
基于BERT与Focal Loss的电商平台评论情感研究
2021-03-17 06:22北方工业大学信息学院北京0044镇江毓秀智教科技有限公司江苏镇江
仪器仪表用户 2021年3期
许 欣,余 杉(.北方工业大学 信息学院,北京 0044;.镇江毓秀智教科技有限公司,江苏 镇江 0)
0 引言
随着信息技术的飞速发展和移动互联网的迅速普及,互联网已经走进千家万户,成为人们生活的一部分。过去主流的购物场所是线下实体店,网购这种方式由于商品质量难以得到保证,比起商品的广告和图文介绍,人们更愿意通过其他消费者的评论信息来了解商品的详细信息。丰富的评论信息可以降低网络购物的不安全性。对于商家层面,商家可以实时通过这些评论得到真实的用户反馈,了解商品的优点、缺点和消费者口碑,从而判断商品存在哪些问题,制定合理的销售策略[1]。
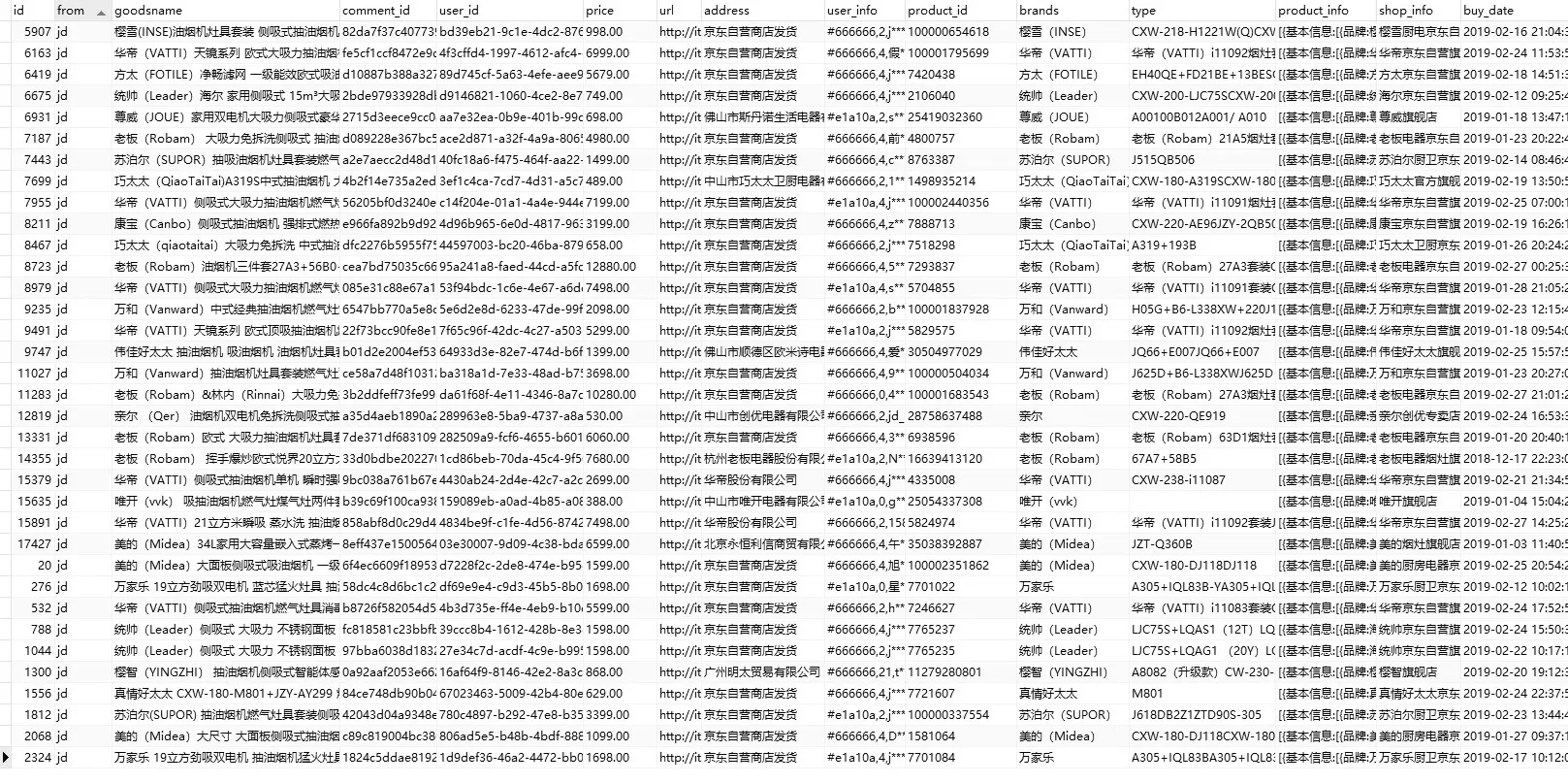
图1 数据集部分截图Fig.1 Screenshot of part of the data set
利用人工智能以及自然语言处理领域的相关技术,从这些主观信息评价中智能地挖掘出网民对某份商品的态度和情绪,并分析出对整个商业和社会有价值的信息,是当今热门且很有意义的研究课题[2]。
1 相关研究及本文研究方法
至今,特定领域情感分析研究大体可分为两类:一类是利用传统语言处理手段,针对特殊场景开展情感分析任务,主要通过人工构建情感字典[3,4]。这种方法工艺繁琐复杂,准确率低;另一类是利用神经网络对通用场景开展情感分析任务,这种方法仅提取浅层语义,对不同场景不同含义的歧义词识别率差。本文采用深度学习结合预训练模型,对特殊场景语言表达进行深层次语义提取,以此开展情感分析任务[5,6]。
2 数据集构建
构建数据集所用的商品评论信息来源于2019年国内7家主流电商平台部分商品的文本评价信息,共计40万条,数据集如图1所示。随后,对数据集数据进行数据预处理操作,数据预处理流程图如图2所示,包括异常字符处理、表情转义处理、平台数据标准化、数据去重、无价值数据剔除等步骤。最终完成数据集搭建工作,数据集共计21万条评论数据。在数据长度分布方面:80%数据长度集中在10~26个字符区间内,数据集数据平均长度为18个字符。数据情感倾向分布方面:96%的评论数据为正面评论,4%为负面评论。因此,存在严重的数据不平衡情况。
