
基于Spark平台的网络攻击检测系统
2021-03-22 02:53龚剑敏颜涛周亮
电脑知识与技术 2021年4期
龚剑敏 颜涛 周亮

摘要:随着计算机技术和通信技术的飞速发展,网络安全形势也越来越严峻,如何在海量日志中发现安全攻击是个值得研究的问题,传统的日志分析方法效率低,难以发现一些高级的网络安全威胁。针对该问题,提出了基于分布式存储和Spark框架的网络日志分析系统架构,不仅有效利用了云环境中的计算存储资源,同时还大大提高了计算效率。
关键词:分布式计算;网络攻击;日志分析;拒绝服务攻击
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2021)04-0044-02
Abstract:With the rapid development of computer technology and communication technology, the network security situation is becoming more and more serious. How to find security attacks in massive logs is a problem worth studying. Traditional log analysis methods are inefficient and difficult to find some advanced network security threats. To solve this problem, a network log analysis system based on distributed storage and spark framework is proposed, which not only effectively utilizes the computing storage resources in cloud environment, but also greatly improves the computing efficiency.
Key words: distributed computing; network attack; log analysis; denial of service attack
随着计算机技术和通信技术的飞速发展,网络数据呈指数级上升,服务器端接收到的用户访问日志文件的数据量越来越多,网络安全威胁形势也越来越严峻,攻击手段越来越隐蔽,如何在海量日志中发现安全攻击是个值得研究的问题。本文提出了一种基于分布式存储和Spark框架的网络日志分析系统架构,不仅有效利用了云环境中的计算存储资源,同时还大大提高了计算效率。
1相关技术概述
本文设计的检测系统是针对实时数据进行计算和分析,目前对于大量实时数据进行流式计算的最实用的组件是 Spark Streaming,本系统采用 Kafka 用于收集服务器的访问日志,接下来介绍 Spark和Kafka。
1.1 Spark框架
Spark是由加州伯克利大学提出的一种分布式数据处理框架,可用于构建低延时的大型数据挖掘应用程序。Hadoop中 MapReduce 会产生巨大的 I/O 开销,Spark采用内存计算克服了这一弱点,提高了性能[1]。SparkStreaming 是一个 Spark 针对实时数据进行计算和分析设计的模型。具有高吞吐率和高容错率等特点。SparkStreaming 可以处理多种不同类型的数据源, 比如 Kafka,flume 等。通过 SparkStreaming 计算得到的结果有两种操作:一种是转化操作,继续进行新的计算;另一种是输出操作,把数据寫入外部系统中,存储到数据库或者应用到实时系统显示界面中。SparkStreaming 相较于其他处理引擎最大的优势是可以同时进行批处理和流处理,还具有强大的容错性。
1.2 Kafka分布式消息中间件
Kafka是近年来使用较多的分布式消息队列中间件,是由 LinkedIn 研发[2]。如今被广泛应用于分布式集群应用之中,当作多种类型的数据管道和消息系统。 Kafka 的出现起到了两个作用:一方面是降低了系统组网的复杂程度,另一方面减少了编写程序的难度,每个子系统并非是彼此协调的接口,而是像插口插在插座上,而 Kafka 起着极速数据总线的角色。
Kafka主要的特点如下:
(1)能够同时发布和订阅,供给高吞吐量。据统计,Kafka 以秒为单位能够产生大约 25 万信息(50Mb),每秒处理达到 55 万信息(110MB)。
(2)持久化操作。将信息持久化到磁盘中因而可用于成批的消耗,例如 ETL。采取将数据持久化到磁盘的方式以及拷贝(Replication) 预防数据遗失,为数据安全提供了保障。
(3)分布式系统,便于向外扩展。所有的 Producer、Broker 和 Consumer 都有多个,而且全都为分布式,便于扩展机器。
