
基于Catboost的特征选择算法
2021-03-23 08:04:26王丽,王涛,肖巍,潘超
长春工业大学学报 2021年1期
王 丽,王 涛,肖 巍,潘 超
(长春工业大学 计算机科学与工程学院,吉林 长春 130012)
0 引 言
特征选择是机器学习中的一个重要步骤,并广泛应用于各领域,在训练模型过程中,不相关的特征会干扰模型学习的正确性,而冗余的特征不会提供任何有用的信息,反而增加模型的复杂性。特征选择的任务是从高维原始特征空间中选出一组有效的特征子集[1]。特征选择方法通过搜索相关特征并移除不相关特征来寻找最优特征子集,提高模型的处理性能,减少处理数据维度[2]。
特征选择方法分为对特征重要性进行排序和选择特征子集两种[3]。前者是根据一些测量标准对特征进行排序,并相应地选择排在顶部的特征;后者使用评价指标对特征子集进行评价,并筛选关键特征。两种方法都可以使用基于过滤式或包裹式方法进行选择[4]。在过滤式特征选择中,使用一定的评价指标评估每个特征的质量,不考虑它对结果产生的影响。包裹式的特征选择则根据一个或一组分类器的结果来衡量每个特征的影响,与过滤式方法相比,包裹式方法的计算密度更高,在预测结果方面更准确。但过滤式方法计算更快,结果准确性稍逊色于包裹式方法[5]。
一部分学者将特征选择划分出嵌入式方法,嵌入式方法将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行特征选择[6]。
尽管在计算开销上嵌入式方法要比包裹式方法小,但在速度上仍然要比过滤式方法慢很多,并且特征选择的效果很大程度上依赖所选择的学习器[7]。
集成学习是解决机器学习问题的重要方法之一,集成学习的主要策略是将弱学习器集成为一个强学习器,在输入一组标记样本到弱学习器后,通过生成的模型为新的未标记样本做出预测。其中,弱分类器可以是任何类型的机器学习算法,例如决策树、线性回归模型等[8]。集成学习在组合多个学习器过程中,单个学习器的误差可能会被其它学习器补偿,因此,模型整体的预测性能将优于单个学习器的预测性能。集成学习能够更好地解决特征选择问题,如Hakan等[9]提出的分类器集成方法应用于特征选择;Martin等[10]提出的使用应用过滤器集成解决多目标参数调整和特征选择问题;Omar等[11]提出的基于关联度、冗余度和依赖度准则的集成模糊特征选择;Ebrahimpour等[12]集成了分级算法和相似性度量两种过滤式方法对微阵列数据集进行特征选择。
Catboost是Dorogush等[13]最近提出的一种新的集成学习算法,具有独特的对称树结构,通过计算叶子节点的值来构造决策树,在此过程中,Catboost对特征进行了量化的度量。
利用基于Catboost树模型的特点,以其对特征的重要性排序作为启发式策略,与搜索策略相结合,提出一种新型的特征选择方法CABFS。以Catboost为基本工具,完成以下工作:
1)基于Catboost构建用于求解特征选择问题的启发式策略;
