
基于不平衡数据的个人信贷违约测度探索
2021-03-17 09:49:52郭畅
集美大学学报(自然科学版) 2021年1期
郭 畅
(安徽大学经济学院,安徽 合肥 230601)
0 引言
信贷风险一直是商业银行不可避免的信用风险之一,然而信用风险管控对风险评级模型有较高的要求,2019年来,随着数字普惠金融模式“开放银行+”的推进,带来了个人、小微信贷业务的提升[1]。此时,随着数据量的快速增多,如何对抗不平衡数据的弊端,建立更加精确的信用风险违约预测模型,降低商业银行所遭受的客户信贷风险,在当今金融科技浪潮下更凸显其重要意义。信贷违约预测的目标是提前预知哪些客户更倾向于违约。然而违约事件的发生是少数的,收集到的信贷数据往往呈现出正负样本分布不平衡的结构。常用的机器学习算法往往建立在训练集各个类别数目分布比例大致均等的假设上[2-3],而在非平衡数据集中的表现一般较差。因此,如何处理不平衡的信贷数据集对风控模型精度的提升显得尤为重要。
随着人工智能第三次浪潮来袭,以神经网络、支持向量机和集成方法为首的机器学习算法越来越多地涌入信用风险评估领域。陈力[4]通过综合不同的采样方法,并结合集成学习算法和模型评价指标构建新的算法模型RHSBoost,将“数据”和“算法”两个方面结合来对银行信用评级的不同数据集进行分类预测并得到了不错的效果。古平等[5]在结合“数据”和“算法”的层面上提出AdaBoost-SVM-MSA算法,按照一定规则将SVM分错的样本划分为噪声样本、危险样本、安全样本三种类型,然后直接删除噪声样本,取安全样本进行SMOTE过采样,显著提高了模型分类准确率。董路安等[6]在文献[5]的基础上,运用“安全样本”消除噪声干扰,并将Weight-SMOTE方法应用于决策树模型中,提升了信用评级模型的可解释性,但对正负样本均进行同原数据比例的SMOTE抽样却忽略了信用评估数据的不平衡结构。李毅等[9]分别采取过采样[7]、欠采样[7]、SMOTE人工合成[8]的三种方法得到三个数据集,对处理后的三个数据集分别建立三个机器学习模型,并与未处理数据的三种模型结果进行对比试验,得出过采样结合随机森林模型评估的结果高于其他模型。