
基于PPO的机械臂控制研究方法
2021-03-22 17:05郭坤武曲张义
电脑知识与技术 2021年4期
关键词:机械臂
郭坤 武曲 张义


摘要:目前应用于机械臂控制中有许多不同的算法,如传统的自适应PD控制、模糊自适应控制等,这些大多需要基于数学模型。也有基于强化学习的控制方法,如:DQN(Deep Q Network)、Sarsa等。但这些强化学习算法在连续高维的动作空间中存在学习效率不高、回报奖励设置困难、控制效果不佳等问题。论文对基于PPO(Proximal Policy Optimization近端策略优化)算法实现任意位置的机械臂抓取应用进行研究,并将实验数据与Actor-Critic(演员-评论家)算法的进行对比,验证了使用PPO算法的控制效果良好,学习效率较高且稳定。
关键词:强化学习;机械臂;近端策略优化算法;Actor-Critic算法;离线学习
中图分类号: TP301 文献标识码:A
文章编号:1009-3044(2021)04-0222-04
Abstract: In manipulator control, there are many different control methods, such as traditional adaptive PD control and fuzzy adaptive control, which are mostly based on mathematical models. There are also control methods based on reinforcement learning, such as DQN (Deep Q Network), Sarsa, etc. However, these reinforcement learning algorithms have some problems such as low learning efficiency, difficulty in setting rewards, and poor control effect in the continuous high-dimensional action space. According to Proximal Policy Optimization algorithm, the application of robot arm grasping at any position is studied, and the experimental data is compared with actor-critic algorithm, which proves that the PPO algorithm has good control effect, high learning efficiency and stability.
Key words: reinforcement learning; robot manipulator; proximal strategy optimization algorithm; Actor - Critic algorithm; offline learning
目前在機器学习领域,根据学习系统与环境交互方式的不同,机器学习大致上可分为三种学习方法——强化学习、监督学习、无监督学习[1]。在基于行为的智能机器人控制系统中,机器人是否能够根据环境的变化进行有效的行为选择是提高机器人的自主性的关键问题[2]。随着信息技术的发展,以强化学习为代表的智能算法以其自适应特性越来越多运用于机器人控制领域[3,4]。其中机械臂控制作为机器人控制的重要模块发展迅速,深度强化学习(DRL)的出现使得机械臂具备了自主学习能力[5],解决了机械臂只能通过固定程序完成任务,在复杂高维的环境中无法自适应训练学习的问题。
在深度强化学习中,典型的优化策略有深度Q网络(DQN)[6] 、深度SARSA(State Action Reward State Action)[7]和彩虹(Rainbow)[8]等。这些方法多用来处理离散动作低维度的问题,无法应用于机械臂抓取这类连续动作。虽然策略梯度(Policy Gradients)、演员-评论家(Actor-Critic)等方法,能应用于连续空间,但基于Actor-Critic算法的近似策略优化PPO(Proximal Policy Optimization)方法在处理学习率的问题上表现更加优异,能更好地应用于机械臂控制问题。
1 强化学习
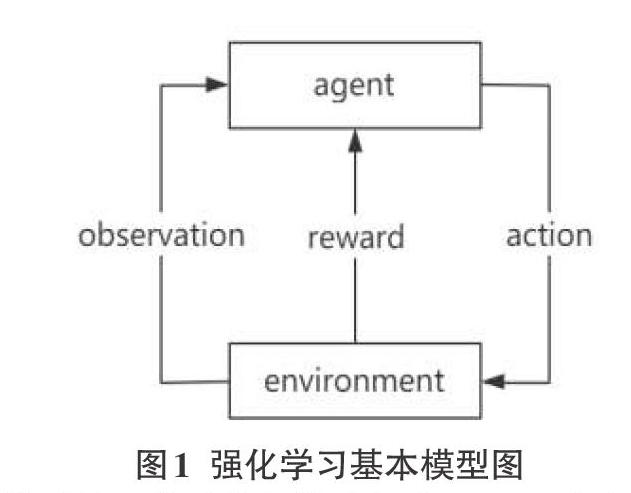
强化学习是一种无监督学习方法,Agent 通过与动态环境的反复交互,学会选择最优或近最优的行为以实现其长期目标[9]。Sutton 和 Barto 定义了强化学习方法的四个关键要素:策略、奖赏函数、价值函数、环境模型[10]。如图1,Agent通过与Environment反复交互进行学习,每次交互中Agent采取某种动作传入Environment,Environment根据传入的动作向Agent提供观测值以及奖励值,来使Agent做出新的动作。强化学习的目的就是Agent通过与环境的不断交互,来获得最优的累计奖励值。
