
融合多特征的分段卷积神经网络对象级情感分类方法
2021-03-17 07:48:54曾碧卿徐如阳韩旭丽程良伦
中文信息学报 2021年2期
周 武,曾碧卿,徐如阳,杨 恒,韩旭丽,程良伦
(1. 华南师范大学 计算机学院,广东 广州510631;2. 华南师范大学 软件学院,广东 佛山 528225;3. 广东省信息物理融合系统重点实验室,广东 广州 510006)
0 引言
情感分类是自然语言处理领域中一个常见的任务,旨在挖掘人们在文本中所表达观点情感倾向的类别[1]。主要研究集中在对篇章级别、句子级别和对象级别的情感分类任务上[2]。其中,对象级情感分类是一种相对比较细粒度的分类问题,旨在判断句子中对某个特定对象的情感类别。例如,“这台笔记本电脑的功能很强大,但价格太高了!”,该任务需要针对对象 “功能”判断正向的情感类别,以及针对对象 “价格”判断负向的情感类别。
基于深度学习的方法能够自动提取文本的语义特征,避免了人工提取特征繁琐的过程,因此该方法广泛应用于自然语言处理的各个研究领域,如词性标注[3]、问答系统[4]、机器翻译[5]等。在对象级情感分类问题的研究中,以往的方法大多利用长短时记忆网络(long short-term memory network,LSTM)具有捕捉序列特征的能力或者在LSTM的基础上融入注意力机制(attention mechanism)来对分类任务进行建模。其中,Tang 等人[6]提出TD-LSTM模型,该模型使用预训练词向量表示单词,根据对象在句子中的位置,利用LSTM提取对象的上下文特征作为最终的句子表示。Wang等人[7]提出ATAE-LSTM模型,其认为不同的词将会对分类的结果产生不同程度的影响,作者在LSTM的基础上引入注意力机制计算每一个词的注意力权重,为句子中对情感极性分类起到重要作用的形容词、词组等分配较大的权重。
有研究指出,卷积神经网络(convolutional neural networks,CNN)和LSTM在文本分类任务上效果基本接近[8],但LSTM在进行序列建模时具有时间依赖性,需要训练较长的时间,而 CNN结构相对简单且可并行化,因此在CNN的基础上,梁等人[9]提出一种基于词向量、词性和位置的多注意力机制卷积神经网络模型CATT-CNN来识别不同对象的情感极性。Xue等人[10]提出一种基于门控机制的卷积神经网络模型GCAE,该门控机制可独立工作且能根据给定的对象有选择地输出情感特征,因此模型结构更加简单且训练快速。
