
中文语境下基于事件关联挖掘的金融网络构建与分析*
2021-03-18 07:26李朋远于华江成
中国科学院大学学报 2021年2期
李朋远,于华,江成
(1 中国科学院大学工程科学学院, 北京 100049; 2 首都经济贸易大学管理工程学院, 北京 100070)
金融是开展经济建设的重要推动力量。由于金融活动的参与者非常广泛,包括中央银行、金融机构、企业、个体群众、银证监管部门等,各方所具有的专业背景不同,在金融市场中所扮演角色和利益关切也不尽相同。面对金融领域各种情形,发现金融事件的内在联系,做出及时有效决策,是金融活动各参与方始终想要解决的问题。
复杂网络作为描述、分析复杂系统的有力工具,近年来引起了包括图书情报、交通物流、电力系统等在内的各领域越来越多研究者关注[1-3]。在金融领域,人们为探索金融活动内部或彼此间在某类型事物(例如市场参与者、参与者状态,乃至活动本身)上反映出的关联关系,会构建特定类型的复杂网络,即金融关联网络。通过资料查阅及整理,本文认为目前围绕金融关联网络的研究包含2大类、4种思路。
利用金融行业内部数据与理论,以金融风险传播为切入点进行金融系统的网络建模与分析。可概括为2种思路:
1)将金融系统内参与者个体作为网络节点进行关联关系建模,例如运用最小生成树MST和平面极大过滤图PMFG方法,构建、分析金融网络,动态识别金融网节点系统重要性[4];通过描述金融市场间协同行为,比较不同危机时期的网络结构[5]。类似还有通过市场分层与网络构建,结合时间演变分析系统性重要市场的研究[6],以及围绕银行行业内部系统性风险进行的讨论[7-8]。在这类研究中,复杂网络仅相当于梳理拟研究对象关系的工具,故研究的视角倾向于对金融领域知识理论的探讨。
2)将金融系统内参与者状态作为网络节点进行关联关系建模,主要是基于图模型展开。例如,Fu等[9-10]提出基于SIR传染模型的“潜在者-投资者-撤资人”(potential-investor-divestor,PID)模型,研究庞氏骗局在均匀和非均匀网络中的扩散动力学,对投资者网络进行分析,看其结构对于骗局扩散的影响,以及骗局操盘者的决策对网络结构的影响,并在上述模型的基础上,考虑直接再投资的个体行为,根据行为之间的转移关联,建立新的(potential-investor-divestor-investor,PIDI)模型;类似研究还有基于医学传染模型的金融风险交叉传染机制[11],以及对银行系统性风险的测度[12]。这类方法相比于上一类方法,能够利用时序数据开展动态的复杂网络构建和分析研究,多引入了一些计量经济模型。但和上一种方法一样,都受限于金融研究者的视角下开展研究工作,对于其他专业人员而言,存在一定的知识短板。
利用金融行业外部数据,不强调甚至不借助金融理论进行金融网络建模与分析。可概括为2种思路:
1)利用金融事件参与者的社交关联映射金融网络。例如,Alamsyah和Ramadhani[13]尝试探索由事件驱动(2014印尼大选事件)的网络拓扑结构变动与银行交易之间的关联;Lismont等[14]构建一个通过共享董事会成员连接的公司网络,应用统计学习分类算法及企业特性、网络特性或两者的不同组合创建5个模型,对网络中节点连接关系、节点的自身财务指标,进行避税的可能性分析;Zhou等[15]通过搜集腾讯QQ上的操作数据,从账户活力、交易序列和账户空间的相关性这3个方面,设计描述洗钱账户的多元特征,并利用统计分类算法,结合这些特征构建判断账户好坏的预测模型;类似的研究还包括使用包括社交网络数据在内的非传统金融数据,得到与研究金融现象有关的参与者网络[16-17]。此类方法能够将现已发展较为成熟的社交网络分析思路予以结合,可针对具体金融事件开展较为深入的研究。但在开展过程中往往会涉及数据搜集、研究者所处社会氛围等客观环境制约。
