
无金标准部分核实数据下基于Bootstrap的小样本齐性检验
2021-03-22 04:28伏启翔王黎明邱世芳
重庆理工大学学报(自然科学) 2021年2期
伏启翔,覃 愿,王黎明,邱世芳
(重庆理工大学 理学院,重庆 400054)
估计疾病流行率是生物医学研究中的一个重要问题。为收集数据,价格便宜的筛检方法常被用来做初步诊断,但由于其分类误差而导致有误的分类结果,进而导致基于这些有误分类数据的统计推断不太合理。无误判的金标准通常存在昂贵、耗时等不足,因而常不能用于每个个体的检验。为此,Tenenbein[1]提出了二重抽样方法,即从感兴趣的总体中抽取的样本(如N)都接受筛检检验,然后再随机抽取部分个体(如n)再次接受金标准检验。由于这n个个体同时接受了筛检检验和金标准检验,反映了个体的真实特征。因而通过二重抽样方法得到的数据又称为部分核实数据[2]。对于有金标准部分核实数据的研究得到了很多学者的关注,如Tenenbein等[3-4]将二重抽样方法推广到多项分布数据的研究,Hochberg[5]推广到多维数据的研究,Geng等[6]发展了部分核实数据的Bayesian分析方法。对于有序部分核实数据,Poon等[7]发展了一类参数模型,Qiu等[8]从有序效应度角度研究了疾病流行率的等价性评价问题。以上研究都是基于有金标准下的研究,事实上,临床诊断中并不一定存在完全无误判的金标准。当2种检验都有误判时基于部分核实数据的统计分析具有重要的现实意义。为此,Nedelman[9]基于条件独立性假定提出了3种模型并研究了疾病流行率、敏感度和特异度的估计问题,Lie等[10]基于2种二重抽样模型进行了研究。在Nedelman等[9-10]提出的模型基础上,Qiu等[11-13]基于无金标准部分核实数据研究了假设检验、区间估计及样本量确定问题。疾病流行率的研究可能受到年龄、性别等混杂因素的影响,因而将这些混杂因素看成分层变量,研究分层设计下的部分核实数据的统计推断问题是一种重要的研究问题。在小样本下基于大样本渐近分布的检验过程常常会得到不太令人满意的结果,因而在小样本下研究基于分层设计下的部分核实数据对疾病流行率的齐性检验是一个有意义的研究问题。
1 统计模型与参数估计
假设存在有误判的2种分类器(初级分类器J和高级分类器S)。从第j层(j=1,2,…,J)总体中随机抽取Nj个个体接受初级分类器进行检验,Jj=1表示第j层的个体被诊断为阳性,反之,Jj=0;然后再从中随机抽取nj(nj<Nj)个个体接受高级分类器的检验,Sj=1表示被诊断为阳性,反之,Sj=0。从而得到如表1所示的部分核实数据。