就人理解的角度而言,在判断某个对象的情感极性时,对象的上下文会对判断产生很大的影响。但在现有以CNN为基础的研究方法中,大多并未考虑到由对象所划分出的上下文对分类效果的影响,在池化层采用最大池化(max-pooling)操作提取句子特征,因此无法得到更细粒度的上下文特征。针对该问题,本文提出一种融合多特征的分段卷积神经网络模型,根据对象将句子划分为包含上下文的两个部分,并在池化层分别对这两个部分进行最大池化操作,即通过分段的方式提取包含对象上下文的特征。此外,本文还充分考虑到有利于情感分类的多个辅助特征,将词的相对位置、词性以及词在情感词典中的情感得分融入模型,并通过卷积操作为每个词计算注意力得分,在SemEval 2014数据集和Twitter数据集的实验中,结果表明,本文提出的模型能够有效地判别句子中对象的情感极性。
本文的主要贡献总结如下:
(1) 提出了一种融合多特征的分段卷积神经网络模型,模型根据对象将句子划分为包含上下文的两个部分,并在模型的池化层采用分段最大池化操作,有效地提取包含对象上下文信息的细粒度特征;
(2) 利用词的相对位置、词性以及词在情感词典中的情感得分作为辅助特征嵌入到模型中,使模型能够学习到更加丰富且有利于情感分类的特征,同时使用卷积操作为每个词计算注意力得分,有效地为那些有利于分类的词分配更大的注意力权重;
(3) 在SemEval 2014数据集和Twitter数据集的实验中,对比基于传统机器学习、基于循环神经网络以及基于单一最大池化机制的卷积神经网络分类模型,本文提出的方法取得了更好的分类效果。
1 相关工作
1.1 对象级情感分类相关研究
近年来,在深度学习领域,学者们利用LSTM和CNN具有自动提取文本的语义特征的能力,避免了传统机器学习算法人工提取特征的繁琐过程,对分类任务进行有效的建模。其中,Tang 等人[6]利用LSTM提取对象的上下文特征作为句子表示,提出对象依赖的分类模型TD-LSTM。Wang等人[7]提出一种基于注意力机制的LSTM模型ATAE-LSTM,该模型利用注意力机制为句子中的每个词计算注意力权重,对词向量加权求和以表示句子,取得了较TD-LSTM更好的分类效果。在CNN的基础上,梁等人[9]根据词向量、词性和位置信息,提出一种基于多注意力的卷积神经网络模型CATT-CNN来识别不同对象的情感极性。Xue等人[10]提出GCAE模型,该模型在CNN上引入一种能够独立工作的门控机制,其能够根据给定的对象有选择地输出情感特征,使分类更加快速和准确。
1.2 辅助特征
Matsumoto等人[11]在带情感标注的日语和英语语料库上,提出了一种估计句子中情感表达的方法,该方法充分利用词性和词之间的位置特征,能更好地识别出情感词或者短语。陈等人[12]利用外部情感词典资源,在句子中提取和情感表达相关的序列片段,凭借词语本身具有的属性特征来构建词向量以作为CNN的输入之一,在其研究领域数据集上的情感分类效果优于未引入词典资源的CNN模型。显然,词性、词的位置信息以及外部情感词典的运用,在一定程度上对情感分类问题发挥了积极影响。
