
基于知识拷贝机制的生成式对话模型
2021-03-17 07:48李少博孙承杰刘秉权季振洲王明江
中文信息学报 2021年2期
李少博,孙承杰,徐 振,刘秉权,季振洲,王明江
(哈尔滨工业大学 计算机科学与技术学院,黑龙江 哈尔滨 150001)
0 引言
作为自然语言处理领域内的主要研究问题,自动对话系统近年来受到了越来越多的关注。特别是“编码—解码”结构在机器翻译任务上取得重大进展之后[1],基于“编码—解码”结构的生成式对话模型也成为了一个热点研究方向。一方面,基于“编码—解码”结构的对话模型可以在大规模的对话语料上以端到端的方式训练。另一方面,根据当前对话自动生成对应回复的模型为自动对话系统的构建提供了新的范式。
由于对话语料中的词频符合长尾分布[2],且模型的优化目标属于经验风险最小化,基于“编码—解码”结构的对话模型更趋于产生信息量低的回复。为了解决这个问题,很多研究者从目标函数[3]、解码方法[4]、主题信息[5]等方面进行了深入探索。同时,也有研究者注意到,知识在对话过程中也起着十分重要的作用,知识不仅有助于对话的理解,对话之间的内在联系[6-7]分析,还能够为回复生成提供更丰富的信息,增加对话的广度和深度。而知识图谱[8-9]作为一种高度结构化的知识,能够以三元组(实体,关系,属性)的形式提供高质量的知识。如何在端到端的模型中有效利用知识图谱,将其融入到“编码—解码”结构中,正吸引着越来越多研究者的目光。
为此,本文提出了一种基于知识拷贝机制的生成式对话模型。首先,本文使用提出基于知识图谱的映射机制对对话内容进行处理,利用知识图谱将对话中出现的实体和属性映射为特殊的标识符,从一定程度上克服词频分布不均导致的生成回复信息量低的问题。随后,模型使用知识拷贝机制,以拷贝的形式直接将知识图谱中的词汇拷贝到回复中。最后,模型利用注意力机制从知识图谱中选择较有效的信息来进一步指导回复的生成。实验表明,相较生成式基线模型,本文所提出的模型可以生成更加准确和多样的回复。
本文组织结构如下: 第1部分对端到端的生成式对话模型以及如何在其中融入知识的相关工作进行简要介绍;第2部分详细介绍本文提出的模型、所使用数据集以及使用映射机制对对话内容进行处理的方式;第3部分对本文提出的模型进行实验对比和分析;最后为对本文工作的总结。
1 相关工作
由于互联网社交平台中(如新浪微博)积累了大量的对话资源,数据驱动的生成式对话模型受到了越来越多的关注。Ritter和Vinyals等发现对话系统中的“消息—回复”关系可按照机器翻译中“编码—解码”过程来建模,通过对编码后的消息序列进行解码来生成回复序列,构建了端到端的生成式对话系统[10-12]。早期的研究工作重点主要集中在对话的语义表示、语义关系计算以及上下文建模上[13-15],没有考虑外部知识在对话过程中的作用。
文献[16]中,作者首先做出了如下假设: 对话参与者给出的回复不仅仅依赖于对话历史,同时也依赖于参与者了解的与对话相关的知识。作者使用Reddit论坛中的对话和维基百科页面构建了对话以及相关知识语料库,分别使用循环神经网络(recurrent neural network,RNN)和卷积神经网络(convolutional neural networks,CNN)对对话和相关知识进行编码,利用这两部分编码信息来生成回复序列。
文献[17]中,自然语言形式的相关知识被表示为词袋(bag of words,BOW)的形式,使用类似于Memory Network[18]的方式将其转换为知识编码向量,随后将该向量附加到RNN解码器的初始状态中。同时,该文为模型的训练定义了多个任务,在训练模型时,按照预先定义的方式随机选择一个任务进行训练。在解码时,使用增加了回复长度和互信息特征的集束搜索(beam search)来生成最终的回复。
Wu等人在利用相关知识生成回复的同时,提出一种知识选择机制[19]。在训练过程中,根据对话历史和训练集中的真实回复来选择最相关的知识,保证训练过程中所选知识的准确性;在生成回复的过程中,模型仅使用对话历史来选择知识。为了处理模型在训练与生成时所选知识之间的差异,模型使用了多种损失函数进行优化。
2 基于知识拷贝机制的生成式对话模型
2.1 模型结构
本文提出的模型是一种基于“编码—解码”结构改进而来的端到端模型,其中包含对话历史编码模块、知识编码模块、知识拷贝模块和注意力解码模块4个部分。模型生成回复序列中每个词的过程如图1所示。

