
时间上下文优化的协同过滤图书推荐*
2021-03-19 10:59:44梁思怡彭星亮林伟明胡振宁
图书馆论坛 2021年3期
梁思怡,彭星亮,秦 斌,林伟明,胡振宁
0 导言
个性化图书推荐是高校图书馆开展精准服务、提升图书使用效益的重要举措。近十年来,越来越多的高校在重视经典推荐、新书推荐和热书推荐的同时,也开始重视挖掘图书馆自动化系统里蕴藏的读者借阅行为数据,通过分析历史借阅数据判断读者潜在的兴趣和爱好,预测其未来可能借阅的图书,有针对性地向读者提供图书列表,帮助读者快速获取有价值的图书目录。从文献看,高校图书馆个性化图书推荐服务主要面向学生群体,多数研究基于协同过滤技术(Collaborative Filtering,CF),并针对评分数据稀疏、阅读兴趣变化等问题改进协同过滤经典算法。这些研究虽然各有成效,但总体来说,高校图书馆关于个性化图书推荐技术的研究和应用还不深入,还有较大的提升空间。
本文以现有研究和实践为基础,分析协同过滤推荐技术在高校图书馆图书推荐方面所面临的场景和困难,提出一套基于时间上下文优化协同过滤的算法ICBO UserCF(Interest Caputure-Based Optimization UserCF),并利用深圳大学图书馆的实际借阅数据进行验证和比较。ICBO UserCF考虑了图书推荐的三个要素,即读者阅读行为评分、时间上下文和内容兴趣变迁,分别构建了阅读兴趣评分模型(Interest Rating Model,IRM)、时间衰减模型(Time Decay Model,TDM)和内容兴趣捕捉模型(Interest Capture Model,ICM),其中IRM模型用于提炼用户评分数据,TDM和ICM模型用于缓解数据稀疏问题和捕捉用户内容兴趣,更好地反映用户兴趣变化,提高推荐准确度。
1 研究综述
1.1 协同过滤算法简述
协同过滤算法作为应用最广泛的推荐算法之一,能在用户没有明确表明需求的情况下,根据用户行为向用户推荐[1],其中基于用户的协同过滤(User-based CF,UserCF)算法适用于用户数量较少的场合。高校图书馆馆藏图书数量一般在百万册以上,读者数量相对较少,因此可选用UserCF作为个性化推荐的基础模型。UserCF的原理是基于当前用户偏好信息(一般为评分),通过相似度计算来寻找到其相似用户(邻居用户),然后将邻居的偏好物品推荐给当前用户。UserCF的主要过程包括相似度计算、寻找最近邻、评分预测和推荐TOP N。
(1)相似度计算。相似度计算是影响推荐算法性能的关键步骤。相似度计算方法多,其中余弦相似度算法最经典,特别适用于数据稀疏情况,因此本文选用余弦相似度算法来计算用户之间的相似度。对用户u和v,余弦相似度计算方法见式(1)。
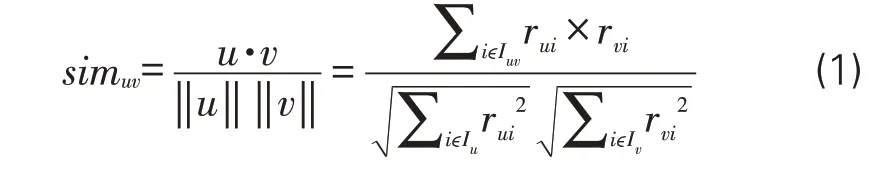
其中,Iu、Iv分别指用户u、v的兴趣集合,Iuv为用户u、v的共同兴趣集,rui、rvi分别为用户u和v对项目i的评分。simuv值域为[0,1],其值越大,证明两者越相似。
(2)寻找最近邻。寻找最近邻常用的方法包括K最近邻方法(K Nearest Neighbors,KNN)和阈值法。本文选用K最近邻方法,取相似度最高的K位用户作为当前用户的最近邻。
