
基于爬虫技术的图书购买推荐与比价策略研究
2021-03-24 16:09卢江刘文正
科技资讯 2021年1期
卢江 刘文正

摘 要:在大数据背景下,大量数据的堆叠使人们在进行人工提取有效信息时,存在诸多不便。网络爬虫技术可以自动完成网络信息的收集和分析,从而方便用户获得有效信息。该文以图书购买推荐与比价策略的研究为重点,主要介绍了lxml库与Python相关技术,以及图书比价的策略特点,为用户提供更直观的商品指标,同时存储商品信息为后续的进一步优化提供数据源。
关键词:爬虫技术 lxml Python 比价策略
中图分类号:TP391.3 文献标识码:A 文章编号:1672-3791(2021)01(a)-0214-06
Research on the Strategy of Book Purchase Recommendation and Price Comparison Based on Crawler Technology
LU Jiang LIU Wenzheng*
(Tianjin University of Commerce, Boustead College, Tianjin, 300384 China)
Abstract: In the background of big data, the stacking of a large number of data makes it inconvenient for people to extract effective information manually. Web crawler technology can automatically complete the collection and analysis of network information so as to facilitate users to obtain effective information. This paper focuses on the research of book purchase recommendation and price comparison strategy, mainly introduces the lxml and python related technology, as well as the characteristics of book price comparison strategy in order to provide users with more intuitive commodity indicators, while storing commodity information to provide data sources for subsequent further optimization.
Key Words: Crawler technology; Lxml; Python; Price comparison strategy
隨着互联网科技的飞速发展,在淘宝、京东、亚马逊、当当网、中国图书网等购物平台上,由于图书资源汇总不全面而导致消费者耗费大量的时间、精力在各大平台自我进行性价比分析的问题也逐渐显露。这些平台对图书的分析推荐有所欠缺,不够全面从而导致消费者耗费大量时间、精力,尤其是学生党和上班族对于这一块的图书高效选择需求尤为突出。
1 爬虫技术概述
1.1 Python语言简介
Python是一种跨平台的计算机编程语言,是一种具有高级解释性、交互性、可编译性和面向对象性的语言。我们可以就像在读英语一样读一个很好的Python代码,它可以让你找出解决问题的方法,而不是去解决语言本身。它最初被设计用于编写自动脚本,随着版本更新和新功能的加入,它越来越多地用于独立、大型项目的开发。
1.2 网络爬虫定义
网络爬虫又被称为网络蜘蛛和网络机器人,是一种能自动采集互联网信息的程序或脚本。爬虫的主要目的是从网络上提取相关的信息保存在本地形成一个多维的数据库用来做出更好的数据模型。
1.3 工作原理