(4)信息被操作的阶段是在 Consumer 端维护,而不是 Server 端维护。当失败的时候能够自动平衡。
2系统的设计与实现
低速率拒绝服务攻击(Low-rate Denial-of-Service,简称LDoS)是近年来提出的一类新型攻击[4],其不同于传统洪泛(flooding)式的DoS攻击,主要是利用端系统或网络中常见的自适应机制所存在的安全漏洞,通过低速率周期性攻击流,以更高的攻击效率对受害者进行破坏且不易被发现,本文主要针对该类型的攻击检测展开研究。如图所示,基于Spark的低速率拒绝服务攻击检测系统模块主要分为:数据采集模块,数据处理模块,特征提取模块,检测模块,预警模块和异常处理模块。
(1)数据采集模块。根据 Kafka+Spark 架构,提取服务器端的实时数据流日志文件,并将初始数据集存储在 Hadoop 的分布式文件存储系统中。
(2)数据处理模块,对初始数据集进行数据预处理,并将数据集切片处理,将一个大的时间周期内的数据集切分成多个小的时间周期,计算相应的吞度量、时延、高频信号的能量值、低频信号的能量值、流量峰值、阻塞指数等特征值。
(3)检测模块,将提取的特征数据集放入提前训练好的随机森林模型中,判断该事件段内服务器端是否受到了LDoS 攻击。
(4)预警模块,当检测模块发现某时间段内大量特征值检测超过正常值范围,即模型认为该时间段服务器端收到了LDoS 攻击,就会触发报警机制,提醒管理人员,在该时间间隔内,服务器收到攻击。
(5)异常处理模块,管理员可以根据发生的时间间隔内的同一IP出现的频率过高或者是同一IP段内同一地区内的 IP 出现过多时,采取屏蔽IP段或者屏蔽某一块地区访问权限。
3系统仿真实验
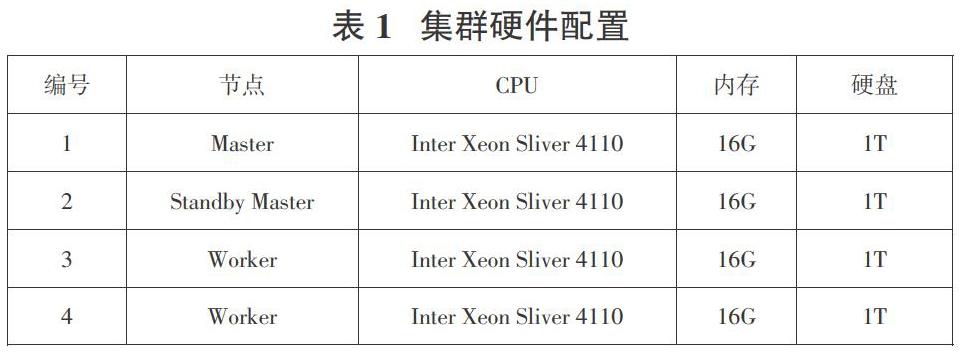
实验设计如下:在一台物理服务器上搭建 4 台虚拟机,其中一台作为主节点,一台作为备用节点,剩余两台作为 Slave 节点。实驗具体硬件配置如表 1 所示。另外在一台内存为 16G,硬盘空间为 1T的物理机上安装相同的环境作为对照。
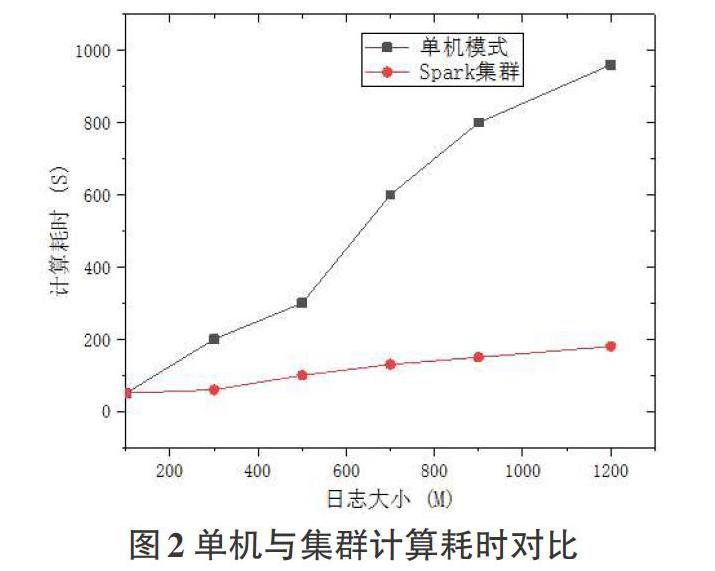
为了保证实验的公平性,本次实验是基于离线数据集批处理过程,初始数据集大小设置为 5 组数据集,分别约为 100M,300M,500M,700M,1T,1.2T。每组的数据量不相同,但攻击数据流的攻击周期,攻击时长,攻击速率以及正常数据流通信的速率, 滑动窗口大小都一致,且都不存在噪声数据。数据分布相似,能够用来作对比实验。经过实验结果统计得到本文提出的检测模型在单机和集群下的不同耗时如图 2所示。由此可见,数据集比较小的时候,单机模式和集群模式下的算法耗时 时长没有明显差异,但数据集越大时,集群模式下的算法耗时优势越明显,而且, 本次实验集群只有两台 Worker,如果有多台 Worker 同时运行,耗时将会更短。 因此,对于一个日活跃用户达到万级的特小型网站来说,假设每个用户每天的点击量是 10 次,那么每天服务器端将收到数十万条的日志数据,因此,采用集群模式的低速率 DoS 攻击检测系统,效率要远高于单机模式下的攻击检测系统。
4总结
本文主要介绍了 Spark,Kafka 的工作原理,以及基于分布式的 LDoS 攻击检测系统的部署和实现流程,并且通过仿真实现对比了单机系统和集群系统的工作效率。实验证明,本文提出的基于Spark的网络日志分析系统能有效地提高日志分析的效率。
参考文献:
[1] 李晓燕,郭亚峰.面向Hadoop的分布式日志分析系统[J].计算机产品与流通,2020(3):111.
[2] Kafka 2.6 Documentation. http://kafka.apache.org/documentation/#gettingStarted [EB/OL].2020,11.
[3] 石乐义,刘佳,刘祎豪,等.网络安全态势感知研究综述[J].计算机工程与应用,2019,55(24):1-9.
[4] 李芳菊.基于Hadoop的网络行为大数据安全实体识别系统设计[J].现代电子技术,2019,42(17):75-79.
[5] 刘军,冷芳玲,李世奇,等.基于HDFS的分布式文件系统[J].东北大学学报(自然科学版),2019,40(6):795-800.
[6] 王建仁,马鑫,段刚龙.改进的K-means聚类k值选择算法[J].计算机工程与应用,2019,55(8):27-33.
[7] 陆勰,罗守山,张玉梅.基于Hadoop的海量安全日志聚类算法研究[J].信息网络安全,2018(8):56-63.
[8] 刘景云.搭建HDFS分布式文件系统[J].网络安全和信息化,2018(2):100-103.
[9] 周波.基于Apache Flume的MR数据采集实现方案[J].电信科学,2018,34(S1):216-221.
[10] 刘芬,廖荣涛,余铮.Hadoop下的在线网络日志分析系统设计[J].电子技术与软件工程,2017(22):20.
【通联编辑:代影】
猜你喜欢