2)提出了基于2种重要性度量的搜索策略;
3)提出了一个新特征选择方法CABFS;
4)通过实验对CABFS的性能做了全面分析与验证。
1 背景知识
1.1 特征选择
特征选择问题旨在从原始特征集合中选择能提供更多有效信息的特征,同时去除掉不相关特征以及冗余特征。
因此,可以使用二进制来表示特征问题中的解决方案。在这种条件下,解决方案中的每个维度采用 1(选定)或 0(未选中)来表示在原始特征集合中选择或不选择相应的特征。特征选择过程可以表示为
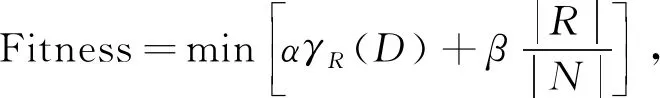
(1)
式中:γR(D)----分类器的分类误差率;
|R|----选择的特征数量;
|N|----原始特征选择集合中的特征数量;
α----分类误差率的权重,α∈[0,1];
β----特征子集中选出特征比例的权重,β=(1-α)。
1.2 Catboost
Catboost是一种新型的梯度提升算法,它是以决策树作为基本学习器的集成算法,不同于其它梯度提升算法,Catboost采用对称树的结构,在树的整个层次上使用相同的分割标准,这样的树是平衡的,并且加快了训练时间。Catboost的建树过程中,每棵树都是基于上一棵树的残差建立的。
Catboost可表示为
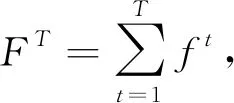
(2)
式中:FT----由多个弱学习器集成的强学习器;
ft----一棵决策树,下一棵树在现有树的基础上顺序构造而成。
损失函数为
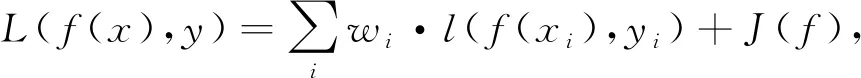
(3)
式中:l(f(xi),yi)----样本点(xi,yi)的损失;
wi----第i个目标的权重;
J(f)----正则化项。
Catboost使用前一棵树的预测结果来训练下一棵树,这个迭代过程使最终的预测结果更为准确,模型更具有鲁棒性。同时,Catboost提供了独特的特征重要性计算方式,为Catboost能够被用来做特征选择问题的启发式策略提供了重要依据。
2 CABFS算法描述
2.1 特征评价策略
重要性度量指标是评估每个特征在所属特征集中重要程度的一种衡量指标。Catboost提供了多种重要性度量指标。其中,预测值改变量(Prediction Values Change,PVC)显示特征值更改时预测值的平均变化程度,特征越重要,则预测值平均值的变化率越大。损失函数变化(Loss Function Change,LFC)描述当模型中有此特征与没有此特征时损失函数的变化,其变化量越大,则该特征越重要。故对确定结构的树模型有:
(v2-avr)2·leafright,
(4)
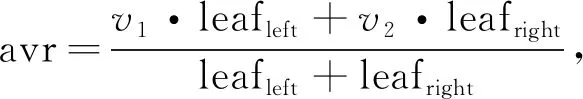
(5)
式中:leafleft,leafright----分别表示左叶子和右叶子的权重;
v1,v2----分别表示左叶子和右叶子的目标函数值。
