
自然语言显式命题自动识别和解析方法
2021-03-17 08:04彭诗雅
中文信息学报 2021年2期
刘 璐,彭诗雅,玉 郴,于 东
(北京语言大学 信息科学学院,北京 100083)
0 引言
自然语言中存在大量命题,这些命题中大都包含文本中的关键信息。正确理解这些命题可以辅助自然语言理解,促进相关任务的发展,如文本摘要、阅读理解、文本推断等。命题和命题形式是形式逻辑的研究对象。在形式逻辑中,判断是对于思维对象有所肯定或否定的一种思维形式[1],命题是判断的语言表达[2]。命题是表达了对事物情况有所肯定或否定的陈述句,它蕴含了或真或假的思想。如果一个句子是命题,它的陈述就一定能区分真假,否则,它就不是命题[2]。自然语言中,大部分命题都是由逻辑联结词引导的,本文将这类命题称为显式命题。《形式逻辑》[2]一书对命题类型做了细致的划分,我们关注其中的四个类型的命题在自然语言文本中的表现,这四种类型分别是性质命题、联言命题、选言命题和假言命题。
自然语言中有逻辑联结词的句子不一定是显式命题,显式命题也往往包含阻碍理解的冗余信息。本文提出两个任务: 自然语言显式命题自动识别和命题关键成分解析。自然语言显式命题自动识别任务要求判断一个子句是否为命题,如表1中,S1不是命题,S2是命题;命题关键成分解析要求解析出支撑命题成立的关键成分,S2中的“子囊果是子囊壳的核菌纲真菌”和“归于球壳目”就是该命题的关键成分。我们基于百度百科(1)https://baike.baidu.com/语料为两个任务建立了大规模人工标注语料库。

表1 标注范例(“1”代表是命题,“0”代表不是命题)
显式命题自动识别任务可以转化为单句的二分类问题。我们将传统的统计学习方法支持向量机(support vector machine,SVM)[3]作为该任务的基线模型,构建双向长短期记忆网络(bi-directional long short-term memory,BiLSTM)[4]作为对照。此外,我们利用Tranformer的双向编码器表示(bidirectional encoder representation from transformers,BERT)[5]在本任务上微调作为分类模型之一。BERT作为一种新型的语言模型,能充分利用大量无监督数据将语言学知识隐含地引入特定任务中,在11个自然语言处理任务中达到目前最好的效果。BERT在文本分类上表现优越[5],适合作为显式命题自动识别任务的模型之一。
命题关键成分解析任务可以转化为序列标注问题。本文主要采用传统统计学习模型条件随机场(conditional random field,CRF)[6]作为该任务的基线模型。我们构建目前流行的序列标注模型BiLSTM-CRF(BiCRF)[7],进一步探索BiLSTM对于特征的选择能力。另外,我们构建BERT-BiLSTM-CRF(BBiCRF)用于该任务,以充分利用BERT在处理百科语料上的优势。
实验结果表明,BERT模型在显式命题自动识别任务上的正确率高达到74.95%,超过基线模型15.30%;BBiCRF模型在命题关键成分解析任务上的F值达到90.74%,超过基线模型17.69%。
本文结构如下: 第1节介绍国内外自然语言中命题的研究现状;第2节介绍本次实验涉及到的命题并逐一分析;第3节介绍数据标注工作,并分析标注结果;第4节和第5节在两项任务上分别设计模型进行实验,比较不同模型在数据集上的表现能力,同时对数据集的特点做出解释。最后一节对论文工作进行总结和展望。
1 相关工作