2)利用金融事件描述性数据(如新闻文本)挖掘事理关联映射金融网络。例如,Zhao等[18]认为可针对词段更进一步地挖掘事件间潜在关联关系,其基于前者的研究数据、基本遵循前者的文本因果提取思路,提出基于事件的双层因果网络模型,结合网络特点将嵌入式链路预测算法运用于分析之中;Souza和Aste[19]探讨基于多重网络方法,运用社交媒体渠道的信息和金融数据,预测期货市场的关联结构的可行性,并在样本外的实验中得到了高精度的结果;此外,还有利用财经新闻构建的股票市场知识图谱,进行关联实体挖掘的研究[20],以及先后利用半结构化数据和非结构化数据(金融新闻),构建出金融知识图谱并加以丰富完善,在给定事件场景下利用该知识图谱进行分析与决策应用[21]。在这类方法中,研究者可以通过爬虫获取相关新闻数据,避免了因所谓“内部数据不公开”造成的数据获取问题。同时研究视角不再强调围绕金融理论展开,打破了专业知识和数据获取的边界,使研究开展更具普适性。但相关研究目前都围绕在英文语境下,对于在其他语言环境下如何开展缺乏探讨。
综上所述,目前关注以事件为节点构建金融网络的研究较前3种研究思路更少。相关研究虽尚处在起步阶段,但在数据搜集选择上更为广泛,可供开展研究的视角也更多。然而,现有成果仅讨论了英文语境下如何构建一般化的金融事件关系网络,而同时考虑事件与实体网络构建与分析的研究,其事件和实体网络的构建过程是相互独立的。如何在非英语语境下(如中文)构建类似的事件关联网络,以及基于事件关联能否直接反映实体之间的关联关系,还有待进一步探讨分析。
本文的主要贡献为:1)提供一种以发现事件基本关联关系为目的,且不受语言环境限制,更具通用性的金融事件关联网络构建思路;2)提出一种基于事件关联关系的事件-实体关联映射方法,基于事件关联发现实体关联,作为一种新的获取实体关联关系的思路。
1 相关工作
本研究将构建一个能直接反映金融事件间关联关系的网络G(V,E)。其中,网络节点v∈V代表通过聚类得到的金融事件类,网络边e∈E代表对于这些抽象事件类之间的关联关系描述。
据我们所知,在现有事件因果关联网络构建的研究中,Zhao等[18]最先给出仅从文本语义入手,以事件为节点,进行非本体论的事件关联网络构建尝试。在其研究中,通过利用英文文本(英语新闻标题)数据,挖掘抽象层面事件间因果关系,构建一个能够描述抽象事件彼此因果关系的网络。本文认为,Zhao等提出的网络构建方法可概括为以下3个组成环节:1)因果关系识别;2)关联事件提取;3)因果事件抽象。
其中,环节1)对应数据筛选和预处理工作,环节2)搭建网络的具体事件层,环节3)生成网络抽象事件层,即得到一般化的金融事件关系网络。利用该方法,在英文语境下,利用新闻构建金融网络的思路可整理为表1所示的方法框架。其中变量D、FCOPA分别记录网络构建过程中,生成的事件文本集合,和经过WordNet和VerbNet语义知识库处理后得到的抽象事件集合。

表1 英文语境下基于事件因果的金融网络构建Table 1 Cause-effect based financial network construction under English context