(3)评分预测。在确定最近邻后,根据邻居集用户已有的评分对目标用户未评分项(召回集)进行预测评分。常用的计算方法如式(2)所示。
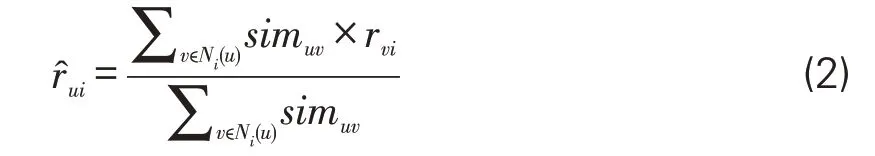
其中,rˆui指的是用户u对未评分项i的预测评分,rvi指的是用户v对项目i的评分,simuv为用户u和v之间的相似度,Ni(u)指用户u的邻居集合。
1.2 高校馆场景下协同过滤图书推荐技术应用
协同过滤技术在电子商务系统运用较为成功,电商可根据海量的订单数据、商品评价数据有针对性地为潜在用户推荐商品。高校图书馆图书个性化推荐服务面临着和电商推荐不同的场景,如学生更青睐数字资源和数字阅读,纸质图书借阅量明显下降;图书流通系统缺少显式反馈,读者借阅兴趣难以把握等。因此,运用协同过滤技术开展个性化图书推荐面临3个难题:(1)评分机制缺乏,难以捕捉读者对借阅过图书的真实兴趣值;(2)借阅行为较少,存在“数据稀疏”和“冷启动”问题,即:一方面,由于大多数用户只对极少量的图书有过借阅行为,使得形成的“用户-图书-评分”借阅矩阵中绝大多数数值为缺失值;另一方面,在新生入学或新书到馆的情况下,存在无借阅行为的新用户或者无被借阅过的新书籍,因而无法得知这些新用户的喜好和新书籍的偏好群体;(3)阅读兴趣变迁,高校学生随着年级提升其借阅兴趣会发生较大变化。
针对以上问题,许多研究从不同角度探索改进UserCF经典算法并应用于图书推荐领域。比如,在缺乏显式反馈的情况下,林晓霞等[2]通过借阅时长、借阅方式两者之和构建“用户-图书”评分矩阵。面对数据稀疏问题,宋楚平[3]利用读者借阅方式、借阅时间对用户评价矩阵进行优化,根据读者特征及图书特征进行读者相似度计算,在一定程度上丰富了矩阵数据。李澎林等[4]建立读者兴趣度模型来模拟读者图书偏好程度,并使用类型因子作为图书相似性权重来填补兴趣度矩阵中缺失的兴趣度值。为解决兴趣变迁问题,李杰等[5]考虑时间动态性和商品热度系数,采用新的用户兴趣相似度计算方法,并利用亚马逊图书评分真实数据进行测试和验证。孙彦超等[6]引入用户兴趣随时间的变化函数来修正用户评价矩阵,提高了推荐准确度。李丹等[7]在设计基于特征的读者行为个性化推荐策略时,引入时间衰减因子,进行不同相似度算法下查准率、召回率的对比。这些研究从不同方面推进了图书推荐技术的应用,具有参考价值。
1.3 基于现状研究的改进方案
本文根据高校图书馆流通服务场景,在分析图书个性化推荐三要素和研究现有成果的基础上,提出一套新的基于时间上下文优化的协同过滤算法ICBO UserCF,从4 个方面改进经典UserCF技术的应用,提升图书推荐精准度。
(1)改善评分办法。多篇文献以借阅时长作为主要因素衡量读者对该书兴趣度,这并不是非常合理的评分办法,比如匆匆还书,可能因为根本不感兴趣,也可能因为被图书吸引而一口气读完;超期借阅,可能因为忘记了还书时间,也可能是抽不出时间去图书馆还书,甚至是“恶意”超期[8]。为证实以上看法,笔者对部分读者和馆员进行了访谈,多数人认为借阅时长可不作为阅读兴趣的指标,而读者借阅行为更具客观性,可对不同借阅操作进行细分,赋予不同权重值,构建阅读兴趣IRM模型。这种基于借阅行为的评分办法可减少借阅时长带来的信息噪音,所产生的评分数据更具真实度。