自然语言中的命题研究一直以来都受到各界学者的关注。国内关于形式逻辑的研究主要集中在逻辑学和语言学领域[8-10]。李先焜[11]定义了语言逻辑的概念,阐述了语言逻辑的地位,梳理了研究语言逻辑的方法,解释了语言逻辑的研究意义。周礼全[12]区分了正统逻辑和自然语言逻辑。龚启荣[13]强调了当代形式逻辑研究对人工智能发展的重要性,他认为当代形式逻辑是人工智能最合适的工具。高逢亮[8]从语义学、语法学、语用学和修辞学等不同领域展开研究,深入探讨了逻辑学和语言学之间的关系,肯定了逻辑学对于语言理解的重要性。
现有命题研究大多集中在哲学和语言学领域。在哲学领域,周文华[14]分析了现有的一些命题定义的特点,并给出了新的命题定义。他将命题定义为具有某种属性的对象。杨宏郝[15]阐述了命题和判断之间的关系,他提出判断无逻辑结构可言,只有作为语句的命题和作为语句模式的命题形式才有逻辑结构。在语言学领域,沈园[16]讨论了逻辑判断基本类型划分,说明逻辑判断是与语法、语用等各方面有着密切联系而又相对独立的一个范畴。李勤[9]从逻辑中判断的分类出发,对句子语义中的命题进行了分类。韩铁稳[17]认为逻辑常项是区分逻辑思维形式的标志,对逻辑常项的语言形式进行了汇总。黄士平[18]认为逻辑常项是逻辑形式中不变的部分,将表述逻辑常项的语言形式直接出现称为显性形式,将未直接出现称为隐性形式,并分析了逻辑常项的隐性形式。
以上研究是从语言学角度和哲学角度对形式逻辑以及命题的一些研究。在计算语言学领域,与命题直接相关的研究较少,部分研究关注篇章句间关系,这种关系也和语言逻辑相关。
张牧宇等人[19]总结了中文篇章及语义分析的特点,提出面向中文篇章句间关系的层次化语义关系体系,对句间关系类型进行详细描述,并在新闻语料上进行了标注。随后,张牧宇等人[20]对中文篇章句间关系识别任务进行初步探索,他们根据文本单元间是否存在篇章连接词将关系分为显式篇章句间关系和隐式篇章句间关系。
基于逻辑学和语言学对命题类型划分的研究成果,本文提出自然语言显式命题自动识别任务和命题关键成分解析任务,并基于百度百科语料为两个任务建立了大规模人工标注语料库。
2 命题及其关键成分研究
2.1 命题研究
在自然语言中,命题是表达了对事物情况有所肯定或否定的陈述句,它蕴含了真或假的思想。如果一个句子是命题,它的陈述就一定能区分真假,否则,它就不是命题[2]。例如:
T1: 所有声音都称之为音频。
T2: 正因为如此,使得它不但能够与世界的顶尖时尚风潮同步,而且更能体现亚洲女性的娇柔与美感。
T1是命题,T2不是命题。T2中代词“它”指代不明确,难以辨别真或假,因此该句不是命题。
根据一个命题本身是否包含有其他命题可把命题分为两类: 一类是本身不包含其他命题的简单命题,包括性质命题、关系命题;另一类是包含了其他命题的复合命题,包括联言命题、选言命题、假言命题和负命题等。本研究针对其中的性质命题、联言命题、选言命题和假言命题展开(见表2)。

表2 性质命题、联言命题、选言命题和假言命题的例句及关键成分
2.1.1 性质命题
性质命题是一种简单命题,是断定事物具有某种性质的命题,由逻辑常项和逻辑变项组成。
逻辑变项: 分为主项和谓项。主项是表示命题对象的概念,谓项是表示命题对象所具有或不具有的某种性质的概念。
逻辑常项: 分为量项和联项。量项是表示命题对象数量的概念,联项是用来联系主项与谓项的概念。
表2的例句T3中,主项是“白猫”,谓项是“哺乳动物”。量项是“所有”,联项是“是”。
2.1.2 联言命题
联言命题是复合命题的一种,是断定事物的若干情况同时存在的命题。联言命题一般由联言肢和联言联结词组成。
