
自动确定聚类中心的比较密度峰值聚类算法
2021-03-18 13:45,2*
计算机应用 2021年3期
,2*
(1.山东科技大学测绘科学与工程学院,山东青岛 266590;2.山东省基础地理信息与数字化技术重点实验室(山东科技大学),山东青岛 266590)
0 引言
随着互联网、社交网络等技术的迅猛发展,数据源的多样化使数据量呈现爆炸式的增长,如何在大规模数据集中进行有效的分析并挖掘背后的价值已经成为了众多行业面临的首要问题。聚类分析[1]作为一种重要的数据挖掘技术,能够在无监督的条件下探索数据背后潜在的数据结构。依据聚类算法原理的不同,可将现有的聚类算法大致分为五类[2-3]:划分聚类[4]、层次聚类[5]、密度聚类[6]、网格聚类[7]以及模型聚类[8]。k-means 算法[9]是著名的划分聚类算法,具有操作简单、效率高等优点,但需要预先指定聚类个数;基于密度的噪声应用空间聚类(Density-Based Spatial Clustering of Application with Noise,DBSCAN)算法[10]对密度估计使用了索引结构,在处理大规模数据集时,有效地提高了聚类速度,但容易受邻域半径和阈值这两个参数的影响;Ankerst 等[11]提出了OPTICS(Ordering Points To Identify the Clustering Structure)算法,该算法解决了DBSCAN 对输入参数敏感的问题;Frey 等[12]提出了一种与k-means 同属于划分聚类的近邻传播(Affinity Propagation,AP)聚类算法,该算法不需要指定聚类个数,但所得的聚类个数受“preference”的影响。
2014 年6 月,Rodriguez 等[13]首次提出了密度峰值聚类(Density Peaks Clustering,DPC)算法。该算法简单高效、无须迭代,能够检测任意形状的类簇,且不需要提前设定类簇的数量,目前在图像分割、医学影像处理、社区发现[14-17]等领域具有潜在的应用价值。但该算法也存在缺陷:1)采用欧氏距离进行距离度量,无法正确反映复杂数据集的分布情况;2)对截断距离异常敏感,微小的变化就会导致不同的聚类结果;3)在确定聚类中心时需要根据决策图手动选择聚类中心,效率低下。