(2)优化评分矩阵。为构建更为合理的评分矩阵,可采用三种方法进行优化:①IRM模型运用网格搜索(Grid Search)方法,通过穷举搜索以获取最佳行为兴趣参数,贴近用户的真实兴趣值。②采用兴趣值标准化方法,消减评分数值过大或过小所造成的“马太效应”影响,提高推荐精准程度。③TDM模型基于时间上下文对评分矩阵进行优化,将读者近期借阅的书籍兴趣度评分赋予较高的权重值,对读者较久远以前借阅图书的兴趣度评分进行惩罚,反映兴趣变迁情况。
(3)缓解数据稀疏现象。针对数据稀疏问题,根据前人研究并结合实地场景数据分析,采用兴趣捕捉模型(ICM)来描述读者对图书内容类型的偏好,通过中图法相近类目对图书进行聚类,并采用“召回-排序”方式对结果进行优化,丰富了推荐模式,有效缓解数据稀疏问题,并进一步提高推荐效果。
(4)创新时间衰减函数。相比其他引入图书内容兴趣的研究,特别考虑了包含由于用户兴趣变化和物品生命周期等引起时间效应的时间上下文信息,并基于时间上下文的内容兴趣变迁问题,借鉴了前人相关研究,构造了一种新的时间衰减函数。基于该函数建立的TDM 模型和ICM 模型,可以更精准地捕捉读者当前的阅读兴趣,产生更准确的推荐列表。
2 基于时间上下文优化的UserCF算法
结合前文关于高校图书馆场景下协同过滤算法的探讨,本文对图书个性化推荐的解决思路如下:在协同过滤的数据准备阶段,采用基于用户借阅操作的IRM构建评分矩阵,解决了高校图书馆评分缺失问题;在推荐召回阶段,采用TDM对IRM生成的评分矩阵进行优化,即针对时间效应特性对较久远的书籍评分进行弱化,捕捉用户近期偏好;在推荐排序阶段,采用ICM对召回结果进行精排序,增加近期喜好的图书类别特征,应对兴趣变迁影响,并在一定程度上降低了数据稀疏度。三个模型以串联的方式一步步叠加,根本目的是为了更加贴近用户喜好,提高推荐效果。优化后的UserCF算法称之为ICBO UserCF算法,具体流程见图1。

图1 ICBO UserCF流程图
2.1 阅读兴趣评分模型
协同过滤算法基于“用户-项目-评分”来进行推荐,但高校图书馆普遍未组织图书评分活动。为解决评分缺失问题,可通过图书借阅数据的分析,构建基于读者“借阅”“续借”及“预约”行为的兴趣评分模型,包含兴趣值计算规则及标准化函数设计。
(1)阅读兴趣值计算规则设计。读者“借阅”“续借”和“预约”三种借书行为源于用户自身操作需要,代表着读者对某种图书不同程度的阅读兴趣,因此IRM 选用这三种读者行为并赋予相应兴趣值,再进行转化得到“用户-项目-评分”矩阵。多数研究[2-4]对不同的借阅行为赋予固定的兴趣值,忽略了不同行为的兴趣差别。IRM 则对不同读者行为进行细分,并赋予不同的权值,如“首次借阅”是所有借阅行为中频率最高的,可设置为兴趣基准值;“借过再借”表达了对该图书有重读一遍的兴致;“网上续借”表示愿意花更多的时间去阅读;“借预约书”意味着终于等到心仪的图书;“未借预约”说明兴趣已过。在实际处理中,为使评分矩阵分值分布尽可能处于业界常用的[0,5]分布区间,将“首次借阅(ϕ u,1)”的兴趣值valu,1定义为1.5,其它借阅操作的兴趣度值(ϕ u,2-ϕ u,5)与首次借阅的兴趣值(ϕ u,1)关系见表1。通过设置不同借阅行为的权值系数,优化了兴趣值计算方案,提高了评分的客观性。

