
基于CNN-SVM的选煤厂浮选泡沫图像识别方法
2021-03-18 09:33孙友森陈传海杨志龙王新欣
煤炭加工与综合利用 2021年2期
孙友森,陈传海,杨志龙,王新欣
(1.枣矿集团煤质管理处,山东 枣庄 277000;2.山东山控信息科技有限公司,山东 济南 250000)
1 概 述
计算机视觉技术是利用相机与电脑连接成的一个系统,通过对目标的检测、追踪、测量和进一步预处理得到能够代表图像特征的信息,再对这些特征信息通过计算机算法进行识别[1-2]。在选煤行业,随着选煤厂智能化水平的提高,对各个生产岗位的要求也更加严格,同样浮选车间的控制也要求精煤灰分尽可能稳定[3]。前人在浮选泡沫图像的识别问题上已经做了大量的研究,例如,Kaartinen[4]在锌粗选浮选槽中进行基于机器视觉的浮选控制实验,在监控系统中,使用的泡沫图像特征主要包括泡沫颜色、泡沫坍塌率、气泡尺寸和一些主要药剂的添加量,基于这些泡沫图像特征对生产工况进行分类。Brown[5]等设计了一个基于泡沫表面视觉特征的浮选过程控制器来控制浮选泡沬流速和液位、起泡剂添加量、通风量3个浮选操作变量。结果表明,当浮选流速能够很好地控制时,浮选性能也能稳定下来。中南大学的桂卫华、杨春华等[6]根据大量的样本和实验,利用机器视觉技术和图像处理技术,设计了一套铜浮选泡沬图像监控系统。利用BP神经网络建立相关指标的预测模型,指导铜浮选生产过程。洪升[7]研究建立了选矿过程中在线监控系统,采用了支持向量机(SVM)的预测方法,进行浮选回收率预测,此方法显著提高了浮选指标的预测精度和模型的泛化能力,使其具有更好的应用性。可以看出,浮选车间的自动化发展是当前研究的热点问题。
由于浮选车间工况复杂[8-9],精矿的品位常常受入料性质、加药量和工人操作等多方面条件的影响,应用在现场的识别精度并不是很高。因此,一种准确可靠的预测算法成为当前研究的重点。传统的图像识别技术更加适应于有明显特征、背景简单的情况[10-11],而选煤厂浮选车间工况复杂,煤泥浮选泡沫图像特征单一,并且捕捉到的图像由于现场特殊环境的干扰往往带有较大的噪声,这样给浮选车间智能化的进程带来严重阻碍。
将卷积神经网络(CNN)[12]和支持向量机(SVM)[13]结合,提出一种混合的煤泥浮选泡沫图像识别算法,通过CNN自动提取图像特征,再将提取到的特征作为SVM的输入预测浮选实时灰分,通过调整网络参数和结构,取得了不错的分选结果。同时面对现场复杂的的环境,该混合算法具有较高的识别精度和较强的鲁棒性(即算法对数据变化的容忍度)。
2 CNN-SVM模型概述
卷积神经网络(CNN)是一种包含多层的深度卷积神经网络模型,它由自动特征提取部分和全连接层组成,特征提取部分包括卷积层和池化层两部分,通过卷积和池化2种过程的迭代从煤泥浮选泡沫图像上提取特征信息[14]。支持向量基(SVM)将特征数据投影到特征空间中寻找最优的分离面,根据其核函数的不同,它可以用来处理线性和非线性问题[15]。卷积神经网络的神经元由权重和偏置项组成,每一个神经元接受输入并执行卷积计算,每个神经元接受来自前端的输入并执行一次点积运算,然后整个神经网络表达出一个评分函数,对网络的输入到输出进行评分[16]。在CNN中通常用一个损失函数对网络中的参数进行估计,这就形成了一个将原始图像变为特征向量的特征提取器[17]。另一部分就是全连接层,将提取到的特征向量按照前向传播网络进行分类。
混合的CNN—SVM模型是将CNN最后的全连接网络层替换为SVM分类器。CNN网络的最外层实际上是指每个样本标签所对应的可能出现的概率估计值,每一个概率估计值对应一个激活函数,单查看隐含层的输出对于分类结果是没有任何意义的,它仅仅对CNN网络模型本身有意义,但是这些值可以作为SVM分类器的特征输入。图1为CNN—SVM模型的网络结构图。首先,将煤泥浮选泡沫图像通过多次卷积和池化,对原始带有输出层的CNN进行预训练直到收敛,然后SVM将隐含层的输出作为特征输入进行训练,一旦SVM训练合格,就会对自动提取特征的煤泥图像做出预测。混合的CNN—SVM模型的优点弥补了两类分类器的局限性,提高了单一模型的泛化能力和模型精度。

