
基于领域自适应方法的统计机器翻译模型的优化研究
2021-03-17 07:41:28杨玲
科学技术创新 2021年5期
杨玲
(武警工程大学,陕西 西安710086)
1 概述
把一种语言转变成另一种我们想要的语言这一过程称为机器翻译[1]。其中比较常用的方法有基于记忆的翻译方法、基于实例的翻译方法、基于统计的翻译方法、基于神经网络的翻译方法。目前,基于统计的机器翻译模型被称为这一领域的主流方法,是由Brown[1]等人提出,该模型可分为翻译模块、语言模型训练模块、解码模块。在进行翻译模型训练时需要进行词对齐,由于统计机器翻译模型在训练词对齐模型时未对训练集进行分类训练,会影响系统的翻译性能。因此,本文提出运用最大熵分类器及领域自适应方法对统计机器翻译模型进行优化,旨在进一步改善模型的翻译性能。
2 统计机器翻译模型的优化策略
传统统计机器翻译方法的系统原理是,用已对齐好的大规模平行语料训练词对齐模型,然后基于此词对齐模型建立翻译模型和语言模型并训练模型参数。但是训练模型的平行语料来自不同领域,有些词在不同领域意思也不用,这会影响模型参数的准确度,基于此建立起的翻译模型和语言模型精确度也会下降,由此得到的译文不够准确。为解决这一问题,我们运用领域自适应方法提高统计机器翻译模型的翻译精度,即首先应用最大熵分类器的方法对平行语料进行筛选,这一步保证了训练词对齐模型的语料符合标准,从而确保了模型参数的精确度。接下来可以运用LDA 模型对双语平行语料进行主题提取,并得到每个主题对应的语料。然后对每个主题训练其相应的词对齐模型,再训练每个主题的翻译模型和语言模型。
语料可以划分为完全平行句、部分平行句对和完全不平行句对。通过观察可以发现,高质量平行句一般会呈现很多共性:源语言和目标语言互译准确、源语言和目标语言都比较流畅,基于此特征可以提出使用句对特征评价平行句对质量,利用分类器进行自动判别句对质量好坏的方法。该过程可分为两部分,第一部分是挑选用于训练分类器的正负例句对,首先确定句对特征,依据句对在各个特征上的得分对句对进行排序。综合各个排序的结果,构造区分性较大的训练句对集合。将那些在各个特征中表现均不好的句对作为负例句对。余下的句对为待分类句对,需要训练分类器自动分类。第二部分利用前一部分构造得到的正负例句对集合训练一个最大熵分类器,通过学习正负例句对的特征,分类器可以自动地对句对进行质量判定。然后使用该分类器对第一部分的待分类句对进行自动分类。在分类器的选择上,本文采用最大熵模型作为分类器进行分类任务。

图1 基于分类的平行语料选择方法流程图
2.1 基于最大熵分类器的平行语料筛选
统计机器翻译模型需要用到大规模的双语平行语料进行训练,因此语料的质量会影响模型的翻译性能。所以需要对训练语料进行筛选,淘汰影响系统翻译质量的语料,保留质量较好的语料进行训练,这样可以从源头上确保系统翻译质量。本节利用最大熵模型分类器[2]对待训练语料进行分类,语料可以分为完全平行句对、部分平行句对、和不平行句对,因此我们的任务是可以从这些大规模的平行语料中找到完全平行句对,用这些来训练模型。首先,我们需要选择训练分类器的正负例句,依据每个句对在句对特征的得分来区分正负例句,将得分高的作为正例句,得分低的作为负例句,通过对正负例句的学习,分类器可以对句对进行质量评定,从而使用训练好的分类器对语料进行筛选。
筛选流程:筛选语料有以下五个关键的环节:
(1)句对特征打分。在训练语料中的句对进行特征得分计算;
(2)句对排序。在上一环节的基础上,依据每个句对的得分情况进行排序,在此,每一个特征对应都有一个排序结果。
(3)分离器训练。
(4)分类器自动分类。使用分类器对待分类句对进行分类,然后将分类结果和训练分类器句对进行融合,得到最终的分类结果。
2.2 主题模型