陈启伟等[10]从欠抽样方法入手,从多数类样本中反复抽取和少数类样本量已知的样本组成多个子数据集,对多个数据子集建立模型并采用简单平均集成得到较好的预测性能。然而,文献[7-9]未讨论现有欠抽样方法上的改进效果,文献[10]未从子模型个数和模型评价效果方面进行研究。
结合上述文献的不足,本文同时从“数据”的修正和“算法”的改进入手,选择UCI真实业务场景的30 000条记录23个指标的台湾客户信用卡信贷数据,将“数据”和“算法”两个层面改进的Batch-US-RF集成模型、Batch-US-Xgboost集成模型与Batch-US处理后的单模型、未经Batch-US处理的单个集成模型,与单模型进行对比,并研究模型在不平衡信用卡信贷数据上的违约预测效果。
1 方法与模型
1.1 Batch-US-集成模型
批量欠采样(Batch-US)是基于随机欠采样(random under sample)方法造成的多数类样本信息缺失的改进,它对多数类样本采取多次欠采样,再和少数类样本组合成一系列新样本,来消除由于信息缺失带来的分类器分类效果不稳定的缺陷。首先,使用欠采样将多数类样本划分为多个部分,其中每部分与少数类样本数相同;接着,将这些数据和所有少数类样本组成新的子集;然后,对不同的训练子集建立差异化的集成模型;最后,将每折交叉验证的预测集预测其概率并进行简单算数平均后再组合。算法的整体结构见图1所示,其中本文训练的子模型分别选择随机森林和Xgboost,将所有子模型的输出概率的平均作为分类结果输出。
输入: 数据集D={(xi,yi),i=1,2,…,N,yi∈{0,1}}。0类(多数类)样本数记为Nm,1类(稀有类)样本数记为Ns,有Nm+Ns=N。

算法步骤:
1)将数据集D中的0类样本和1类样本分别记为Sm和Ss,k=ceil(Sm/Ss)进一取整;
2)forj=1,2,…,k,do;
3) 从1~(Ns-i+1)中随机抽样,取出对应序号的样本x′;
4) 在类0样本中取出所选样本Ss=Ss-x′;
5) 随机欠采样后的数据集{Dj′=(xi,yi),i=1,2,…,N-Ss·RS/(RS+1),j=1,2,…,k,yi∈{0,1}},RS表示采样比率;
