
基于主动学习的机器学习算法研究进展
2021-03-24 08:21刘霄宇左劼孙频捷
现代计算机 2021年3期
刘霄宇,左劼,孙频捷
(1.四川大学计算机学院,成都610065;2.上海政法学院,上海200000)
0 引言
随着机器学习与深度学习技术的高速发展,图像分类算法已经在各个领域中体现出了它的应用价值。但对于机器学习与深度学习来说,都需要大量的标注数据进行驱动,让算法模型见过的数据越多,它的分类效果就会越精准。而在实际情况下,标注数据需要巨大的工作量,极其耗费人力、物力、财力资源。主动学习算法所解决的正是标注成本问题,它的目的是通过模型与标注人员的交互,使用少量的数据获取与大量数据相同的模型准确率。主动学习的概念早在90 年代便被学者提出[4],其最早主要应用于机器学习的方法中,仅使用简单的选择策略便可以获得较好的效果[4],如使用不确定性的主动学习方法[5],使用委员会投票的方法[6],期望模型最大提升的方法[7],期望错误减小的方法[8]和期望变化减小的方法[9]。随着深度学习的发展,模型复杂度的增加,主动学习的传统方法在深度学习模型中并没有体现出其优秀的表现。在2017 年,Zhu J J 等人提出了借用生成对抗网络的主动学习方法[12]。在2018 年,Ozan Sener 等人[1]提出了使用核心集的方法,通过数据在特征空间上的代表性来选择标注数据。2019 年,Donggeun Yoo 等人[2]提出了通过学习损失函数的值的方式来进行标注数据的选择。2019 年,Samarth Sinha 等人[3]提出了使用变分自编码器的表征学习方式来学习已标注数据和未标注数据的差异来选择标注数据。这些主动学习方法在公开的数据集上都取得了优秀的效果,进一步的证明了主动学习的研究价值。
1 相关工作
上世纪90 年代,主动学习的概念便被学者提出并进行应用。它的步骤如图1 所示。第一步是由专家对少部分样本进行标注,第二部是针对少部分样本对目标模型进行训练,第三步是使用主动学习算法对未标注样本进行选择,第四步是将选择出的样本送回给专家继续标注并重复上述步骤。主动学习的核心问题是寻找出最有用的样本,对于最有用的样本的定义一般分为两种,基于不确定性选择的样本和基于差异性选择的样本。对于不确定性,我们可以理解为去寻找模型最难以判断的样本。如样本的信息熵越大,它的不确定性越大,模型置信度越低,选择此类样本可以获取得到丰富的信息量,以便模型进行判断。对于差异性,我们可以理解为针对数据本身选择其最有代表性的样本,如使用聚类的方法对样本进行处理,再选择聚类中心进行标注,则可获取到就数据本身而言的最具代表性的样本。不论哪种方式对样本的选择,都脱离不了样本的信息量的概念,因此对于主动学习算法的研究,也是对数据所携带信息的提取与表示上的研究。
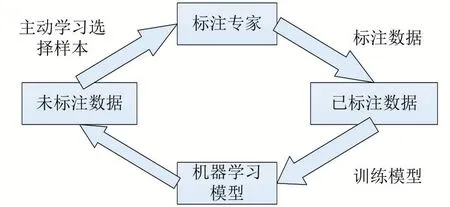
图1 主动学习流程
2 研究进展
2.1 使用预聚类的主动学习方法
使用预聚类的方法是收到了无监督学习的启发,该方法的核心思想是在每一轮的数据选择之前提前对数据进行聚类,以获取多个数据簇及聚类中心,再对聚类中心或数据簇中的数据使用主动学习算法进行选择。该类方法的最新研究成果是核心集方法[1]。
该方法包含了两种具体的实现方式,第一种是KCenter-Greedy 的方法。它将已标注数据定义为集合s,在每一轮的迭代中选择budget 个样本。在每一轮标注中,顺序选择k 个聚类中心中,与集合s 距离最远的点u 加入集合s。其中u 与集合s 定义为u 与集合中各个点距离的最小值,距离使用L2-norm 距离。其具体算法如表1 所示。第二种方法是Robust K-Center方法,其在K-Center-Greedy 的基础上进行了修改。它通过计算得到无标记点与集合s 的最远距离,设为δ2−OPT,此时所有的样本点都会在包括在这个半径δ2-OPT 内。通过计算Feasible 函数,去找到一组符合Feasible 函数的解,使得Feasible 内所有约束条件都满足,如果找到了,那么说明此时的半径δ不会使outlier的数量超过自己定的界限Ξ,半径δ可以缩小,即缩小上界ub;如果没有找到,那么说明此时的半径δ会使得outlier 数量超过界限Ξ,需要扩大半径,即扩大下界lb。直到最后,ub−lb 相等或者相差不大,算法停止。Feasible 公式如下所示,Robust K-Center 的具体算法如表2 所示。

该方法利用了CNN 提取到的特征进行聚类,并使用核心集的方法进行筛选,在深度学习的特征中选择了与已标注样本最远的数据点,因此该方法既考虑到了特征的代表性,又考虑到了样本的不确定性。