(1)首先获取初始URL。初始URL地址可以由用户指定,也可以从几个初始爬网页人为地指定或确定。
(2)根据初始URL抓取页面来获取新URL。获取初始URL地址后,首先需要对相应URL地址中的页面进行爬取,爬取了相应页面之后,将页面存储在数据库中,同时新的页面进行爬取,然后查找新的URL地址,并在列表中存储爬取到的URL地址,用于判断是否爬取网页重复并且确定爬取过程。
(3)将新URL放入URL队列中。
(4)从URL队列中读取新URL,根据新URL对页面进行爬取,从新网页中获取新URL,然后重复上述爬取过程。
(5)满足Python系统设定的停止条件时停止爬行。当写Python代码时,通常会设置停止条件。如果未设置停止条件,Python将不停地爬取网页,直到新的URL地址无法获取;如果设置了停止条件,则Pyhton将在满足该条件时停止爬取。
2 技术实现
2.1 技术路线
技术实现的主要技术路线见图1。
2.2 基于lxml的信息爬取系统设计
2.2.1 lxml概述
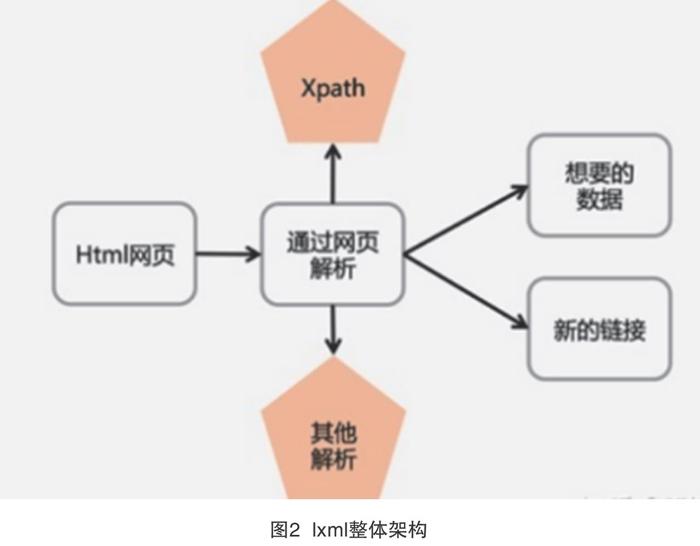
lxml工具包用于libxml2和libxslt的Pythonic绑定。它的独特之处在于它结合了各种所需库的速度和XML功能完整性与本机PythonAPI的简单性,但由于众所周知的ElementTreeAPI的优势,因此lxml工具包被广泛使用。lxml工具包的整体架构情况见图2。
ml.etree是一个处理XML的很快的库。但是在将强大的libxml2库映射到简单方便的ElementTree API时,需要注意一些问题。并非所有操作都像API建议的那样快,而一些用例可以从找到正确的操作方法中获益匪浅。基准页面与其他 ElementTree实现进行比较,并提供了许多性能调整提示。与任何Python应用程序一样,经验法则是:在C中运行的处理更快。另请参阅系统设计部分。
2.2.2 Xpath概述
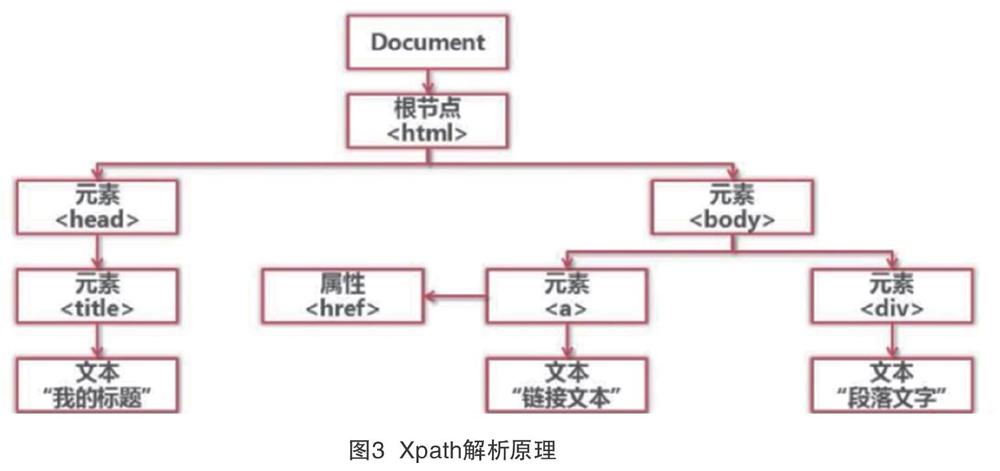
Xpath是XML路径语言,用于标识XML文档中的特定位置。Xpath基于XML的树形结构,并且提供树形结构数据中的定位节点的能力。同样的,Xpath也支持HTML,因为Pyhton通常从HTML页面中爬取,而HTML网页与XML一样,都是树形状结构。Python的目的是获取数据,但是这些数据通常不是页面的全部数据,因此获取指定的数据需要数据匹配。常见的匹配技术包括Python自己的正则表达式类库(re),但正则匹配不能完全保证与指定的数据节点匹配,表达式的编写也很复杂。Xpath语言简化了匹配表达式的编写,并且具有较高的成功率。Python语言能够很好地支持Xpath,lxml和Xpath的组合使Python爬取更高效可靠。Xpath的解析原理见图3。
3 技术特色与创新性
在日常生活中,很多人因为不知道什么购物平台有自己所需要的资料,就盲目下载或浏览各种软件或网站。而该文设计的方案是可以直接根据用户搜索的图书,呈现最优的图书排名及对应的平台,此时用户就可以针对性下载以及查找。
同时可以直接呈现出性价比的结果,不用用户一而再、再而三地去花时间进行对比分析。
“基于爬虫技术的图书购买推荐与比价策略研究”进行了很好的图书汇总处理,主要针对人群是学生党和上班族,他们因为工作或学习的原因,没有大量的时间耗费在查找学习资料上,为此很多人因为图书没有针对性导致事倍功半、劳心劳力也没达到自己想要的预期效果。
该文介绍了通过广度优先网络爬虫对淘宝、京东、中国图书网等平台上的图书资源汇总分析,再到数据可视化的对比过程。主要通过用户在搜索的时候,可以选择输入书名或者作者名,网页就会呈现出经过性价比分析后的最优图书。除此以外,我们会根据关键词,推荐出评价最好、价格适中的图书。更方便学生党和上班族的学习需求,提高了买书的效率。
4 系统设计
4.1 多线程的使用
