
无人工标注数据的Landsat影像云检测深度学习方法
2021-03-19 00:27仇一帆柴登峰
自然资源遥感 2021年1期
仇一帆,柴登峰
(浙江大学地球科学学院,杭州 310027)
0 引言
Landsat系列卫星自1972年发射至今一直持续对地观测,提供了全球范围长时序连续陆地遥感记录,是目前应用最广泛的遥感数据集之一。然而,Landsat系列卫星与其他光学传感器一样,容易受到云层及其阴影影响,研究表明,地球表面的年均云层覆盖率在中纬度地区大约为35%,全球范围内约为58%~66%[1-3]。遥感影像上,被云层遮挡的像素变亮,被云阴影遮挡的像素变暗,地表特征模糊[4-6],干扰地物信息的提取,影响研究结果的准确性。因此,云和云阴影检测是Landsat影像产品生产的重要环节。
目前美国地质调查局(United States Geological Survey, USGS)官方使用CFMask(C function of Mask)算法来检测影像上的云和云阴影,检测结果作为质量评估(quality assessment, QA)波段保存于Landsat Collection 1 Level 1产品中。CFMask是Fmask(Function of Mask)算法的C语言实现[1,6-7],通过分析Landsat影像所有波段的大气层顶(top of atmosphere, TOA)表观反射率和亮度温度,基于云和云阴影的物理属性建立阈值规则逐像素进行检测。这种基于阈值规则的方法在遥感影像云和云阴影检测领域应用广泛,但受到传感器类型、地理位置、大气条件等因素影响,阈值的选择通常难以把握; 而且为了保证精度,往往会设定大量阈值规则,例如FMask就使用了超过20组阈值,增加了该方法的使用和迁移难度[6,8]。除此之外,常用的Landsat影像云和云阴影检测方法还包括多时相检测法和统计学方法。多时相检测法基于云和云阴影的动态性,通过比较恒定视角多时相影像的光谱差异构建云检测算法[5,9]。虽然研究结果表明多时相检测法能有效提高云检测精度,但在实际应用中诸如热带和亚热带等全年多云的地区很难获取无云观测作为参考,限制了现有多时相检测方法的应用。基于统计学思想利用空间特征和光谱特征来估计影像整体云覆盖率[10]或检测影像上的云层[11-12]也是云和云阴影检测的一种常见思路。
计算机性能的提升和深度学习的发展为云和云阴影检测带来了新思路[13-14],如Chai等[15]利用SegNet模型将像素划分为云、薄云、云阴影或无云4个类别,实现了Landsat影像上的云和云阴影检测。深度学习方法通常依赖大规模标注数据来训练网络模型,而这些数据往往是通过人工标注的方式来获取的,成本高、耗时长、具有主观性,不利于训练出具有实用价值的模型。为了解决这个问题,有学者提出了弱监督学习概念,使用不充足或不准确的监督信息来训练模型,减少了人工标注数据的使用,目前这个方法在计算机视觉领域已经有了一定的突破[16-17],但具体到云和云阴影检测研究上还没有进展。