为了解决DPC存在的问题,Du等[18]将流形学习的测地距离引入距离度量中,很好地解决了包含有多流行结构的数据处理问题;Mehmood 等[19]引入热扩散理论提出了一种从数据集中自动提取截断距离的方法,解决了DPC 算法中参数难以确定的问题;吴斌等[20]将基尼系数引入提出了一种自适应截断距离的方法,以获得最优的截断距离值;马春来等[21]根据簇中心权值的变化趋势来搜索“拐点”,并将“拐点”之前的点作为各簇中心,该算法避免了通过决策图判断簇中心的方法所带来的误差;丁志成等[22]利用KL(Kullback-Leibler)散度的差异性度量准则划分聚类中心点和非聚类中心点,根据散度排序图中的拐点实现对聚类中心的自动选取。
基于现有研究,本文设计了一种自动确定聚类中心的比较密度峰值聚类算法(Comparative density Peaks Clustering algorithm with Automatic determination of clustering center,ACPC)。ACPC根据决策图中数据的分布特征,采用了基于统计分析的二维区间估计方法来自动地识别决策图中聚类中心点。距离比较量主要集中对第二个假设的定量建模上,使聚类中心点在决策图中更明显地区别于非聚类中心点。实验结果说明,新算法有较高的准确性且适应性更好。
1 经典DPC算法
密度峰值聚类算法是一种可以发现非凸簇类的新型聚类算法。其核心思想建立在对聚类中心点的两个重要假设之上。
假设1 聚类中心的局部密度大于其周围邻近点的密度。
假设2 聚类中心与比其密度高的数据点的距离相对较远。
根据这两个设定,聚类中心应该是同时具备较大局部密度和较大相对距离。要确定数据集的聚类中心,对于每一个数据点,都需要计算两个属性:数据点i的局部密度pi和相对距离δi。令待聚类的数据集S={x1,x2,…,xn},IS={1,2,…,n}为相应的指标集。
定义1局部密度pi(Cut-off kernel 和Gaussian kernel 两种计算方式)。
Cut-off kernel:

其中函数:

式(1)中:i和j分别为第i个数据点、第j个数据点;rij=,rij为数据点xi和xj之间的欧氏距离;参数rc为截断距离,其作为密度峰值聚类算法的唯一参数,实际起着距离阈值的作用。
Gaussian kernel:

式(1)为数据集规模较大时数据i的局部密度计算方式;当数据集的规模较小,为减小截断距离的选择对算法的影响,DPC 算法采用高斯核函数来估计数据i的局部密度,如式(3)所示。
定义2相对距离δi:

计算pi和δi之后,密度峰值聚类算法通过构造决策图选择pi和δi都较大的数据点作为聚类中心。
图1(a)展示了原始数据点集的分布。图1(b)为该数据集的决策图,其包含每个数据点的局部密度pi和相对距离δi。从决策图中可以容易发现,灰色圆形点和菱形点标记的数据点为聚类中心点,因为这两个点同时具有较大的pi值和δi值。
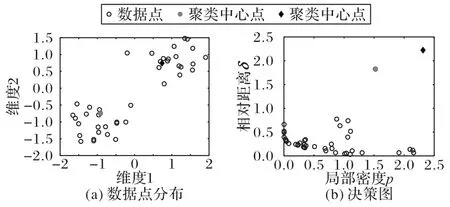
图1 原始数据点分布和决策图的实例Fig.1 Examples of original data point distribution and decision graph
在选定聚类中心后,密度峰值聚类算法按照密度从大到小的顺序将剩余数据点依次归入比它密度大且与其距离最近的数据点的类簇,仅一步就可以高效地完成数据点的分配。
2 自动确定聚类中心的比较密度峰值聚类算法
2.1 比较量
依据密度峰值聚类算法第二个假设的描述,即聚类中心与比其密度高的数据点的距离相对较远可知,聚类中心点的δi值一定相对较大。原算法对于“相对较大”的概念只是让用户在决策图的可视化分析中进行比较,然而决策图中不是所有的聚类中心点都能体现出来,并且有时聚类中心点与非聚类中心点在决策图中显示不够清晰。借鉴文献[23]思想,本文采用比较量d来替代δ,实现定量比较的方式来显示相对距离,从而凸显聚类中心。
本文用τi作为数据点i与其密度更低点的最短距离,具体定义如下:

式(5)中当数据点i的局部密度为最小值时,它的τi值为δi值。τi值的定义作为与δi值正好相反的一个距离属性,为了描述其差值,用d来表示,其定义如下:

di为δi与τi的比较数量,有助于识别潜在的聚类中心。如图2(b)所示,当di值较大时,表明该数据点距离低密度区域的数据点很近而距离更高密度的数据点更远,符合聚类中心的选择特征。当di的值在零附近,表明该数据点既有密度更大的数据点也有密度更小的点,说明该数据点处于某个类簇中。若di远小于零,该数据点距离密度高的数据点较近而距离密度低的点较远,这类点为类簇边缘点。
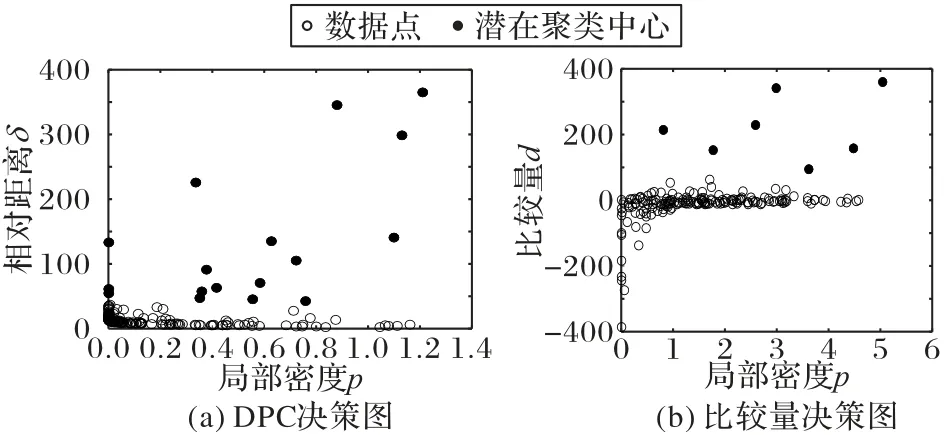
图2 决策图对比Fig.2 Decision diagram comparison
2.2 基于统计分析的聚类中心点自动识别
DPC 算法在选取聚类中心时设计了一种启发式方法,在决策图上手动选择同时具备高密度和高距离的数据点作为聚类中心。这种方法虽然可以人为地在决策图上可视化地识别聚类中心,但只是在数据集分布清晰的条件下能有较好的识别效果,当处理大规模数据并且具有复杂的决策图时,人为的方式就难以保证聚类结果较高的准确性。针对该问题,借鉴文献[24]思想,本文采用特定统计量来实现聚类中心点的自动识别。
根据数据点在决策图中的分布特征,用高斯核函数来估计特定密度值pi处的概率密度ρy(pi,y),其定义如下:
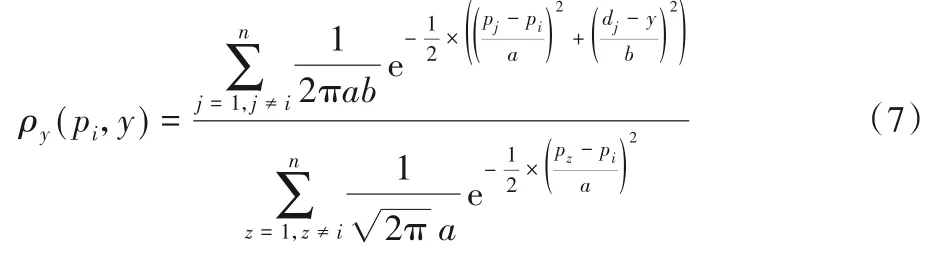
其中:y表示特定密度值pi处可能的距离值。数值n为数据点的总数,参数a、b为核宽度值。分母是一个归一化的因子,可以确保(pi,y)=1。核宽度a和b作为概率密度估计重要的参数,通过pi和di的标准差估计得到,rp和rd设置为0.5,具体定义如下:

根据式(8)得到的概率密度估计,然后在特定密度值pi对最小距离值y的期望值和方差值进行估计,其定义如下:
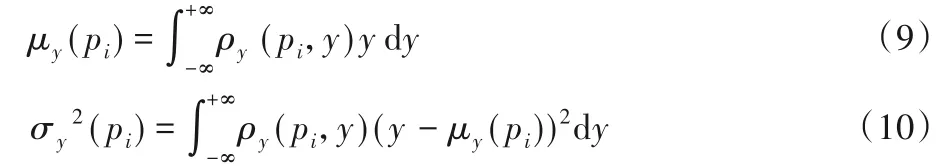
通过化简可以得到:
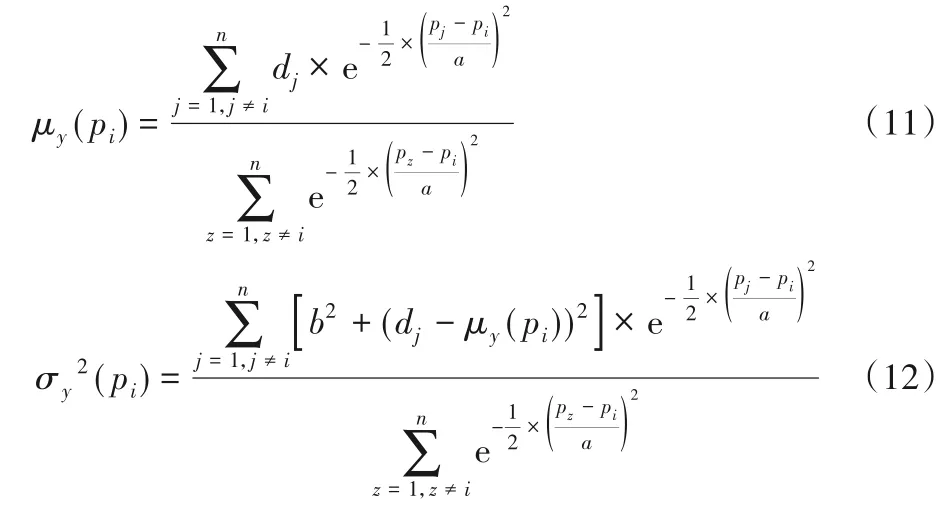
式(11)、(12)中,n为数据点总数,pi表示数据点i的局部密度,参数a、b表示核宽度值,dj表示比较量。
完成在特定密度值pi处最小距离y的期望值和方差值的计算后,利用以下公式进行聚类中心的自动化识别:

根据式(13)可知:μy(pi)表示y的期望值,σy(pi)表示y的标准差。如果数据点的最小距离值di>THd(pi),它将会自动识别为聚类中心点。为了便于了解自动化识别聚类中心算法,图3 进行了直观描述,其中黑色圆形点为聚类中心,菱形为期望值,正方形为标准差。
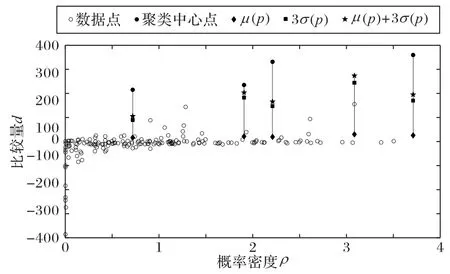
图3 用于聚类中心点自动识别的统计量Fig.3 Statistics for automatic recognition of clustering center points
2.3 算法的主要步骤描述
ACPC算法的具体实现步骤如下:

2.4 时间复杂度分析
ACPC 算法的时间复杂度主要有4部分[25]构成:1)计算相似度矩阵,其时间复杂度为O(n2);2)求每个数据点的比较量d,其中距离δ的时间复杂度为O(n2),对比量τ的时间复杂度为O(n),比较量d时间复杂度为O(n2),所以计算每个数据点的比较量d的整体时间复杂度为O(n2);3)对特定密度值pi处最小距离值y的期望值和方差值估计,时间复杂度为O(n2);4)分配样本的时间复杂度与DPC 中相应操作的时间复杂度相同,为O(n2)。因此,ACPC算法的整体时间复杂度为O(n2)。
3 实验仿真及分析
选用人工数据集和UCI(University of California lrvine)[26]公开数据进行实验验证,数据集的详细信息如表1 所示,并将其与DPC、基于KL 散度的密度峰值聚类算法(Density Peaks Clustering based on Kullback-Leibler divergence,KLDPC)、改进的快速搜索与发现密度峰值聚类(Clustering by Fast Search and Find of Density Peaks,CFSFDP)、APC(density-based Clustering using Automatic density Peaks detection)、自动确定聚类中心的快速搜索和发现密度峰值的聚类算法(AUTOmatic determination of clustering center for CFSFDP,AUTO-CFSFDP)算法[27]进行比较,各算法在不同数据集上的参数取值如表2 所示。实验开发环境Matlab2014a,硬件条件为:Intel Core i5-3470 CPU,主频3.20 GHz,内存4.00 GB。