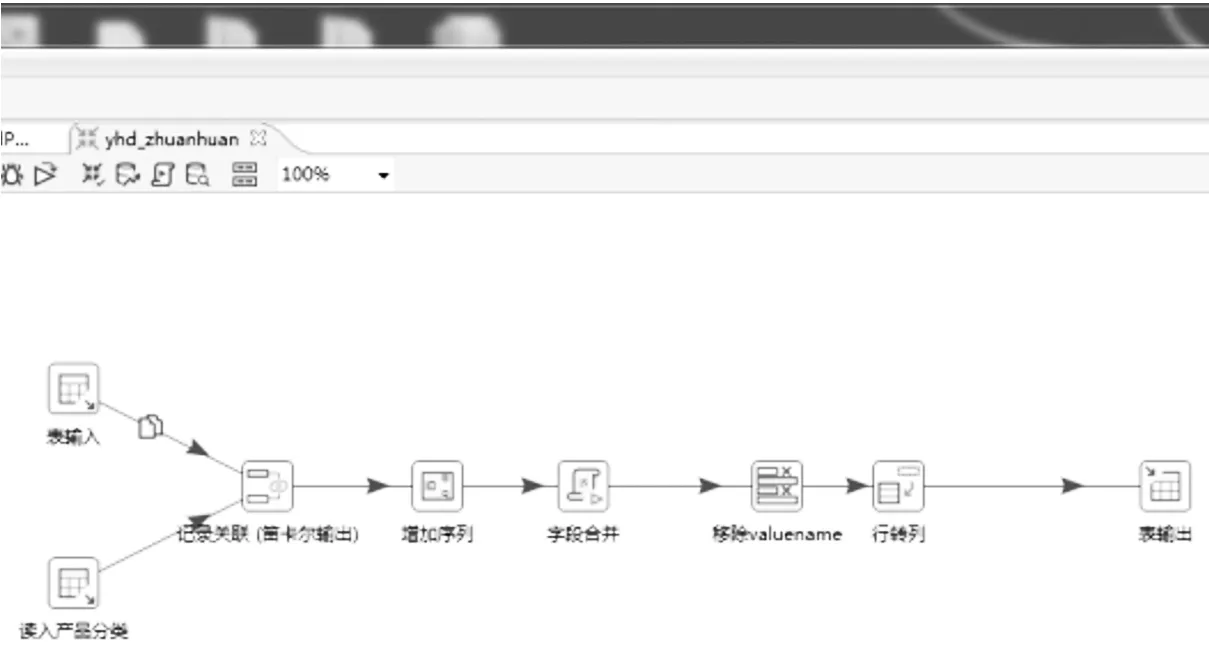
图2 数据预处理流程图Fig.2 Data preprocessing flowchart
3 模型构建
下面将详细描述本研究中用于情感分析的基本语言模型BERT,以及用于分类的损失函数。
3.1 BERT
BERT是一种基于双向Transformer的通用语言模型,它基于self-attention机制捕捉长距离信息,生成文本语义级别的词向量,核心计算公式如下:
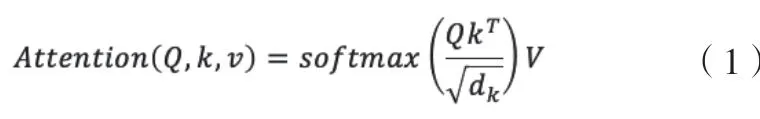
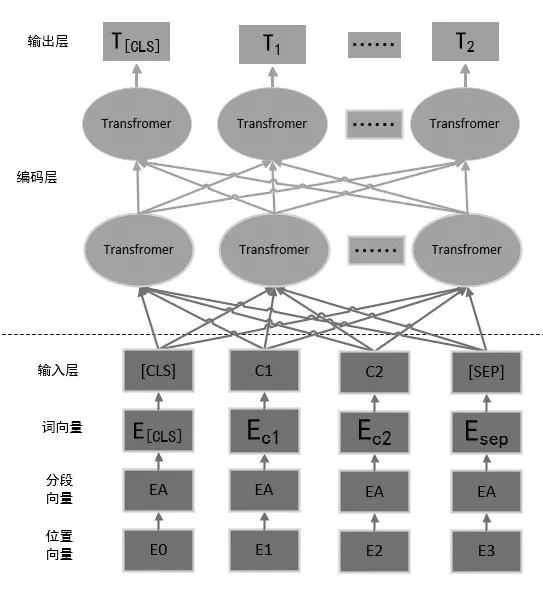
图3 Transformer结构示意图Fig.3 Schematic diagram of transformer structure
BERT使用33亿单词以及25亿维基百科和8亿文本语料的大型语料库进行预训练来提高其语义提取能力。在训练过程中,BERT通过使用[mask]标记随机替换文本字符,再通过模型预测原始字符,提高其对语义的理解与预测能力。BERT核心Transformer的结构如图3所示[6-8]。
为了将BERT应用于情感分析任务[9,10],首先使用大量评论数据对BERT进行fine-tuning训练,通过WordPiece masking(MLM)与Next Sentence Prediction(SEQ)任务,提高模型在电商评论领域的通用语义提取能力,随后将BERT模型的输入[CLS]句首标记作为分类器的输入[11-13]。
3.2 损失函数
3.2.1 Cross Entropy Loss(CEL)
BERT在解决分类问题的损失函数时,通常采用Cross Entropy Loss(交叉熵损失)[14,15]。在这项研究中,使用Eq表示二元交叉熵损失,公式如下:
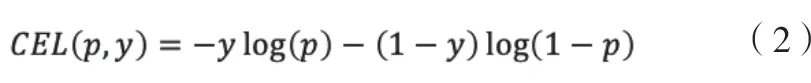