多线程类似于同时执行多个不同程序,多线程可以把占据任务过程时间较长的程序放到后台去处理,这样可以加快处理一些正在等待的任务,如用户输入输出、文件的读写和网络接受发送数据等。在一些等待的情况下我们可以释放资源,如内存占用等。在爬虫设计中,如果使用单线程技术,那么在进行巨大的爬取工作时,逐行执行将会占用非常长的时间,但是当引用了多线程技术,那就类似于同时运行了多个爬虫程序对网页进行爬取,会极大地提升网页的爬取速度。在该程序中我们使用了3个线程来运行,在测试过程中节省了很多时间。
4.2 反爬虫机制的机制分析
在网络请求中,User-Agent是客户端表明身份的一種标识;在服务器中,可以判断User-Agent是否为浏览器行为。当我们使用代码进行爬虫时,如果对方服务器中需要浏览器标识User-Agent时,但是在自己的代码中没有添加浏览器标识时,那么这段代码的请求不会通过,并且将返回403错误码。
在许多购物网站中,为了防止爬虫机器人在短时间内进行大量网络资源的访问,所以在其网页中,经常都引用反爬虫机制来禁止这种行为。在测试过程中,分别使用postman软件和Microsoft Edge浏览器同时访问相同的网页,在postman中获得的返回码虽然是200,但是获取的源代码却比Microsoft Edge浏览器中的代码少了很多,说明这个网页设置了反爬虫机制。
所以为了应对反爬虫机制,经常设置一个header值来模拟浏览器行为,通常每个浏览器都有不同的代码,在此举几个例子:谷歌chrome浏览器:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36;Microsoft Egde浏览器:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299。但是在个别网页中,同一个浏览器、IP地址下短时间内发送大量的数据也是会被禁止访问,因此我们在此爬虫中引用了fake-useragent库,其包含了10种浏览器的识别代码,在使用中,可以固定一种浏览器,也可以直接使用random参数。在爬取数据过程中,最重要的就是可以随机使用头文件,这样将大大减少了被禁止访问的风险,同时减少了代码量。
4.3 lxml解析器的应用
(1)lxml。对于浏览器的爬取需要使用解析器来解析网页,在爬虫中,通常使用BeautifulSoup库和lxml库来解析网页,因为BeautifulSoup需要加载整个网页的文档数来进行查询匹配操作,所以会占用较多的资源,降低运行速度,而对于lxml库,它同时支持HTML、XML和XPATH的解析,解析效率非常高,所以在此爬虫中使用了lxml库。
(2)XPath。全名为全称XML Path Language,或XML路径语言,是一种查询XML文档中的信息的语言,最初用于搜索XML文档,但它也适用于html类型的文档搜索。XPath非常强大,它提供了一个非常简洁的Web源路径选择表达式,此外,它还提供了100多个内置函数,用于数字、时间匹配、字符串和序列、节点处理等,几乎所有我们想要定位的节点,都可以选择XPath。
爬虫在该系统中处于主导地位,因此lxml库在本系统中发挥了重要的作用,对于3个网址的解析都使用了lxml中Xpath方法进行路径定位和分析。在网页中使用开发者模式打开网页元素界面,通过标识符可以定位到需要爬取内容的位置,经过对比可以发现代码位置的相同之处,如图4所示,可以确定在淘书团网站下搜索python关键字定位的第一本图书。
同时发现在搜索结果显示中的结构都是一样的,所以可以直接使用代码定位到其具体位置tree.xpath('//ul[@class="bigimg"]/li')下,并将其存储在li_list中,并使用循环来遍历所有
4.4 Requests的网络请求方式
Requests支持在python内置模块的基础上进行了高度的封装,从而使得python进行网络请求时,变得人性化,使用Requests可以轻而易举地完成浏览器可有的任何操作。
Requests库支持HTTP连接保持和连接池、支持使用cookie保持会话、支持文件上传、支持自动响应内容的编码、支持国际化的URL和POST数据自动编码。并且在内置模块的基础上进行了高度的封装,使得python在进行网络请求时,变得人性化,使Requests可以轻而易举的使用代码的方式完成浏览器的任何操作。Requests.get(url,header)语句打开使用header中的useragent方式打开一个网站的网址,并保持连接,直到数据处理完成。