联言肢: 联言命题所包含的简单命题称为联言肢。
联言联结词: 表达联言命题的逻辑联结词称为联言联结词。
表2的例句T4中,联言肢为“味噌可以做成汤品”和“味噌能与肉类烹煮成菜”。联言联结词为“既……又”。
2.1.3 选言命题
选言命题也是复合命题的一种,是断定事物若干种可能情况的命题。选言命题由选言肢和选言联结词组成。
选言肢: 选言命题所包含的简单命题称为选言肢。
选言联结词: 表达选言命题的逻辑联结词称为选言联结词。
表2的例句T5中,选言肢为“海角天涯形容彼此相隔极远”和“海角天涯形容事物的尽头”。选言联结词为“……或……或……”。
2.1.4 假言命题
假言命题也是复合命题的一种,是断定事物情况之间条件关系的命题。假言命题由假言肢和选言联结词组成。
假言肢: 假言命题所包含的简单命题称为假言肢。
假言联结词: 表达假言命题的逻辑联结词称为假言联结词。
表2的例句T6中,假言肢为“左耳先听到声音”和“听者就觉得这个声音是从左边来的”。假言联结词为“如果…那么…”。
2.1.5 四类命题在自然语言中的逻辑常项
逻辑常项是逻辑形式中不变的部分,即在同类型的逻辑形式中都存在的部分[18]。常项在思维逻辑形式中起决定作用,它是区分思维逻辑形式的标志[17]。在上述四种命题中,性质命题的逻辑常项包括量项和联项,而联言命题、选言命题和假言命题中的联结词就是逻辑常项。
根据《形式逻辑》[2]一书中总结的文本中的常见的逻辑常项,我们汇总并补充了四类命题在文本中常见的逻辑常项,见表3。

表3 各类命题在文本中的逻辑常项
2.2 关键成分研究
自然语言中的显式命题也往往包含冗余信息。抽取命题的关键成分有利于理解自然语言。命题的关键成分是指构成该命题成立的最基本要素。
段士平[21]将语块定义为以整体形势存储在大脑记忆库中,并可以作为预制板块,供人们提取使用的多词单位。通俗地讲,语块的概念淡化了原有的词汇与语法之间的界限,不仅包括多词的搭配、句子框架,还可以扩大到句子,甚至语篇。参考段士平[21]对“语块”的定义,我们将命题的关键成分定义为构成命题最基本的几个语块。
性质命题的关键成分是指命题中构成主项和谓项的最小语块。例如,“白猫”和“哺乳动物”是性质命题“所有的白猫都是哺乳动物”的关键成分(见表2,T3)。
联言命题的关键成分是指构成各联言肢中主项和谓项的最小语块。例如,“味噌”“可以做成汤品”和“能与肉类烹煮成菜”是联言命题“味噌,既可以做成汤品,又能与肉类烹煮成菜”的关键成分(见表2,T4)。
选言命题的关键成分是指构成各选言肢中主项和谓项的最小语块。例如,“海角天涯”“彼此相隔极远”和“事物的尽头”是选言命题“成语释义海角天涯释义形容极远的地方,或彼此相隔极远,或者事物的尽头”的关键成分(见表2,T5)。
假言命题的关键成分是指构成各假言肢中主项和谓项的最小语块。例如,“左耳先听到声音”和“听者就觉得这个声音是从左边来的”是假言命题“如果左耳先听到声音,那么听者就觉得这个声音是从左边来的,反之亦然”的关键成分(见表2,T6)。
3 自然语言中的逻辑命题挖掘和标注
本次逻辑命题挖掘和标注任务主要分为数据选择和预处理、制订标注规范、数据标注、数据标注结果分析几个步骤,图1是本次数据标注的整体流程。

图1 标注流程图
3.1 数据选择和预处理
显式命题可能出现在任何类型的自然语言文本中。合适的语料来源能挖掘更多、更有效的语料。因此语料来源的选择至关重要,直接关系到标注的难度和成本。为此,本文收集、对比并分析了文学语料、微博语料(2)https://weibo.com和百度百科语料(见表4)。