2.2 使用学习损失的主动学习方法
使用学习损失的主动学习方法[2]是由Donggeun Yoo 等人在2019 年提出。该方法的核心思想是使用了当前流行的多分支神经网络结构进行多任务学习。其结构如图2 所示。

图2
该方法使用了多分支网络,在学习目标任务的同时,增加一个分支进行loss 数值的学习。在该方法中,在神经网络提取特征的部分,将每一个大的网络块的特征进行提取并进行全局平均池化,使得各个层的特征值的维度统一,再将其进行连接并通过全连接层输出,得到预测的loss 数值。这样的方法能够提取到多尺度的特征,这意味着可以对图像的细节特征进行捕捉。其结构如图3 所示。

图3
在进行多任务学习时,该网络将会对任务本身的目标loss 值和预测loss 数值的loss 值进行加权整合,其公式为:

其中Ltarget为目标任务的loss,Lloss为学习loss 数值的loss。
由于在模型训练过程中,真实的loss 数值会不断变化,因此不能拿真实loss 数值本身作为预测loss 的真实值。该方法提出了一种新的loss 函数,对于每一个批次的B 个数据,将其分为两部分,成对进行计算,其公式为:
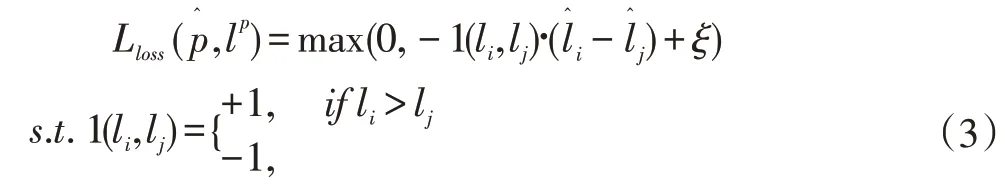
对于这个函数我们分析一下考虑第一种情况li>lj且模型预测的结果也满足那么损失值加上一个ξ后小于0,那么loss 取0 说明模型的预测关系是对的,不进行权重更新。如果li>lj但模型的预测的结果则损失函数值大于0 进行权重更新。这个损失函数则说明损失预测模型的实际目的是得到对应数据的损失值的大小关系而不是确定的损失值。
2.3 使用表征学习的主动学习
使用表征学习的主动学习方法由Samarth Sinha 等人[3]于2019 年首先提出,后在2020 年又基于此,由Ali Mottaghi 等人提出了对抗表征主动学习[10],和Beichen Zhang 等人提出了状态重标注表征主动学习[11]。它的主要思想是使用了表征学习中变分自编码器的思想,再加上深度学习中多任务学习以及多分支网络的形式,进行主动学习。该方法的基本结构如图4 所示。
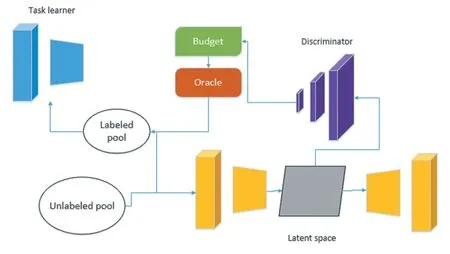
图4
该方法的目的是寻找出已标注数据和未标注数据的差异。它利用了变分自编码器进行特征提取,这样做的目的是为了在无数据标注的情况下,使用表征学习的方式将数据映射到一个潜层空间,数据在潜层空间的表示就是它的特征。同时它使用了一个判别器对数据是否是已标注数据进行打分,分值接近1 的为已标注数据,分值接近0 的为未标注数据。该方法使用了对抗式的训练方式,首先将判别器的参数进行固定,将数据的潜层空间特征都以标签为训练数据的形式送入判别器,进行变分自编码器的训练。再固定变分自编码器的参数,将数据的真实来源送入判别器进行判别器的训练。以此方式提取到的特征,对于较为接近训练集的未标注数据,会欺骗判别器使其打出高分,反之则会使判别器打出低分。再以此方式进行排序选择。
该方法使用了无监督学习的思想,挖掘了数据本身的特征,同时又无需修改目标模型本身,这意味着该方法具有很强的通用性,同时又在主动学习的过程中有着很好的效果。
3 结语
本文综述了在主动学习领域中三种最新的,同时又具有代表性的方法。三者的共同点在于:在深度学习的大背景下,试图寻找出最具有代表性的数据进行标注。不同点在于:基于预聚类的主动学习方法是通过对特征的聚类来选择最具有代表性特征的数据;基于学习损失的主动学习方法是通过模型的学习,学习到对模型来说最不确定的数据;而基于表征学习的主动学习方法是试图学习到数据的原始特征,在与目标模型无关的情况下进行数据的选择。从以上的内容介绍可以看出,基于主动学习的机器学习算法已经得到了广泛的关注,在深度学习高度发展的情况下,主动学习算法受到了越来越新的挑战。目前对于主动学习的探索仍然在朝着各个方向多面发展,而越来越新的方法在所发表的文献中所呈现出的实验结果,也证明了主动学习算法的研究价值。
猜你喜欢
今日农业(2022年15期)2022-09-20
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
小天使·二年级语数英综合(2019年10期)2019-11-08
科技与创新(2017年5期)2017-03-28
电子技术与软件工程(2016年23期)2017-03-06
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
电子设计应用(2004年6期)2004-07-27