1.3 分段卷积神经网络
在知识图谱关系抽取领域的研究中,要对两个给定实体之间的关系进行分类。Zeng等人[13]认为句子本质上可由给定的两个实体划分成3个部分,为了获取两个实体之间更加丰富的语义特征,作者设计了一个如图1所示的分段卷积神经网络模型。其中,两个实体在Word Embedding层用深黑色标识,Convolution层使用3个不同的过滤器提取局部n-gram特征,Pooling层采用分段最大池化操作,返回每个分段中的最大值,而不是单个句子的最大值,与传统最大池化方法相比,该方法取得了更好的分类效果。类似地,在对象级情感分类任务中,句子可由对象划分成上下两个部分,其中包含了对象的上下文信息,若使用分段卷积神经网络对上下文进行建模,采取分段最大池化策略,将得到更加细粒度的对象上下文特征。

图1 分段卷积神经网络[13]
2 融合多特征的分段卷积神经网络模型
考虑到由对象所划分上下文的重要性,本文使用分段卷积神经网络对上下文进行建模。图2为本文提出的MP-CNN模型的网络结构,模型主要分为五个部分: 词的多特征向量表示、卷积层、分段池化层、特征连接层以及softmax层。以下将对这些部分以及注意力计算方式进行详细说明。

图2 MP-CNN网络结构图
2.1 词的多特征向量表示

xi=Weei
(1)
Si=Wsei
(2)
Pi=WPei
(3)
位置特征嵌入在对象级情感分类任务中,距离对象越近的词越有可能为描述对象的词,其所在的位置也就越重要。如图3所示,一般取词与对象的相对位置作为位置特征,但是该方法使情感词“horrible”相对于对象的距离较非情感词“was”和“so”要远。

图3 无位置重排
针对该问题,本文提出一种位置重排算法对位置进行重新排序,算法表示如下:
输出: 重排后的特征向量(l′1,l′2,…,l′n)。
(1) 根据词的相对位置及其情感得分计算位置得分向量score,如式(4)所示。
(4)
其中,scorei为第i个词对应的位置得分,由softmax函数对该词的原位置值以及情感得分进行归一化,两部分相加得到。该操作相当于在考虑原位置的基础上引入了情感得分因素,使情感词能够分配到更大的位置得分。
(2) 根据位置得分计算新的位置值,如式(5)所示。
(5)
其中,top_k为输出scorei在所有位置得分当中排在第几位的函数,函数f值取-1表示词出现在对象的左边,取1表示词出现在对象的右边,取0则表示对象本身。

图4 有位置重排
Li=WLei
(6)