根据表1所示的网络构建逻辑,面对搜集的新闻标题数据,识别关系事件是基于人工给定的包含因果关联的句法模式,以关键词匹配形式实现;提取关系事件即提取文本中起主谓宾作用的动、名词;因果事件的抽象则是引入现成的英文语义知识库,借助其给出的词语语义上下位概念体系,得到文本层面的语义抽象,直接完成不同事件在语义上的聚类。最后将抽象出来的一般化事件作为网络节点,把具体事件间已知的因果关系映射至抽象事件得到网络边,完成抽象事件间因果关联网络的构建。
然而,面对不同语言间的巨大差异,如何在非英文语境下选择合适的句法模式以处理文本,以及面对缺乏WordNet等成熟语义知识库的情形,如何完成事件抽象得到网络节点与连边,本文以在中文语境下获取的新闻标题数据为例,就表1中抽象得到网络节点与网络边的思路提出改进。
2 金融事件关联网络构建方法
在表1所示的现有网络构建方法基础上,淡化现有网络构建方法因语言差异导致的局限性,同时考虑更普遍的事件间关联关系(而非仅局限于因果关联关系),提出基于文本共现和层次聚类的金融网络构建方法框架,如表2所示。其中,变量D、SimMtrx、SimIdx分别记录网络构建过程中,生成的事件文本集合、文本关联矩阵、指定阈值下筛选出的关联文本的索引集合。

表2 构建金融事件关联网络Table 2 Framework of constructing financial event correlation network

27. forjinHclusterKWdo28. ifa,b∈iandc,d∈jwhilea+c,b+d∈Ddo29. addi,jtoV,(i,j)toE30. end if31. end for32.end for33.returnG(V,E)
相比于表1的网络构建方法,表2方法的改进包含以下3个方面:
1)关联关系识别:表2所示的方法框架中,考虑到新闻标题的高度概括性,新闻标题仍是网络构建的原材料。经过大量观察发现,中文语境下,新闻作者往往为了表达两个不同事件存在某种关联关系,如因果、时间顺序、类比对比等,而构造“两段式”标题——即由两个各自独立描述不同事件的半句及其间起黏结作用的空格复合成的标题。因此,通过“两段式”标题,能帮助获取不同事件之间,包括因果、时间顺序、类比对比等多种形式的关联关系。
2)关联事件提取:表1所示的现有网络构建方法中,关联事件识别与关联关系识别同时进行,其基于“新闻标题只简洁地传递事件最核心元素”的认知,认为直接提取文本中的动、名词,即可将其作为事件的基本描述,并用作后续关联事件抽象。这一逻辑是建立在后续可以直接借助WordNet等现成语义知识库中的词汇语义体系,利用上下位关系词完成事件的抽象。然而,在其他语言中,特别是中文语境下,考虑中文用语在分词和词性上的多变性,不仅缺乏类似的成熟语义知识库,更要考虑到分词尺度对文本语义的影响。因此,在表2提出的网络构建方法中,关联事件提取被放在关联事件抽象后进行,即当完成关联事件抽象后,针对抽象事件下包含的一系列描述具体事件的文本,以关键词提取的方式,利用TextRank算法[22],按动、名词词性优先识别的规则,用不超过4个词语将抽象事件进行提炼概括。
