
少数民族大学生学业成绩影响因素分析
2021-03-18 06:53
科学与信息化 2021年7期
北京第二外国语学院网络与信息中心 北京 100024
引言
随着我国教育、教学水平的不断提高与高等教育的不断扩大化,越来越多的少数民族学生赴内地高校求学深造,少数民族大学生已成为我国高校大学生群体中的重要组成部分和社会高等专业人才的重要力量。但少数民族地区所具有的文化多元、人才缺乏、发展滞后的地域特征,使少数民族大学生普遍呈现出汉语、英语水平不高、基础知识储备不足、学习动机相对不强等特征[1]。如何采集各类相关数据对少数民族大学生与全体本科生的各项相关数据进行描述性对比分析,还原少数民族大学生的学业真实情况[2],找出学业成绩的影响因素,以便根据其特点因材施教,助力提高少数民族学生的学业成绩是目前高校面临的重要课题。
1 研究对象及方法
研究以北京某高校2013-2019级7个年级共962位少数民族学生为研究对象。参考国内大部分高校通用的GPA(绩点成绩)计算方法,以GPA作为衡量学生学业成绩的标准,从学校各业务系统的数据中抽取出与研究主题相关的数据,进行描述性对比分析,而后利用挖掘算法,建立各特征因素对少数民族学生学业成绩的影响模型。根据学生的绩点成绩对学生进行学业成绩名次排序,名次在前20%及以内的学生学业成绩设为A,名次在20%~40%的学生学业成绩设为B,以此类推,名次在后20%的学生学业成绩为E,通过验证少数民族学生学业成绩预测模型准确率及精度验证影响因素选择的合理性。
2 数据获取及描述性统计分析
2.1 数据获取
研究从相关系统中提取到学生相关信息包括:籍贯、性别等人口统计信息;年级、院系、专业等学籍信息;校园消费、上网时长、外借图书馆册数等校园行为信息,将所获取的这些信息特征作为影响少数民族学生学业成绩的潜在因素。
2.2 描述性统计对比分析
(1)GPA统计分析
研究分别对少数民族学生和全体本科本的绩点成绩进行了统计,数据显示:2013-2019级少数民族学生的GPA均值为2.81,全体本科生的GPA均值为3.13,少数民族学生的GPA均值较全体本科生偏低10.22%。
(2)数值型特征统计分析
少数民族学生和全体本科本的数值型特征描述性分析如表1所示,包含上网时常、借书数量、消费天数、入馆天数、日均消费等行为特征的分布情况。
由上述对比可知,少数民族学生在上网时长、年借书册数、年消费次数、自习次数的均值都低于全体本科生,日均消费数则高于全体本科生。
3 建立影响因素模型
3.1 数据拆分
对962条数据采用随机抽样的方法抽取80%的样本数据共769条数据作为训练数据集,用来训练建立模型,余下的20%样本数据共193条数据则作为测试数据集,测评数据集用于在模型建立后检测模型的性能。
3.2 筛选影响因素
研究选取随机森林算法构建少数民族学生学业成绩影响因素模型,为使构建的模型易于理解,需要从全部特征中选取相关性强的特征因素构建最优影响因素子集[3]。选用最优特征子集的方法可以缩短模型的训练时间,增加模型的通用性,降低过拟合的风险。研究采用了正向选择法进行最优特征集选择:从空特征集开始,向特征集合中加入一个该集合不包含的特征,然后对新的集合进行评估,找出评估结果最佳的特征变量加入当前集合;不断重复,直到加入任何新的特征变量都不能提高评估结果为止。通过实验得到当随机森林分类模型包含年消费天数、性别、年借书数量、年自习天数、日均消费、籍贯、年上网时常、所在专业8个特征时模型拟合程度是最佳的。
3.3 模型性能评估
在构建好随机森林的分类模型后,以测试集中的193条记录对模型的分类性能进行评估测试。模型验证结果的混淆矩阵见表2。
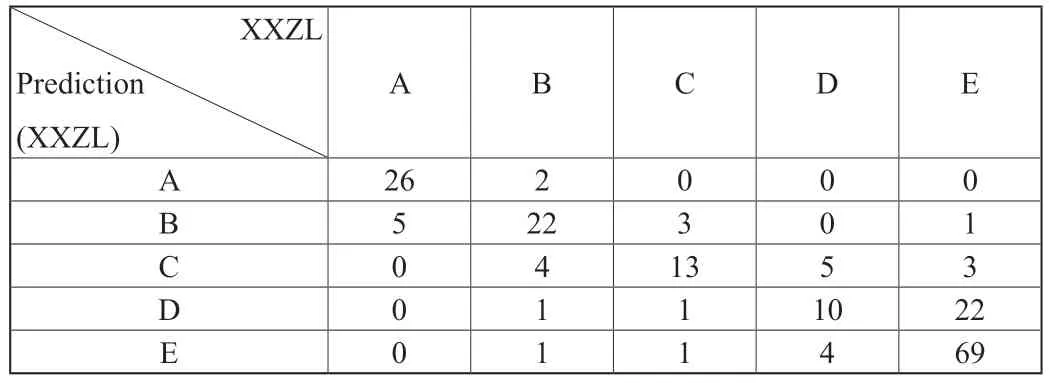