LFCi=l(exi)-l(features),
(6)
式中:l(exi)----不包含特征i时模型的损失函数值;
l(features)----使用全部特征时模型的损失函数值。
2.2 特征选择过程
CABFS特征选择过程包含两个步骤:构造Catboost中的树模型和特征子集搜索策略。在构建树结构前,为了防止过拟合,每棵树的权重会随着选择不同的分割或不同的树而变化。在训练过程中,CABFS会连续构造一组树,每棵树会基于前一棵树的基础上,减少损失进行构建。构建一棵树分为两个阶段:选择树结构,得到多种树结构后,计算叶子节点的值。为了选择最佳的树结构,算法贪婪按顺序选择特征作为分割,并用这些分割构建一棵新树。重复以上过程,构建集成模型,依据2.1中的重要性度量指标对特征进行评分,生成新的特征重要性评价排名集合。
CABFS特征选择过程采用加权前向搜索策略进行实现,即在传统前向搜索的基础上进行改进,对特征的两个度量指标PVC与LFC赋予相应的权重进行搜索,两个指标分别代表特征变化时预测值的改变量以及有无第i个特征时损失函数的变化量。在不同应用场景下,面对不同的特征选择需求时,可以赋予两个指标不同的权重来进行侧重的衡量。文中实验目的是与其他已有的特征选择算法进行比较,不涉及特殊应用场景,故将两个指标都赋予了相同的权重便于比较。
具体搜索过程操作如下:设置一个起始元素为空的特征集合S,根据PVC与LFC加权后得到的综合评价指标对候选特征子集进行搜索,将搜索到的特征依次添加到集合S中,目标是当加入该特征后提高目标集合的适应度值。
2.3 伪代码
CABFS伪代码
输入:原始特征集合 O
输出:目标特征集合 T
步骤:
1:T ← Ø; depth ← 0
2:建立根节点
3:while depth < 树的最大深度 do
4: for each s ∈ O do
5: 计算最佳特征分割点并为最佳分割点建立孩子节点
6: end for
7: depth ← depth + 1
8:end while
9:根据式(2)将生成的树集成为统一的模型C
10:依据式(4)和(6)从C中生成重要性指标PVC和LFC
11:将PVC和LFC中相同特征对应的评价结果进行加权求和并排序,生成新的特征重要性评价排名集合I
12:定义最初的特征子集评价结果F(T) ← 0
13:for i in I do
14: T′← T∪i
15: 计算新的特征子集评价结果F(T′)
16: if F(T′)> F(T)
17: T←T′
18: F(T) ← F(T′)
19:end for
20:return T
3 实验结果与分析
3.1 实验数据与对比算法
使用UCI数据集中的一些经典数据集进行对比实验,详细信息见表1。
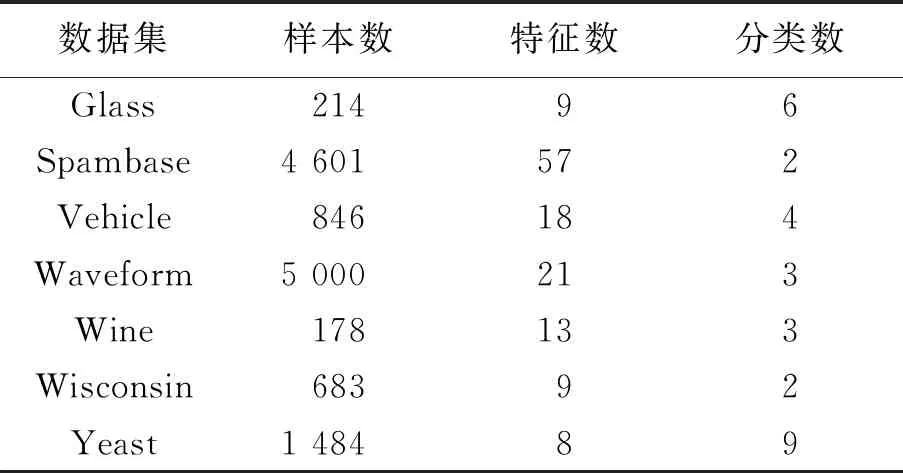
表1 UCI数据集 个
实验采用一些近年来具有代表性的特征选择算法与CABFS进行对比,见表2。