设Dj=1表示第j层中个体患病,反之,Dj=0;令πj=Pr(Dj=1)表示第j层中个体患病的概率,ηj=。为了使模型可识别,不妨假定不存在假阳性。

表1 第j层部分核实数据
1.1 模型1及参数估计

表2 模型1下第j层概率结构
以下为齐性检验:H0:π1=π2=…=πJ=π↔H1:至少有一对πi≠πj(i≠j)。
设mj=(n11j,n10j,n01j,n00j,xj,yj),π=(π1,…,πJ)′,η=(η1,…,ηJ)′,θ=(θ1,…,θJ)′,则基于m={mj:j=1,2,…,J}的对数似然函数为:l1(m;π,η,θ)=,其中

显然,πj,ηj,θj的非限制性极大似然估计是方程组的解。根据文献[12]可得,当n11jn00j≥n10jn01j时,

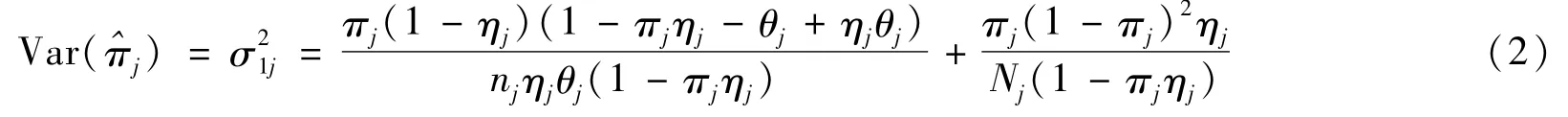
在H0:π1=π2=… =πJ=π下,π,ηj,θj的限制性极大似然估计是如下方程组的解:,由于无显表达式,因而可用牛顿迭代法等求得方程组的解。