以淘书团网址http://www.bookschina.com/book_find2/default.aspx?stp=%s&p=%s为例,对于程序开始阶段输入的关键字和页数分别由stp和p参数确定,在程序运行过程中使用中经过多线程的处理,将页码传入进来,进行自加一操作,即可实现自动翻页行为。
4.5 数据处理的方法
Pandas是基于NumPy的一个开源库,该工具是为了解决数据分析任务而创建的。在Pandas中有两种数据结构,即序列Series和数据框DataFrame。Series类似于Numpy中的一维数组,可通过索引标签的方式获取数据,具备索引的自动对齐功能;DataFrame类似于Numpy中的二维数组,可以使用二维数组的函数和方法处理数据。Pandas是使Python成为强大而高效的数据分析环境的重要因素之一。
在完成爬虫功能将文件保存下来之后,使用pandas库对数据进行处理。首先使用DataFrame()将“我爱淘书.csv”转换为二维数组。在查看未处理文件时,发现爬取的数据中存在很多空行,所以使用lc.dropna(axis=0, how=‘any, inplace=True)代码将空行删除,axis表示删除轴,即按行删除或按列删除,此时0表示的是按行删除,how表示筛选方式,‘any,表示该行/列只要有一个以上的空值,就删除该行/列,inplace表示是否直接在源文件中替换空行,true表示在源文件中进行操作而不生成新的文件。
用户在进行搜索图书时,可以选择输入书名或者作者名,网页就会呈现出经过性价比分析后的最优图书。既然要进行比价操作,所以需要对爬取的文件进行升序排列,将价格最优惠的图书放在上面,为使用者提供简单明了的阅读。在这里使用sort_values(by="价格", ascending=True, inplace=True)語句,by定位要进行操作的列;ascending的值为True时代表升序排列,为False时代表降序排列,inplace参数同删除空行一样,代表是否直接替换源文件。由于爬取数据较大,因此只对部分数据进行展示,具体见图5、图6。
5 结语
从获得的数据来看,优先显示价格较低的图书,同时显示读者比较关注的相关信息,如可以购买到的平台名,近期折扣活动,购买链接,图书简介等,该系统通过lxml库、XPath等技术实现了利用关键词进行爬取资源的操作,对网络上的图书进行比价策略研究,具有一定的实用性。
参考文献
[1] 苻玲美.正则表达式在python爬虫中的应用[J].电脑知识与技术,2019,15(25):253-254.
[2] 罗安然,林杉杉.基于Python的网页数据爬虫设计与数据整理[J].电子测试,2020(19):31,94-95.
[3] 朱燕腾.Python的计算机软件应用技术分析[J].电脑编程技巧与维护,2020(9):10-11,16.
[4] 赵文杰,古荣龙.基于Python的网络爬虫技术[J].河北农机,2020(8):65-66.
[5] 曾燕清,陈志德,李翔宇.应用树结构的Xpath自动提取算法[J].福建电脑,2020,36(7):34-38.
[6] 刘新鹏,高斌.利用Python和Pandas进行学生成绩处理[J].信息与电脑:理论版,2020,32(7):41-43.
[7] 温娅娜,袁梓梁,何咏宸,等.基于Python爬虫技术的网页解析与数据获取研究[J].现代信息科技, 2020,4(1):12-13,16.
[8] 李培.基于Python的网络爬虫与反爬虫技术研究[J].计算机与数字工程,2019,47(6):1415-1420,1496.
[9] 何春燕,王超宇.基于python+pandas的数据分析处理应用[J].数码世界,2018(7):386.
[10]蔡光波.面向主题的多线程网络爬虫的设计与实现[D].西北民族大学,2017.
[11]王朝阳.基于Python的图书信息系统的设计与实现[D].吉林大学,2016.