微博是一种信息发布及社交网络平台[22]。用户可以通过发表微博来记录生活、分享心情、表达观点等。微博中抽取的句子的句式比较随意,且通常含有较多语气词(如表4中,“哈哈”“啦”和“的啦”等)。文学语料虽然结构完整、文本规范,但其内容往往很难控制。大部分文学作品或多或少涉及到各类虚拟人物或事物,这导致难以判断文本的真假性。如表4中,“许多”和“时代”是文学作品中创作的虚拟人物,因此与他们相关事物的真假较难判断。除此之外,文学作品大多叙事,较少出现对某些事物有所肯定或否定的表达。百科语料是内容开放、自由的网络百科全书。与微博语料相比,其结构更为完整、规范,语句更通顺;与文学语料相比则更具真实性和普适性。如表4中,百度百科例句有明确的描述事物“资本主义”及性质“资本主导社会经济和政治的意义”,并能辨别真假。因此,本文选择百度百科作为数据来源。
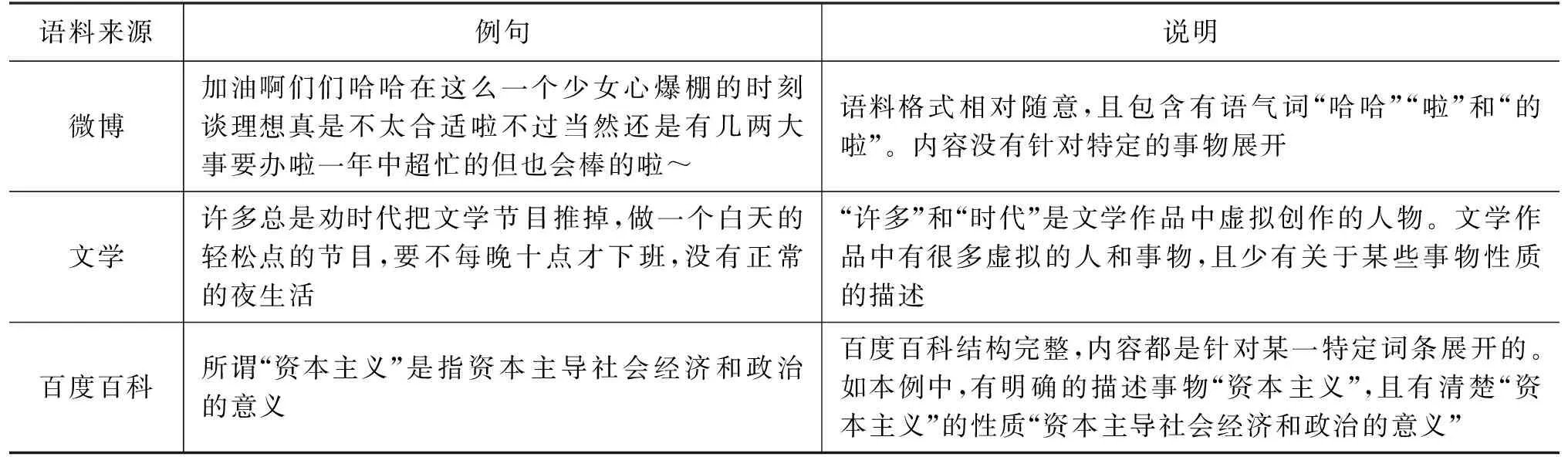
表4 三种语料来源对比
本次研究共选取2 111 764条百科词条对应的简短描述,并去除了不完整的句子。我们把四种命题类型的常见逻辑常项作为触发词,从语料中抽取各类命题的候选集。筛选得到24 337条候选显式命题。我们招募5名具有语言学背景的研究生和本科生对24 337条显式命题集进行标注。具体流程在后续章节中详述。
3.2 制订标注规范
本次标注主要包含两个任务: 是否命题标注和命题关键成分标注。
在是否命题标注阶段,标注者需要标出一个陈述句是否为命题,该阶段主要是判断前面给出的命题句是否是一个合格的命题,若是合格的命题,则标注为1;若是不合格的命题,则标注为0。根据命题的定义,我们提出以下两个命题标注规范:
规则1: 该命题描述的主体是一个明确的概念或者某一明确的事件,例如: 味噌、阮和海獭等,而不是一些代词,如她、他、它、这个和那个等。例如,陈述句“大部分时间里,海獭不是仰躺着浮在水面上,潜入海床觅食,当它们待在海面时,几乎一直在整理毛皮,保持它的清洁与防水性”符合规则1,因为其包含明确的描述主体“海獭”。而陈述句“这个画派的活动时间虽然不是很长,但是对于19世纪的英国绘画史及方向,带来了很大的影响”不符合规则1,其描述主体是代词“这个”。
规则2: 该命题符合其所在的“命题类型”大类的普遍定义和特征。例如“三叶草是优质豆科牧草,茎叶细软,叶量丰富,粗蛋白含量高,粗纤维含量低,既可放养牲畜,又可饲喂草食性鱼类”是符合定义和性质的联言命题。而陈述句“锡勒图库伦历史上虽然以喇嘛旗著称,但是原来没有喇嘛教的学塾”尽管是由联言联结词“虽然……但是……”引导的,但其不符合联言命题定义,没有阐述事物的若干情况同时存在。
在命题关键成分标注阶段,标注者需要进行两项任务,一是核查命题,即对第一步标注的是否命题数据进行再次审查,确保流入第二阶段数据的有效性;二是参照前文对于命题关键成分的定义将构成命题的关键片段抽取出来,要求尽量直接复制、粘贴,而不是自己键盘输入,避免由于键入产生的误差。
3.3 标注数据
标注工作分为两个步骤: 第一步是对已有命题候选集中每一条数据进行“0-1”标注;第二步是对第一步中被标注为“1”的数据进行关键成分抽取。本次标注的总体流程如图1所示。
5名语言学专业的硕士生和本科生参与了标注。整体的标注分为培训、试标注、正式标注三个环节。
在线下培训环节,介绍了标注任务、界定了命题的概念及不同类型命题的定义及划分。
在试标注环节,5名标注人员对同样的100条候选的命题句进行“0-1”标注以确保标注人员完全理解了标注规范。一致性检验结果显示,5名标注者之间的一致性较好(Fleiss’ kappa=0.69[23]),说明培训后的标注员理解了标注规范,可以进行正式标注。