新兴市场一旦被发现,短时期内将涌入众多参与者。因此,创业项目的致命痛点在于对于商品成本进行有效控制和延续话题热点。创业项目在校园阶段就应主动实现成本控制,尝试实现由销售端转向“生产+销售”的模式转变,从而实现经营的链式转化。同时,利用网络热点进行创业的项目尤其应注意目标群体审美意象与注意力的转移,及时更新商品,并重视对相关话题的炒作。由于创业公司主营业务将销售区域明确界定为大学城,在业务向大学城外拓展时,要格外注意运输成本的上升与外地市场改变。
2.2 卷积层
2.3 分段池化层
为了得到包含对象上下文更加细粒度的特征,本文将up和down两个部分卷积操作的结果分别做最大池化操作,即分段池化以得到包含上下文特征的结果zup和zdown,该过程表示如式(11)、式(12)所示。
2.4 注意力计算

其中,g(·)为sigmod函数,si即为句中第i个词的注意力得分,使用si对词向量进行加权得到新的词向量表示x′i,并对加权后的向量采取求和操作,如式(15)、式(16)所示。
(17)
其中,*为两个矩阵元素对应相乘相加操作,na为过滤器的数量,g(·)为tanh函数。
2.5 softmax层
设#nw为模型所用卷积过滤器的类型,其值指示一个特定长度的卷积过滤器,若模型中使用到3个不同长度的过滤器,则#nw的取值为[1,2,3]。将池化操作以及上下两个部分单词注意力计算结果zatt_up、zatt_down进行串联,以丰富句子的特征表示,得到结果zout,将其交给softmax分类器输出情感分类的概率P,过程表示如式(18)、式(19)所示。
其中,“⊕”为向量连接操作,Wp和bp为权重参数和偏置参数。2.6 损失函数在模型反向传播过程中,本文采用基于Adam的mini-batch梯度下降法,通过最小化交叉熵来优化模型,交叉熵损失函数如式(20)所示。
(20)

3 实验
本文将在3个不同领域的对象级情感分类数据集上进行实验,并将实验结果与现有模型进行比较,验证了本文提出的模型具备良好的分类性能。其中,实验在如表1所示的环境配置下完成。

表1 实验环境配置
3.1 数据集
本文使用的数据集包括SemEval 2014提供的Restaurant和Laptop两个领域的用户评论,以及Twitter提供的用户推文数据集。数据中包含对象词或对象词组,对象的情感极性被分为消极、中性以及积极。数据集被划分为训练集和测试集,3个情感类别在各数据集上的数量统计结果如表2所示。
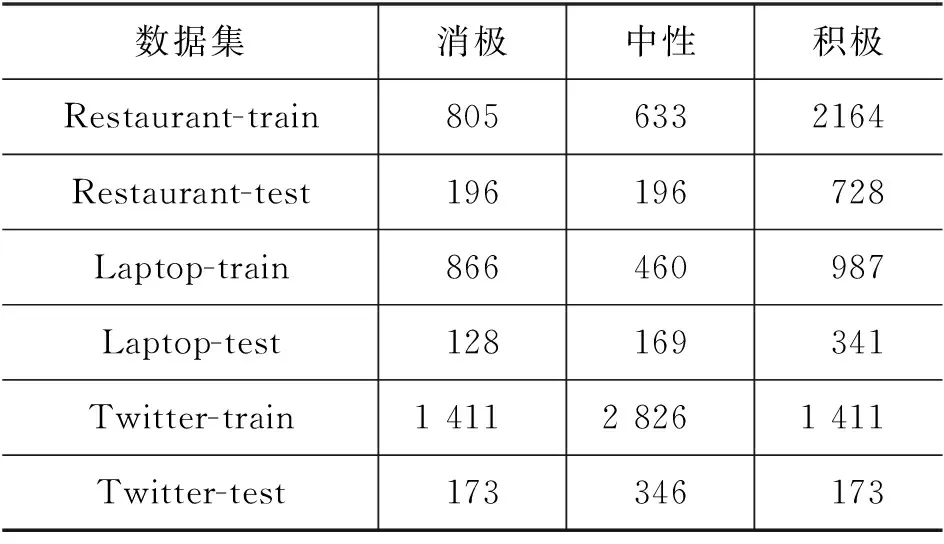
表2 实验数据集情感类别统计
3.2 参数设置
在模型的输入层,本文使用GloVe预训练英文词向量作为模型的输入之一,维度d设置为300,对于未登录词,其词向量用0向量初始化,三个可训练特征矩阵使用均匀分布U(-1,1)随机初始化;在多特征嵌入当中,经过多次实验发现,嵌入维度对模型的影响不大,考虑到时间性能因素,本文将3个特征嵌入的维度m1、m2、m3统一设置为较低的50维;在卷积层和注意力计算过程中,模型均采用了多个卷积过滤器进行卷积计算;为防止模型过拟合,模型在池化层和优化损失函数过程中分别采用了dropout和L2正则化策略,其中模型的参数设置如表3所示。