如图2所示,Agents分为三类,虽然Value-Based的强化学习可以有效完成连续状态空间的问题,但它的动作空间仍是离散的,也无法学习随机策略或应用到高维空间。而Policy-Based虽然能解决上述问题,但缺点是只能局部收敛且评估策略效率低方差很大。Actor-Critic结合了前两种类型的优点,通过策略梯度的方法选择动作,同时也保存在每个状态所得到的奖励。
2 Actor-Critic算法
Actor-Critic算法将Value-Based和Policy-Based结合,具有Actor和Critic两种不同的体系,可以看作两个不同的神经网络。
此算法的主要思想是不使用reward来评估真实价值函数,而是利用Critic网络来评价价值函数,用Policy函数作为Actor,生成动作与环境进行交互,Critic来评价指导观察Actor的动作并做评价。Critic的评估action-value函数是基于[πθ]的近似如公式(1):
其中s为状态,a为动作,[πθ]代表策略。所以Actor-Critic算法是遵循近似的Policy Gradient(策略梯度)如公式(2):
Critic网络需要更新参数w,Actor网络需要更新参数θ,基本的Actor-Critic算法流程如算法1所示:
算法1 Actor-Critic算法
输入:[γ,α,β,θ,w]
輸出:optimized[θ,w]
1.Initialize:s,θ
2.Samplea~[πθ]
3.foreachstepdo
4. Samplerewardr=[Ras];sampletransition[s'?Pas],
5. Sample action [a'?πθs',a']
6. [δ=r+γQws',a'-Qws,a]
7. [θ=θ+α?θlogπθs,aQws,a]
8. [w←w+βδ?s,a]
9. [a←a',s←s']
10.end for
结束算法
Actor-Critic算法成比例的优化Critic模型,使它向着TD error(TD误差)乘以特征的方向(误差最小化)进行优化,此处的误差指估计的价值和执行步骤后现实的价值之间的。Actor模型实际决定在环境中做什么,并向Critic模型认为价值高的方向优化。
3 PPO(Proximal Policy Optimization近端策略优化)算法
Actor-Critic采用在线更新方法,不能经验回访,PPO(Proximal Policy Optimization近端策略优化)基于Actor-Critic算法,应用Important-sampling实现离线更新。PPO在每步迭代中都更新新的策略,在保证损失函数最小的同时减少与上一步策略间差值,所以引用Important-sampling数学方法,在有连续随机变量x,[px]、[qx]为概率密度,[fx]的期望表示如公式(3)所示:
[pxqx]为Importance Weight,是新旧策略在当前状态s采取动作a对应的概率比。在ppo中的一个回合中不断重复对[qx]充分采样,来改进新策略[px],则N回合平均奖励值的梯度为公式(4):
ppo在更新Actor时,使用clipped surrogate objective的方式,对[pθat|stpθ'at|st]进行clip操作,[clippθat|stpθ'at|st,1-?,1+?]([?]为可调超参数)。
算法2 PPO算法
输入:[s]环境状态
输出:a动作
1.Initialize:Actor[A(s∣θA)]网络、Critic[C(s,a∣θC)]网络、Clip
2.for episode=1 to M do
3. for t=1 to T do
4. [at←A(s∣θA)]
5. 执行[at],获得单步奖励[rt]
6. 更新Actor网络权重[θA]
7. 更新Critic网络[θC]
8. end for
9.end for
4 实验设计与实现
4.1 实验机械臂设计
本文使用python中pyglot可视化库来构建二维机械臂环境来实现机械臂抓取控制。仿真环境参考了周沫凡的 2D机械臂仿真模型[11],在此基础上对环境进行修改,使其更易于实现PPO的仿真实验。如图4所示,以o为中心点建立机械臂初始中心点,实验中将始终绕o转动,利用三角函数与设定L1、L2臂长计算每段手臂4个端点坐标,以便机械臂随机生成转动角α、β时记录对应坐标。同时环境每次刷新目标位置也随机生成,实现任意位置的机械臂抓取,不仅丰富训练数据,也能测试算法的稳定性。
4.2 实验参数设置
通过仿真环境获取转动角α、β与对应坐标关系,向三层全连接神经网络输入7维状态空间(L1末端与o点水平距离和垂直距离、L2末端与o点水平距离和垂直距离、o点与仿真环境中心点水平距离和垂直距离、是否达到目标位置),输出2个动作(关节转动角度)。
