
计算机Matlab软件的SVM回归分析设计研究
2021-03-26 03:29秦昌琪
电子元器件与信息技术 2021年11期
秦昌琪
(江苏信息职业技术学院,江苏 无锡 214000)
0 引言
随着我国电子计算机技术的不断发展,Matlab得到了越来越广泛的应用,该软件在铁路货运领域的应用大幅提升了货运量运输预测的准确性,为铁路资源的合理调配提供了大量的科学依据。做好SVM回归分析的关键在于预测模型的设计工作,本文将对SVM预测模型的设计方案进行重点介绍。
1 铁路货运量SVM预测模型的基本设计思路
SVM即Support Vector Machine,中文为支持向量机,是一种常用的回归分析手段,本质上特征空间上间隔最大的线性分类器[1],能够针对未知的新样本实施高水平的分类预测,其根本目的在于以二次规划求解的方式来实现预测[2]。在铁路货运量的预测方向,本次研究所提出的SVM预测模型的建立流程如下:
第一步:基于现有的货运量数据实施归一化处理,进而建立测试样本数据集和训练样本数据集,即通过归一化的方式将原始数据样本纳入至[a,b]范围内,所采用的计算公式为:

上式将原始数据记为X;将X经过归一化处理后的数据记为Y;将原数据样本的最大值记为Max,将原数据样本的最小值记为Min。
第二步:通过交叉验证法确定核函数参数g和参数惩罚因子c[3]。设有一个核函数参数g,再随机将训练集划分为k个不相交的子集,将测试样本锁定为k,将训练样本锁定为除第k以外的部分,在此基础上估计该参数的效果,经过k次测试后对比结果,进而提取出合理的参数,最终所获取的性能评价指标为k次模型结果的MSE平均值。
第三步:在获取最佳参数的基础上学习训练样本集数据[4]。
第四步:基于测试样本数据实施预测,通过反归一化的方式获取数值。
第五步:对梯形预测结果进行验证。
为了对所建模型的预测精度及有效性进行验证,本次研究通过两种检验标准对模型进行了检验[5-6]。
(1)通过预测相对误差对模型预测精度进行检验
定义如下所示的预测相对误差(FRE):

2 铁路货运量SVM预测模型的具体设计方案
2.1 基于模糊信息粒化的铁路货运量SVM预测模型
本次研究基于MATLAB软件R2016a版本设计了如图1所示的铁路货运量预测流程。
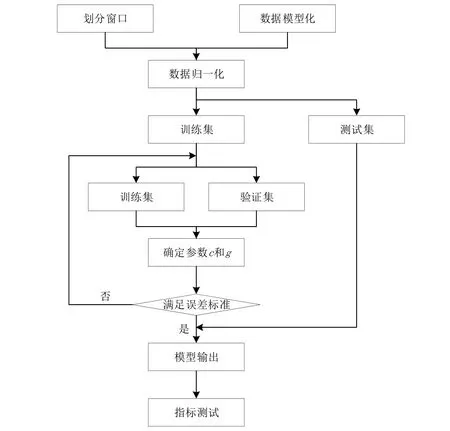
图1 SVM 预测流程