1.2 模型2及参数估计

表3 模型2下第j层概率结构
基于m={mj∶j=1,2,…,J}对数似然函数为,其中:
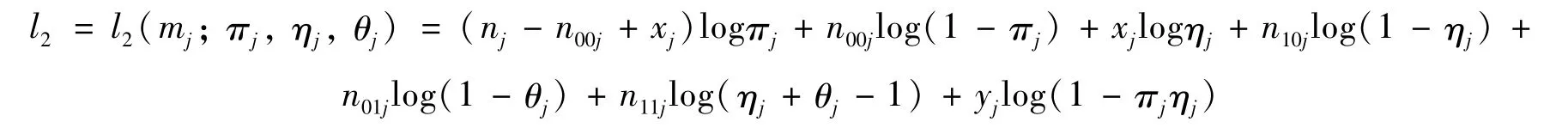
则πj,ηj,θj的非限制性极大似然估计为
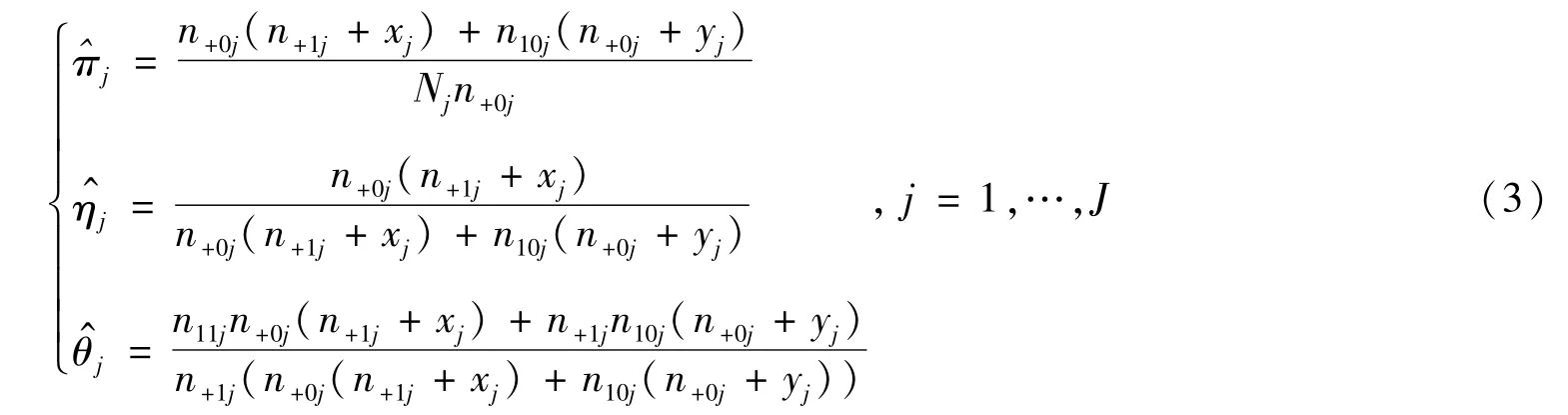
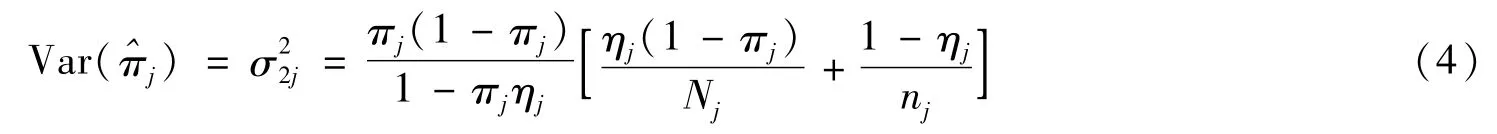
在H0:π1=π2=… =πJ=π下,π,ηj,θj的限制性极大似然估计通过求解以下两式:,得到:
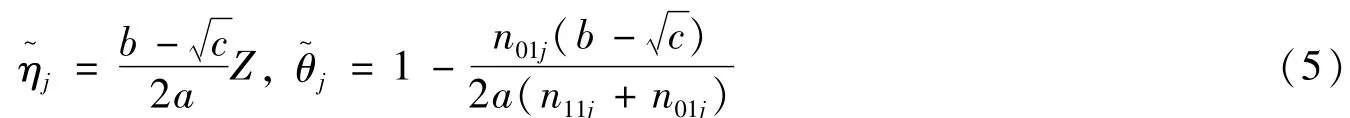
2 齐性检验统计量
2.1 Score检验统计量
根据Rao[14]所提出的Score检验的一般理论,在2种模型下,经过简单计算可得在H0:π1=π2=…=πJ=π成立下的Score检验统计量为
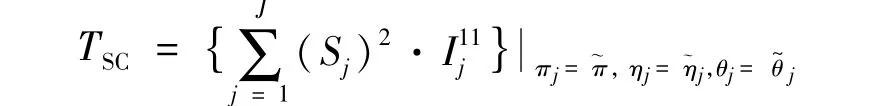
其中Sj是2种模型下的Score函数,
I11j为第j层Fisher信息阵的逆矩阵的第一主对角元素(见附录)。当Nj→∞(j=1,2,…,J)时,检验统计量Tsc渐近服从自由度为J-1的卡方分布[15]。