表1 兴趣值计算方案
其中,curNum代表读者已借阅该图书次数。a1、a2、a3、a4分别表示相关借阅行为的兴趣系数,通过网格搜索方法可推算出各系数最优的取值。
综上,读者u对图书i的兴趣度总值Sϕu,i通过ϕ u,1-ϕu,5对无权重求和得出,表达式见式(3)。

(2)兴趣值标准化。按照式(3)的计算规则,如果一个读者多次“借过再借”同一本书,那么对这本书的借阅兴趣值必然会大于5,而超出所期望的[0,5]分布区间,这样不利于使用余弦相似度算法计算读者之间的相似度,因此需引入受限Tanh函数对S ϕ u,i进行标准化,兴趣值标准化函数表达式见式(4)。借鉴Tanh函数的原因在于其具备独特的数学性质,具体的表现为[0,+∞]在区间内一阶导数恒大于零、二阶导数恒小于零、且取值范围为[0,1)。Tanh 函数的表达式如式(5),其在[0,+∞]的取值范围见式(6)(7)。
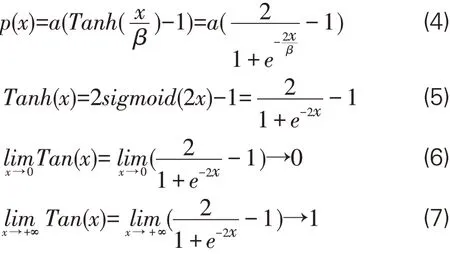
式(4)中,p(x)的x值即为兴趣总值S ϕ u,i,参数α为评分上限,参数β用于调控p(x)增速。根据链式求导法则可知,当α,β都取正值时,p(x)具备与Tanh函数相同的一二阶导数性质,即α,β只影响p(x)一二级导数的值的大小,不影响其正负,故而该兴趣值标准化函数可达到数值标准化的需求。为保证兴趣标准化后评分在[0,α]取值区间内能有一个较好的区分度,需寻找适合的α,β值。p(x)函数在不同α,β值下的函数走势见图2。由图2(a-d)可知,p(x)随着用户兴趣值x的增大而增大,并逐渐趋向于α 值,同时p(n+1)与p(n)的差值随着n的增大而逐渐变小,且其变小的速度随着β的增大而减小。
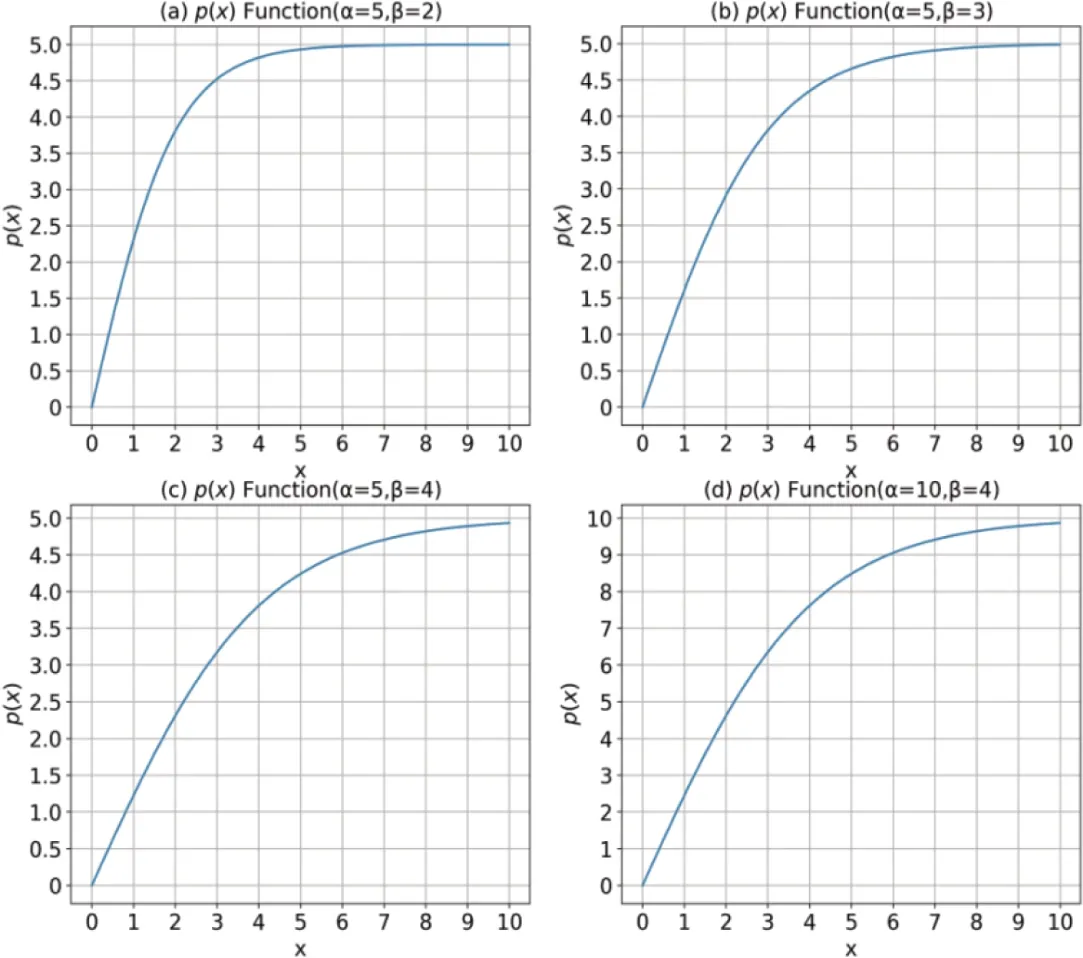
图2 p(x)函数在不同α、 β 值下的函数走势
为使用户评分值处于[0,5]的取值区间,设置p(x)的α 为5。同时在观察图2中p(x)函数在不同α、β值下的函数走势后,为使标准化后的兴趣值区分度较好,将参数β设置为4。此时,当两个读者对某书籍的兴趣值为较大值时(比如7与8),模型认为这两位用户对此书的兴趣度都较高,但是兴趣度相差不会很大(标准化后的兴趣值分别为4.7与4.8,逼近评分上限值5),而当两位读者对同一本书的兴趣值为较小值(如2与3)时,模型则会认为这两位读者对该书的兴趣值相差较大(标准化后的兴趣值分别为2.3与3.1)。此时标准化函数如式(8)所示、标准化函数的走势可见图2(c)。
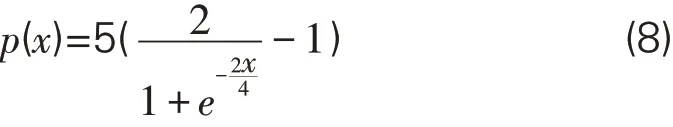
综上所述,通过IRM得到“用户-图书-评分矩阵”,计算步骤见表2。

表2 IRM计算步骤
2.2 时间衰减模型
时间衰减模型的提出主要是源于研究场景中用户借阅行为轨迹易发生变迁这一特点,通过对兴趣评分模型生成的“用户-图书-评分”矩阵进行优化,将读者近期借阅的图书赋予更高的评分值,同时在评分值上对读者较久远借阅的图书进行惩罚。经典的时间衰减函数的表达式见式(9)。