图1 模型生成回复的过程
模型的输入包括对话历史和与对话相关的知识图谱两部分。首先使用对话历史编码模块和知识编码模块分别将对话历史和知识图谱中的知识条目转换为向量形式的表示,随后使用知识拷贝模块和注意力解码模块将其解码为回复词序列。
2.1.1 对话历史编码模块

2.1.2 知识编码模块
在对三元组形式的知识图谱中的知识条目进行编码的过程中,编码的主体是三元组(实体、关系、属性)中的属性部分。首先将输入的多个知识图谱三元组中的属性拼接在一起形成为一个词序列K={k1,k2,…,kn},随后将其转换为词向量序列{ek(k1),ek(k2),…,ek(kn)}。为了保留属性在三元组中对应的关系和实体信息,在序列K中的每个词的词向量上添加了额外的关系和实体编码。K中第j个词的词向量ek(kj)计算如式(1)所示。
ek(kj)=e(kj)+e(rj)+e(Ej)
(1)

通过上述编码方式,知识被编码为向量形式的表示,其中包含的信息一方面被知识拷贝模块使用,用来判断是否将序列K中的词拷贝到回复中,另一方面被注意力解码模块用于指导回复的生成。
2.1.3 知识拷贝模块
拷贝机制[21]的主要思想是在生成回复序列中的每一个词时,模型可以从一个额外的候选词汇集合中选用一个词作为当前生成的结果。这样一来,可以通过构建一个数量较小、包含信息较为丰富的候选词汇集合,来帮助模型生成质量更高的回复。同时在候选词汇集合中也可以包含词表中未出现过的词汇,增强模型的泛化能力。
本文使用知识图谱中属性所包含的词作为候选词汇集合,拷贝方式参考了CopyNet[21]中的拷贝机制,与其不同的是,CopyNet中的拷贝机制是从对话历史中拷贝,对话历史是完整的自然语言对话,拷贝时可以利用词的上下文关系。而知识拷贝是从知识图谱三元组中属性拼接成的词序列K中拷贝,词的前后相关性较弱,故在知识编码模块中保留了关系信息和实体信息,以便知识拷贝模块利用。
知识拷贝的具体过程如下: 在对回复序列中的第t个词进行解码时,不仅计算词表中每个词的生成概率,同时计算序列K中每个词被拷贝的概率,若拷贝概率大于生成的概率,则将拷贝概率最大的词直接作为回复中第t个词yt。
K中第j个词kj的拷贝概率使用式(2)计算。
(2)

在知识拷贝过程中,模型需要记录已经被拷贝的词的相关信息,这一信息称为选择性输入(selective read),其有助于模型综合利用被拷贝词本身包含的信息以及词的位置信息[21],选择性输入使用式(3)计算。
(3)
2.1.4 注意力解码模块

(4)
(5)
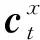
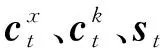
其中,gt为长度与词表大小相同的向量,表示词表中每个词的生成概率,ct为长度为n的向量,表示序列K中每个词的拷贝概率。将两个向量拼接后,使用softmax函数进行归一化处理。若ot中的值最大的元素存在于与gt对应的部分中,则将词表中对应的词作为yt,若存在于ct所对应的部分中,则将K中相应的词作为yt。若在序列K中出现了词表中相同的词,则将相同的词对应的拷贝概率与生成概率相加后再进行比较。
为了对解码模块输入的各部分信息的有效性进行验证,本文共构建了4个不同的模型,如表1所示,其中最后一个模型MCTA为本文最终使用的模型。