2.2 加权最小二乘估计检验统计量
根据研究,可得如下的加权最小二乘估计检验统计量[16]:
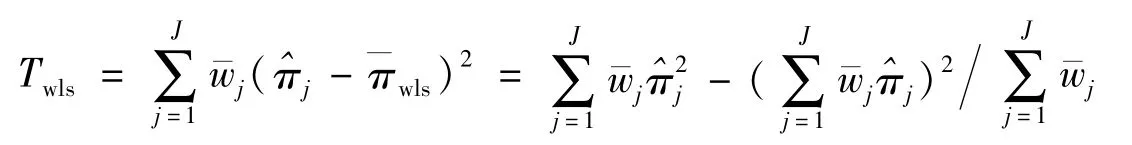
2.3 基于log变换的加权最小二乘估计检验统计量

2.4 基于logit变换的最小二乘估计检验统计量
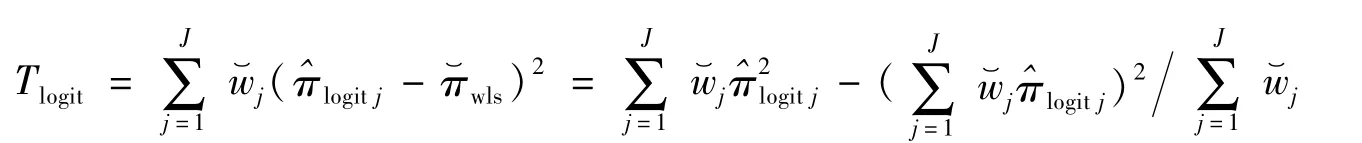
式中:渐近服从于自由度为J-1的卡方分布。
2.5 基于双对数变换的最小二乘估计检验统计量
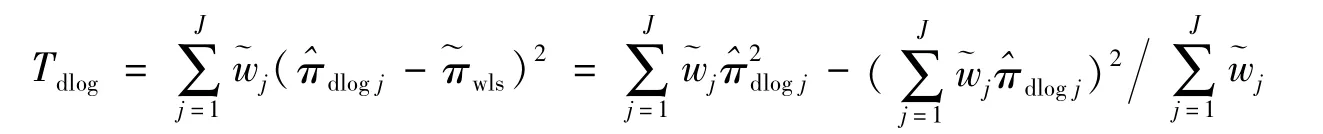
3 检验过程
3.1 渐近的检验方法
3.2 基于Bootstrap的检验方法
4 模拟研究
为评价提出方法的有效性,考虑如下的样本量:①平衡设计nj=20,Nj=30(j=1,2,3);②非平衡设计:(n1,n2,n3,N1,N2,N3)=(10,10,15,20,15,30)和参数设置:π=0.10(0.20)0.50;η1=0.50(0.05)0.60,η2=η1+0.05,η3=η1+0.10;θ1=0.70(0.05)0.80,θ2=θ1+0.05,θ3=θ1+0.10研究各种检验的犯第1类错误的概率,模拟结果列于表4、5。