
一种基于图卷积网络的文本多标签学习方法
2021-03-21 05:11刘晓玲刘柏嵩王洋洋
小型微型计算机系统 2021年3期
刘晓玲,刘柏嵩,王洋洋
(宁波大学 信息科学与工程学院,浙江 宁波 315211)
1 引 言
多标签学习[1]是处理现实世界中具有多语义对象的主要学习框架之一.一篇文本可能同时属于政治、经济、文化等多个主题,针对这类数据需要预测实例可能具有的多个标签.标签关联关系会为多标签学习提供有用的信息,例如当标签“政治”存在时,出现“娱乐”的概率相对较小,如何充分挖掘和利用标签之间的关系是目前研究者普遍认可和关注的一个关键问题[2].
根据多标签学习算法中考虑的标签关联关系,将现有方法分为3类[3]:一阶策略、二阶策略和高阶策略.一阶策略是将每个标签看成独立不相关,不考虑标签之间的相关性;二阶策略利用了标签成对的关联信息,但在实际应用中标签之间的相关性可能会超过二阶;高阶策略考虑每个标签对其他标签的影响.BR算法[4]假设标签相互独立,将多标签学习任务转换为单标签分类问题.分类器链CC[5]将样本特征与第1个分类器预测出来的标签联合作为新的特征,并将新特征通过第2个分类器,以此类推来模拟标签之间的高阶关系.基于信息熵[6]提出的CC算法[7]利用条件熵使标签间相关性最大化.LIFT[8]基于标签类属性为每个标签生成专属的特征进行多标签学习.近年来,一些基于神经网络的模型应用于多标签学习任务并取得重要进展.CNN-RNN[9]采用提取全局与局部语义信息的方式进行多标签学习,考虑标签之间的二阶关系.SGM[10]将多标签学习任务当成序列生成问题.MLILDSA[11]采用深度监督自动编码器来计算后验条件概率以建模标签关系.大部分多标签算法假设训练数据的标签是完整的,但实际中不完备数据普遍存在,NNADOmega[12]为提升模型效果在神经网络损失函数中刻画标签依赖关系.大多数方法将实例文本作为独立学习分类器参数的载体,未充分挖掘高阶标签之间的关系.

图1 TMLLGCN框架Fig.1 Framework of TMLLGCN
图卷积网络是一种对图数据进行操作的神经网络,众多学者对图卷积网络进行了研究和应用.Wang等人[13]将图卷积网络应用于推荐社交网络建模;Si等人[14]提出了基于图卷积网络的人体动作识别方法;Yu等人[15]将图卷积网络应用于交通流量预测问题.基于图卷积学习理论,本文提出利用标签图结构来捕获和探索标签的高阶关系.具体来说,GCN在标签图之间传播信息,从而学习具有每个文本标签的高阶关系分类器.这些分类器从标签图中汇聚信息,并将这些信息进一步应用于文本特征表示,从而实现最终的标签预测,这是一种明确建模标签高阶关系的方法.本文的主要贡献有:
1)提出一种新的基于GCN进行文本多标签学习的端到端学习模型,充分挖掘利用标签高阶关系.
2)考虑到未标记标签集对已知标签集的影响,充分挖掘有价值信息进行标签补全,提高模型的适应性.
3)在真实多标签数据集上验证了TMLLGCN的有效性.
2 相关定义

D={(ds,Ys)|1≤s≤Mum,Ys={1,-1}C,Ys⊆L}
对于测试样本Ti,学习模型需输出与其相关的标签集合Yi=[y1,y2,yi,…yC],yi取值“1”或“-1”.
定义2.集合M={a1,a2…am},集合N={b1,b2…bn},ai的概率为p(ai),则M集合的信息熵:
(1)
则在M条件下N的条件熵:
(2)
I(bj|ai)=-p(aibj)log2p((bj|ai))
(3)
定义3.图G=(V,E),V和E分别表示节点和边.矩阵X∈Rn×d,其包含n个带有特征的节点,d表示节点特征维数,节点v的特征向量为:xv∈Rd,对应的边关系矩阵A∈Rn×n.GCN通过一层卷积捕获邻居信息,当GCN堆叠可以获得较大邻域信息[16].对一层GCN,k维节点矩阵H(1)∈Rn×k的形式化表示即:
(4)
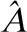
(5)
l表示层数,并且H(0)=X.
3 基于图卷积网络的文本多标签学习
本文提出一种TMLLGCN模型,其架构如图1所示.首先,进行文本特征表示,其中w1,w2,…,wn表示文本输入的词向量表示,经过不同的卷积窗口尺寸得到3种不同的特征表示,进而融合形成Dd维文本特征.其次,进行标签补全建模,最后进行GCN建模高阶关系的分类器学习,其中d表示初始标签向量的维度,经过图卷积操作形成Dd维的标签表示,C表示标签数量,将文本特征和生成分类器以点积的方式结合,并对预测分数进行归一化产生C个标签概率,然后据损失函数迭代训练.
3.1 文本特征表示
深度学习方法在特征提取方面效果优异,遵循AGCNN[17]提取文本特征,特征为x:
x=fAGCNN(T,θAGCNN)∈RD
(6)
其中θAGCNN表示模型参数,Dd表示维度.
3.2 非对称标签补全建模
现实文本数据的标签并非总是完整的,探究标签高阶依赖关系有助于在标签缺失时提高模型的效果[18].此外大多数多标签学习方法采用预定义的关系矩阵,但预定义的关系并非总可得.此外,据简单共现概率建立相关矩阵的方法通常具有对称假设.GCN基于相关矩阵在节点之间传播信息,相关矩阵的设计至关重要,本文考虑到未标注标签集对已知标签集的影响,设计非对称性参数充分挖掘标签信息.基于上述原因,通过数据驱动方式获得基础置信度矩阵,由相关定义1和公式(3)得到:

pij=-μaij+(1-μ)bij
(7)
其中μ是非对称参数,通过增加基础关系矩阵bij的权重和减少aij的权重进行学习.将实例训练数据的标签矩阵Y更新为:
(8)
非对称标签补全建模的具体流程如下:
算法1.非对称实例标签补全
输入:标签矩阵Y,非对称参数μ

1.Y={Yi|i=1,…,C},Y∈RMum×C
2.For eachyi,yj,利用公式(3)计算:
ifi=j
aij=bij=1
3.由式(7)得到非对称化矩阵:
pij=-μaij+(1-μ)bij
3.3 基于GCN建模高阶关系的分类器学习

(9)


gθ×Gx=gθ(L)x=gθ(UΛUT)x=Ugθ(Λ)UTx
采用切比雪夫多项式简化为:
(10)

θ0x+θ1(-D-1/2AD-1/2)x
(11)
进一步扩展到高维特征向量x∈RC×d,有式(12):
其中Θ∈Rd×F是卷积核参数,对输入数据x执行一次图卷积,得到gθ×Gx∈RC×F,标签节点被0~K-1阶邻居标签信息更新.
3.4 基于图卷积网络的文本多标签学习
基于图卷积网络的多标签学习流程如下:
算法2.基于图卷积网络的多标签学习

非对称性参数μ,
ρ=LeakyRelu,σ=softmax

输出:预测标签Yout
1.重构训练集:
通过AGCNN对ds提取文本特征xD
2.GCN建模高阶关系的分类器学习:
根据式(7)得到第一层输入关系矩阵pij;
A←pij,H0←x∈RC×d
3.标签图卷积:由式(10)-式(12)得:
forl←0toLdo:
yc=WxD
由公式(9)得目标函数:minLt
更新权重W←W+ΔW
直到满足迭代停止条件
4.预测新数据:
对Ti提取文本特征TD
TD应用到标签空间对象分类器:Yout=σ(WTD)
5.returnYout
4 实 验
4.1 实验数据集
为检验TMLLGCN模型的性能,在真实数据集上进行了对比实验,数据划分详情见表1.
Zhihu(1)http://tcci.ccf.org.cn/conference/2018/taskdata.php:短文本数据集,其包含知乎问题标题、相关描述和话题标签,选取标签数量为260.

表1 多标签数据集描述Table 1 Multi-label data description
AAPD(2)https://drive.google.com/file/d/18JOCIj9v5bZCrn9CIsk23W4wyhroCp_/view.:该数据集为计算机科学领域的学术论文,包含摘要和对应的标签,标签总量为54.
4.2 实验方法
为防止数据周期性影响,首先对实验样本随机shuffle之后按8:2的比例划分训练集和测试集,其次,对于词向量矩阵中未出现的词,采用-0.25~0.25值初始化,对问题(题目)和描述(摘要)分别取其2倍的平均长度,进行补齐或截断至一致长度.通过实验选定合适的非对称性参数μ.本文使用基于实例和基于标签的两类评估指标[20]:Precision(P)、Recall(R)、F1-Measure(F1)、One-error(OE)、Coverage(CV)、Ranking Loss(RL)以及Macro-F1、Micro-F1.他们可以从各个方面评估多标签学习方法的性能.其中OE、CV和RL的值越低,则表示模型效果越好.同时TMLLGCN与基于BR[21]、CC[22]、LP[23]的方法以及CNN-RNN[9]、SGM[10]多标签学习算法进行对比.
4.3 实验结果与分析
4.3.1 TMLLGCN和各基准方法的整体性能比较
各方法在数据集上的比较结果如表2-表5所示.