针对上述遥感影像云和云阴影检测方法存在的问题,本文受弱监督学习思想启发,利用CFMask产生的云和云阴影检测结果作为弱监督学习样本训练SegNet深度神经网络,整个训练过程不使用人工标注的先验数据。模型训练完成后,对新图像进行检测并验证检测精度,定量化描述研究结果。旨在探讨脱离人工标注数据训练深度神经网络模型进行Landsat影像云和云阴影检测的可行性,为后续实现更加完善的云和云阴影检测奠定基础。
1 研究数据
1.1 数据描述
实验数据来自Landsat Collection 1 Level 1产品和Landsat8云覆盖评估(cloud cover assessment, CCA)验证数据集[18]。
Level 1产品包含10个30 m空间分辨率波段,1个60 m空间分辨率的全色波段,以及QA波段。QA波段中包含的云和云阴影信息依据CFMask算法生成,根据表1列出的QA波段bit位描述或文献[19]提供的59类QA波段值解释规则可以解译出影像上的云和云阴影信息。
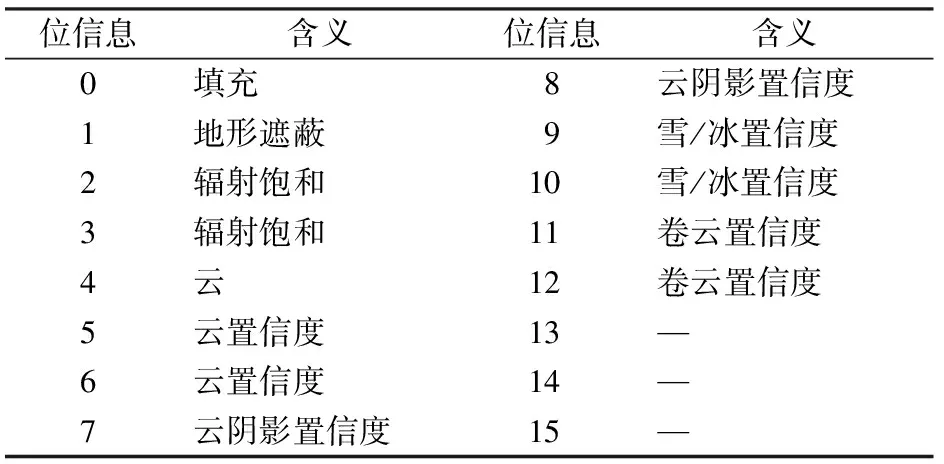
表1 Landsat8 Collection 1 Level 1 QA波段bit位描述Tab.1 Landsat8 Collection 1 Level 1quality band bit designations
如表1所示,QA值二进制形式第4位是云像素标识,第7位和第8位存储云阴影置信度信息。对于单个bit位存储信息的情况,以第4位为例,若值为0表示该像素并非云像素,若值为1则为云像素; 对于用双bit位表示的信息,以第7位和第8位为例,若从高位到低位分别为: “00”表示不存在云阴影; “01”表示云阴影存在的置信度很低(0~33%); “10”表示中等置信度(34%~66%); “11”表示置信度很高(67%~100%)[19]。QA波段能提供较高精度的云和云阴影掩模,但仍存在一定的误差,其数据标签并不是完全准确的。本实验将30 m空间分辨率波段组合成的10通道多波段影像对应TOA表观反射率和亮度温度作为输入数据,将QA波段派生为标注数据来训练SegNet模型。
Landsat8 CCA验证数据由USGS地球资源观测与科学中心创建,通过人工方式标注出了影像上的云、薄云、云阴影和无云像素。验证数据共96个场景,均匀分布于全球各大洲,覆盖荒地、森林、灌木地、草地/农田、雪/冰、城市、湿地以及水域8个不同的生物群落区[1,18]。需要注意的是,Landsat8 CCA验证数据只用于评估检测结果精度,不参与模型的训练过程。
1.2 数据预处理与样本集构建
由于Landsat影像图幅较大,直接输入深度神经网络占用内存高,图形处理器(graphics processing unit,GPU)很难负担,因此将各场景切割为互不重叠的512像素×512像素大小子景并存储为png格式。影像上有一些不反映地物信息的填充像素,为了简化信息提取过程,在构建样本集时剔除了这些包含填充像素的切割图像。最后,每个场景约有120个512像素×512像素大小子景用于样本集的构建,每个子景对应10个多光谱波段和1个QA波段。