其中,α 表示时间衰减因子;T表示当前时间;t表示图书被借阅的时间;T-t表示时间差,单位为天。时间衰减因子α决定着f(t)的衰减速率,f(t)随着时间差的增长而减小,取值范围为[0-1]。
除经典的时间衰减函数,学者们还提出了许多其他形式的时间衰减函数。比如,有学者[9]提出线性时间衰减函数,但这种线性衰减特性与人类遗忘特性不符,不太适用于该场景。有些学者[6,10-11]提出以e或其他常数为底的指数型时间衰减函数,与式(9)类似,呈现了非线性特征,具有较好的兴趣变迁表征能力。借鉴上述成果,构造了新的非线性时间衰减函数,记作RETD(Ratio Exponential Time-Decay Function),其表达式见式(10)。基于RETD的模型记作TDM-RETD,表达式见式(11)。
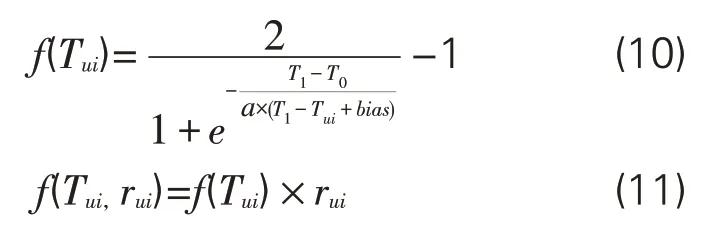
其中,Tui指的是在当前借阅记录中用户u对图书i操作的最后时间,rui指的是用户u对图书i的兴趣评分,T1表示测试集起始日期,T0表示借阅记录中所有用户最早借阅日期。α 为时间衰减因子,用于控制f(Tui)随-(T1-T0)/(T1-Tui)值递减时的衰减速度,bias为偏置量,用于防止出现T1-Tui=0算术运算错误,在计算时会设置为一个非常小的值。
由于f(Tui,rui)中的rui在实际计算时为一常量,因此f(Tui,rui)的走势可通过分析f(Tui)完成。由于bias为非常小的偏置项,当Tui趋向于T0时,T1-Tui近似等于T1-Tui+bias,故而在式(10)中以e为底的指数项可近似等于-1/α。当Tui趋向于T1时,-(T1-T0)/(α×(T1-Tui+bias))趋向于负无穷,故而式(10)结果趋向于1。综上,f(Tui)及f(Tui,rui)的取值范围求解见式(12)(13)(14)(15)。
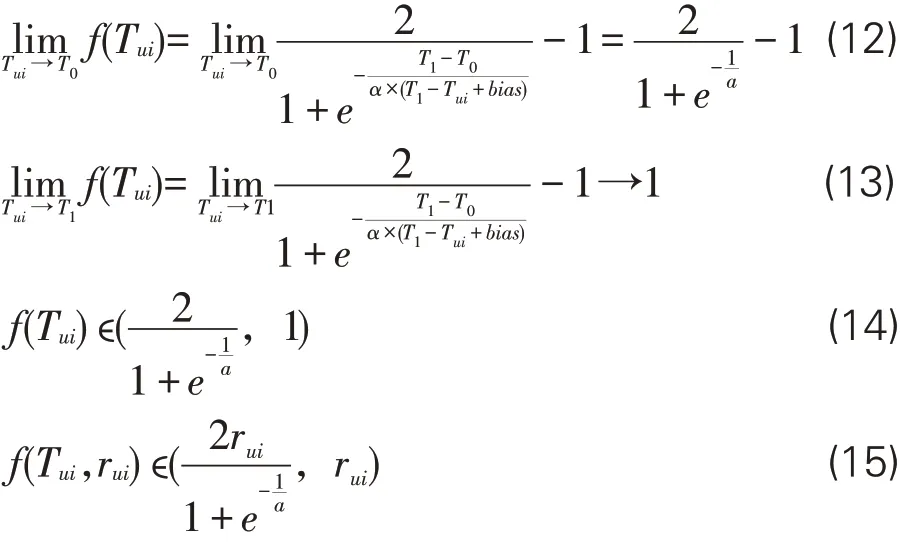
对f(Tui)进行分析后,易知整个模型的衰减速度主要受α与T1-T0的取值影响,其中T1-T0在训练集及测试集选定好时便可确定,α 则需要根据T1-T0值与T1-Tui取值范围来选定。在实际使用时,可以采用网格搜索来获得α的最佳取值。
2.3 内容兴趣捕捉模型
对经典UserCF来说,对召回集项目的评分预测后,取评分最高的N个项目即完成推荐。高校图书馆场景下存在用户借阅行为较少、用户-项目矩阵稀疏且借阅兴趣随时间变化产生较大波动等问题,会造成UserCF推荐列表不够精准现象。为解决该问题,ICBO UserCF借鉴研究[12-13]成果,构建内容捕捉模型ICM,表达式见式(16)。在TDM-RETD基础上,ICM对召回集按照图书分类号进行精排序,按分类号最细一级进行内容聚类,对召回集重构评分矩阵,降低了数据稀疏度。同时ICM加入时间衰减函数,应对兴趣变迁影响。经过ICM优化处理后的召回集,大大提高了推荐列表TOP N的准确性。

式(16)与式(11)在表达形式上基本相同,最大的不同是式(11)中f(Tui,ruij)的Tui指的是用户u借阅某本图书i的时间,rui指的是用户u借阅某本图书i的兴趣评分值。式(11)中R(Tui,ruij)的Tui指的是用户u借阅某个图书类别i的最后时间,ruij指的是用户u对召回项目中i类图书j的预测评分值,式(11)其它T1、T0、α、bias四个参数的意义与式(11)中的一致。