正式标注环节可分为两个阶段: 第一阶段是判断候选命题是否为命题,标注者要求对候选命题进行“0-1”判断,是命题的候选句标为“1”,不是命题的候选句标为“0”。为了保证标注结果的准确性,第二阶段有两项标注任务: 对第一阶段中标注为“1”的数据进行二次核查标注。若核查之后该句子依旧被认定为是符合规范的命题则标为“1”并标注命题关键成分;若核查之后认定该命题不符合规范,则标为“0”。我们从核查为1的数据中随机选择5 565条数据进行第二阶段标注。第二阶段进行命题关键成分抽取,要求标注员按照标注规范标记命题关键成分。
全部的标注流程结束之后,将24 337条标注为“0”和“1”的句子作为显式命题自动识别任务的数据集,将标注了关键成分的5 565条显式命题作为关键成分解析任务的数据集。
3.4 数据标注结果分析
本文从百度百科中抽取了24 337个候选命题进行标注,最终构建了包含24 337条有效数据的自然语言显式命题自动识别任务数据集和包含了5 565条数据的命题关键成分解析数据集。其中,自然语言显式命题数据集包含14 625条非命题和9 712条命题。
我们将所构建的数据集按照命题类型所占比例切割成训练集、验证集、测试集三个部分。具体数据情况如表5所示。

表5 显式命题自动识别和关键成分解析数据集统计
4 显式命题自动识别研究
显式命题自动识别是自动识别出某一句话是否为命题,可以抽象为“0-1”二分类问题。本文采用SVM[3]作为该任务的基线模型,并构建BiLSTM[4]和在本任务上微调的BERT[5]进行对照实验。评价指标为分类正确率。
4.1 显式命题自动识别模型
4.1.1 Support Vector Machine(SVM)
SVM由Cortes和Vapnik[3]于1995年首先提出。它在解决小样本、非线性及高维模式识别中表现很好,是现有机器学习中应用最广泛的一种分类算法。
本文基于scikit-learn(3)https://scikit-learn.org/stable/modules/svm.html实现SVM模型。SVM输入特征为句子全部字向量的加和。本研究中使用的字向量由大规模百度百科语料预训练而来[24]。
4.1.2 Bi-directional Long Short-Term Memory(BiLSTM)
BiLSTM[4]的基本思想是每一个训练序列都有向前和向后的两个LSTM(long short-term memory)。这个结构将输入序列中每一个点前向和后向的信息拼接起来作为完整的上下文信息提供给输出层。本文将平均池化和最大池化的BiLSTM输出拼接起来作为句子的最终表示,将其提供给分类器。
实验代码的实现基于tensorflow框架(4)https://tensorflow.google.cn/实现,采用字级建模,使用预训练的字向量作为初始表示,字向量在训练过程中不断更新。
4.1.3 Bidirectional Encoder Representation fromTransformers(BERT)
BERT[5]是一种新的语言表示模型。它的模型结构由多层的双向Transformer编码器[25]构成。BERT支持对特定的任务进行微调,只需要添加一个额外的输出层,不需要对模型结构进行大量的修改。BERT作为一种新型的语言模型,充分利用大量无监督数据将语言学知识隐含地引入特定任务中,在多项自然语言处理任务中达到了最优结果[5]。因此,BERT模型能很好地迁移到显式命题自动识别任务上。