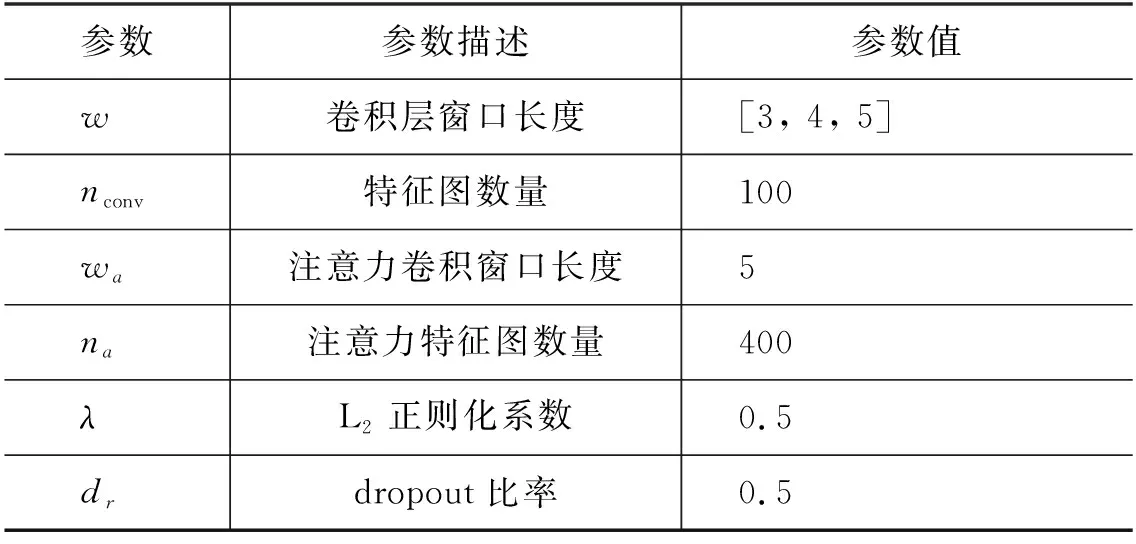
表3 参数设置
3.3 对比实验
实验结果将和以下10种不同类型的方法进行对比。
(1)SVM[20]: 一种基于可用特征的传统机器学习算法支持向量机(support vector machine,SVM)分类模型;
(2)SVM+lexicons: 在上述SVM的基础上引入了多个情感词典优化的模型;
(3)TD-LSTM[6]: 根据对象将句子划分成两个部分,利用LSTM提取上下文特征进行情感分类;
(4)ATAE-LSTM[7]: 将对象和其上下文表示连接到一起,在LSTM的基础上引入注意力机制计算每一个词的注意力权重而提出的情感分类模型;
(5)IAN[21]: 利用两个LSTM对上下文和对象进行建模,并用注意机力机制交互地学习上下文和对象中的关键特征表示,最后将得到的表示连接到一起进行情感分类;
(6)TextCNN[22]: 基于CNN提出的最基本的文本分类模型;
(7)Att-CNN[23]: 在CNN基础上添加多层注意力的文本分类模型;
(8)CATT-CNN[9]: 结合词向量、词性、位置信息计算注意力得分,提出的基于多注意力CNN对象级情感分类模型;
(9)GCAE[10]: 一种基于CNN和门控机制对象级情感分类模型。其中,门控机制Tanh-ReLU单元可以根据给定的对象选择性地输出情感特征;
(10)Mul-AT-CNN[24]: 一种利用多层卷积神经网络对上下文进行多次建模,并使用注意力机制显式学习情感中间表示,最后将所有特征集成到一起进行情感分类。
本文提出的模型如下:
(1)MP-CNN: 融合多特征的分段卷积神经网络模型,该模型能够根据对象在句子中的位置划分句子,在模型的池化层采用分段最大池化操作,提取包含对象上下文信息的细粒度特征。
(2)MP-CNN-2: 受CNN在图像处理中应用的启发,本文认为更深层的CNN能够学习到更多有利于分类的特征,实验发现2层CNN效果最优,即MP-CNN-2。
3.4 实验结果
本文提出的两个模型MP-CNN和MP-CNN-2在3个数据集上都取得了不错的分类准确率,实验结果如表4所示。

表4 不同模型分类准确率(%)
首先,对比基于传统机器学习算法的两个模型SVM和SVM+lexicons,引入情感词典的SVM+lexicons模型较SVM模型在Laptop数据集上效果提升了6.88%,这进一步说明了引入辅助特征的有效性。因为深度学习模型具有强大自动提取特征的能力,并且又添加了更多的辅助特征,所以与需要手工设计特征且只引入了情感词典的SVM+lexicons模型相比,本文表现较好的模型MP-CNN-2取得了更好的实验结果,在Restaurant和Laptop数据集上效果分别提升了1.09%和4.07%。