6) 对每个Dj′训练一个子模型,记hj(x);
7)end for;

1.2 子模型确定
1.2.1 随机森林模型
集成学习模型有两个重要的方面——基于Bagging的集成模型和基于Boosting的集成模型。基于Bagging的集成模型是将多个有差异的分类器取平均,能够解决一定程度上的模型不稳定问题。随机森林(random forest,RF)作为典型的Bagging类模型,可和采样技术结合被用于解决类不平衡问题。本文就是利用样本采样技术构造平衡随机森林[11],并对随机森林的预测结果再次组合。
随机森林是基于Bagging的集成学习方法,它采用bootstrap自助抽样从数据集中抽取多个子样本,对抽样后的子样本分别建立具有差异性的CART决策树模型(每个模型随机选取m个特征,本文选择使模型误差最小的m),最后对每个分类器的预测结果进行组合,组合方法采用多数表决(投票法),算法的流程如图2所示。
1.2.2 极限梯度提升模型
基于Boosting的集成模型Xgboost[12]使用贪心算法和加法模型,每次构建一个当下最优的树模型,将所有树模型的最终结果求和作为最终的预测结果。其优点在于GBDT算法的求解采用了二阶梯度,并加入了正则化项,由于树模型容易过拟和,因此通过同时控制模型损失函数和模型复杂度得到更优结果。模型的原理和推导见文献[10]。当基模型同样选择树模型时算法的流程如图3所示。

2 研究设计
2.1 指标类型
本文数据源于UCI机器学习网站(http://archive.ics.uci.edu/)公布的台湾客户信用卡信贷数据集,3万条样本数据包括来自三个方面用户信息的23个指标数据。其中:正常客户占数据的77.88%,违约客户占22.12%;人口统计学特征的用户基本属性信息指标包括性别、年龄、教育程度、婚姻状况等4个变量;金融特征的借贷相关信息指标包括月还款情况、月账单、月支付金额等19个字段。由于数据存在错误值和离群值。对数据进行简单预处理后,具体的数据说明见表1。
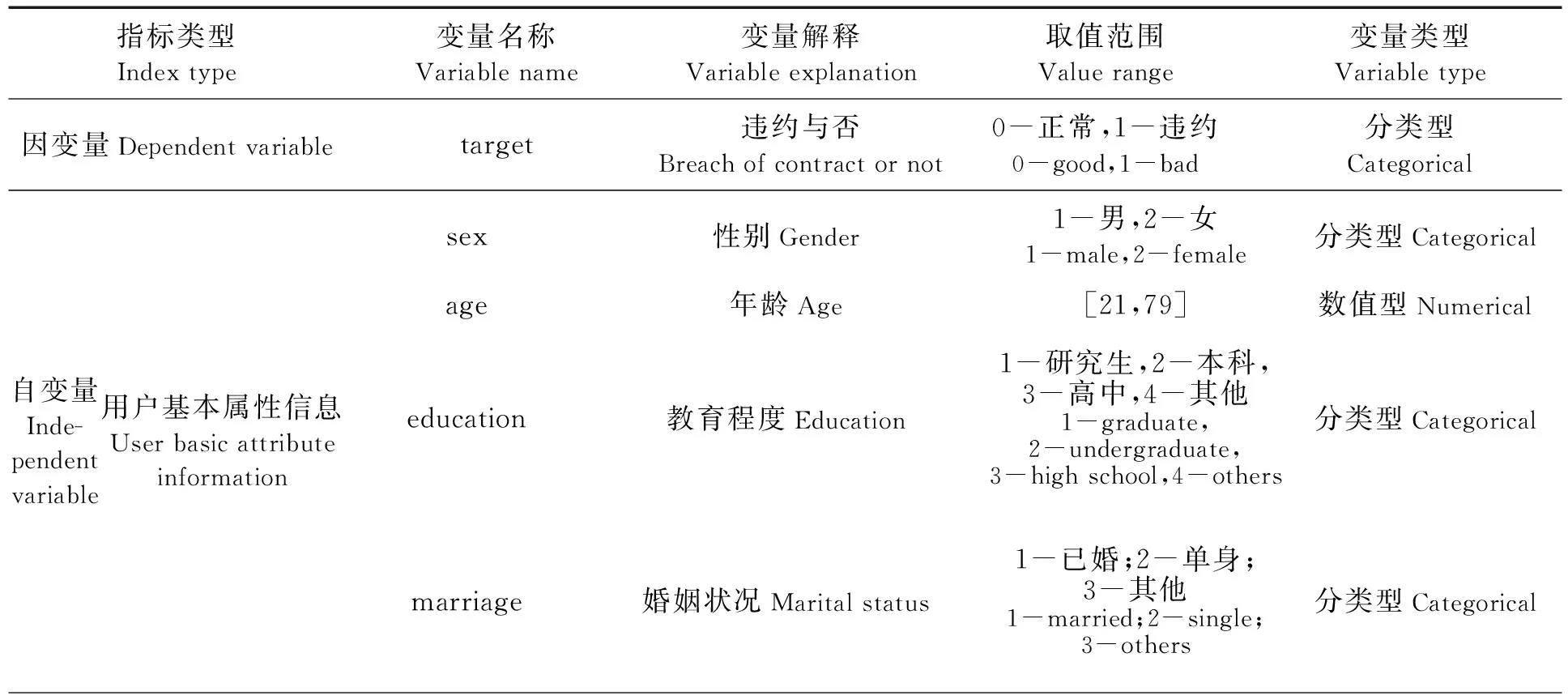