3)关联事件抽象:前文提到,表1所示方法框架中,其直接借助WordNet等现成语义知识库中的词汇语义体系,利用词语上下位关系完成事件的抽象,然后将已知具体事件间的关联关系映射为抽象事件间的关联关系。然而在中文语境下,该方法并不适用,最直接原因即缺乏现成的语义知识库供文本语义聚类之用。本文认为,不考虑语言上的差异,可直接考虑采用基于自底向上的层次聚类(hierarchical agglomerative clustering)框架[23],基于预先训练的词向量模型获取各文本向量并计算两两间相似度后,按相似度的降序将相似文本进行聚集,直至相似度达到预设的阈值停止,如此可避免表1方法内相应步骤的通用性问题;然后,查找不少于两个共现于同一聚类的文本,若与之分别组成标题的文本同属另一个聚类,则这两个聚类间存在关联关系,以此尽可能确保形成的事件路径是基于某一事件框架下的,同时令网络维持一定的路径形成能力,达到对抽象层面事件路径描述准确性和形成能力之间的平衡;遍历所有聚类后,即完成抽象类层面的事件关联。
3 金融事件-实体关联映射分析方法
通过金融事件网络,我们不仅可以从中获取一般化的金融事理关联及事件传递路径,更能利用事件层面的关联关系,通过事件-实体映射关系,探讨实体(如金融交易市场上的股票)间基于事件关联,可以呈现怎样的关联关系。
本文研究的“事件-实体关联”的内涵是一种针对不同关系集合间的映射,它将事件间关联关系和实体间关联关系联系起来,利用事件层面的关联关系和事件与实体间的对应关系,发现实体的关联关系;外延是由事件关联集合和实体关联集合及两个集合构成元素间的内在关联映射所构成的关联集合整体。其中,“实体关联”的内涵是一种关联关系,描述可造成金融领域活动的个体间由于某方面属性或表现,基于一定视角予以配对;外延是涉及金融领域的一切活动中,所有参与个体之间构成的关联关系的集合。
本文选择股票为映射实体对象,以股票关联为切入点,开展基于事件关联的实体关联映射尝试。我们设计通过事件-实体映射关系获取股票关联关系大致思路为:
1)给定目标股票集合,从构建事件关联网络所用的新闻数据集中,获取每只股票对应的事件集合;
2)根据已构建的事件关联网络,将各股票所包含事件全部转化为抽象事件,并得到抽象事件间形成的传递演变路径;
3)对比各股票的事件传递演变路径,计算路径相似度,得到基于事件关联的股票关联关系。
同样是发现股票之间的关联关系,目前的研究基本都是围绕股票价格数据开展的,常见方法包括基于股票价格时间序列的Granger因果关系[24-25],考虑给定时间段内股票价格趋势变化的Pearson相关性分析[26-28],等等;待得到股票间关联关系后,可通过每只股票基于其关联股票的价格变化,判断自身股价涨跌趋势,以趋势预测准确度来度量股票关联关系构建效果[26]。
本文同样选择以股票价格为切入点,考察基于事件关联的股票关联关系构建效果。考虑事件发生的时间先后,假设,给定一只股票,若有其他股票与该股票在事件演变路径上存在一致之处,则可认为这些股票与该股票间存在关联关系,且利用这些股票的市场价格数据,能够预测该股票价格的变化趋势;在相似事件传递路径基础上,路径时间同步度越高,股票基于其关联股票价格的趋势预测准确性越高。
图1展示了从事件关联网络映射实体(股票)关联,以及利用基于事件的实体关联关系判断股票价格变化趋势的实验流程。
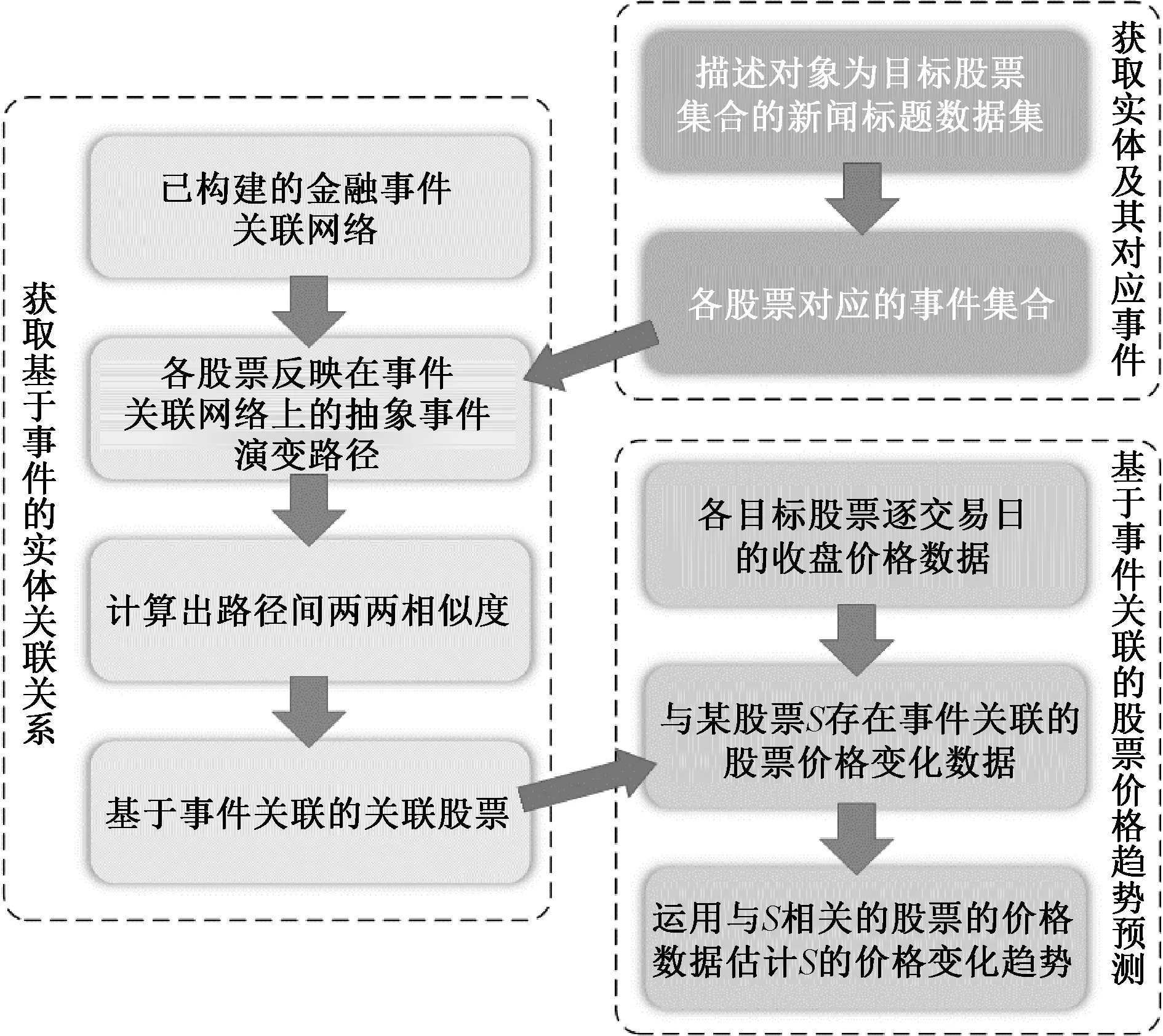
图1 基于事件关联发现实体关联的步骤Fig.1 Experimental procedures of finding relationships among entities based on event correlations