对于本项目数据分布严重不平衡问题,二元交叉熵损失函数会严重偏向易分类类别,导致数据量少的类别对于总损失贡献甚微[16,17]。为解决由每个类别数据规模导致的数据不平衡问题,引入权值α∈[0,1]来调整损失平衡,经过多次试验,发现可以使用每个类别包含数据规模的倒数作为α的实际值,公式如下:
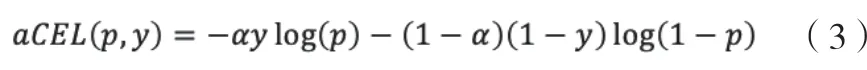
3.2.2 Focal Loss(FL)
Focal Loss是图像处理领域中目标检测问题的一个有效的损失函数[18,19]。在目标检测问题中,背景占据了图像的很大一部分,因此很难识别特定目标。Focal Loss在损失函数基础上引入一个调制因子γ,用来区分每个类的识别难度。公式如下:

由于调制因子的作用,模型减弱了容易识别类的错误贡献,并防止了压倒性的损失函数。这使得模型可以更有效地集中在难以识别的类别。
4 实验
在本次实验中,采用google公开的BART与训练参数Bert_base_chinese (num_transformer=12;hidden_size=768;num_transformer_block=12),比较了使用不同损失函数的分类器在情感分析问题的性能,使用的损失函数如下:
◇ BSE loss:传统最大交叉熵损失函数[20]。
◇ Focal loss:引入权值与调制因子的交叉熵损失函数。
使用的评价指标如下:
◇ F1_Score公式如下:
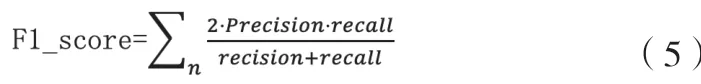
◇ Accuracy公式如下:
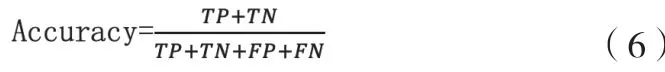
◇ MCC马修斯系数。MCC本质上是介于-1和+1之间的数值,1表示预测与真实分布接近,0表示预测为平均,-1表示预测与真实分布相反。MCC,也称为phi coefficient(phi)系数。MCC公示如下:
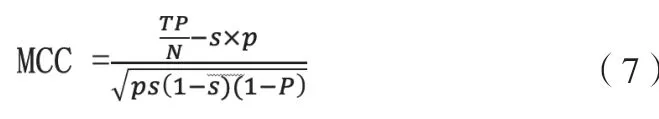