表2 模型混淆矩阵
混淆矩阵一个n行n列矩阵,其中n为分类数。在该矩阵中,正类(positive)为1,负类(negative)为0。混淆矩阵主对角线上的值为TP(True Positive)即正类且预测为正类的样本个数;每列除主对角线元素以外的其他位置元素值为FP(False Positive)即正类且预测为负类的样本个数。此外还可通过计算得到模型的TN(True Negative)负类且预测为负类的样本个数和FN(False Negative)即正类且预测为负类的样本个数。分类模型的准确率及精度的计算公式可表示为:Precision。通过对表2的计算可得到,随机森林模型的验证预测准确率达到72.54%,预测精度达到70.92%,证明了特征变量选择是合适的。
4 影响因素分析
(1)总的来看,相对于汉族学生,少数民族学生的学业成绩整体呈落后状态。
(2)学生管理部门应重视少数民族学生的年在校天数较汉族学生偏少的现状,对于少数民族学生的考勤情况应给予更多关注。
(3)性别差异导致少数民族学生的学业成绩出现分化现象,应采取相应措施来改善此种局面。
(4)学校相关部门应着力改善少数民族学生的学习环境,尽可能地为少数民族学生营造良好的学习氛围,引导和鼓励少数民族学生增加阅读量和其他自主学习机会。
(5)与传统观念不同的是,上网时间的增加不仅不会影响少数民族学生的学业成绩反而会起到促进作用,应当引导学生正确使用网络资源。
(6)外部因素对少数民族学生学业成绩的影响远小于内部因素的影响[5],而且学生在校行为比其他因素对学业成绩的影响力更大。
5 结束语
(1)本文考虑少数民族学生的学业成绩的影响因素时,未将学生的历史成绩作为影响因素指标。在实际应用中,若加入该因素,重新生成模型,模型准确度和精度可能会有提升。
(2)由于数据统计时对数据时间区间的设定为2013年1月至2019年12月,以2019级少数民族学生数据为测试集,并以对2019-2020学年第一学期的期未绩点成绩对预测结果进行验证。模型的预测准确性明显降低,仅为44%左右,造成这种结果的原因可能包含:
1)新生校园行为数据的数据量较小。
2)新生入学后对大学生活有适应期,其行为数据尚未稳定。
3)以大一第一学期的期末成绩代表学生的学业成绩有其片面性,但可以发现模型不太适用于新生学习情况预测。
(3)以少数民族学生为样本的学习质量分析有其局限性,未来可从其他角度对学生进行分类,进行学生学业成绩的预测和监控。
研究从促进少数民族学生管理工作开展、提高学生管理工作效率、促进少数民族大学生学业成绩提高的角度出发,以少数民族大学生这一特殊的大学生群体为对象开展的学业成绩影响因素分析研究,力求突破以往单一的分析视角,利用客观数据对影响少数民族学生学业成绩的因素展开全面、科学的分析。以经过预处理的少数民族本科生在校期间的相关数据为样本进行模型训练,建立少数民族学生学业成绩和影响因素之间的映射关系,并以对随机森林算法构建模型的分类预测率验证影响因素选择合理性。
但本研究也存在一些不足之处,对于影响因素对于少数民族学生学业成绩是如何产生影响的还有待进一步研究。
猜你喜欢
无线互联科技(2022年8期)2022-06-23
家教世界(2022年10期)2022-05-06
牡丹江医学院学报(2019年5期)2019-11-04
作文周刊·小学二年级版(2019年36期)2019-10-17
小学生学习指导(低年级)(2019年3期)2019-04-22
活力(2019年21期)2019-04-01
领导决策信息(2018年16期)2018-09-27
中国德育(2017年10期)2017-06-17
数学学习与研究(2017年3期)2017-03-09
西南学林(2011年0期)2011-11-12