对于显式命题自动识别任务,我们使用了Google AI开源的BERT代码(5)https://github.com/google-research/bert,根据我们的任务调整部分参数,微调过程载入Google AI在维基百科数据上预训练的中文模型。
4.2 结果分析
首先,我们对比了SVM、BiLSTM和BERT三个模型在显式命题自动识别任务2 000条测试集上的表现能力;其次,我们以准确率最高的BERT模型为例,详细地分析了该模型在不同长度和不同类型命题上的表现。
4.2.1 总体分析
表6展示了三个模型在显式命题自动识别任务上的结果。SVM、BiLSTM和BERT在显式命题自动识别任务中的测试集上正确率分别为59.65%、66.80%和74.95%。其中,BERT表现最好,比SVM高15.30%,比BiLSTM高8.15%。这可能是因为,BERT是基于大规模维基百科数据上预训练得到的模型进行微调进而进行分类,百度百科数据和维基百科数据都是半结构化的百科数据文本,因此它们在结构上、内容上都具有一定的相似性。因而,BERT在基于百度百科数据的显式命题自动识别任务上表现较好。
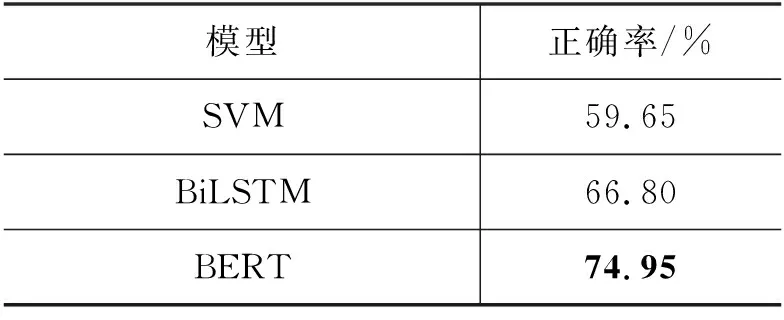
表6 三个模型在显式命题自动识别测试集的正确率
4.2.2 BERT在不同类型命题上的表现
图2展示了BERT在本次研究中涉及到的四类命题上的识别正确率。从图中我们可以明显地看出,BERT模型对联言命题和假言命题的识别正确率分别达到了80.60%和78.38%,说明BERT对联言命题和假言命题的识别能力比较高。相反地,BERT模型对于性质命题和选言命题的识别能力较差,正确率仅有72.74%和71.30%。

图2 BERT在不同类型命题上的识别正确率
4.2.3 BERT在不同句长命题上的表现
图3展示了BERT模型在不同长度命题上的显式命题识别正确率。从图中可以看出,BERT模型在不同长度命题上的表现并无明显规律,这证明本次所建立的数据的难度是比较均匀的,不会受到句长因素的影响。

图3 BERT在不同命题长度区间上的正确率
5 命题关键成分解析研究
命题关键成分解析是从已有命题中提取出关键成分,可以抽象为序列标注问题。本文采用四位标记“BMES”对标注数据进行整理。每个关键成分的开头部分被标记为“B”,中间部分被标记为“M”,结尾部分被标记为“E”,关键成分为单字,则标为“B”,其余非关键成分被标记为“S”,如表7所示。

表7 命题关键成分解析标记实例
5.1 命题关键成分解析模型
5.1.1 Conditional Random Field(CRF)
CRF[6]是给定一组输入序列,预测另一组输出序列的条件概率分布的模型。CRF在预测时考虑相邻数据的标记信息。
本文使用开源的工具包CRF++(6)https://taku910.github.io/crfpp/实现本实验。
5.1.2 BiLSTM-CRF(BiCRF)
基于神经网络的方法在序列标注任务中非常流行。Lample等人[26]提出了基于词和字符嵌入的BiLSTM-CRF命名实体识别模型。在序列标注任务中,基于深度学习的BiLSTM被用来提取特征,CRF层为最终的预测标签添加一些约束。受到该模型的启发,本文使用基于字嵌入的BiLSTM-CRF作为命题关键成分解析的基准模型之一。
本文使用开源工具包NCRF[7]实现了基于预训练字向量[24]的BiLSTM-CRF实验。
5.1.3 BERT-BiLSTM-CRF(BBiCRF)