综上所述,ICBO UserCF算法计算步骤见表3,输入“用户-图书-评分矩阵”R1由上文IRM得出。

表3 ICBO UserCF算法计算步骤
3 实验结果及分析
3.1 数据集
实验数据来源于深圳大学图书馆2017级学生2017-2019年2年间的借阅日志,包括读者借阅记录表和读者预约记录表,涉及字段见表4。实验将数据切分为训练集与测试集,训练集用于分析读者行为并给出推荐结果,测试集用于验证训练集推荐结果的准确度。训练集包括2017年9月6 日至2019 年5 月31 日之间的读者行为记录,涉及读者4,286人、图书34,419册、借阅事务总计51,637次。测试集包括2019年6月1-30日产生的借阅记录,涉及读者892人、图书2,341册,借阅事务总计2,595次。
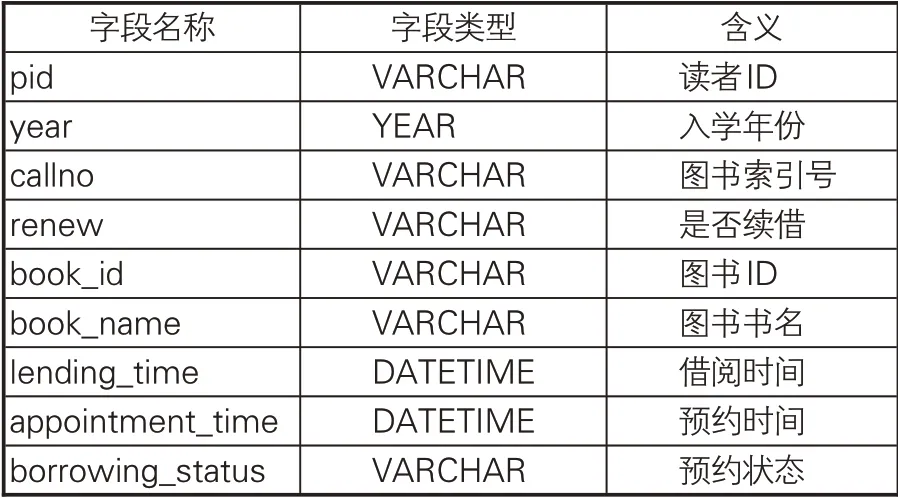
表4 借阅日志字段
3.2 实验设计
实验以UserCF算法为基准,用户相似度计算方法采用式(1)的余弦相似度计算法、寻找最近邻使用K最近邻法(K值不设上线)、预测评分采用式2的加权计算法。实验内容主要包括设定模型参数和验证模型性能。首先采用网格检索方法,根据推荐F值来寻找和确定最优参数值,然后通过两组实验对模型各要素及RETD时间衰减函数的有效性和性能进行验证。
第一组实验是验证本文提出的ICBO UserCF算法所涉及到的IRM、TDM和ICM三个模型的性能。第二组实验是对比RETD时间衰减函数的性能优势,具体实验设计如下:将推荐书目N设定为20,根据表3的计算步骤,将TDM和ICM模型中的RETD函数替换为经典时间衰减函数(common),即在其他条件不变的情况下将式(11)和式(16)中f(Tui)的变为式(9)的经典时间衰减函数。
计数统计法计算用户评分矩阵的方法如下:记读者对某图书的“借阅次数”为num1、“续借次数”为num2、“预约次数”为num3,则用户对该图书的评分值val如式(17)。
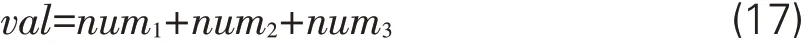
为评估算法性能,采用准确率(Precision)、召回率(Recall)、F值(F-Measure)和覆盖度(Coverage)来评估算法的推荐效果,详见式(18)(19)(20)(21):

其中,U代表用户集合,I代表书目集合,R(u)代表根据用户在训练集上的行为给用户做出的推荐列表,T(u)代表用户在测试集上的行为列表。由于准确率和召回率是既矛盾又统一的两个指标,而F值将准确率和召回率进行了加权调和平均,能够综合评定准确率和召回率的效果。
3.3 实验过程与结果分析
3.3.1 模型参数设定
模型参数主要包括IRM中各行为兴趣值权重和TDM、ICM中RETD函数α值。