表1 变量说明表

续表
2.2 模型建立与评价
2.2.1 评价指标
对于本文正负样本比例约3.5∶1的不均衡的数据集,传统的基于准确率的模型评价指标已经不再适用[13-14]。基于此,本文选取F1指标和ROC曲线下面积AUC来评价模型的预测精度,用KS值(kolmogorov smirnov)[15]检测实际风控模型的好坏。KS取值越接近1则模型区分度越高,预测能力越强。模型评价指标由表2混淆矩阵计算得出,指标计算公式为:查准率P=NTP/(WTP+NFP);查全率R=NTP/(NTP+NFN);F1=2×precision×recall/(precison+recall)。
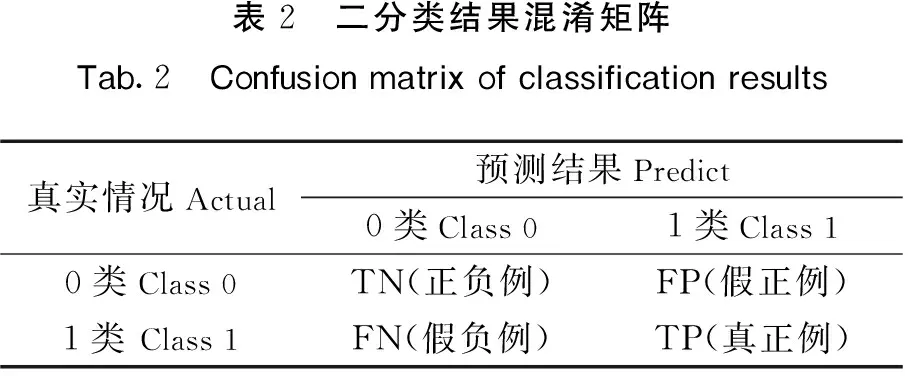
表2 二分类结果混淆矩阵Tab.2 Confusion matrix of classification results真实情况Actual预测结果Predict0类Class 01类Class 10类Class 0TN(正负例)FP(假正例)1类 Class 1FN(假负例)TP(真正例)
2.2.2 模型建立和评估
由表1变量说明可见,本文选用的客户信用卡信贷数据间量纲差别较大,需要对数据进行标准化处理。本文为了更好地进行模型评估,增强模型稳定性,对每个模型分别进行5折交叉验证(模型如表3所示)。对于本文不平衡的信用卡信贷数据,经阈值调优,对未经平衡处理的数据阈值设定为0.45,处理后的数据阈值设定为0.55。
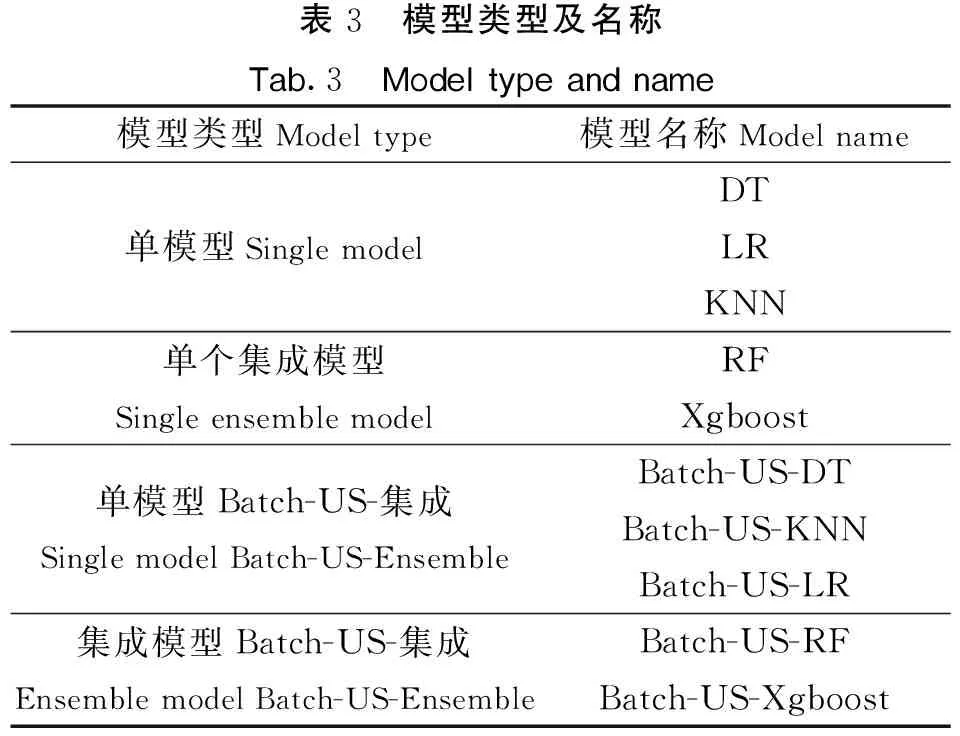
表3 模型类型及名称Tab.3 Model type and name模型类型Model type模型名称Model name单模型Single modelDTLRKNN单个集成模型Single ensemble modelRFXgboost单模型Batch-US-集成Single model Batch-US-EnsembleBatch-US-DTBatch-US-KNNBatch-US-LR集成模型Batch-US-集成Ensemble model Batch-US-EnsembleBatch-US-RFBatch-US-Xgboost