第一步:基于目标铁路站点的流量数据提取出用于预测和训练的货运量数据。
第二步:通过三角形模糊信息粒化的处理方式在铁路货运量数据中提取出Up数据、R数据和Low数据。
第三步:通过交叉验证的方式对经过模糊粒化处理的Up数据、R数据和Low数据进行SVM寻优,进而获得RBF核函数,在此基础上确定参数g、c的值,再对拟合结果和误差状况进行分析。
第四步:在最优参数的基础上获取最终决策函数,再针对铁路货运量实施训练与预测,获取Up、R和Low的值。
第五步:对模型的预测结果进行验证。
2.2 模糊信息粒化FIG-SVM预测模型
本次研究基于MATLAB软件R2016a版本设计了如图2所示的铁路货运量预测流程。
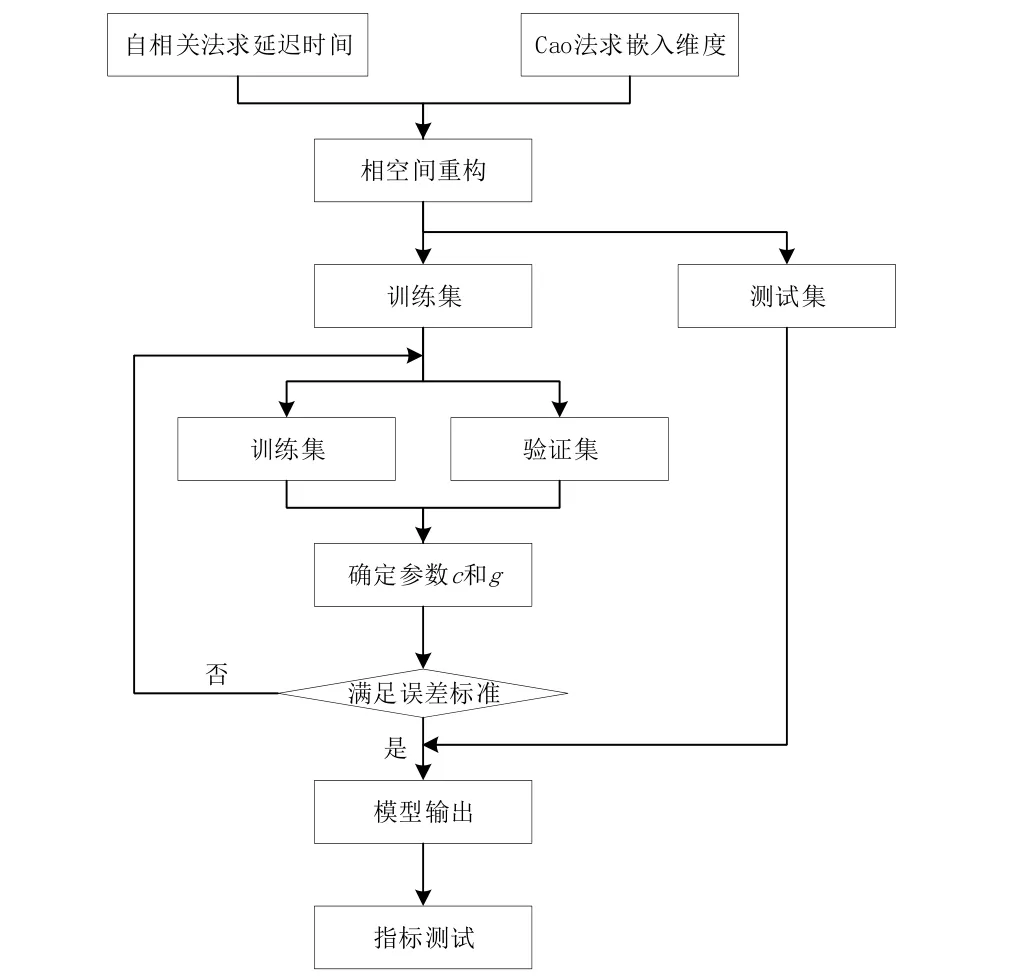
图2 相空间重构-SVM预测流程图
第一步:基于目标铁路站点的流量数据提取出用于预测和训练的货运量数据。
第二步:以矩阵形式对铁路货运时间序列进行转换,明确数据之间的关系。为了充分反映系统的运动特征,还需要选取合理的延迟时间τ和嵌入维m,基于经过变形后的一维时间序列提取出输入样本X并用于训练,每一列为一个相点。
第三步:选取RBF核函数,在对货运量数据进行空间重构处理后对SVM进行寻优,进而获取参数g和参数c的值,并对误差进行分析。
第四步:在最优参数的基础上获取最终决策函数,再针对铁路货运量实施训练与预测。
第五步:对模型的预测结果进行验证。
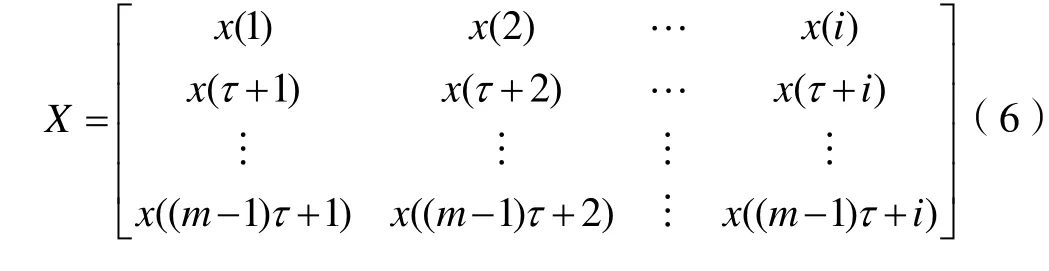
3 结语
本文以铁路货运量的SVM预测为例详细介绍了基于计算机Matlab软件的SVM回归分析方法,在未来的研究中,还可以利用最小二乘法、神经网络法等方法对各种不同的特征的数据进行更加深入的分析,以提升数据预测的准确度,为科学管理提供更加有效的指导。
猜你喜欢
农机科技推广(2022年7期)2022-08-16
河南农业科学(2020年7期)2020-07-22
广州文博(2020年0期)2020-06-09
广西农学报(2019年4期)2019-11-26
大陆桥视野(2017年13期)2017-12-23
中国民族医药杂志(2016年2期)2016-05-14
中国民族医药杂志(2016年4期)2016-05-09
哈尔滨理工大学学报(2015年4期)2015-12-31
温州职业技术学院学报(2014年3期)2014-03-11