其中,通过新闻数据集和金融事件关联网络,发现某与给定股票S相关的事件构成的演变路径形式为Path(S)={s1(t1),s2(t2),…,sm(tm)},组成该路径的m个二元组各自包含了一个描述股票S的事件s和该事件的时间戳t;此外,分别用match、sync和allpairs记录两个路径上累计时间同步值、累计同步事件数、累计共现事件数,给定股票事件路径的时间同步阈值,计算事件路径之间两两相似度pathsim的方法如表3所示。

表3 股票事件路径相似度计算Table 3 Similarity calculation among stocks’ event paths
在关联结果检验环节,假设已知股票S与其基于事件关联的n只关联股票的关联权重为W={w1,w2,…,wn},并得知这n只股票t+1个交易日内的股价数据P={p1,p2,…,pn},Pn={pn,1,pn,2,…,pn,t+1},在第t和第t+1个交易日,各支股票的价格构成的集合分别为Pt={p1,t,p2,t,…,pn,t}和Pt+1={p1,t+1,p2,t+1,…,pn,t+1},即得到从第t个到第t+1个交易日,这n只股票的价格日变化幅度集合C(t,t+1)={c1,(t,t+1),c2,(t,t+1),…,cn,(t,t+1)},其中每只股票的变化值ci,(t,t+1)=pi,t+1-pi,t,i∈n。对于股票S而言,可以通过式(1)估计其从第t到第t+1个交易日的股价变化趋势qS,(t,t+1)
(1)
最终可得到股票S在t+1个交易日内的股价变化趋势序列QS={qS,(1,2),qS,(2,3),…,qS,(t,t+1)}。将QS与股票S在t+1个交易日内的股票价格实际变动序列CS,(t,t+1)={cS,(1,2),cS,(2,3),…,cS,(t,t+1)}按式(2)计算,即可得到股票S在t+1个交易日内依据事件关联的趋势预测准确度Acc(S):
(2)
4 实验分析
本节依照表2网络构建方法,搜集数据构建金融事件关联网络,分析构建出网络拓扑连通性;此外,利用这一网络进行事件-实体映射,得到股票市场实体关联网络,验证通过事件关联获取的实体关联关系在发现实体行业关联上的效果。实验在配置为Ubuntu 18.04操作系统的台式机平台上运行,核心硬件配置为:两个主频 2.6 GHz的Intel Xeon E5-2560 v2处理器,32 G运行内存。
4.1 网络构建数据
为获取构建网络所需数据,即财经新闻标题,通过爬取新浪财经网站上2017年3月2日至2019年7月2日的2 054 662条中文财经新闻标题,经过筛选处理后,得到520 056条符合网络构建要求的标题数据。
4.2 网络构建与拓扑分析
依照表2所示的方法构建网络时,存在一个不确定性变量,即在关联事件抽象过程中,如何选择文本对的聚类相似度阈值。基于直观判断,文本的相似度阈值选取决定网络的规模与形态:文本的相似度阈值设置的越低,能够用于事件抽象的文本对数量就越多,抽象出的事件数量对应着网络节点的数量;相反,相似度阈值选取得越高,进行聚类抽象的都是高相似度文本,保证了聚类抽象的质量,而这也将进一步影响网络边即抽象事件之间关联关系的生成质量。
按照表2所示的方法,利用HanLP中文自然语言处理包(1)https:∥github.com/hankcs/HanLP中Word2Vec预封装模块默认的CBOW框架训练词向量模型,用余弦相似度计算文本相似度,依次生成相似度阈值为0.95、0.90、0.85、0.80的4个网络。图2是这4个网络在以下3种特征的对比结果:
1)网络内所有连通分支的规模分布(即连通分支内节点数,按降序排列),见图2(a);
2)连通分支大小按降序排列和网络规模(即网络中节点数)之间的累积占比,见图2(b);
3)抽象事件数量与网络节点规模之比,见图2(c)。

CC即连通分支(connected components)的英文缩写。图2 文本相似度阈值变化与所构建网络拓扑的关系Fig.2 Relationship between the changing of text similarity threshold and network topology
图2中的3个子图展示了,文本相似度阈值设置的越低,整个网络的连通分支集中度就越高(如图2(a)和图2(b)所示);随着文本相似度阈值的降低,整个网络的规模会先膨胀后收缩,网络连通分支的数量会一直减少,而网络节点数与抽象事件数之比会逐渐上升(如图2(c)所示)。
上述现象反映事件话题种类数变化。随着文本相似度阈值的降低,可供网络构建使用的文本数据量不断增加,这不仅使得每个网络节点所对应的抽象事件内包含的文本数量增加,同时随着越来越多较低相似度文本对的加入,又涌现出更多新事件话题,从而抽象得到更多事件。但是,事件话题类别并不是无限制增长的——当相似文本对达到一定数量后,两个原本并不相干的抽象事件所对应的文本集可能会出现交叉,随着层次聚类不断深入二者被重新合并,因此孤立存在的抽象事件也随之减少。
由于设置的文本相似度阈值越高,抽象事件间的关联度也就越高。综合考虑网络构建所使用原始材料(即相似文本对)的可靠性,以及对抽象事件进行层次聚类后的主题覆盖率,我们认为:在文本相似度阈值设置为0.90时,可以构建出相对完善的事件关联网络,文本相似度阈值为0.85的网络次之;文本相似度阈值设置为0.95时,用于构建网络的数据相对较少,因此事件类型的覆盖广度和事件间关联挖掘程度上不如文本相似度阈值为0.90和0.85的网络;文本相似度阈值为0.80的网络明显存在网络节点过于集中的现象,而且网络整体节点数相比另外3个网络大幅减少,推断其可能过度地合并事件话题,使得各个事件类型被定义得过于宽泛,而网络中的连边,即“类事件”联系可靠性也随之被削弱。
4.3 金融事件路径传递分析
本文以4.2小节中生成的相似度阈值为0.95的网络为例,说明利用4.1小节中搜集的数据构建网络,可以帮助发现并解释一些金融现象,获取其中存在的事件传递关系。
图3展示文本相似度阈值为0.95的网络中最大的连通分支概况。
对网络中的部分细节予以放大,共包含以下5条路径,分属网络的2个部位(图中突出显示部分):
路径Ⅰ:[发、飞越、导弹、日本]→[开盘、下挫、下跌、道指]→[下跌、延续、趋势、昨日]
路径Ⅱ:[发、飞越、导弹、日本]→[避险、升温、情绪、市场]→[来袭、重磅、原油、EIA]
路径Ⅲ:[担忧、贸易战]→[避险、升温、情绪、市场]→[来袭、重磅、原油、EIA]
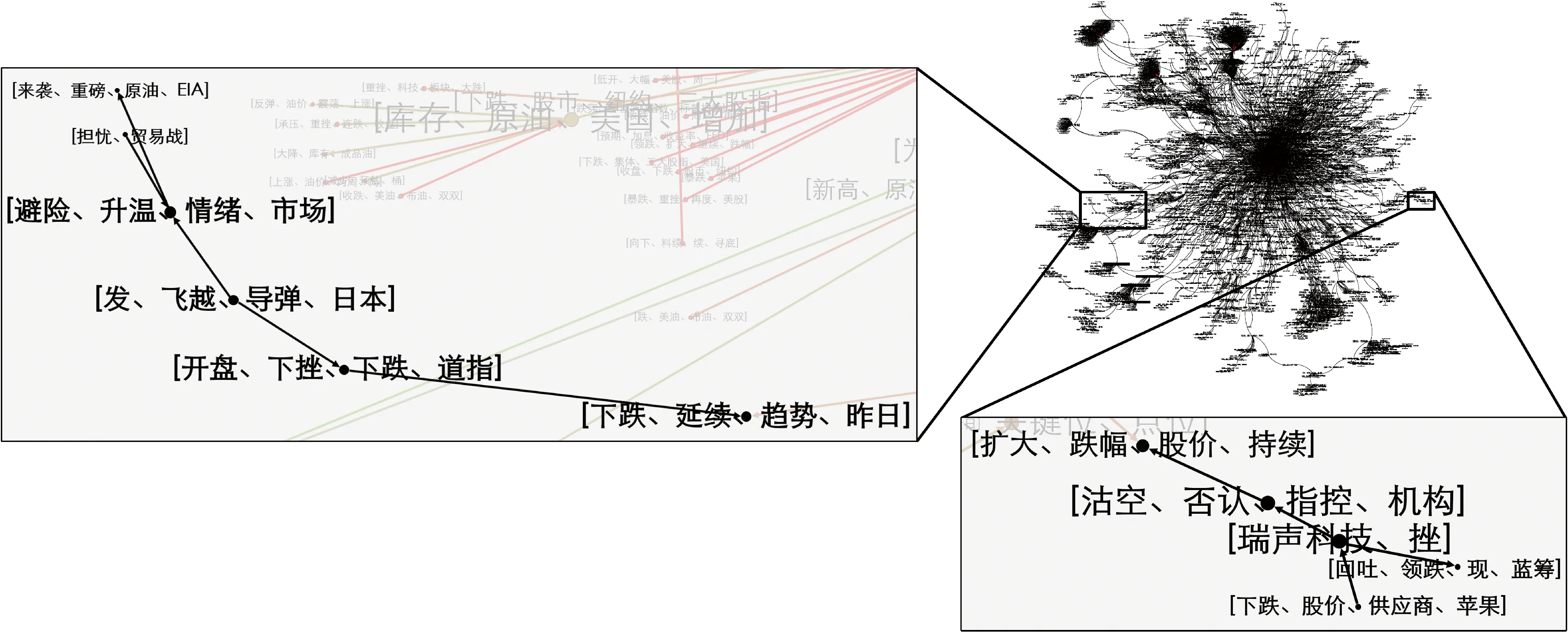
图3 生成的金融事件关联网络与部分路径细节Fig.3 Generated financial event correlation network and some of its path details
路径Ⅳ:[下跌、股价、供应商、苹果]→[瑞声科技、挫]→[回吐、领跌、现、蓝筹]
路径Ⅴ:[下跌、股价、供应商、苹果]→[瑞声科技、挫]→[沽空、否认、指控、机构]→[扩大、跌幅、股价、持续]