同时,考虑以上2种样本量下δ=0.10(0.10)0.30和以上参数设置各检验的功效,由于篇幅的限制,本研究只列出了nj=20,Nj=30(j=1,2,3)下的模拟结果,如表6所示。
模拟结果表明,2种模型下基于Bootstrap的小样本检验过程优于渐近的检验方法,前者犯第1类错误的概率更接近名义水平且具有更高的功效,而后者在小样本下犯第1类错误的概率太保守。特别地,基于Score检验的Bootstrap检验过程在2种模型下的犯第1类错误的概率最接近名义水平。
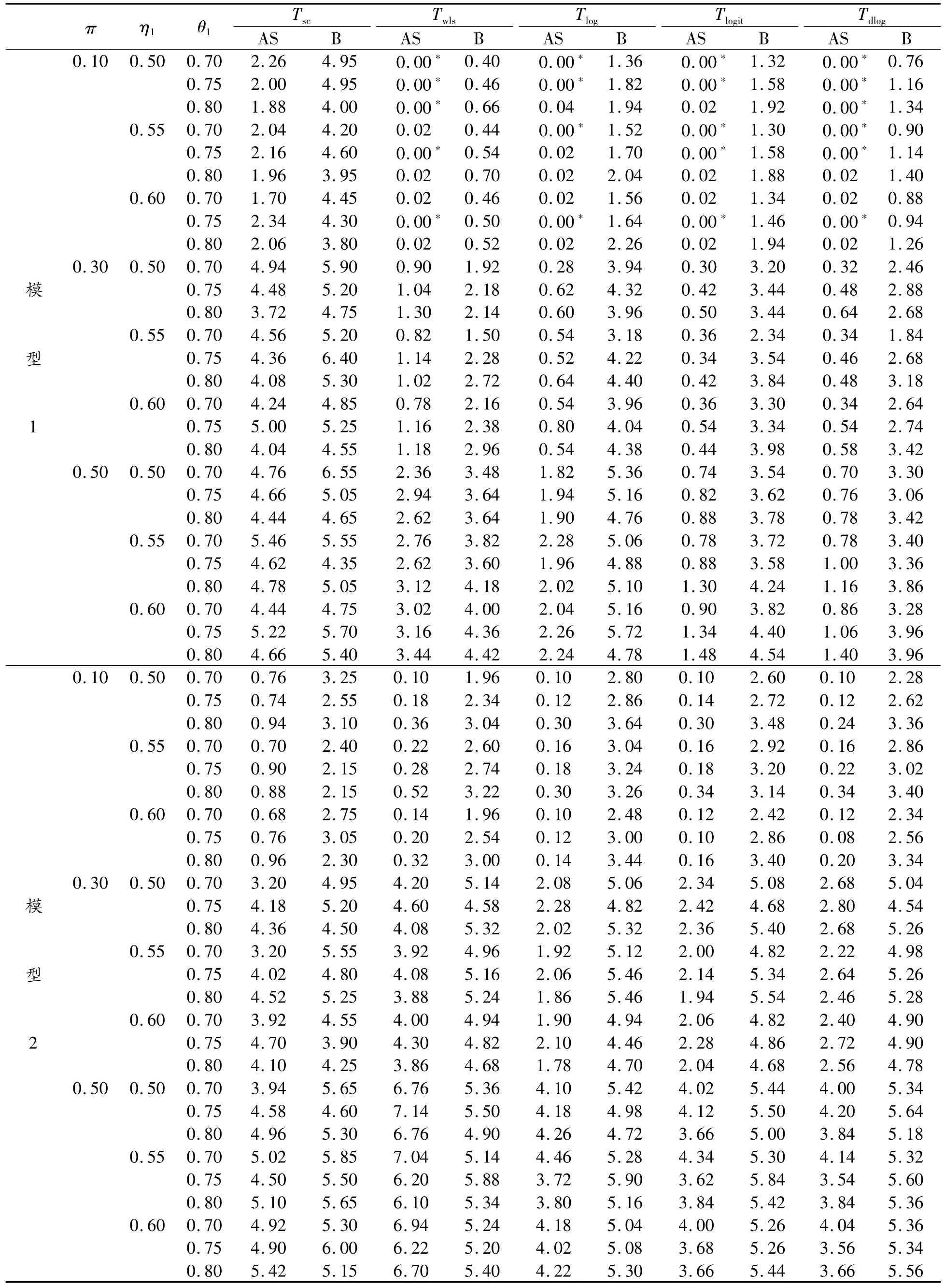
表4 平衡小样本量nj=20,Nj=30(j=1,2,3)下各检验统计量在显著性水平为α=0.05下犯第1类错误的概率(%)
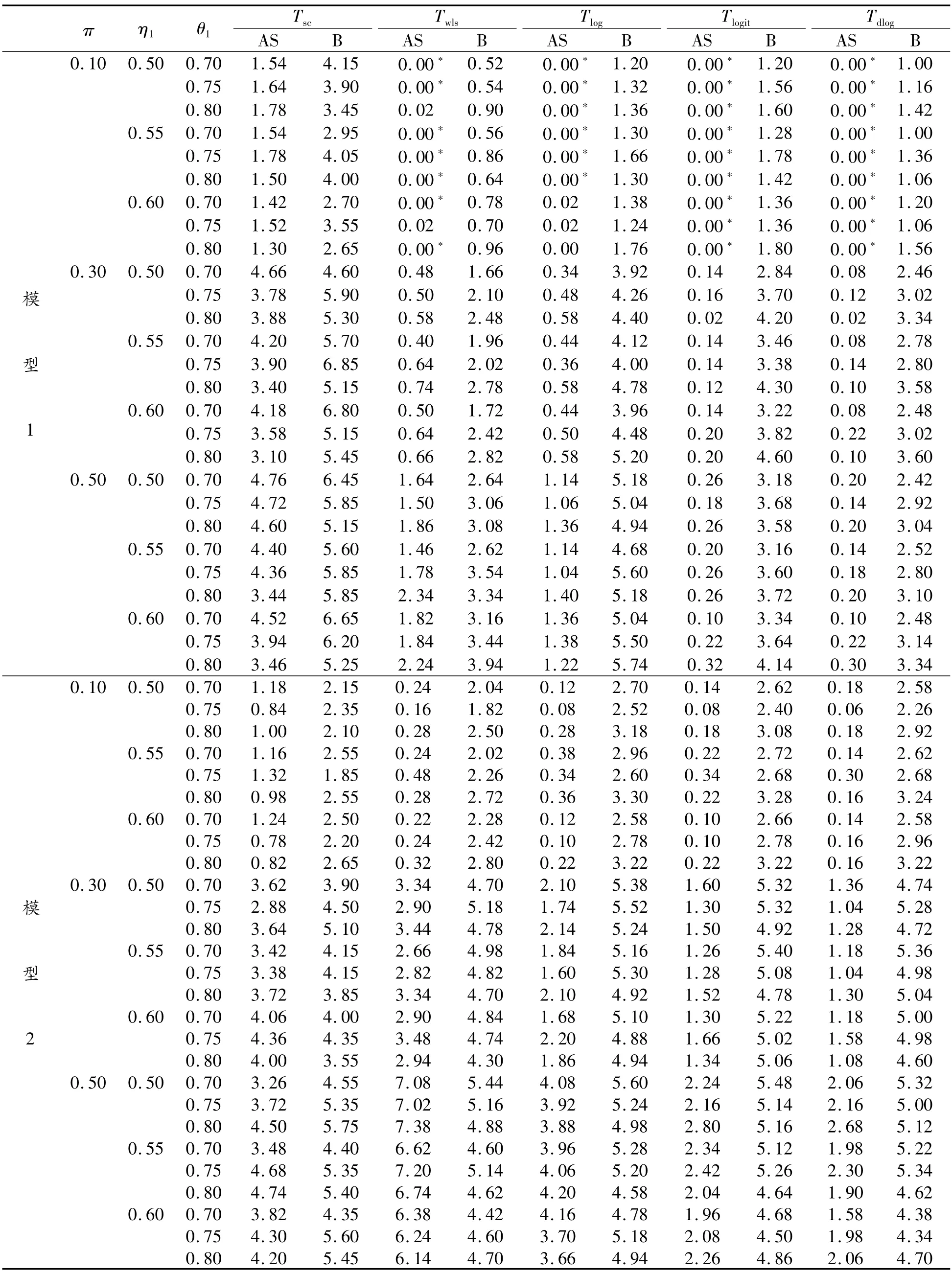
表5 非平衡小样本量设置下(n1=10,n2=10,n3=10;N1=20,N2=15,N3=30)各检验统计量在置信水平α=0.05下犯第1类错误的模型结果概率(%)
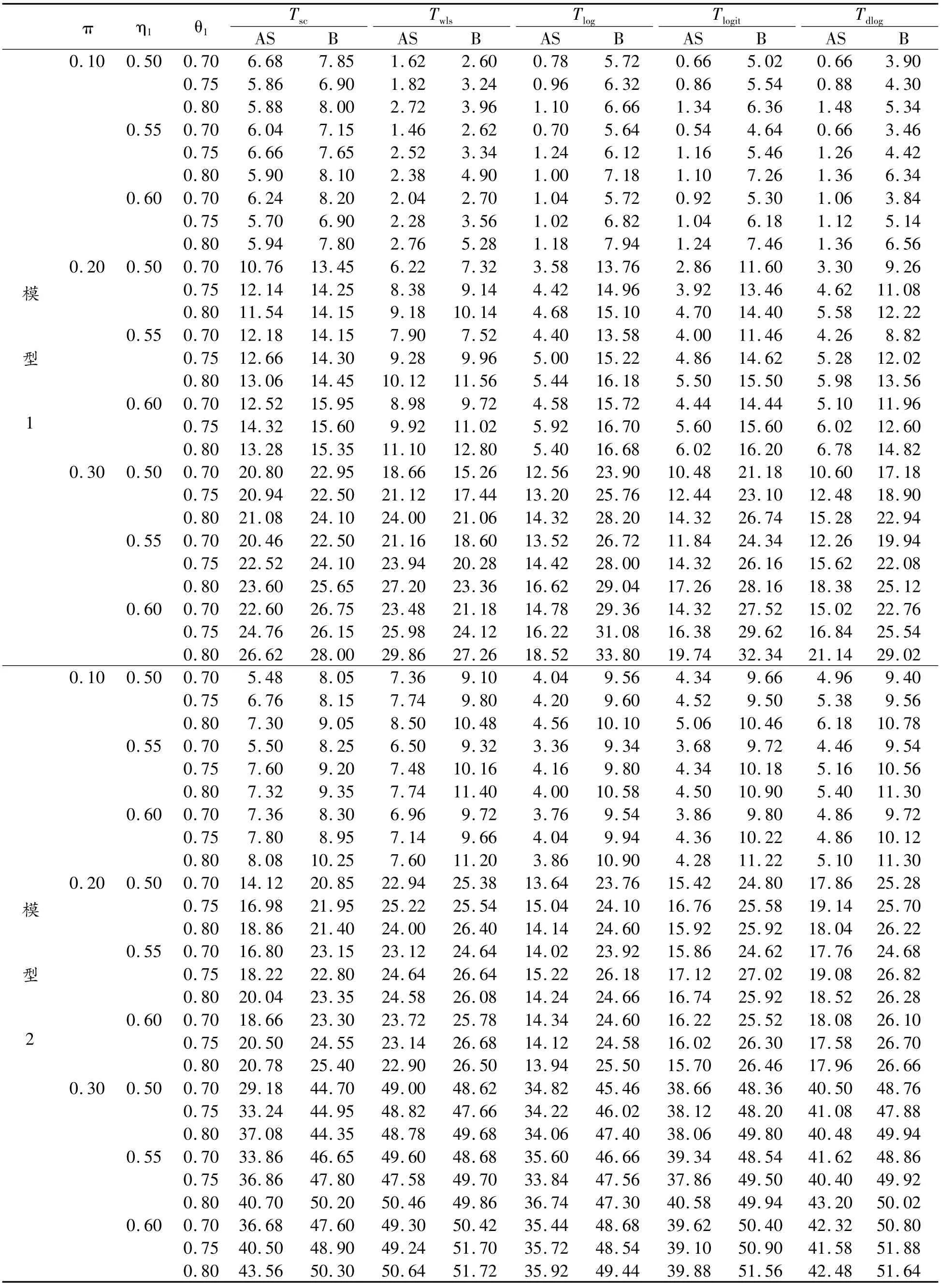