本文共构建了3个样本集,分别是: 用于训练SegNet网络的训练样本集,用于优化网络参数的验证样本集,以及用于客观评价网络性能的测试样本集。本研究以Landsat8 CCA 验证数据集的96个场景为研究对象,这些场景均匀分布于全球范围,包含所有生物群落区类型,具有代表性。96个场景中,有64个场景未标注出云阴影,不能用于精度验证,将这64个场景每个场景切割后的子景按80%和20%的比例随机分配为训练样本和验证样本; 其余32个场景标注完整,用于构建测试样本集。训练、验证、测试样本集中子景数量和切割图像数量如表2所示。
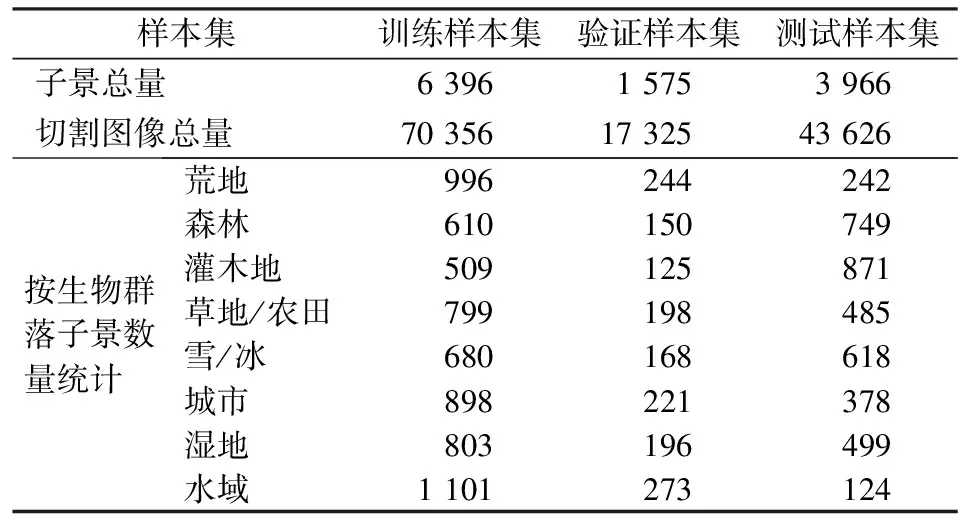
表2 样本集子景数量和切割图像数量Tab.2 The number of subscenes and images in sample set
2 云和云阴影检测算法
本文方法实验流程如图1所示。
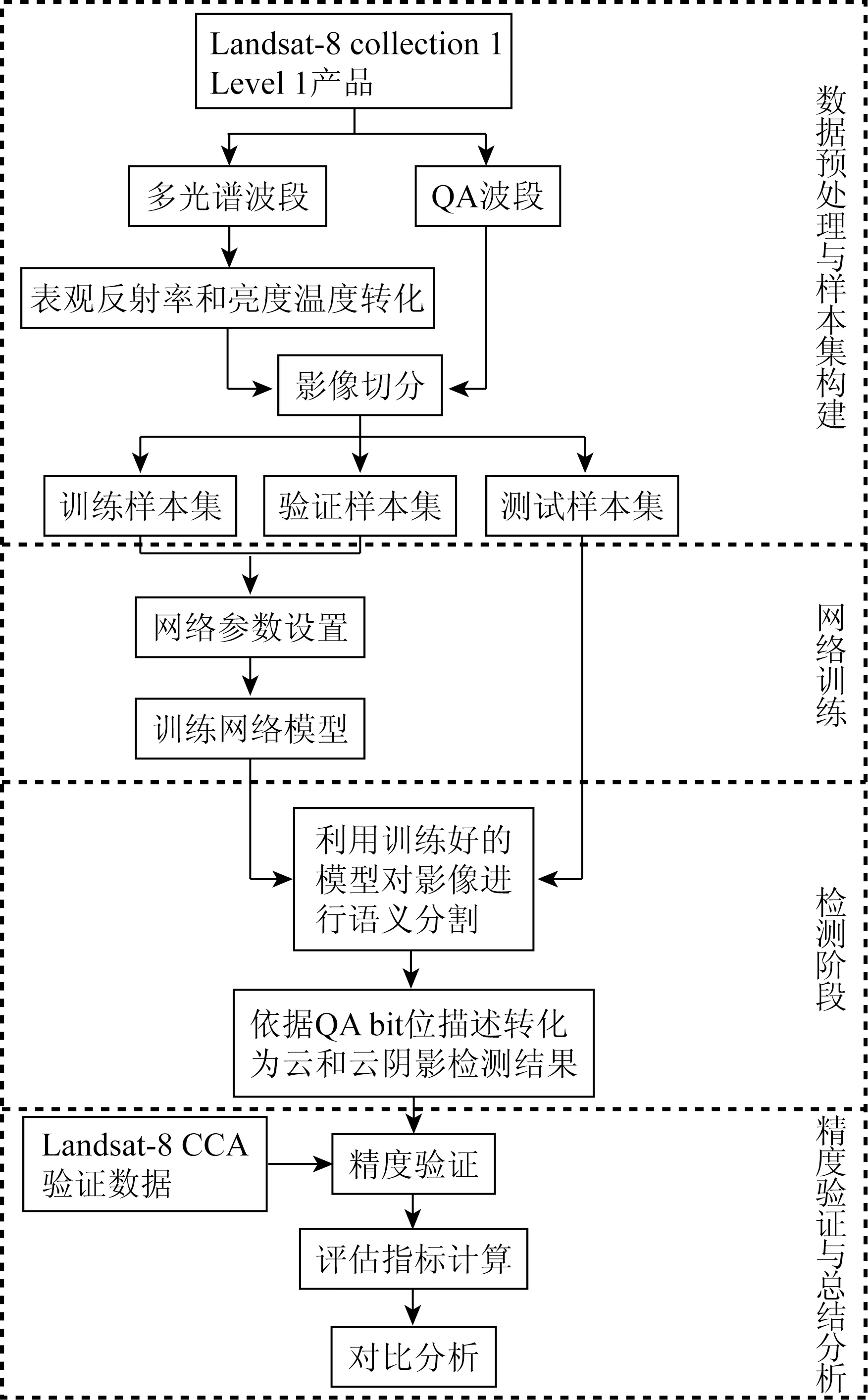
图1 实验方案技术流程Fig.1 Technical flowchart of experimental scheme
本方法将云和云阴影检测视为语义分割问题,利用整幅影像的空间信息和所有波段的光谱特征对图像进行分割,最后依据表1的QA波段位描述将语义分割结果标记为云、无云或云阴影,完成遥感影像云和云阴影检测。
2.1 SegNet模型
本文参考文献[20]构建了SegNet语义分割模型,其网络结构如图2所示,从输入图像开始,从左向右依次经过编码器(Encoder)、解码器(Decoder)和Softmax分类器,最后到达输出层,完成端到端的像素级分割任务。SegNet可以接受任意尺寸的输入图像,其原型结构的输入为3通道图像,本文为了能更好地学习和利用Landsat影像特征,设置模型的输入图像通道数为10,本文中输入图像尺寸为512像元×512像元。编码器基于VGG网络,包括卷积层、批归一化层、ReLu激活层和池化层,卷积层均采用3像元×3像元大小卷积核,第一层卷积层中卷积核个数设置为96,池化层采用最大池化操作,并记录池化索引,图像经过编码器各隐含层,实现对影像特征信息的低维提取; 解码器包含上采样层以及与卷积层一一对应的反卷积层,利用编码阶段保存的最大池化索引还原图像尺寸和边界信息,重构高维特征。编码器-解码器结构大大减少了模型的训练参数,提高了网络效率,并对边界的描述起到优化作用。解码器输出的高维特征向量输入Softmax分器,用于预测图像上各像素所属类别的概率并生成一个k通道的类置信图(k为类别个数),尺寸与输入图像相同。最后,具有最大概率的类别输出为语义分割结果。
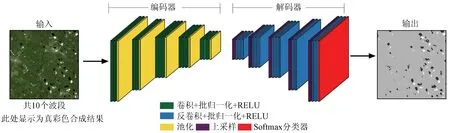
图2 基于SegNet的网络结构Fig.2 Network structure based on SegNet
2.2 参数设置与网络训练