表1 构建的模型信息
2.2 数据集
2.2.1 数据格式
本文使用了文献[19]中提供的数据集,该数据集在“2019语言与智能技术竞赛”中的“知识驱动对话”任务中使用(1)http://lic2019.ccf.org.cn/talk。数据集中的样本包括了“对话内容”“对话话题及其关联”和“与话题相关的知识图谱”三个部分,并包含了分词信息。其中“对话内容”中包括了多轮对话,对话的话题指定为两个,话题和话题之间的关系在“对话话题及其关联”部分中给出,最后给出了与两个话题相关的知识图谱。数据集中的样本形式如表2所示。

表2 数据集中的样本形式
2.2.2 基于知识图谱的映射机制
对话中经常会使用许多语义相近的词汇,例如,“北京市”和“上海市”均表示地理位置,“狼牙山五壮士”与“上甘岭”均表示电影的名称。这些词汇有着相近的语义但又互不相同,模型按照经验风险最小化的方式训练后,会趋向于选择语义相近的词汇中出现频率较高的词,这使得生成的回复中难以包含准确的信息。例如,若在训练数据中“北京市”的出现次数高于“上海市”的出现次数,那么模型在生成表示地理位置信息的词汇时,会更倾向于生成“北京市”,进而造成生成回复中包含错误的、与相关知识不相符的信息。
针对这一问题,本文提出使用基于知识图谱的映射机制对对话内容进行处理,其主要思想是利用相关知识,将对话内容中语义相近的词汇序列映射为相同的特殊的标识符,对这一部分内容进行统一的表示后输入到模型中,在模型生成回复序列后再将其中包含的特殊标识符还原为相关知识中对应的内容。
为了设计针对本文所使用数据集的映射机制,本文首先对数据集中不同词出现的频率进行统计,如表3所示,对话内容所形成的词表中共包含了49 129个不同的词,其中46.85%的词仅仅出现过1次,88.04%的词出现次数小于10次。由于样本数量较少,这一部分低频词汇的学习和生成对于模型来说十分困难。

表3 数据集中的词频情况
但经统计后发现,低频词汇中有很大一部分包含在对话所对应的知识图谱中,如表3中的第三列所示,总计78%的词可以在知识图谱中找到。故本文首先使用一种基于知识图谱的映射机制对数据集进行处理,处理后的结果如表4所示。
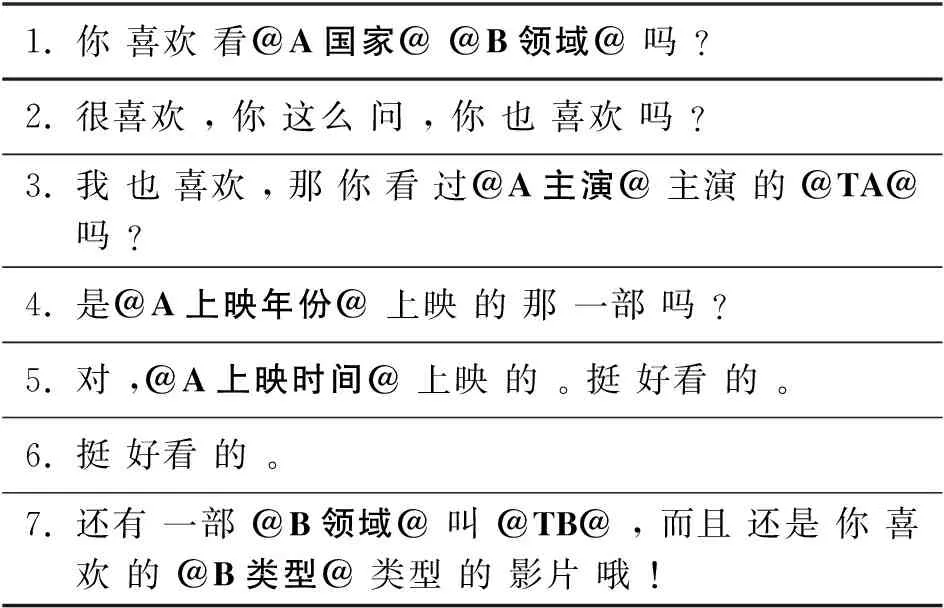
表4 映射机制处理后的对话内容