路径Ⅰ、Ⅱ、Ⅲ共同阐释了由政治事件造成的恐慌情绪,会对包括股票、原油等在内的金融市场产生影响。其中,路径Ⅰ和Ⅱ都描述的是源于地缘政治因素(导弹飞射)产生的恐慌情绪,不仅会使股票市场反映出连续的消极情绪,也可能会使原油市场有“大动作”出现;路径Ⅲ是贸易争端引起的市场恐慌,同样可能导致原油市场产生较大反应。
路径Ⅳ、Ⅴ反映了关联股票彼此间影响及可能引发的后续影响。瑞声科技作为苹果公司供应商,其股价会受苹果公司这一大型下游客户影响,并且影响之大可能会造成其在蓝筹股中的领跌局面;而当出现这种因供应链关系造成的股价牵连下跌时,相关机构不仅不会承认存在沽空的指控,股价反而可能会进一步下探。
通过构建网络,获取以上所示的事件传递路径,不仅可以帮助发现金融领域一般化事理演变,而且由于网络是基于大量描述具体事件的文本而构建,对于其中包含的参与事件的实体对象,在金融网络构建的同时,也可以帮助发现这些实体之间存在的关联关系,并利用实体关联开展一些应用。
4.4 事件-实体关联网络映射分析
按照本文图1和表3所示的方法步骤,开展金融事件-实体关联网络映射实验。实施过程中,利用本文4.2小节中构建的文本相似度阈值为0.90的网络,选择中证100指数(CSI100)成分股(2)CSI100成分股数据为2019年6月3日的调整版本。作为实验中的实体目标。通过Tushare Pro财经数据接口(3)https:∥tushare.pro/,获取2019年7月2日至2019年8月13日共计31 个交易日的中证100指数(CSI100)收盘价格数据。为研究预测时间远近与预测结果准确性之间的关系,我们将7月2日至7月16日11个交易日数据作为一组实验数据,7月2日至8月13日31个交易日数据作为另一组实验数据,进行两组预测实验;此外,选择1,3,5,7,14,30 d作为股票事件路径时间同步阈值,探讨事件演进路径的时间同步度对预测结果的影响。最终的实验结果如表4所示。

表4 基于事件关联网络的股票趋势预测Table 4 Stock price prediction based on event correlation network
由表4可见,随着股票事件路径时间同步阈值的增加,即路径两两间一致的事件也更趋向同步发生,会使得最终的趋势预测更加准确,但也会因同步条件变得严格,使得可预测的股票数量减少;同等可预测率下,预测时段整体越靠近起始时间节点,趋势的预测效果越好。
作为对比,获取2017年3月2日至2019年7月2日共570个交易日的中证100指数(CSI100)收盘价格,按照文献[26]里提供的基于股票价格发现股票关联关系的方法,选择用Pearson关联构建股票关联预测方法得到股票关联关系,并基于同样的预测数据和预测思路,输出与表4中同等可预测率的预测结果,如图4所示。

图4 基于事件关联的预测和基于Pearson关联的预测结果对比Fig.4 Comparison of trend prediction of event correlationbased and Pearson correlation based
相比以Pearson相似为代表的传统基于股价相关系数所建立的网络,我们提出的方法在股价预测方面体现出的本质不同可概括为以下两个方面:
1)实验数据上:实验数据所蕴含的信息量
以Pearson相似为代表的传统的基于股价相关系数所建立的网络,使用的都是最原始的交易数据,将这些原始时序数据作为确定股票关联相似度的素材;而我们的方法基于新闻文本搭建的金融事件关联网络,将获取的各个股票所发生的事情在事件关联网络上找出股票演变路径集合,作为股票相似度计算的素材。