由于树模型容易过拟和,本文对选择的每个树模型进行参数调优(见表4),并在Batch-US模型集成过程的Rstudio中构建ovun.sample随机欠采样函数,通过设置seed随机种子的不同,对每一折交叉验证数据构建多个随机欠采样子样本,得到多个平衡子样本,再加上参数调节,使每个子模型更具差异性,从而增加集成模型的泛化能力。其中对Batch-US改进的模型分别构建10个差异性的子模型。
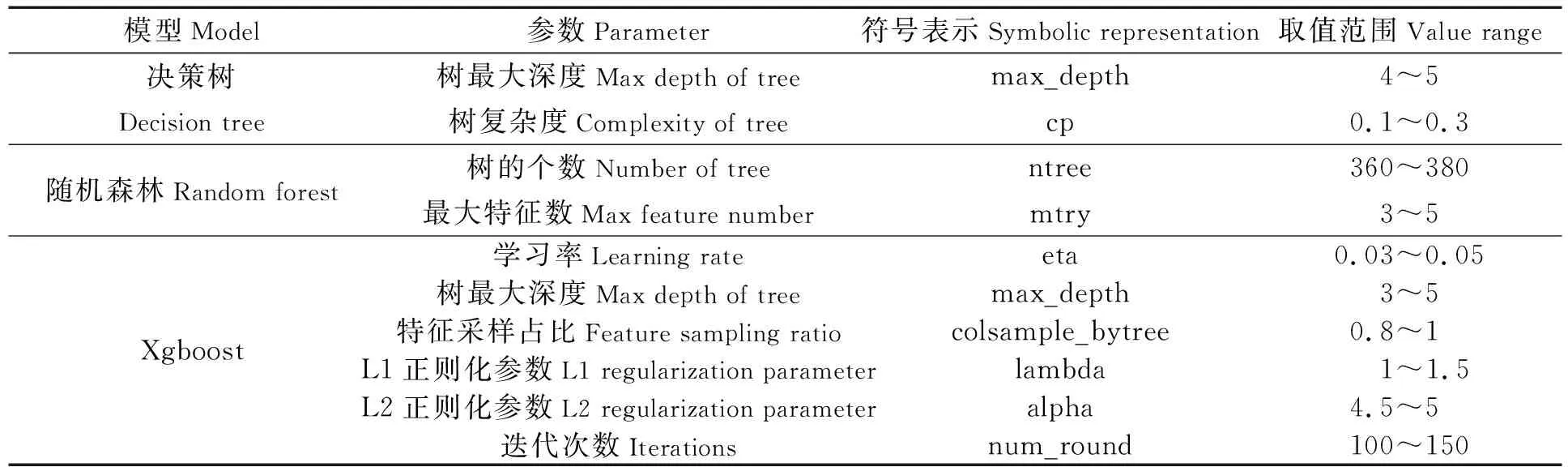
表4 树模型调优参数及范围
本文对文献[10]中的评价指标进行改进,基于准确率对不平衡数据的缺陷,选择用F1值衡量模型精度,用AUC值评估模型的优劣,用KS值衡量模型的稳健性和风控能力。将10个模型经五折交叉验证后的预测指标平均,汇总至表5。

表5 模型结果汇总
由表5模型结果可知,不管是单模型还是集成模型,在通过本文的Batch-US批量欠采样集成后,在F1值、AUC值和KS值3个评价指标上都有明显的提升。在本身就较优的集成模型上更能进一步提升模型的表现能力。Batch-US-RF模型的F1值、AUC值和KS值分别比改进前提高了3.57%、1.29%、1.61%;Batch-US-Xgboost模型的F1值、AUC值和KS值分别比改进前提高了7.11%、0.4%、0.66%。Batch-US-集成模型的精度衡量指标F1值和AUC值都是10个模型中最优的,并且观察其区分度指标KS值也大于0.4且排名在10个模型中前三,说明模型风控能力较好。
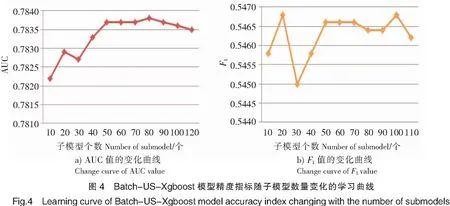
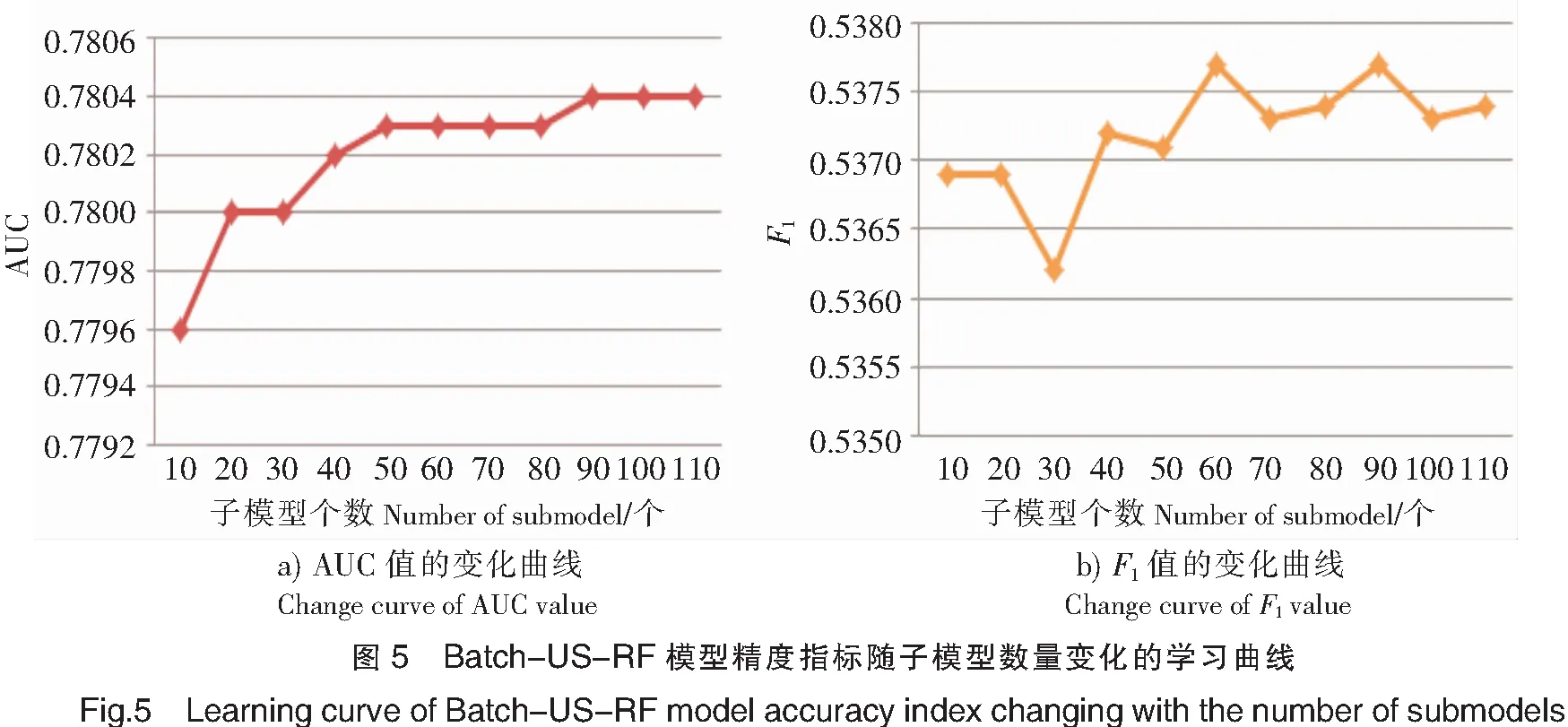
表5评价指标结果均为本模型数量选择k=10的结果。为了进一步研究子模型数量是否对模型精度造成影响,本文将两个Batch-US-集成模型通过设定子模型数量k为10,20,…,110时的模型评价效果绘制学习曲线,如图4、图5所示。