最近BERT模型刷新了自然语言处理多项任务的最高记录。基于维基百科预训练的BERT模型在处理百科数据上具有优势,因此我们构建BBiCRF进行实验。BBiCRF的主要思想是使用BERT模型,在大规模语料库上预训练上下文相关的字向量表示替换BiCRF的字向量,最终利用CRF层的输出预测输入序列的标记。
我们对命名实体识别任务的开源工具包BBiCRF(7)https://github.com/macanv/BERT-BiLSTM-CRF-NER进行修改并实现命题关键成分抽取模型。
5.2 结果分析
首先,我们分析CRF、BiCRF、BBiCRF三个模型在命题关键成分解析任务500条测试集上的表现能力;其次,以BERT模型为例,详细地分析了该模型在不同命题类型数据上的表现能力;再次,选取部分实际数据案例,分析其在三个模型上的序列标注结果,详述每个模型识别的异同。最后,为验证关键成分的有效性,我们用5 565条命题的关键成分替换显式命题识别数据集中的相应命题,并在BERT上进行实验。
5.2.1 总体分析
表8展示了三个模型在命题关键成分解析任务上的实验结果。CRF、BiCRF、BBiCRF在该任务测试集上F值分别为: 73.05%、83.45%和90.74%。其中,BBiCRF表现最好,比CRF高17.69%,比BiCRF高7.29%,这得益于BERT在大规模维基百科上的预训练。而BiLSTM处理了长距离的依赖问题,加强了局部窗口的联系,这使得BiCRF模型得到的标注结果的准确率、召回率、F值分别比CRF模型提高3.98%、17.44%和10.4%。

表8 模型在命题关键成分解析测试集的表现(%)
5.2.2 BBiCRF在不同类型命题上的表现
为进一步分析模型在命题关键成分解析任务上的表现,我们在图4中展示了BBiCRF在解析不同类型命题的关键成分时的实验结果。
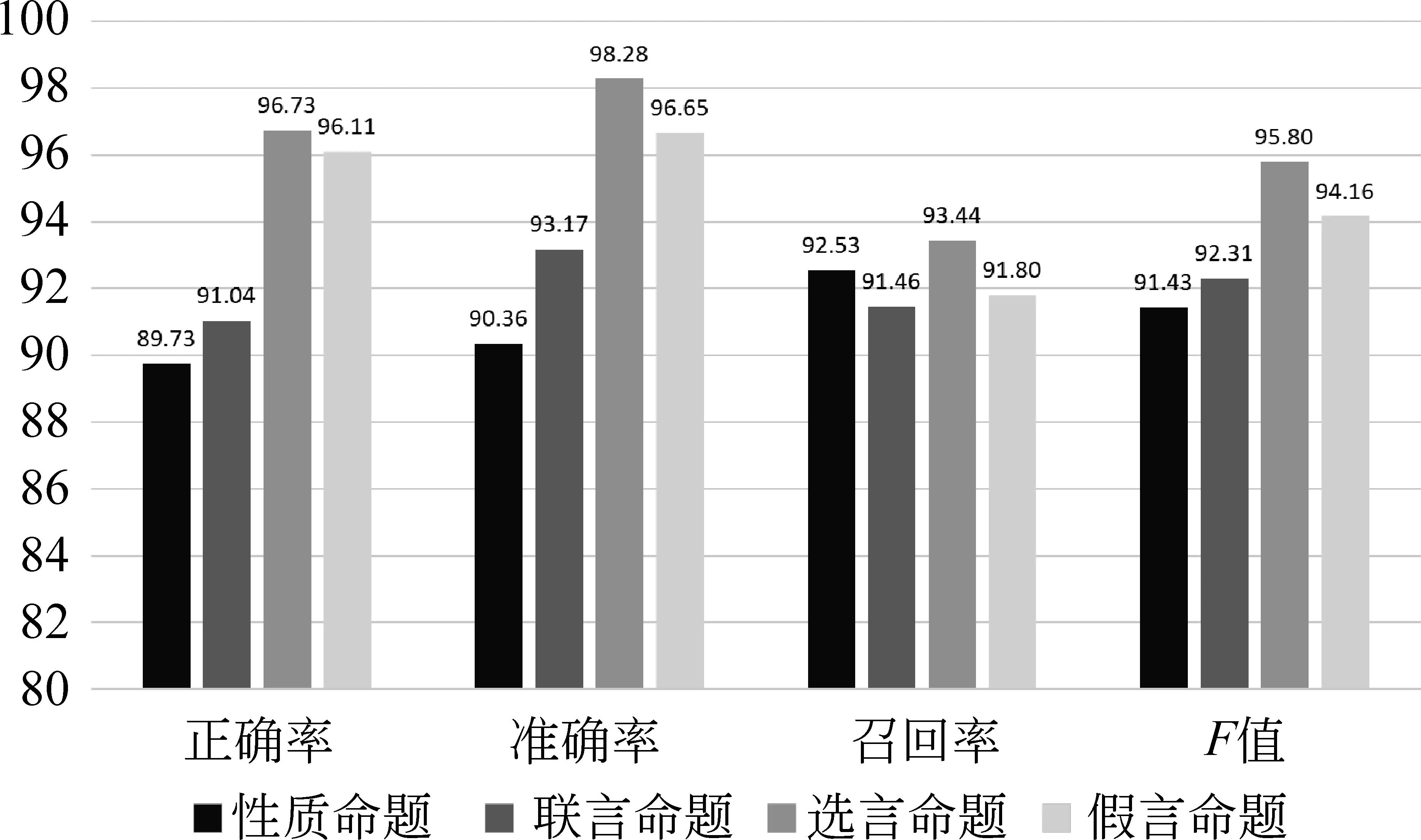
图4 BBiCRF在不同类型命题上的表现
从图4中看出,BBiCRF对选言命题的标注能力较高,标注准确率达98.28%,F值也达到95.80%,这可能是由于所构建的数据集中选言命题的数量较少所致。如何在样本量差距较大的情况下还能平均地学习到每个类型命题的特点并进行关键成分解析是未来研究的重难点之一。我们也将在未来的数据集完善过程中增大选言命题的规模。除此之外,BBiCRF对其他类型命题的标注结果比较平均,这说明数据集内每种类型命题在关键成分解析任务上的难度比较平均。
5.2.3 实例分析
我们选取部分实际数据案例,分析它们在CRF、BiCRF、BBiCRF三个模型上序列标注的结果。图5展示了我们从测试集中选择的3条案例以及三个模型的解析结果。

图5 实例分析
对于例1,CRF和BiCRF都没有将第一个关键成分“玉田县国家档案馆”标注出来,而BBiCRF能正确地将关键成分标注出来。与其他两个模型相比,BiCRF能准确地标注出命题的几个关键成分,漏标关键成分的情况比较少。
对于例2,CRF错误地将“却偏偏表现出对异性恐惧”标注为一个关键成分片段,BiCRF则将“偏偏表现出对异性恐惧”标为一个关键成分片段。CRF和BiCRF有时会将非关键成分片段标为关键片段,BBiCRF能做出正确标注。
对于例3,CRF和BiCRF在进行第二个关键片段标注时都错误地定位了片段的边界,将“称之为音频”标记为了“称之为音频,它可能包括噪音等”。以上两个模型能很好地识别到命题关键成分所在的位置,但是对于其边界判断还存在问题,未能在结束位置停止标注。相比前两个模型,BBiCRF能很好地定位关键成分边界。