表6 平衡小样本量设置下(Nj=20,Nj=30,j=1,2,…,3)各检验统计量在置信水平α=0.05下的检验功效(%)
5 实例分析
考虑Nedelman[9]在研究疟疾流行率时按年龄分层的疟疾数据,本研究考虑如表7所示的3个成年组数据,其中“+”表示被诊断为阳性,“-”表示被诊断为阴性。

表7 成人组疟疾数据
基于以上数据,可得到2个模型下参数πj、ηj、θj的非限制性和限制性极大似然估计,如表8所示。
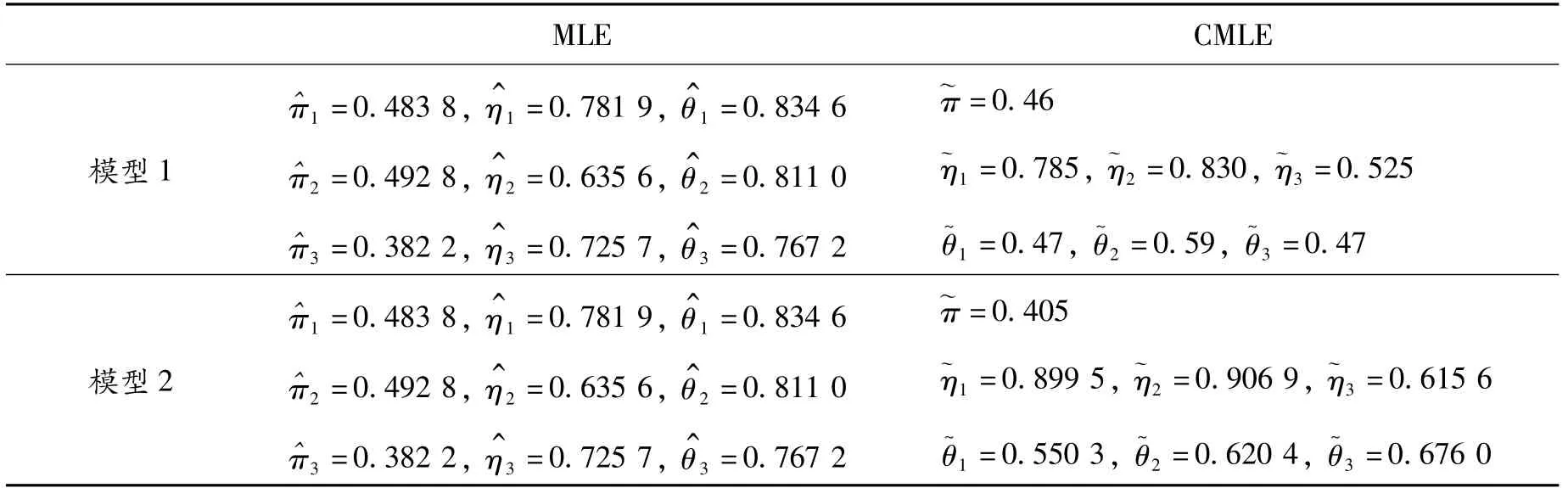
表8 成人组疟疾数据的非限制性极大似然估计(MLE)与限制性极大似然估计(CMLE)
对于假设检验:H0∶π1=π2=π3↔H1∶π1,π2,π3不全相等,各种检验的渐近p值和Bootstrap检验p值如表9所示。

表9 成人组疟疾数据的检验p值
由表9可知,2种模型下各种检验的渐近和Bootstrap检验p值都大于0.05,因而在显著性水平0.05下都没有足够的理由拒绝原假设。
6 结论