SegNet语义分割模型的训练以交叉熵损失函数最小化为目标,使模型对训练样本的预测结果尽可能地与所给标注数据标签相匹配。模型采用反向传播(back propagation, BP)算法,计算网络中所有权重损失函数的梯度,反馈给优化器(Optimizer)以更新网络参数,实现交叉熵最小化。本文选择自适应矩估计(adaptive moment estimation, Adam)算法作为优化器,Adam是一种自适应学习速率的求解方法,实验证明它能较好地解决损失函数的最优化问题,与其他优化器算法相比综合性能表现更佳[21-22],Adam的一阶矩估计衰减速率设定为0.9,二阶矩估计衰减速率为0.999; 学习速率初始值设定为1E-4,在每一轮参数更新过程中更新学习速率。为了防止出现过拟合,模型在对每个卷积层进行RELU函数激活后,添加了一个dropout层,以一定的概率激活网络上的神经元,本文将激活概率设置为0.5。
2.3 精度评价
为了定量评价Landsat8影像云和云阴影检测的精度,本文采用总体精度(overall accuracy, OA)和F1分数作为评价指标。总体精度表示为检测结果中分类正确的像素数量占测试样本集全部像素数量的比值,F1分数是对精确率和召回率的调和平均。2个评价指标的计算公式分别为:
(1)
(2)
式中:i,j为类别标识;F1i为类别i的F1分数;Nij为本属于类别j的像元预测为类别i的数量;pi和ri分别为类别i的精确率和召回率,计算公式如下:
ri=Nii/∑iNji,
(3)
pi=Nii/∑jNij。
(4)
3 实验结果分析
为了评估本文方法的有效性和可行性,对测试样本集进行云和云阴影检测,并与CFMask算法结果进行对比分析。CFMask是Landsat官方云检测方法,可以对全球范围Landsat影像进行无偏检测,综合性能较好,具有权威性[1]。
3.1 定性分析
从实验结果中选取了5个典型场景进行视觉评价,如表3所示,影像1—5所示场景分别位于不同的生物群落区中,其下垫面分别为荒地、冰雪、植被(灌木)、水域和湿地; 从左至右依次是输入图像、地面真值、本文方法检测结果以及CFMask检测结果。输入图像以B4(R),B3(G),B2(B)合成显示,真值为Landsat8 CCA验证数据中经人工方式标注的云和云阴影掩模,检测结果及真值中的云阴影、云和无云像元分别用红色、绿色和蓝色标示。由于Landsat8 CCA验证数据提供的云和云阴影掩模在标注时区分了云类别与薄云类别,而本文方法和CFMask算法在进行云和云阴影检测时均不区分云的厚薄,因此合并Landsat8 CCA验证数据中的云和薄云2个类别,统一作为云类别来进行标示,在后续对实验结果进行定量分析时,也作相同合并处理以验证计算结果的精度。对于Landsat数据的实际应用而言,通常认为云像元和薄云像元都是无效的,因此将云与薄云类别合并并不会影响对本方法有效性的判断。由表3可知,总体而言,本文方法在不同生态环境、云属种类或云层分布条件下均能较好地判定出云和云阴影位置,识别出云和云阴影的大致边界。相比CFMask结果,本文方法检测出的云和云阴影更准确,与真值的匹配度明显更优,如本文方法识别出了CFMask没有识别出的表3中1号影像右侧较薄的云层,对3号影像的卷云也有更好的识别效果,4号影像中CFMask方法结果过多估计了影像上的云层和云阴影,而本文方法改善了这一问题。

表3 云和云阴影检测结果Tab.3 Cloud and cloud shadow detection results
3.2 定量分析