综上,CRF和BiCRF在进行命题关键成分解析任务时会出现关键成分漏标、错误标注关键成分边界的情况,而CRF更是会出现将非关键成分标注为关键成分的情况。BBiCRF则在这些问题上有很好的表现。
5.2.4 BERT在关键成分数据集上的表现
为探究关键成分是否能代表命题中的关键信息,我们在显式命题自动识别任务上利用解析的关键成分进行了实验。
我们将显式命题自动识别数据集中5 565命题替换为仅其关键成分,例如,用“招式 讲究大开大阖”替换原命题“所有的招式都讲究大开大阖,势大力沉,大气磅礴,没有任何用来诱惑取巧的花样”。
我们用BERT在替换后的数据集上重新进行实验。实验结果见表9。从表中可以看出,将部分命题替换为关键成分后,BERT在替换后测试集上的正确率达到了82.70%,比在原始数据测试集上提升了7.75%。在替换为关键成分的命题数据上,识别正确率更是达到了98.20%,比在原始被替换的命题数据上提高了16.22%。结果证明了我们提取的关键成分有效地提升了命题自动识别的正确率,命题中的关键成分可以代表命题的关键信息。

表9 BERT在命题自动识别测试集上的表现
6 结语
本文提出自然语言显式命题自动识别任务和命题关键成分解析任务。显式命题自动识别的目的是判断一个自然语言句子是否为命题。命题解析是从已获取的命题中解析出支撑该命题成立的关键成分。为此,我们为两个任务建立了大规模人工标注数据集,分别是: 包含24 337条有效数据的自然语言显式命题自动识别数据集和包含5 565条数据的命题关键成分解析数据集。通过构建基于统计学习和基于深度学习的模型,我们在自然语言显式命题自动识别和命题关键成分解析两个任务上进行了初探。实验结果表明,本文提出的深度学习模型能有效识别显式命题并解析显式命题的关键成分,为下一步研究提供了可靠的基线方法。本文数据已经公布在https://github.com/blcunlp/Explicit-Propositions。
自然语言中的命题可以分为显式命题和隐式命题,本文主要研究的是自然语言中的显式命题,在未来的工作中我们将逐渐探索自然语言中的隐式命题。本次研究根据性质命题、联言命题、选言命题和假言命题四种类型的命题及其触发词在百度百科数据源上筛选并构建了数据集,未来将通过人工标注的方法尝试在更多的数据源上进一步扩大数据集规模,涵盖更多的命题类型,如关系命题和负命题等,为后续模型研究提供良好的数据基础。
本文工作为显式命题自动识别和关键成分解析的研究提供了可以研究和改进的方向,包括: ①扩展命题类型,目前涉及到四种显式命题,未来可在其他类型命题上进一步扩展; ②扩充从自然语言文本中挖掘候选命题时用的触发词表,针对每一类命题,继续探索可用的触发词,以扩大语料规模; ③从更多的数据源中挖掘命题,扩大命题数据集的规模; ④尝试隐式命题的挖掘; ⑤进一步强化两个任务的模型,提高模型的学习能力。
猜你喜欢
中老年保健(2022年1期)2022-08-17
舰船科学技术(2022年10期)2022-06-17
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28
中国交通信息化(2019年7期)2019-10-08
特别健康(2018年3期)2018-07-04
电测与仪表(2016年6期)2016-04-11
中国商人(2013年1期)2013-12-04
中国商人(2013年1期)2013-12-04
对联(2011年24期)2011-11-20
对联(2011年18期)2011-11-19