为了提高系统的翻译性能,本文利用LDA 模型[3]挖掘双语语料中的领域信息,从而应用到该领域翻译模型的搭建中,以提高参数精确度。LDA 模型是一个三层贝叶斯模型[4]。
LDA 模型:
David Blei[3]在2003 年提出隐含狄利克雷分配,这是一种用于离散数据集合的建模方法,它可以自动地完成挖掘大规模语料库中所蕴含的主题信息。LDA 模型首先基于一篇文档,这个文档要求由许多主题组成,LDA 模型将这个文档看作是这些主题的不同比例的混合,每个主题是指词表中的一个多项式分布。
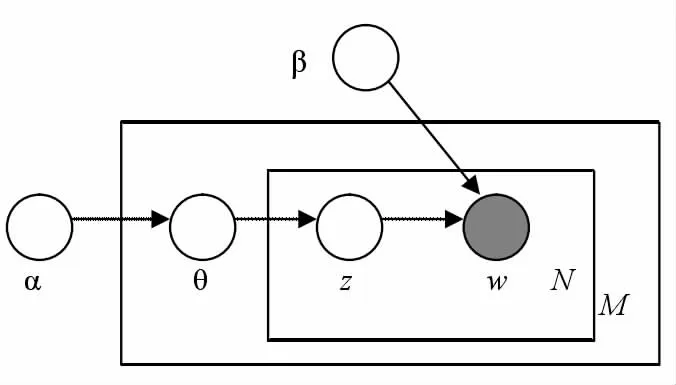
图2 LDA 概率模型
2.3 领域自适应方法下词对齐模型原理解析
由于训练翻译模型的语料种类较多,对于这种异源的数据进行词对齐模型训练,再搭建翻译模型,这会导致翻译的准确率下降。比如古汉语短文中有关于医学的文章,也有关于军事战争的文章,如果我们不对这些异源的数据进行领域区分,这样就会大大降低我们翻译准确率,因此在训练词对齐模型时,首先要考虑领域这一特性[4]。但是,不同的领域虽有本领域特有的词语,但是也会有领域之外的词汇,这一点可以看出领域之间既有共同点也会有不同点,但是我们不能简单的将不同领域划分为互无交集的几个部分分别去训练词对齐模型,这会造成信息丢失,准确率下降。因此,为了使得词对齐准确率提高,将在统计词对齐模型中引入领域的信息。即对于训练语料的每个句子首先通过LAD 模型得到其所属领域的概率,接下来结合领域内与领域外的词来进行词对齐。即通过加权技术来实现领域内模型与领域外模型相互结合来提高领域内的词对齐准确率[5]。

领域自适应词对齐的训练过程指:假设双语平行语料库由s 个句对组成,首先用LAD 模型对语料库领域信息进行提取,则假设某一句对(f,e)属于某一领域的概率为pk[6],则接下来为每一领域训练相应的词对齐模型,训练过程用EM算法进行参数估计:在E 步,两个词共同出现在频率:
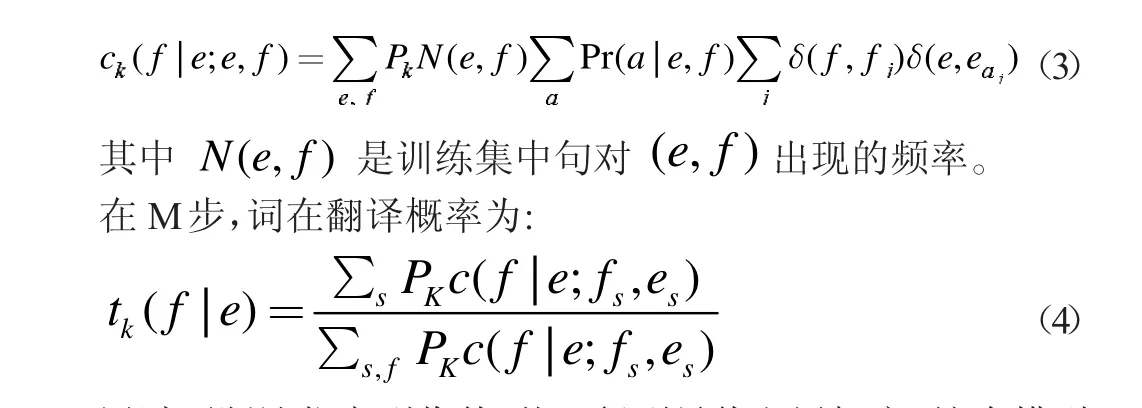
通过不断迭代直到收敛,从而得到最终翻译概率。这个模型中,当一个句对属于某个领域的概率越大,则词对齐结果就会属于当前领域,最终在此基础上相应的翻译模型,则该模型能够呈现出所属领域准确率最高的结果。
3 结论
本文主要介绍了统计机器翻译模型的改进方法,首先运用最大熵分类器的方法,对训练统计机器翻译模型的语料进行筛选,提升了语料的准确性。接下来对筛选的语料运用LDA 主题模型确定了语料的主题,在统计机器翻译模型词对齐的过程中对每个进行词对齐过程的句子结合其对应的主题概率,从而使行词对齐的结果更精确,进而提升了统计机器翻译模型中翻译模型与语言模型的精度,使得统计机器翻译模型性能有了一定程度的提高。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
思维与智慧·上半月(2022年4期)2022-04-08 21:24:29
小哥白尼(神奇星球)(2021年4期)2021-07-22 03:17:22
少年博览·初中版(2018年12期)2018-01-18 09:17:58
海外华文教育(2016年1期)2017-01-20 08:21:58
小天使·一年级语数英综合(2016年4期)2016-11-19 10:22:17
小天使·一年级语数英综合(2016年6期)2016-05-14 12:21:05
汽车观察(2016年3期)2016-02-28 13:16:36
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
小天使·一年级语数英综合(2015年10期)2015-10-14 06:30:06