图1 CNN—SVM混合模型结构
3 实验与分析
3.1 数据集
实验采用CCD工业相机对浮选泡沫拍照,选取更加可靠LED背光源为泡沫的补光光源,这样可以最大程度的减小浮选泡沫表面的反光现象。为了避免外界光源的干扰,对现场对采集系统进行遮光处理。针对浮选工况的不同,分散取样化验实时灰分作为图像标签,设置图像大小为1024×1024像素,对每个灰分标签连续采集30张照片,择优选取20张作为该标签对应的数据集。最终取得山东某选煤厂浮选车间的30 000张浮选泡沫图像,按照灰分区间不同将其标签划分为小于7、7~7.99、8~8.99、9~9.99、10~10.99、11~11.99、12~12.99、大于13共8个类别,其中20 000张作为训练集,7 000张作为验证集,最后3 000张作为测试集。
3.2 图像预处理
选煤厂浮选车间的实际环境比较特殊,因此在图像采集、传输等过程中,难免受到周围特殊环境和磁场等的影响,经过工业相机采集的图像最终传到计算机上时难免会带有较大的噪声和微小的失真现象,这样的图像喂入神经网络就会出现过拟合或者准确率较低,无法达到较好的的分类效果,为了解决这类问题必须对采集到的图像做去燥、增强等预处理。根据实际验证对采集到的数据集进行了高斯椒盐去燥和图像增强预处理,处理前后的图像如图2所示。

图2 预处理浮选泡沫图像
3.3 模型构建与分类结果
3.3.1 CNN特征提取
CNN被用来提取煤泥浮选泡沫图像特征被认为是有效的,本文在全连接层之前添加一个额外的卷积层,其中包含8个神经元的200个特征图。最大池化层进行全零填充和归一化操作。卷积神经网络的参数图如表1所示。
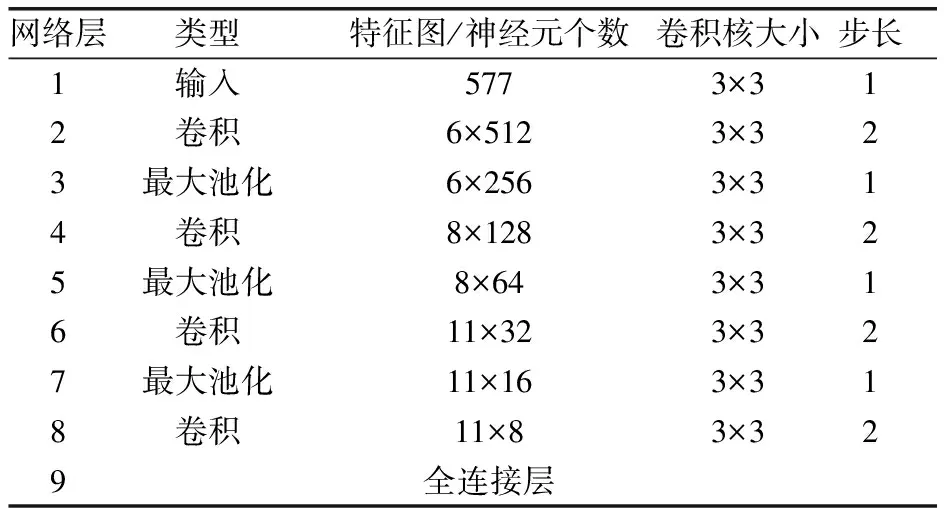
表1 CNN模型参数设计
3.3.2 SVM分类
在SVM中首先将数据投影到特征空间中,然后确定最优分离超平面,利用不同的核函数将线性问题转化为非线性问题。该方法最初是为了解决两类问题而提出的,然而现在这项技术已经被用来解决多分类问题。
首先将训练集S定义如下:
其中:yi∈{1,2,3,4,5,6,7,8}代表灰分标签的8个类别(小于7、7~7.99、8~8.99、9~9.99、10~10.99、11~11.99、12~12.99、大于13),并且i=2500。目前有2种方法用来解决多分类问题:一种是构件多个二分类SVM并将它们以一对一或一对多的方式联合起来,另一种是将所有多分类数据集考虑在一个最优化问题中用SVM分类。Hsu[18]等人通过使用不同的数据集验证得出一对一的方法更加合适实际应用。LIBSVM[19]是一种开源的SVM分类工具,本文将使用它来做分类处理,一对一的分类方法构建了一个k/(k-1)/2(k为分类数)分类器,其中每个分类器从k个类别中挑选出的2类作为训练数据。下式主要计算如何获取从第i和第j个类别的训练数据:


其中αi是拉格朗日乘子,核函数K用来计算高维空间未完成分类映射的点积,C是控制最大分类误差和最小分类误差的一个惩罚因子。在分类决定的过程中,LIBSVM采用“max Wins”算法[20],即每个分类器对上一次的分类结果评分,来获取最佳的分类结果。
3.3.3 实验结果与分析
在CNN—SVM混合训练模型中,使用SVM代替CNN最后的全连接层。为了构造混合模型中的SVM,通过对数据集采用10倍交叉验证的方法,采用径向基函数来确定最佳的核参数S和惩罚因子C。各参数的范围为C=[0.8,0.9,1.0,1.1,1.2],γ=[0.01,0.03,0.05,0.07,0.09],应用不同的组合最终选定C=1.0,γ=0.05。将这些参数代入混合模型,如图3所示,设置样本量大小为400,学习率为0.001,过拟合为0.75,50个训练样本之后模型的准确率达到了87.66%。

图3 CNN-SVM模型识别度准确率
模型中各个灰分类别的准确率如图4所示,从图中可以看出,CNN—SVM模型对每个灰分类别的泡沫识别准确率都在80%以上,其中灰分小于7%和大于13%的泡沫识别精度最高,达到90%以上,这也与浮选现场这2种泡沫的形态差距明显有一定关系。由于煤泥浮选泡沫图像差异小,分别难度高,所以识别精度不如其他的特征明显的图像高。但在未来的应用中,随着数据集的扩大和计算机计算能力的增强,相信可以取得不错的分类结果。

图4 各灰分等级的泡沫识别精度
4 结 语
以选煤厂煤泥浮选泡沫为分类对象,提出一种CNN—SVM混合的网络模型。先对输入网络前对所有图像做了增强去噪的预处理,该模型结合了支持向量机和神经网络的优点,利用CNN部分对预处理后的图像自动提取特征,之后将提取到的特征输给SVM预测分类,最终在本次煤泥浮选泡沫分类中取得了87.66%的准确率。在未来的研究中,通过继续增加网络的深度和获取更多的数据集有可能获得更高的准确率。
猜你喜欢
选煤技术(2022年2期)2022-06-06
选煤技术(2022年2期)2022-06-06
选煤技术(2022年2期)2022-06-06
选煤技术(2022年2期)2022-06-06
电子产品世界(2022年4期)2022-04-21
选煤技术(2022年1期)2022-04-19
煤化工(2021年4期)2021-09-13
四川蚕业(2021年4期)2021-03-08
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