对每个分类器模型分别进行6次实验,取所有实验结果的平均值作为实验结果,具体见表1。首先,检测了使用两种不同损失函数的分类器的性能,之后通过改变Focal Loss引入权值与调制因子的取值,进行了不同的实验,以此来验证不同权值与调制因子对模型的性能的影响。随后选用正负类别规模不同的数据集A、B,分别检测不同损失函数分类器的分类效果,以此验证对于不同程度数据不平衡问题,不同损失函数的贡献。
由表1可见,通过对比BERT与BERT_Focal_Loss分类效果的差异,表明在数据不平衡问题中,增加权重与调制因子是有效的。当使用符合数据规模倒数的权重时,模型获得了最好的F1_score与正确率。通过对比模型在A、B数据集分类效果的差异,表明对于不同程度的数据不平衡问题Focal_Loss的贡献是不同的,类别规模相差越大,Focal_Loss的作用越明显,并且都超过了Bert模型。因此可以说,增加Focal Loss的模型是通用的。
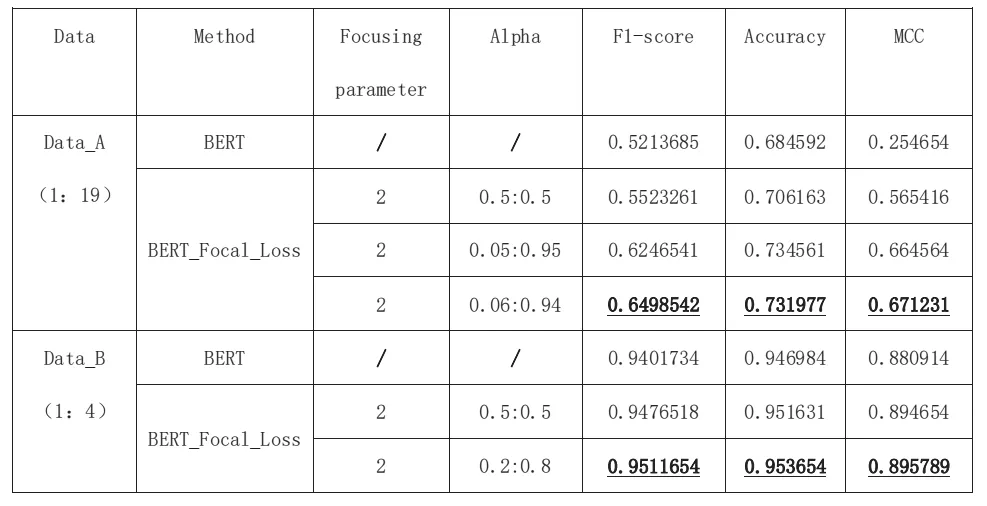
表1 实验结果Table 1 Experimental results
5 结束语
实验结果证明本课题的研究方法是行之有效的,且对电商评论的数据不平衡特性进行了有效的研究。根据训练结果来看,模型对于评论信息具有良好的情感分析效果,尤其对于正面评价的样本具有更高的预测正确率。而对于数据规模较小的负面评论样本,模型会出现一些轻微的分类错误的情况[21]。另一类错误情况则是当评论数据中同时包含两种情绪的观点的时候,模型可能会给出错误的分类情况[22]。
猜你喜欢
开放教育研究(2020年2期)2020-03-31
民族古籍研究(2018年1期)2018-05-21
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
现代语文(2016年21期)2016-05-25
新校长(2016年8期)2016-01-10
浙江大学学报(工学版)(2015年1期)2015-03-01
大连民族大学学报(2015年2期)2015-02-27
电测与仪表(2014年15期)2014-04-04
中国中医药现代远程教育(2014年16期)2014-03-01