基于IRM计算评分矩阵的方法及步骤见表2。IRM 涉及到的兴趣系数α1、α2、α3、α4的取值,通过网格检索方法并经过多次实验后发现,当α1、α2、α3、α4分别取值为0.7、0.4、1.2、0.4时,采用UserCF 算法计算出来的推荐结果最佳。通过该结果,可以猜想兴趣系数可能与时间成本和读者借阅心理需求相关,在其他条件相同的情况下,“借预约书”代表这本书对读者具有一定的价值,对图书的了解程度也相对最深,值得用户经过长时间等待依然愿意借阅该书,故而兴趣系数最大,“借过再借”其次,而“预约未借”和“网上续借”仅需在线上操作即可,所以兴趣值权重最小。
基于RETD函数的TDM和ICM具体的方法及步骤见表3,分类号可从读者借阅记录表中的“callno”字段取出。在涉及到的TDM和ICM公式中,参数T1-T0由训练集起止时间算出为881,偏置量bias取一较小值0.001。两者的α 值则由网格检索求出。实验中设TDM 的α 值为α1,ICM的α值为α2。经过多次试验,实验将检索范围设定在[6,18],步长为2,观察不同α 值对应Top5~30(步长为5)推荐F值总值情况,最终选定衰减参数α1取值为16,α2为6。此时TDM 和ICM 的表达式见式(22)(23),对应RETD 函数走势见图3。由结果看出,在α1>α2情况下的推荐效果较优,表明相较于读者对某本书的兴趣度流失速度,读者对于图书类别的兴趣度流失速度要慢得多,且基本是以年为转折,这预示着高校学生随着年级增长,涉猎的图书类别会有较大差异,但同年级期间学生对于图书类别的兴趣变化幅度稍小。

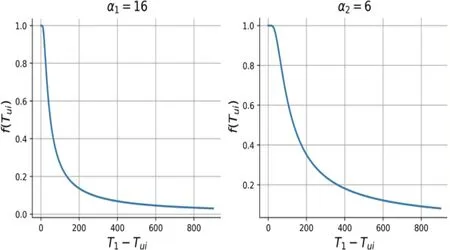
图3 α1=16、α2=6时f(Tui)的函数图像
3.3.2 模型性能验证
为验证基于行为评分、时间上下文和内容兴趣要素叠加改进而成的ICBO UserCF算法以及RETD时间衰减函数的有效性,按照实验设计,进行两组实验。
第一组实验以基于计数统计法构建评分矩阵的UserCF 算法作为基准,记为“USERCF@计数统计法”;以基于IRM 模型构建评分矩阵的UserCF算法,记为“USERCF@IRM”;在IRM基础上加入基于RETD函数的TDM模型优化评分矩阵的UserCF 算法,记为“USERCF@IRM_TDM-RETD”;在通过TDM-RETD模型优化评分矩阵得到召回集的基础上,运用ICM模型对召回结果进行排序得到的UserCF算法,为本文最终提出的算法,记为“ICBO UserCF”。最终通过实验,分别得到当推荐书目N为5、10、20、30时的推荐列表,推荐效果对比结果见表5。
表5 ICBO UserCF算法性能评估
由表5看出,在为测试集用户推荐5~30本书籍时,ICBO UserCF算法在准确率、召回率、F值、覆盖度均有所提升,验证了有效性:(1)验证了行为评分模型IRM的有效性。由表5可知,基于IRM 的UserCF 相较于计数统计法F值提升0.41%~0.51%,覆盖度提升2.03%~9.64%,说明IRM更接近于用户的真实兴趣值,更具客观性且推荐书目覆盖更广。(2)验证了时间上下文模型TDM的有效性。在IRM基础上叠加TDM-RETD,相比于只有IRM 的F值提升1.99%~2.92%,覆盖度提升0.69%~1.27%,表明用户的借阅兴趣存在时间效应,加入TDM能有效捕捉用户的近期兴趣。(3)验证了内容兴趣模型ICM的有效性。在前两者的基础上加入ICM,F值相比单引入TDM-RETD和IRM优化提升了1.66%~2.26%,相较最初基于计数统计法的UserCF提升了4.16%~5.62%,其中Top5的F值提升增幅最高,达141%。由此说明,ICM模型使算法性能有显著的提升效果,能体现高校图书馆场景下读者兴趣变迁的特性。因此,ICBO UserCF算法可有效地基于时间上下文捕捉用户的借阅兴趣,达到提高推荐效果的目的。