为进一步验证所提方法的有效性可行性,本文利用Landsat8 CCA验证数据对检测结果进行精度验证,采用总体精度和F1分数2个指标进行定量评价,结果如表4所示。实验结果的总体精度为85.55%,云、云阴影和无云类别的F1分数分别为78.14%,43.86%和90.62%,均高于CFMask结果。值得一提的是,与云检测相比,精确的云阴影检测难度更高,往往会出现大量漏检和误检情况,而本文方法云阴影检测结果的F1分数较CFMask有所提高,且精确率从35.5%提高到44.5%,标示着本方法一定程度上能够改善云阴影检测的精确程度,优化云阴影检测结果。
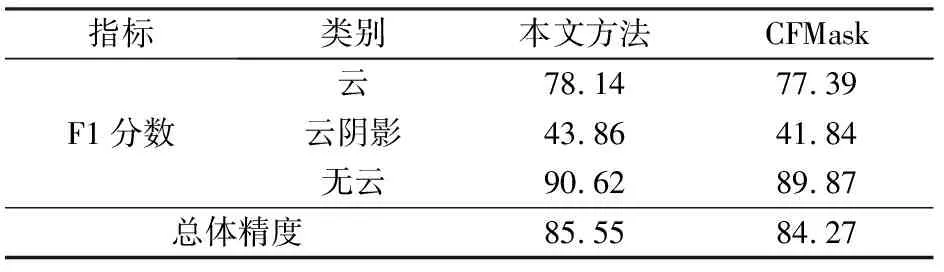
表4 测试样本集检测结果评价Tab.4 Evaluation of detection results (%)
对8个生物群落区进行单独统计,大部分群落区的检测精度优于相同场景下的CFMask结果,其中,荒地、草地/农田、城市、灌木地和水域5个生物群落区的检测精度均超过90%,城市场景的云和云阴影检测精度为91.49%,较CFMask结果提高了超过10.6%,检测性能提升显著。但是,本文所提方法对雪/冰区域的检测结果精度较差,这一点在表3的2号影像中也有所体现,经过分析,认为可能是由于训练样本标注数据在这个区域的准确率过低(低于60%),导致错误标签信息对训练过程造成的干扰难以忽视,模型无法正确地提取特征,因而出现分割结果误差较大的问题,在后续研究中拟加入其他辅助条件做进一步筛选以提高检测的精确程度。
4 结论
1)本文利用CFMask云检测结果替代人工标注数据训练SegNet语义分割模型,检测Landsat影像上的云和云阴影。结果表明,本文方法能够实现Landsat影像上的云和云阴影检测,总体精度达到85.55%,与CFMask结果相比有一定改善,证明了采用非人工标注数据训练深度网络模型进行云和云阴影检测的思路是可行的。
2)本文方法改进了利用深度学习进行云和云阴影检测时依赖大规模像素级云和云阴影人工标注数据的问题,降低了训练数据的获取成本,为后续研究奠定基础。
3)本方法在检测精度上仍有进一步提升的空间,下一步的研究工作拟通过结合其他筛选条件,对标注数据中的显著错误,如冰雪与云的混淆错误,进行初步纠正后再用于网络模型训练来进一步提高Landsat影像云和云阴影检测精度。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
文苑(2020年11期)2020-11-19
中国诗歌(2019年6期)2019-11-15
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2018年11期)2018-08-04
中国与非洲(法文版)(2017年10期)2017-11-23
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
数学大王·中高年级(2016年4期)2016-05-14
测绘科学与工程(2016年5期)2016-04-17
CHIP新电脑(2016年3期)2016-03-10