2)方法实现上:股票关联网络边的生成
传统的基于股价相关系数所建立的股票关联网络,其网络边是通过对比所搜集的各股票价格日变化数据确定的。以本实验中利用Pearson相似度构建的网络为例,股票关联网络边是计算其彼此间时序数据的Pearson相关系数确定的;而本文方法所用股票关联网络的边是通过对比各股票的事件演进路径确定的,其建立在先期已构建好的事件关联网络上,通过查找各支股票在事件网络中的演进路径集合,设置路径相似度的计算规则,通过比较两两间演进路径相似性确定。
由图4可以得出,尽管从整体上看,在同等可预测率下,基于Pearson相关性方法发现的股票关联能够更好地运用关联股票数据预测给定股票的价格变化趋势,但运用本文提出的基于事件关联的方法,在可预测率为0.64时预测10、30 d的股价趋势变化,以及在可预测率为0.69时预测30 d的股价趋势变化效果相对更好。因此,为保证用于预测的股票关联关系可靠性,在较低的股票可预测率下,面对有限数量的股票间关联关系,利用关联股票数据预测给定股票的价格变化趋势时,我们的方法比利用Pearson相关性的方法有更好的预测准确率。
5 总结
本文提出一种更具语言环境普适性、以发现事件基本关联关系为目的的金融事件关联网络构建思路。通过构建这种网络,可以从中发现一般化的事件关联关系,并观察到一些规律:
1)构建网络的规模与文本相似度阈值的设置相关。文本相似度阈值设置越低,整个网络的连通分支集中度就越高,即事件变得越来越抽象,最终会体现为几个高度抽象事件之间的关联;
2)随着文本相似度阈值的降低,整个网络的规模会先增加后减小,网络连通分支的数量会一直减少,整个网络的连接会更加紧密,越来越多经抽象处理的事件会产生关联关系。
本文所提出的网络构建方法,可以挖掘事件的关联关系和演进路径,帮助对于社会热点话题的理解;此外,利用这种事件关联网络,可以通过其内在事件-实体映射关系,发现指定的金融实体间的关联关系,并用于股票价格趋势预测,且相比于现有类似的基于股票价格发现实体关联、进行股票价格趋势预测的研究,本文所提出的实体关联关系挖掘方法,在较低可预测率,即已知有限数量股票间关联关系下,表现出更好的预测性能。
本文提出的网络构建和分析方法可以应用于多种情景:除可在与金融有关的领域开展应用外,还可以在其他领域开展类似应用。如利用本文提出的聚类方法,可对新闻事件抽象聚类并梳理得到事理逻辑,设计出一套财经新闻个性化推荐机制;而在其他的学科领域中,基于本文提出的方法,可以研究个体潜在关联对象。如在流行病学研究中,通过分析以文字形式记录的研究个体近期活动历史和过往社交历史,自动化挖掘并确定与该个体可能有关联的个体及关联密切程度。
在未来的研究中,将进一步围绕本文提出的方法,就基于金融事件关联的实体关联应用开展深入探讨。
猜你喜欢
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
智能计算机与应用(2020年4期)2020-08-31
当代陕西(2019年15期)2019-09-02
当代陕西(2019年5期)2019-03-21
21世纪商业评论(2018年3期)2018-03-02
学苑创造·A版(2018年11期)2018-02-01
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