本研究考虑了分层设计下的无金标准部分核实数据对疾病流行率的齐性检验H0∶π1=π2=… =πJ↔H1∶πi,πj不全相等(i≠j),提出了小样本下基于检验统计量Tsc,Twls,Tlog,Tlogit,Tdlog的Bootstrap检验过程。模拟研究结果表明,在小样本下基于Bootstrap的检验过程犯第1类错误的概率更接近显著性水平,且具有更高的功效。因而,在小样本下推荐使用Bootstrap的检验过程。
附录
第j层Fisher信息阵的逆矩阵的第一主对角元素为
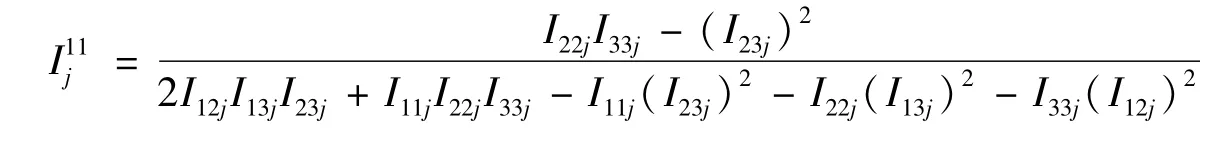
其中,
在模型1下:

在模型2下:
猜你喜欢
内蒙古统计(2021年4期)2021-12-06
中学生数理化·中考版(2021年9期)2021-11-20
考试与评价·高二版(2020年4期)2020-09-10
测控技术(2018年4期)2018-11-25
临床医药文献杂志(电子版)(2017年11期)2017-05-17
临床骨科杂志(2017年1期)2017-03-07
环球时报(2014-01-09)2014-01-09
中国卫生统计(2012年1期)2012-12-04
统计与决策(2012年14期)2012-07-25
中学英语之友·下(综合版)(2008年10期)2008-02-16