续表
在该数据集上,映射机制处理规则如下: 若对话内容中的词序列与知识图谱中的某一属性完全匹配,则将其替换成特殊标识符。特殊标识符的两端为字符“@”。由于该数据集中每一轮对话仅包含两个话题,故使用“@TA@”“@TB@”分别表示话题名称。在其余的特殊标识符中,字母“A”表示第一个话题相关的属性,字母“B”表示第二个话题相关的属性,字母后面的部分表示所替换内容在知识图谱中对应的关系。经映射机制处理后的词频情况如表5所示。可以发现,经映射机制处理后,词表的大小减少了47.19%,对话数据得到了有效的简化。同时,出现次数小于10次的低频词也有很大幅度的减少,词频不均现象也得到了改善,这能够进一步帮助模型对数据进行学习。
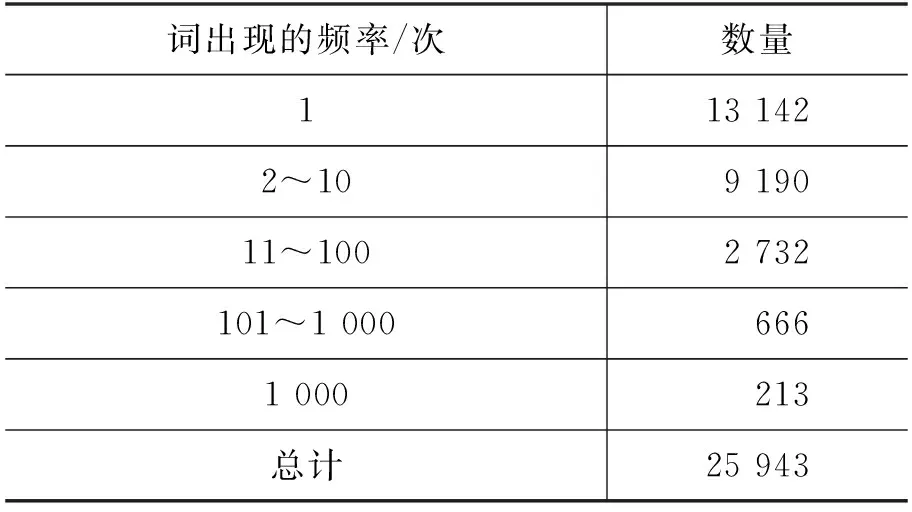
表5 映射机制处理后的词频情况
3 实验分析
本文所使用的数据集的详细信息如表6所示。

表6 数据集的详细信息
在训练集中,多轮对话被拆分为对话历史与回复形成的问答对,将每一个问答对作为一个单独的训练样本。测试集中的多轮对话则直接拼接用于模型输入。模型使用贪心的方式进行解码。模型中主要参数设置如表7所示。

表7 模型中主要参数设置
3.1 自动评价指标对比
在实验中,本文使用准确性字符级别的F1[22]、词级别BLEU-1和BLEU-2[23]以及多样性指标DISTINCT-1和DISTINCT-2[3]对模型进行评价。评价结果如表8所示,评价指标是基于测试集数据,使用“2019语言与智能技术竞赛”提供的线上评价系统计算得到的。Baseline-R和Baseline-G分别表示竞赛举办方提供的检索式基线模型和生成式基线模型(2)https://github.com/baidu/knowledge-driven-dialogue,这两个模型是使用与文献[19]中相似的方法构建的。同时,为了进一步对映射机制进行对比和验证,分别使用原始的对话数据和经映射机制处理后的对话数据训练文献[21]中所提出的拷贝模型,表示为CopyNet和CopyNet-M。