表2 不同方法在指标P、R、F1上的比较Table 2 Comparison of different methods on P,R,F1

表3 不同方法在One-error上的比较Table 3 Comparison of different methods on OE
从表2实验结果可以看出TMLLGCN模型在P、R和F1的评估上比其他方法表现更好.基于BR的算法在精确度指标上比其他算法低,主要原因是其对标签关系进行独立性假设,标签关联信息较弱.传统基于CC和LP的方法由于建模标签关系性能有限,预测结果并不理想.深度学习方法CNN-RNN和SGM在精确度指标上较BR、CC和LP有明显提升,基于图卷积的TMLLGCN在充分挖掘标签高阶关系的同时考虑了未标记量对标签集的影响,所以预测标签结果要优于上述模型.从表3的6种算法在One-error指标上的结果可以看出,本文方法TMLLGCN在数据集Zhihu上比深度学习方法CNN-RNN、SGM分别降低了7.1%、3.7%,在数据集AAPD上分别降低9.7%、6.2%.从表4实验结果可以看出,CNN-RNN、SGM和TMLLGCN在覆盖率和排序损失上表现明显优于BR、CC和LP方法,其中在指标Ranking Loss上,TMLLGCN比其他方法的值更低,在数据集AAPD上的排序损失降低到0.141.由表5实验分析可得TMLLGCN在基于标签的评价指标上获得优异表现,其Macro-F1、Micro-F1指标值比深度学习方法CNN-RNN均有提升,且显著优于传统方法,这也进一步说明了本文方法在挖掘标签高阶关系方面取得效果.综合以上各方面实验评估结果,验证了TMLLGCN多标签学习方法的有效性和优异性.

表4 不同方法在Coverage和Ranking Loss上的比较Table 4 Comparison of different methods on CV,RL

表5 不同方法在Macro-F1、Micro-F1上的比较Table 5 Comparison of different methods on Macro-F1 and Micro-F1
4.3.2 非对称性参数μ的影响
为了观察式(7)中不同μ值的影响,将μ设在[0,1]之间,平均准确度在不同数据集上的实验效果如图2所示.

图2 在Zhihu(a)和AAPD(b)数据集上值的影响Fig.2 Effect of μ on Zhihu(a)and AAPD(b)
由图2可得,μ取值范围在区间[0.1,0.3]上效果较好,非平衡参数μ=0.2时,模型效果最好,这表明合理增加未知相关标签的学习权重有利于标签信息在节点上的传播.
4.3.3 不同词向量表示对TMLLGCN的影响
为探究不同词向量表示对本文提出模型的影响,对标签进行GloVe[24],GoogleNews[25],FastText[26]和one-hot词向量表示.在数据集Zhihu和AAPD上的实验效果如图3所示.
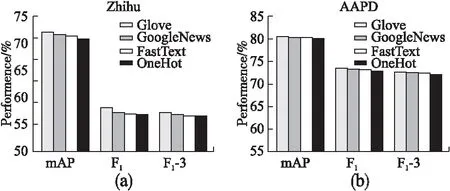
图3 在Zhihu(a)和AAPD(b)上词向量对TMLLGCN的影响Fig.3 Effect of word vector on TMLLGCN on Zhihu(a)and AAPD(b)
由图3可发现,不同词向量作为TMLLGCN的输入时,多标签学习准确度不会受到显著影响.one-hot结果也表明模型准确度的提升并非绝对地来自词向量的语义,但使用强大的词向量可带来更好的结果.大量文本语料库中学习的词向量保持了一些语义拓扑,即语义相关的概念在词向量空间中是接近的,同时TMLLGCN可以使用这些依赖关系更好的进行文本多标签学习.此外,GCN层数并非越多越好,由图3中F1-3指标可知,当图卷积层数增加到3时,数据集上的F1指标降低,可能的原因是:在增加GCN层数时,节点传播积聚导致过度平滑.
5 结束语
捕获标签依赖性是文本多标签学习的一个关键问题.为了对这些重要信息进行建模和探索,本文提出通过GCN的映射函数从数据驱动的标签表示中学习对象分类器挖掘标签高阶关系.为更好地建模高阶关系以及提高标签缺失时的预测效果,在得到的基础标签关联矩阵上考虑了未标记标签集对已有标签集的影响进行标签补全,定量和定性的实验结果均证实了TMLLGCN模型的优势.在进一步研究工作中,我们将致力于通过注意力机制和更好的初始关系策略来优化网络结构,以提升模型的多标签学习能力.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2022年1期)2022-04-15
计算机系统应用(2021年2期)2021-02-23
上海师范大学学报·自然科学版(2019年5期)2019-12-13
福建基础教育研究(2019年7期)2019-05-28
数学学习与研究(2018年15期)2018-11-12