其次,对比基于LSTM的模型。其中,添加注意力机制的ATAE-LSTM和IAN模型与只考虑对象上下文信息的TD-LSTM模型相比,效果都有一定程度的提升,这说明注意力机制在对象级情感分类当中起到一定程度上的改进作用,但这3种方法都没有考虑额外的辅助特征,而引入3个辅助特征的MP-CNN-2模型具有更好的特征学习能力。因此,分类效果与基于LSTM的模型中表现较好的IAN模型相比,在Restaurant和Laptop数据集上的分类准确率分别提升了2.65%和2.46%。
最后,对比基于CNN的分类模型。较最基本的模型textCNN来说,因未考虑对象的上下文且未引入任何辅助特征,捕获特征的能力不足,所以分类结果较差,这也说明了本文分段提取对象上下文特征的有效性。Att-CNN、CATT-CNN以及本文提出的两个模型都分别在CNN模型的基础上使用了注意力机制,较未使用注意力机制的TextCNN模型分类效果都有所提高,所以将注意力机制应用于CNN上亦可改进分类效果,但这两个模型在池化层都采用最大池化操作,并未考虑更细粒度的上下文特征,所以本文提出的两个模型表现均优于这两个模型。和GCAE模型相比,MP-CNN-2在Restaurant和Laptop数据集上分别取得了1.58%和5.42%的提升,说明上下文特征结合多个辅助特征要比单一的门控机制表现力强; Mul-AT-CNN模型和本文提出的两个模型均考虑了对象的上下文信息,但建模方式不同,由于本文考虑了多个辅助特征,使模型更具特征表现力,所以在Restaurant和Twitter数据集上表示更为出色,分别提高了1.79%和1.56%。而Mul-AT-CNN在Laptop数据集上领先0.83%,这反映了该模型的上下文建模方式在Laptop数据集上有着更好的效果,但却不能泛化到其他数据集上。
3.5 实验分析
为验证本文方法的有效性,下面将针对位置重排算法、注意力机制以及辅助特征设计分析实验,描述如下。
位置重排算法验证实验在进行位置嵌入时,将模型设置为有位置重排和无位置重排进行对比实验,实验结果如图5(a)和图5(b)所示。其中with表示有位置重排,without表示无位置重排,从图的对比中可以看出,本文提出的两个模型MP-CNN和MP-CNN-2,使用位置重排模型的分类效果在所有数据集上均优于未使用该算法的模型,这是因为重排后的位置使得情感词处在更重要的位置上,因此模型学习到了更有利于情感分类的位置特征,所以位置重排算法在一定程度上能够改进模型的分类效果。