由图4、图5可知,Batch-US-Xgboost模型通过增加子模型数量,其F1值和AUC值在一开始的确有一个上升幅度,但是随着模型不断增多,这三个评价指标均先趋于稳定而后随子模型个数上升甚至出现轻微下降趋势。Batch-US-RF模型通过增加子模型数量,其AUC值在一开始的确有一个上升幅度,但是随着子模型不断增多AUC值趋于稳定;其F1值在前60个模型的整体趋势不断上升,但是在60个子模型后围绕一个固定值波动(认为其趋于稳定)。因此,子模型数量并非越多越好,两个Batch-US-集成模型的子模型数量在60个左右能够取得AUC和F1指标的较优和模型较稳定的结果。
3 结论
本文使用UCI台湾客户信用卡信贷数据,分别对数据进行单模型、集成模型和Batch-US处理后建模。由表5可以看出,基于欠采样改进的Batch-US-集成模型的建模结果明显优于处理之前的数据建模结果。由于在风控模型中千分之一的精度改变带来的影响也是巨大的,对不平衡数据的处理具有较大意义,本文进行Batch-US集成后模型的确提升了模型预测效果,且Batch-US-集成模型总能表现出更好结果。
该系列模型从“数据”层面使用批量欠采样处理修正了随机欠采样的弊端,从“算法”层面对多个模型采用简单平均集成增加了分类器的稳定性。通过实证分析,结合模型评价指标,验证了Batch-US-RF和Batch-US-Xgboost模型不管从模型精度、综合效果方面还是从实际风控效果方面都具有较高的表现能力,尤以Batch-US-Xgboost模型有效性和精度最高。本文通过绘制不同子模型个数和模型评价指标的学习曲线,得出结论:对于Batch-US-集成模型并非子模型数量越多越好,子模型的数量可以根据模型复杂度和不同评价指标的倾向性进行选择。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
计算机应用(2018年12期)2019-01-08 01:55:48
商周刊(2018年26期)2018-12-29 12:56:00
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