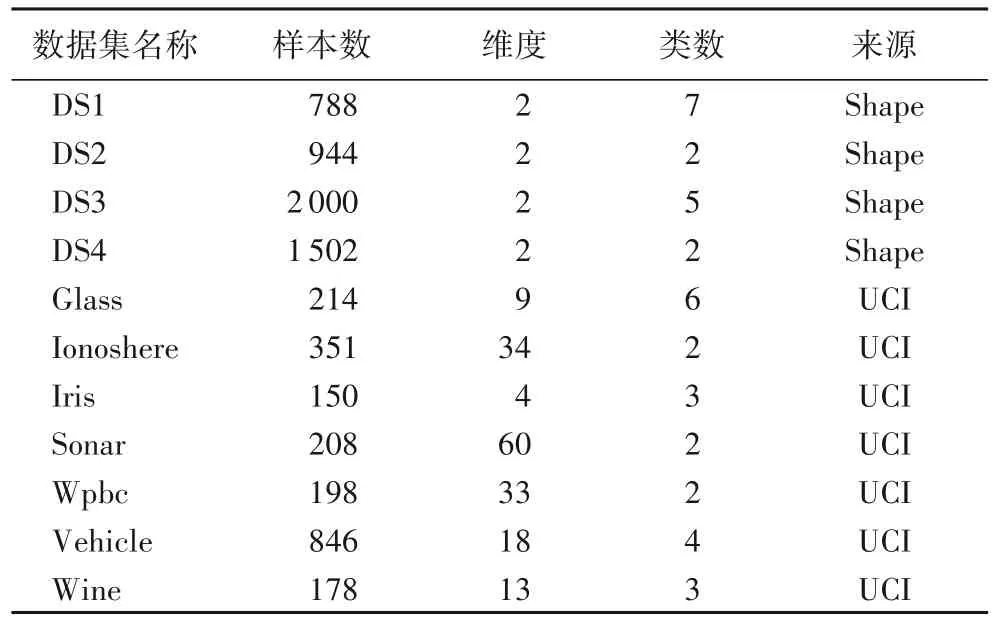
表1 数据集信息Tab.1 Information of datasets
3.1 人工数据集的实验结果分析
本文采用4 个人工数据集验证ACPC 的聚类效果,图4 为实验数据的二维图形展示,图5~8 为各算法分别对DS1~DS4的聚类结果。
图5 为DS1 在五种算法中得到的聚类结果。DPC 算法、APC算法、ACPC算法都可以准确确定聚类个数且聚类效果都很好。KLDPC 算法、改进的CFSFDP 算法、AUTO-CFSFDP 算法不能正确聚类,错误地将多个球形数据聚为一个类簇。
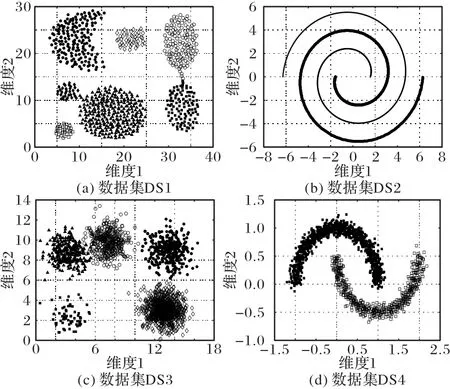
图4 实验数据的二维图形展示Fig.4 2D shapes of experimental data
图6 为DS2 在五种算法中得到的聚类结果。DPC 算法、KLDPC 算法、APC 算法、AUTO-CFSFDP 算法、ACPC 算法对数据集都有很好的聚类效果。改进的CFSFDP 算法对环形数据集聚类结果不理想,错误地将两个类簇的数据点聚类成一类。
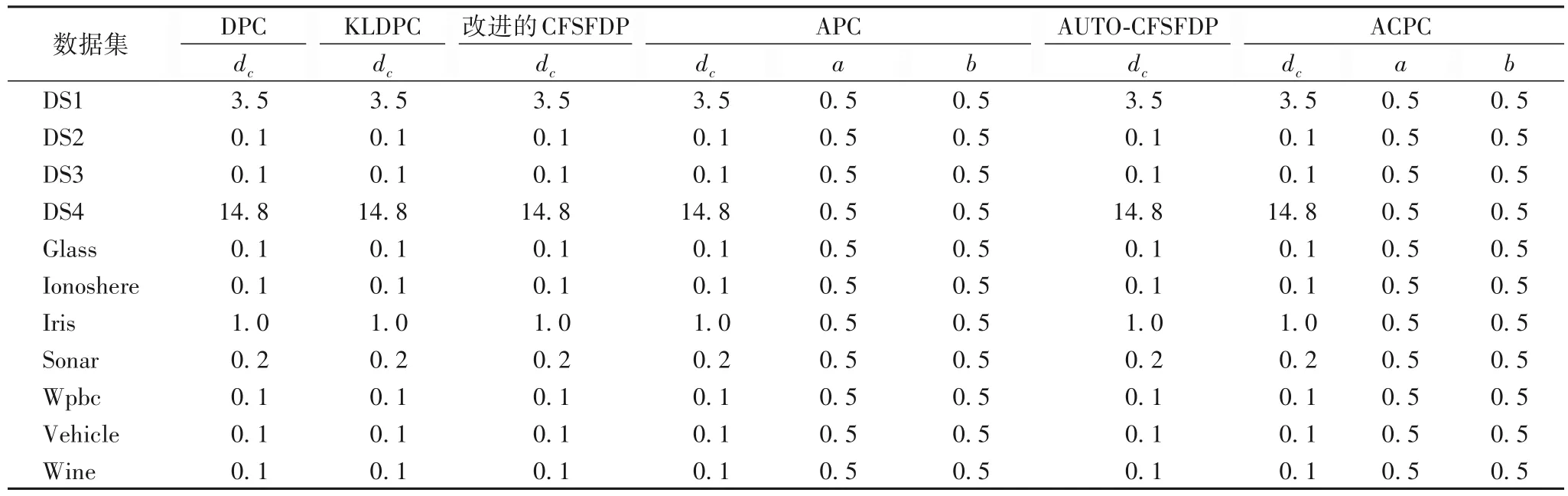
表2 各算法在11个数据集上的参数取值Tab.2 Parameters of different algorithms on 11 datasets
图7 为DS3 在五种算法中得到的聚类结果。DPC 算法、改进的CFSFDP 算法、ACPC 算法能准确确定聚类个数,但在两个离得近的球形数据上没能正确分配。KLDPC 算法得不到数据集聚类中心点的准确个数,将五个类簇划分为两个类簇。APC 算法错误地将一个簇类分成多个类簇。AUTOCFSFDP算法不能正确确定聚类个数,错误地将数据密集的类簇识别为多个类簇。