第二组实验为验证本文提出的RETD时间衰减函数有效性,将RETD函数与经典的时间衰减函数做对比,观察两者的推荐效果,结果见表6。由表6看出,使用RETD时间衰减模型进行推荐时,推荐准确率、召回率和F值均有一定程度的提升。因此,RETD相较于经典的时间衰减函数具有一定的优势。

表6 RETD有效性验证
4 结论和展望
ICBO UserCF针对高校图书馆应用UserCF开展个性化图书推荐面临的评分数据缺乏问题,以借阅行为构建IRM模型,评分机制具有客观性和普适性;提出新的时间衰减函数RETD,应用于TDM和ICM模型,对解决兴趣变迁、数据稀疏等问题有明显帮助,优化了UserCF算法。在推荐相同数量的图书时,相比传统的协同过滤算法和经典时间衰减函数,ICBO UserCF的准确率、召回率和F值均有较显著的提升。不足之处在于,一方面ICBO UserCF 和多数研究一样,仅仅在已有的数据集进行了测试,推荐效果并没有在实际应用中得到验证。另外,虽然ICM兴趣捕捉模型丰富了评分矩阵的数据,但用户冷启动和数据稀疏问题依然存在,影响了推荐效果。另一方面,本研究为实现高校图书馆的个性化推荐服务,主要针对推荐F值进行了探究,而在推荐多样性、新颖性和惊喜度方面没有进行探索,在实际推荐中,若仅针对用户过去的喜好推荐图书,可能会陷入“信息茧房”困境,故在实际上线推荐应用时,可加入部分经典推荐、新书推荐和热书推荐栏目,增加推荐的多样性。
关于ICBO UserCF 的深化研究计划包括3个方面。首先是推广应用,将通过“我的图书馆”向学生进行个性化TOP N图书推荐,根据实际借书行为和读者调查反馈情况来评估算法的准确性,并改进算法,提高实用能力。其次是加强对读者及行为的研究,根据高校的特点,对学生按专业、年级、性别等特征进行个别或团体的画像,将用户画像技术应用于ICBO UserCF中,尝试解决新生冷启动问题;同时设立借阅评价功能,鼓励学生对阅读的图书进行评价,建立显式评分机制。最后是深入研究图书本身,通过内容分析,建立馆藏图书和本科专业、博硕士学科点之间的有机联系;通过使用分析,区分某种书或某类书的热门或冷门程度等。总之,要在研究读者和图书的基础上,不断优化ICBO UserCF,提升基于用户的协同过滤图书推荐技术的准确性和实用性,提高图书馆的精准服务水平。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
南风(2020年22期)2020-09-15 07:47:08
小学生优秀作文(低年级)(2019年5期)2019-04-25 13:13:40
小学阅读指南·低年级版(2017年12期)2017-12-26 17:01:14
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