因为稀疏的回报值学习效果很差,所以在设置奖励回报时将离散回报值改写为连续回报值,当机械臂L2末端(x2,y2)离目标位置(xo,yo)相对距离越近奖励值越大,相对距离表示为Dabs=[x2-x02+y2-y02],奖励回报值公式(5)如下:
4.3实验效果与分析
实验效果如图5所示,在交互界面上可任意移动目标位置,机械臂都能准确地实现快速抓取,说明了PPO有良好的学习效果。
在将Actor学习率、Critic学习率、训练次数、训练网络单次提取的数据Batch_size、衰减率等共有参数均保持相同的情况下,比较 PPO与Actor-Critic深度强化学习算法,验证PPO更适用于机械臂控制。
图6、7分别表示PPO与Actor-Critic前1000集奖励函数图,虽然显示两种算法都能在该环境中达到良好学习效果,但 PPO能在更少的集数中取得最更大的奖励值,与Actor-Critic比较收敛速度提高了27.58%学习效率更高,且明显获得的奖励值更高。
图8表示了两种算法训练最后100集所用步数,共分为10组对比区间内累计step。Actor-Critic的平均步数是117.28,PPO的平均步数是101.96,通过对比发现PPO所使用的step更少并且数据波动浮动相对稳定,训练效果更好。
5 结束语
本文通过实现基于PPO算法的机械臂任意位置抓取,根据成功训练出的仿真结果与 Actor-Critic算法实现的数据对比,分析应用在机械臂实验中强化学习算法效果,验证了PPO能实现良好的学习效果,学习效率较高且稳定。
参考文献:
[1] 褚建华. Q-learning强化学习算法改进及其应用研究[D].北京化工大学,2009.
[2] 秦志斌,钱徽,朱淼良.自主移动机器人混合式体系结构的一种Multi-agent实现方法[J].机器人,2006,28(5):478-482.
[3] Liu Q, Zhai J W, Zhang Z C, et al. Review of deepreinforcement learning[J]. Chinese Journal of Computers,2018(1): 1-27.
[4] Wang S, Chaovalitwongse W, Babuska R. MachineLearning Algorithms in Bipedal Robot Control[J]. IEEETransactions on Systems Man & Cybernetics Part C, 2012,42(5):728-743.
[5] 劉全,翟建伟,章宗长,等.深度强化学习综述[J].计算机学报,2018,41(1):1-27.
[6] Mnih V,Kavukcuoglu K,Silver D,et al.Human-levelcontrol through deep reinforcement learning[J].Nature,2015,518(7540):529-533.
[7] Zhao D,Wang H,Shao K,et al.Deep reinforcementlearning with experience replay based on sarsa[C]//Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence(IEEE-SSCI),2016:1-6.
[8] Hessel M,Modayil J,Van Hasselt H,et al.Rainbow:combining improvements in deep reinforcement learning[J].arXiv preprint arXiv:1710.02298,2017.
[9] Wang Z,Shi Z,Li Y,et al. The optimization of path planning for multi-robot system using Boltzmann Policy based Q-learning algorithm[C]/ /2013 IEEE International Conferenceon Robotics and Biomimetics(ROBIO). Shenzhen,2013:1199 -1204.
[10] Sutton, R, Barto, A. Reinforcement Learning: An Introduction[M]. MIT Press, 1998.
[11] Morvanzhou. Train a robot arm from scratch[Z]. 2017: [2018-10-4].
【通联编辑:唐一东】
猜你喜欢
科技与创新(2016年23期)2017-03-30
山东工业技术(2017年4期)2017-03-28
求知导刊(2017年1期)2017-03-24
计算机教育(2016年7期)2016-11-10
现代电子技术(2015年17期)2015-09-23