图8 为DS4 在五种算法中得到的聚类结果。ACPC 算法对DS2 简单流形数据能很好聚类,对于DS4 数据错误地将一类聚成两类。DPC 算法、KLDPC 算法、改进的CFSFDP 算法、APC算法、AUTO-CFSFDP算法在聚类效果上很不理想。
3.2 UCI数据集的实验结果分析
为了进一步验证ACPC 算法的性能,采用准确率(Accuracy,ACC)与标准互信息(Normalized Mutual Information,NMI)两类聚类指标对本文算法和现有算法进行了性能对比,加粗的数据为数据的最优聚类结果。表3 为聚类结果的性能对比。
已知真实类划分U={U1,U2,…,UT},V={V1,V2,…,VT}为聚类结果。
定义3准确率(ACC):

其中,ncorrect代表分类正确的记录个数,ntatol代表全部测试数据的个数。当预测结果与真实结果完全相符时准确率为1,两者越不相符准确率越低。
定义4标准互信息(NMI):
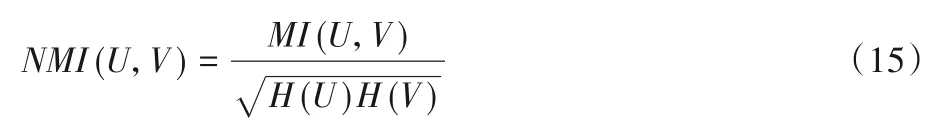
其中:H(U)和H(V)是U和V两种分布的熵,MI(U,V)是U与V之间的互信息,NMI 取值范围为[0,1],值越大意味着聚类结果与真实情况越吻合。每一部分的计算见文献[28]。
由表3 可知,ACPC 算法在准确率上,除了在Sonar 数据集上聚类效果差一些,在其他数据集上都达到了最优。在标准互信息上,ACPC在Iris和Wine数据集上要优于其他算法,在其他数据集上略差一点。综合这两种聚类指标来看,ACPC算法优于DPC、KLDPC、改进的CFSFDP、APC、AUTO-CFSFDP算法。
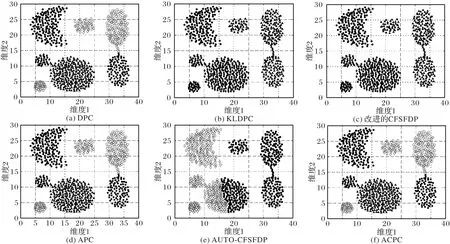
图5 五种算法在DS1数据集上的聚类结果Fig.5 Clustering results of five algorithms on DS1 dataset
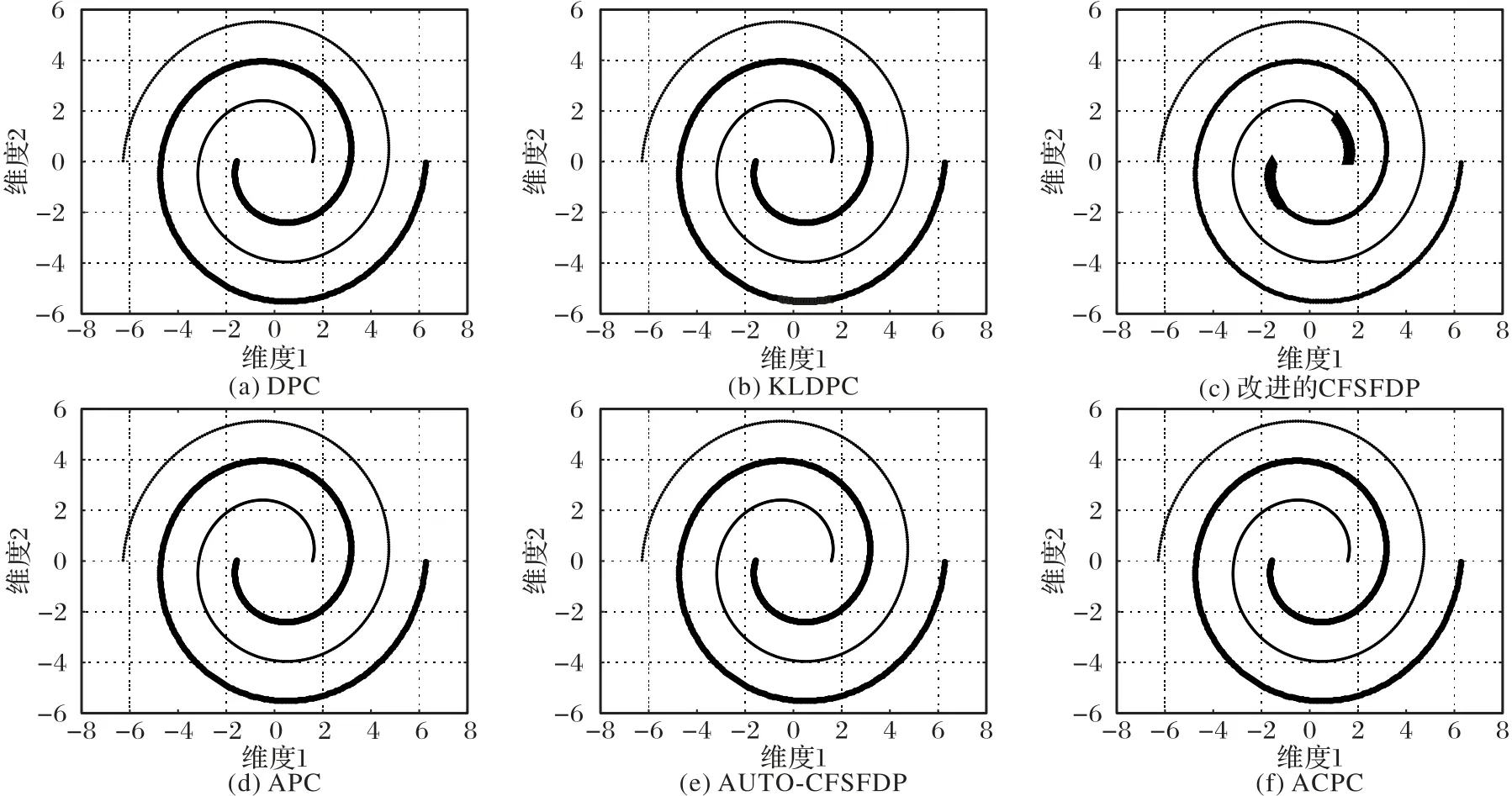
图6 五种算法在DS2数据集上的聚类结果Fig.6 Clustering results of five algorithms on DS2 dataset