图5 辅助特征验证实验结果
注意力值可视化实验为验证注意力机制能够关注到与描述对象有关的词,我们在数据集上分别随机挑选两个句子进行测试,输出各个词的注意力得分,并对其进行可视化,结果如图6所示,对于第一个句子,描述对象“bread”的单词“is”“top”“notch”以及第二个句子描述对象“hardware”的单词“was”“slow”“locked”等都被赋予了较大的权重,这说明注意力机制在一定程度上发挥积极作用。

图6 注意力可视化
辅助特征验证实验为验证在本文提出的模型上添加辅助特征的有效性,实验首先将所有辅助特征从模型中剔除,然后再逐个添加,实验结果如图7所示。其中,“0”表示剔除所有辅助特征;“1”表示只包含一个辅助特征,选取实验中3个辅助特征得到的最大准确率作为该实验的结果;“2” 表示包含两个特征,3个辅助特征共有3种不同的组合方式,亦选3种组合中取得的最大准确率作为该实验的结果;“3”为添加所有辅助特征。可见,随着特征的添加,分类的准确率在3个领域的数据集上都呈现上升趋势,这是因为随着辅助特征的增多,使模型能够提取到更多有利于情感分类的特征信息,因此特征表现力就越强,所以引入辅助特征能够改进模型的效果。
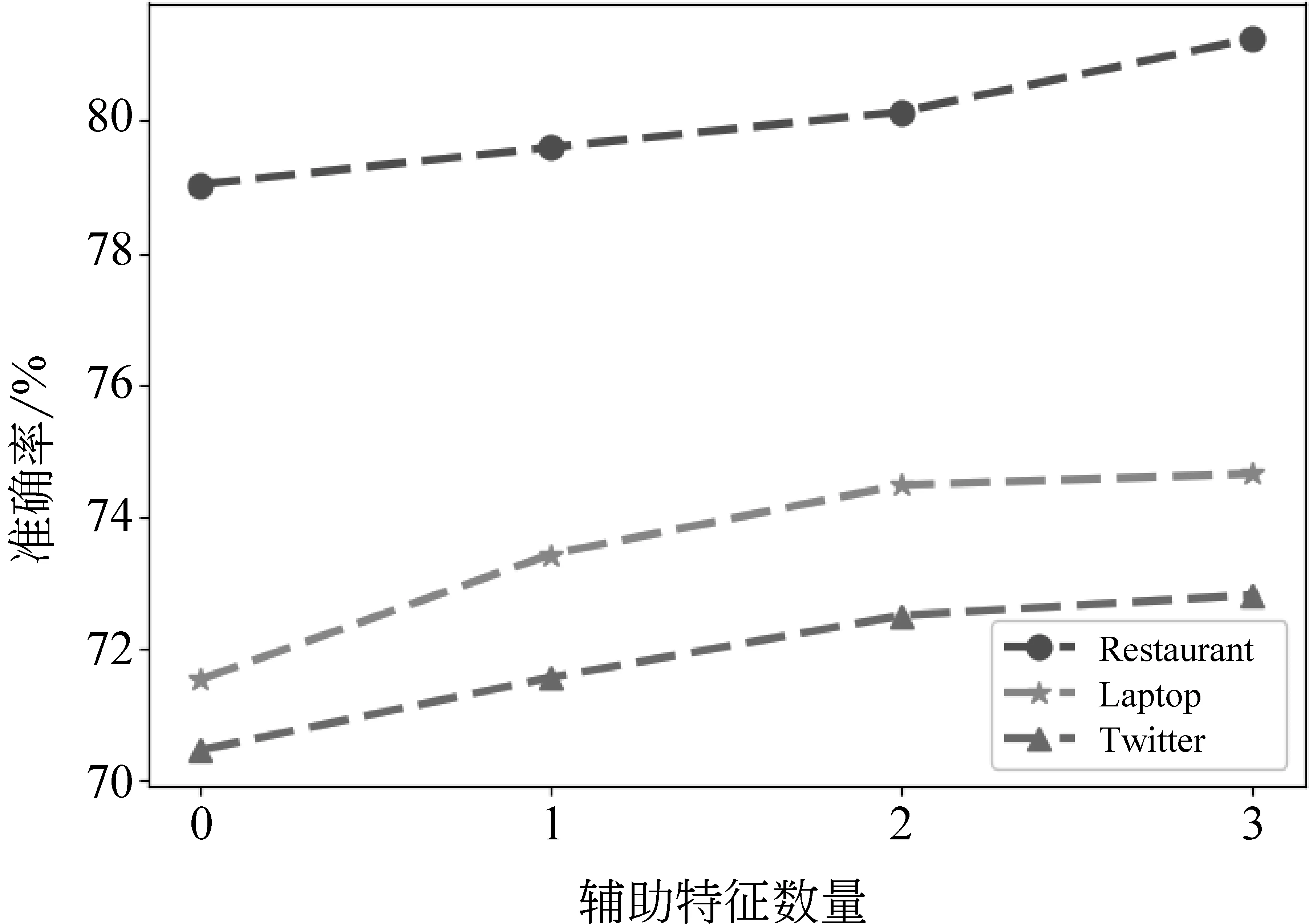
图7 辅助特征验证实验结果
4 总结和展望
本文提出了融合多特征的分段卷积神经网络模型MP-CNN和MP-CNN-2,考虑到由对象划分出句子上下文的重要性,选择分段最大池化策略提取更加细粒度的对象上下文特征。此外,根据情感分类的特点,引入多个辅助特征,将词的位置、词性以及词在情感词典中的情感得分特征融合进模型,增强了模型的特征表现力。最后模型采用卷积的方式计算词的注意力得分,帮助改善模型的分类效果。
虽然本文提出的两个模型在3个不同领域的对象级情感分类数据集上均取得了较好的分类结果,但多个辅助特征+注意力的句子表示方式是否可以泛化到其他更细粒度的情感分类领域仍然未知,下一步的工作重点将是验证该组合方式在更细粒度的分类任务上的有效性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
数学物理学报(2021年4期)2021-08-30 08:28:02
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
数学物理学报(2017年5期)2017-11-23 07:51:31
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
太空探索(2016年9期)2016-07-12 10:00:04
中国当代医药(2013年35期)2013-12-10 10:45:48
