毕存入MySQL数据库后,即可进行其他工作;前端SSM框架也只对存储在MySQL中的数据进行可视化展示,不影响后端的其他工作。
3.4 数据分析
通过对采集的数据进行分析可知,所采集的数据为各个城市24 h的气象数据,每一条数据又包含整点气温、整点降水量、整点风力、整点气压和整点相对湿度等详细数据。对于整点降水量,通过对所有城市所有整点时刻的降水量进行降序排序,在一定程度上可以体现出洪涝风险,但一个时间点的数据并不具有代表性。而通过对所有城市24 h整点时刻的降水量进行求和,再进行降序排序,结合整点降水量降序排序结果,即可全面体现洪涝风险。对于Spark,首先可以使用groupBy操作按照province,city_name,city_code的字段分组,再使用agg方法对rain1h字段进行分组求和得到新的字段rain24h(过去24 h累积雨量),最后使用sort方法按照rain24h降序排列,经过上述操作后得到新的Dateframe df_rain_sum。
在剩下的数据字段中,气温数据中所有城市的最高温排名、最低温排名、温差升序排名、温差降序排名和平均温度排名对指导人们生产劳作和外出旅行发挥着重要作用;风力数据中所有城市的风力值降序排名可以有效指导人们防范大风带来的不利影响;气压数据中所有城市的气压值降序排名、气压值升序排名、平均气压值升序排名和平均气压值降序排名对指导人们运动和安全也具有十分重要的意义。Spark中的各类操作方法比较多,可以满足各类数据的处理需求。此外,Spark基于内存进行工作,可以直接在内存中读取数据,减少了磁盘I/O的开销[6]。因此Spark特别适用于这种实时的大数据分析统计处理。
3.5 结果可视化
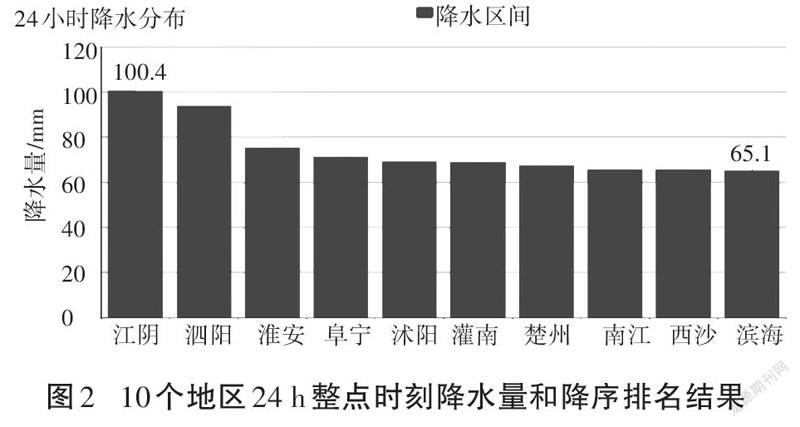
数据可视化的优点是能帮助人们以最快的速度理解并记忆数据。例如,有些数据信息之间存在各种各样的联系,如果用书面形式表达,可能要花数个小时分析所有数据之间的联系,而通过图表就可以清晰快速地发现数据之间的关系[7]。通过气象分析结果数据的可视化展示,人们可以更加清晰地观察各个城市的天气状况。图2是10个地区24 h整点时刻降水量和降序排名结果。在前端可视化部分,本系统选取SSM框架对所有大数据分析结果进行可视化展示。之所以选择SSM框架作为前端可视化技术,是因为SSM框架是目前流行的Java EE企业级框架[8]。SSM三个字母分别代表Spring、Spring MVC和MyBatis[9],其中,Spring可以控制所涉及的各个对象之间的依赖关系,使开发过程进一步简化;Spring MVC能与Spring无缝连接,并对Web层解耦以进一步简洁开发过程;MyBatis可以灵活地利用SQL语句对MySQL数据库进行操作[10-11]。