4 结语
针对DPC 需要手动选取聚类中心,以及在处理密度变化较大的数据集时生成的决策图聚类中心和非聚类中心不够清晰的问题,实现了一种无须人工交互选择聚类中心的比较密度峰值聚类算法。该算法通过统计分析的二维区间估计方法实现对聚类中心的自动选取,同时采用距离的比较量di来代替原算法的δi,使潜在的聚类中心在决策图中更加突出。通过对人工和UCI 数据集的实验验证,并与其他算法的对比分析,本文算法不仅能够自动选取聚类中心,实现了聚类过程的自动化,并且具有更好的准确性以及适用性。如何自动地确定最佳的截断距离以及将DPC 算法应用于实际问题将是下一步的研究重点。
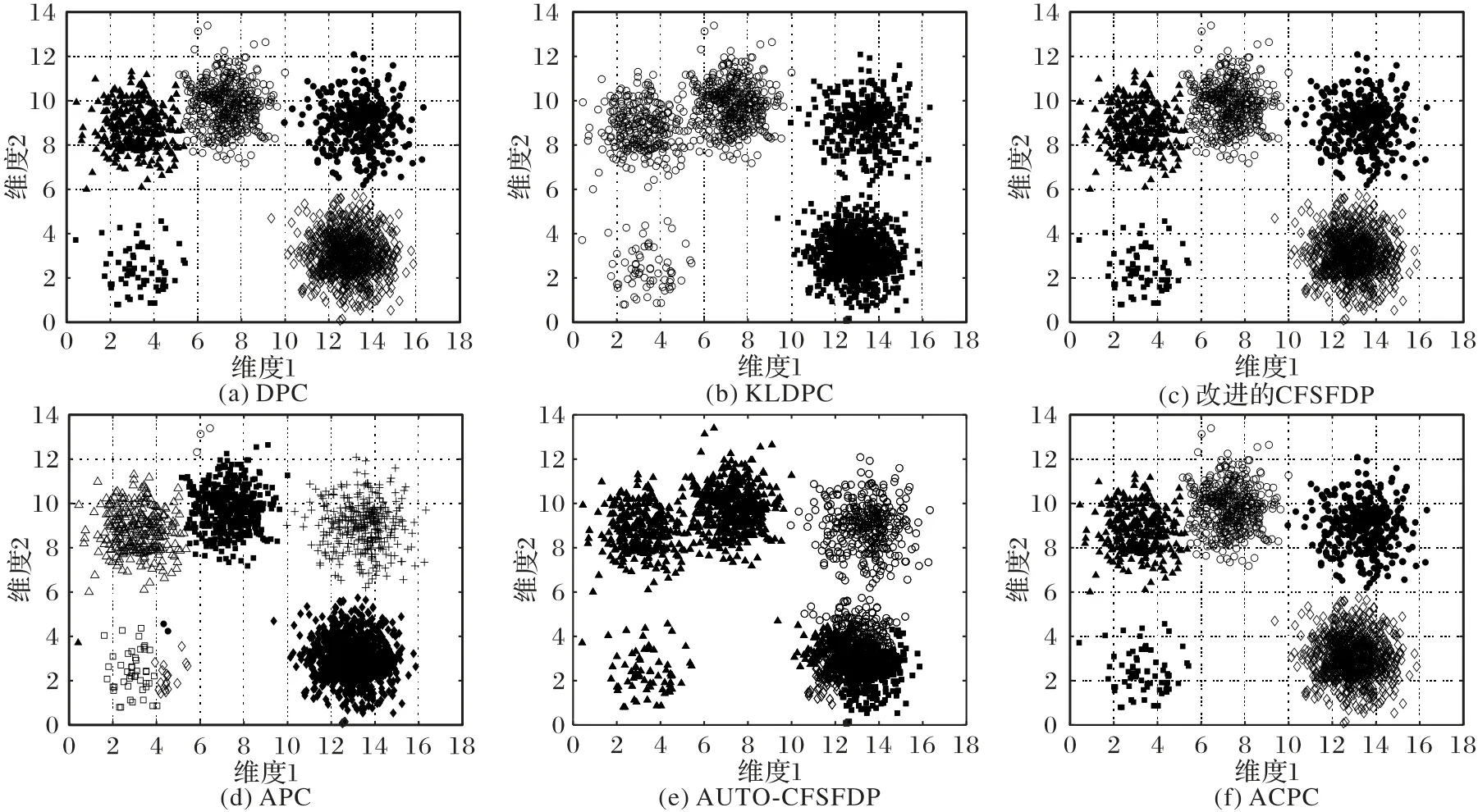
图7 五种算法在DS3数据集上的聚类结果Fig.7 Clustering results of five algorithms on DS3 dataset
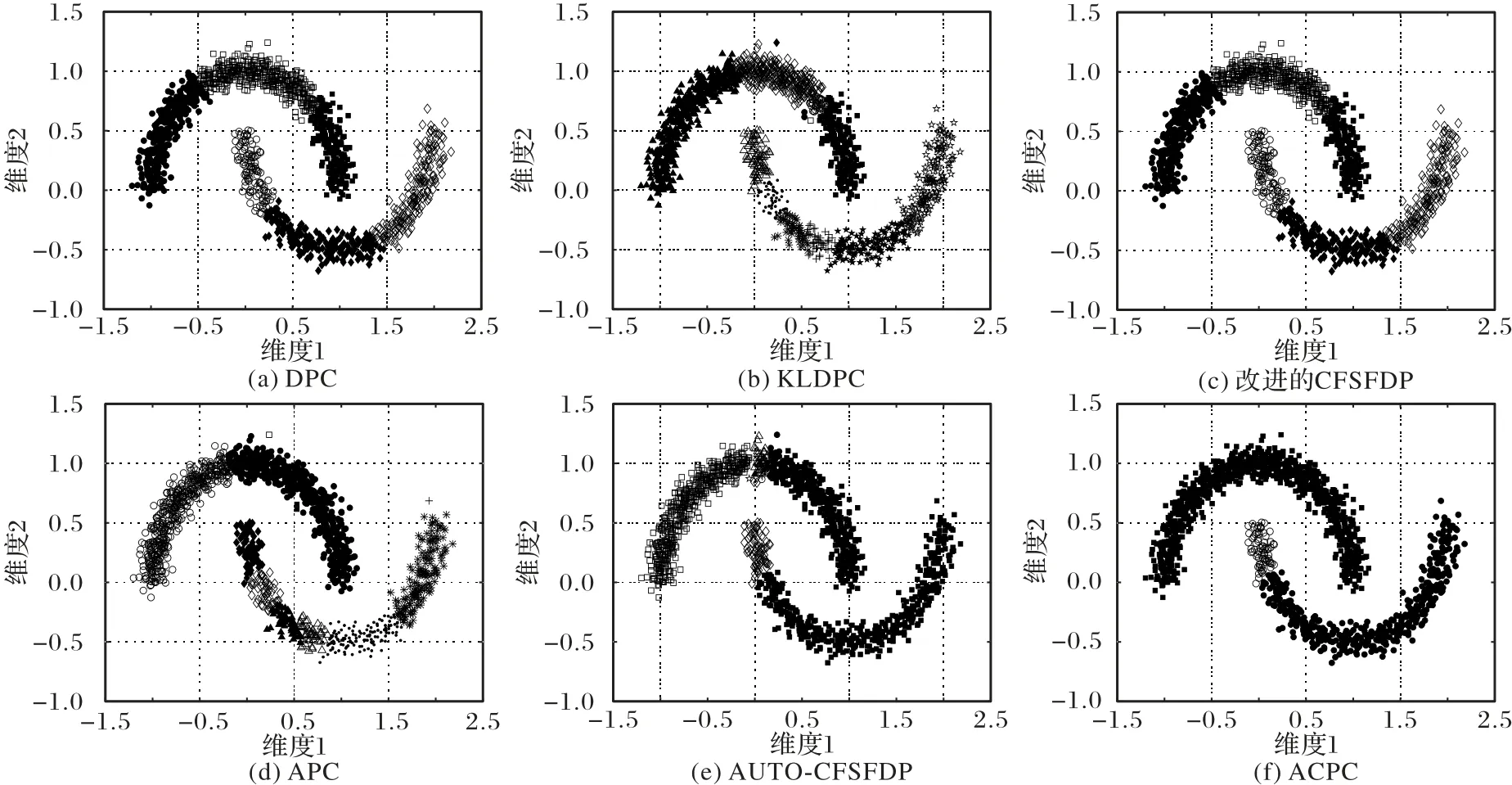
图8 五种算法在DS4数据集上的聚类结果Fig.8 Clustering results of five algorithms on DS4 dataset
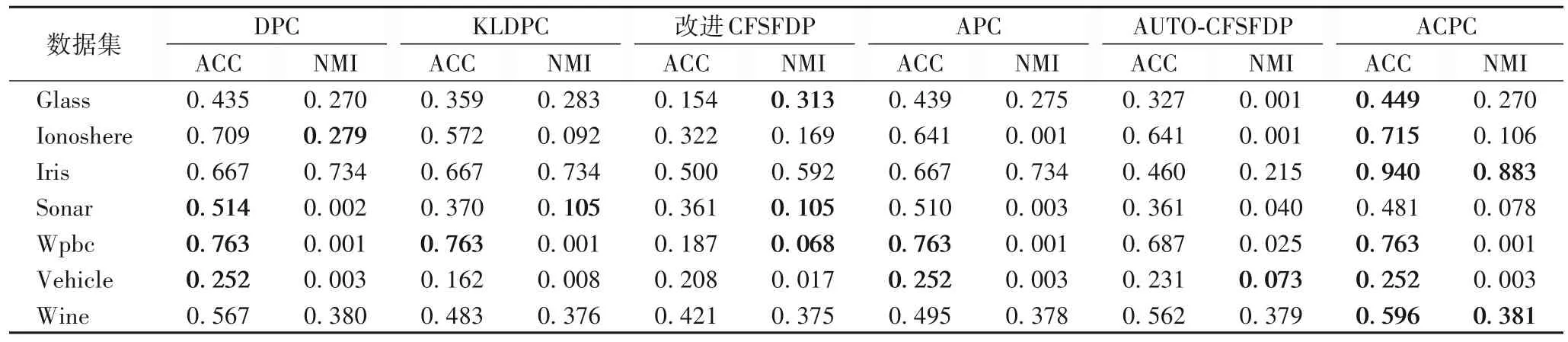
表3 聚类结果对比Tab.3 Comparisin of clustering results
猜你喜欢
中国畜牧杂志(2022年10期)2022-10-12
北京大学学报(自然科学版)(2022年4期)2022-08-18
社会科学战线(2022年2期)2022-03-16
电脑报(2020年12期)2020-06-30
现代计算机(2020年12期)2020-06-08
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
电脑报(2019年4期)2019-09-10
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
新课程·小学(2019年1期)2019-03-18
大众摄影(2015年9期)2015-09-06