表8 模型结果的评价指标对比
由表8可以看出,首先,使用映射机制的生成式模型M以及CopyNet-M,相较未使用映射机制的生成式模型Baseline-G和CopyNet的结果有了大幅度提升。在使用了基于知识图谱的映射机制后,对话内容中存在的大量低频词汇被统一为特殊标识符,而特殊标识符在对话内容中的出现频率是一定高于替换前的原始词汇的,在生成回复时,相对高频的特殊标识符生成的风险要低于低频词汇,这保证了特殊标识符在回复中的出现频率,在将其还原成知识图谱中对应的内容后,也就提高了生成式模型回复的多样性。同时,在模型训练时,特殊标识符相较低频词汇有更多的机会参与到模型训练中,有利于模型充分掌握特殊标识符表示的语义,降低了数据的复杂度和模型对其的学习难度。
与模型M相比,添加了知识拷贝机制的模型MC的结果又有了进一步的提升。通过对结果进一步统计分析,发现约6.3%(3 456/54 739)的词是通过知识拷贝机制直接拷贝到回复中的,这说明回复的质量提升主要归功于知识拷贝机制。同时,被拷贝的词中还包括184个不包含在词表中的词,说明拷贝机制对不在词表中的词汇也有一定处理能力。
从表8中还可以看出,增加了知识编码信息的模型MCA和MCTA在指标上又有了进一步的提升,说明编码后相关知识的语义与回复的语义之间存在着较强的相关关系,在解码时选择合适的知识,能够帮助回复的生成。此外,引入截断机制的MCTA与MCA模型在评价指标上各有优势,相较MCA,MCTA在字符集别的F1上有所提升,而在词级别的BLEU-1和BLEU-2上则有所下降,经过分析,这可能是由于生成回复与真实回复之间的分词存在差异造成的,例如,在回复中包含词序列“看”“电影”,而在真实回复中包含的词是“看电影”,导致了F1与BLEU之间的差异。同时由于词频不均的原因,准确性指标和多样性指标之间存在矛盾,随着生成回复准确性的提升,多样性也略有下降。最终,相较生成式基线模型Baseline-G,MCTA在F1、DISTINCT-1和DISTINCT-2指标上分别取得了10.47%、4.6%和13.1%的提升。
3.2 具体实例分析
表9列举了模型MCTA的生成结果、模型Baseline-G的生成结果以及真实回复的一些具体实例。

表9 模型生成结果对比
在实例1中,对于“上映日期”这类能够与知识图谱类完全匹配的词汇,映射机制能准确地将其引入;在实例2中,对于“时光网短评”这类无法完全匹配的内容,知识拷贝机制也能够很好地处理,将其无缝融入到回复中。在实例3中,知识图谱中存在“狩猎,口碑,口碑 不错”这一信息,其以知识编码的方式添加到解码过程中,模型能够将其在回复中体现出来。在实例5中,本文提出的模型利用映射与拷贝机制,生成的回复中包含了大量的低频事实性词汇,相较模型Baseline-G,回复的质量有很大的提高。
同时可以发现,在实例2中,由于端到端模型中并没有使用特殊的机制来保证回复中语义的一致性,Baseline-G模型生成的结果出现了前后矛盾的情况。同样,在实例4中,Baseline-G模型生成了与实事不相符的信息。对于本文提出的模型来说,回复中的事实性内容能够通过映射和拷贝机制直接由知识图谱中引入,在一定程度上保证了信息的准确性和一致性,提高了生成式对话系统的实用性。
4 结论
本文提出了一种基于知识拷贝机制的生成式对话模型。首先,模型使用基于知识图谱的映射机制对对话内容进行处理,在一定程度上简化了对话内容,克服了词频长尾分布对模型造成的影响。其次,通过知识拷贝机制,模型能够将适合的词汇拷贝到回复中。最后,模型使用了注意力机制,能够选择最相关的知识并将其引入到回复中,对回复的生成进行指导。
实验表明,本文提出的模型能够提高端到端的对话模型所生成回复的准确性和多样性,使得所生成的回复更加恰当和实用。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
少先队活动(2020年12期)2021-01-14
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
中国生殖健康(2018年1期)2018-11-06
今日中国·中文版(2017年8期)2017-09-03
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
杂草学报(2012年1期)2012-11-06