表2 对比算法
3.2 评价指标
实验采用特征分类准确率CA(Classification Accuracy)以及特征维度缩减率FR(Feature Reduction)对特征选择的效果进行评价,

(7)

(8)
3.3 实验结果与分析
CABFS及其对比算法在Glass、Spambase、Vehicle、Waveform、Wine、Wisconsin、Yeast上的结果分别见表3~表9。

表3 CABFS及其对比算法在Glass上的结果 %

表4 CABFS及其对比算法在Spambase上的结果 %
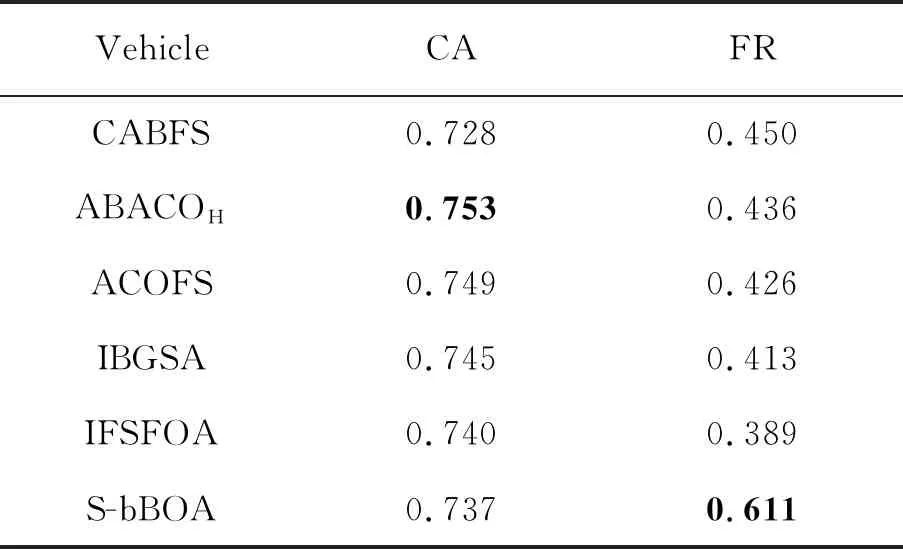
表5 CABFS及其对比算法在Vehicle上的结果 %
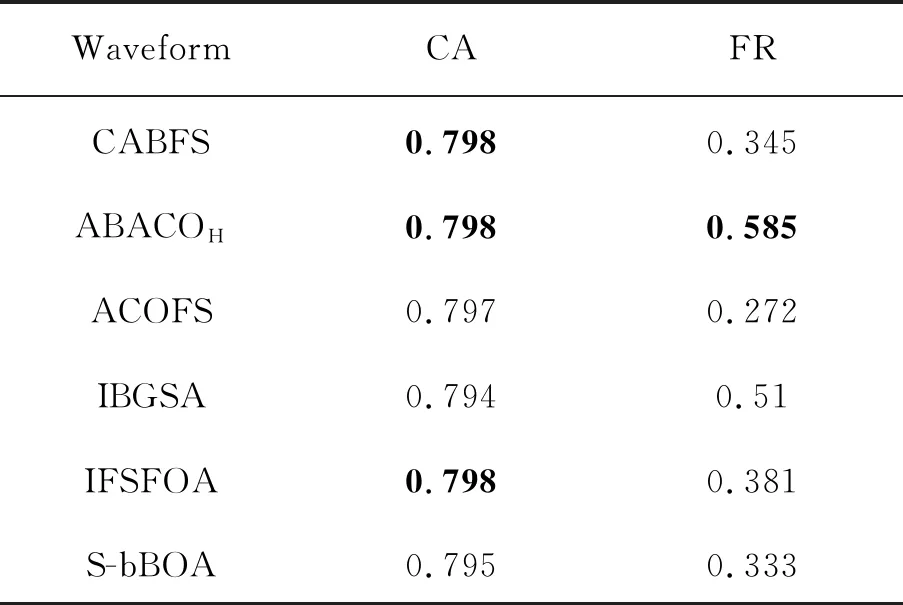
表6 CABFS及其对比算法在Waveform上的结果 %

表7 CABFS及其对比算法在Wine上的结果 %

表8 CABFS及其对比算法在Wisconsin上的结果 %

表9 CABFS及其对比算法在Yeast上的结果 %
通过表3~表9可以看到,CABFS在Glass、Spambase、Waveform、Wisconsin、Yeast这5个数据上的分类准确率均达到了最高,说明CABFS在一定程度上能够很好地确保分类准确率,而针对以上数据集的维度缩减率而言,CABFS仅在Spambase上达到了最优,另外几个数据集上的排名均在居中位置,这说明CABFS在追求分类准确率的同时,并没有完全的牺牲维度缩减率,而是一定程度上做到了兼顾,但是还无法保证两个衡量标准均达到最优的表现。
综合7个数据集的实验结果分析发现,大多数数据集的准确率都能在分类准确率或维度缩减率达到最优,只有Vehicle 数据集上的结果没有达到最优。之所以有这种情况,是因为CABFS算法应用于Vehicle 数据集上在建树时分割特征的过程中无法获得最优的分割点导致的,但在维度缩减率上能排在第2位置,能够说明CABFS对于降低数据维度方面相对其他对比算法而言,具有较好的效果。
4 结 语
CABFS将Catboost中构建树模型过程中的分割指标作为特征选择中度量特征重要性的标准,在传统前向搜索中对两种度量赋予了权值,并通过综合计算来进行搜索,实验结果证明,CABFS采用特征重要性度量作为启发式的策略是有效的,但在保证分类准确率结果好的情况下,如何进一步提高维度缩减率,仍需要更进一步的深入研究,并加以改进。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:26:02
中国生殖健康(2020年4期)2021-01-18 02:58:26
甘肃教育(2020年21期)2020-04-13 08:09:24
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
电子制作(2017年23期)2017-02-02 07:17:06
唐山文学(2016年11期)2016-03-20 15:26:04
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
西北工业大学学报(2015年4期)2016-01-19 03:31:47