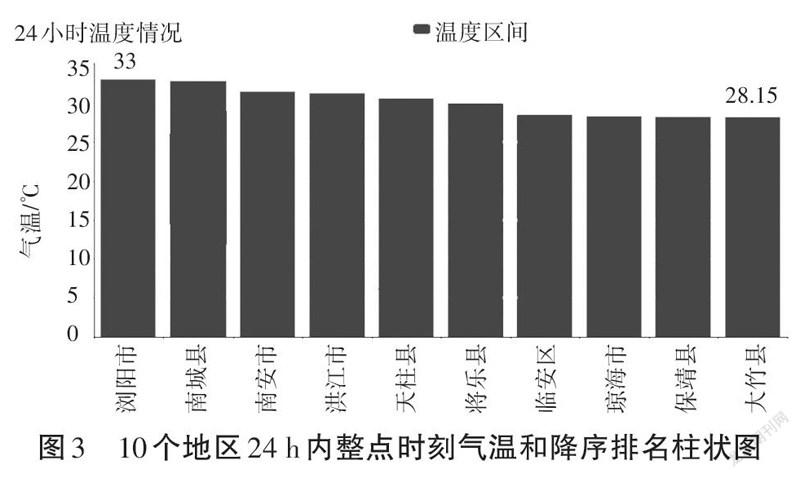
在数据可视化方面,系统还提供了不同类型的可视化结果,以满足多数人员的需求。图3为10个地区24 h内整点时刻气温和降序排名结果。通过点击可视化界面右上角的折线图标,可以把数据可视化结果变换为折线图(见图4);通过点击可视化界面右上角的表格按钮,可以把数据可视化结果变换为表格;通过点击可视化界面右上角的刷新按钮,可以刷新最新的数据可视化结果;通过点击可视化界面右上角的下载按钮,可以把数据可视化结果下载下来。
4 结语
极端天气带来的自然灾害给人类生活带来了极大的破坏。因此,对天气信息进行大数据分析,将对人们的生产生活、旅游出行和抗洪救灾等产生积极影响。本系统的设计积极响应国家号召——将科技与实际相结合,能运用在抗洪救灾、生产生活指导方面,在一定程度上提高人们的生活质量。
参考文献:
[1]金静梅.基于网络爬虫的城市天气服务系统设计与实现[J].办公自动化,2021(19):58-59.
[2]虎啸.基于大数据、云计算构建的智慧校园生活平台[J].通讯世界,2016(11):274-275.
[3]覃禹.智慧管廊云平台中人工智能及大数据模块的设计与实现[D].北京:北京邮电大学,2021:1-72.
[4]刘海,王壮壮,乔昭源,等.基于SSM框架的校园帮平台的设计与开发[J].数字化用户,2020(45):20-22,25.
[5]程宇翔,梁均军,刘洪波,等.时空数据转换服务系统设计与应用[J].地理空间信息,2021(9):116-118.
[6]闫小彬.大数据增量降维方法的研究与实现[D].哈尔滨:黑龙江大学,2019:1-71.
[7]艾青龙.柔性自动化生产线工艺信息组织技术研究[D].南昌:南昌大学,2017:1-83.
[8]臧聪聪.气象预报系统中数据处理子系统的研究与实现[D].南京:东南大学,2018:1-75.
[9]邵玉春.高校教师聘期考核系统的设计与实现[D].南昌:江西师范大学,2018:1-65.
[10]吴小东.基于Dubbo和Zookeeper的学校自助证明打印系统设计与实现[D].甘肃:兰州大学,2021.
[11]薛峰,梁锋,徐书勋,等.基于Spring MVC框架的Web研究与应用[J].合肥工业大学学报(自然科学版),2012(3):337-340.
猜你喜欢
电脑知识与技术(2017年1期)2017-03-24
电脑知识与技术(2017年1期)2017-03-24
计算机时代(2017年2期)2017-03-06
中国新技术新产品(2017年4期)2017-03-04
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
科技经济市场(2016年2期)2016-06-16
电脑知识与技术(2016年7期)2016-05-19
