
XGBoost算法在二分类非平衡高维数据分析中的应用*
2021-03-16 10:18哈尔滨医科大学卫生统计学教研室150081
中国卫生统计 2021年1期
哈尔滨医科大学卫生统计学教研室(150081)
卢娅欣 黄 月 李 康△
【提 要】 目的 探讨XGBoost算法在二分类高维非平衡数据中的分类判别效果。方法 通过模拟实验及真实代谢组学数据分析,对XGBoost、随机森林、支持向量机、随机欠采样以及随机梯度提升树共五种方法进行比较。结果 模拟实验显示,XGBoost算法在数据非平衡较明显时,在各种实验条件下均优于或不劣于其他四种算法,在数据类别趋于平衡的情况下也同样具有较好的分类效果,且对噪声变量具有一定的抗干扰能力。实例分析显示,与其他四种算法相比,XGBoost算法的分类性能最优,且在保证分类效果的基础上具有更快的运算速度。结论 XGBoost算法适用于非平衡高维数据的判别分析,值得研究。
在对高维数据进行分类或判别时,数据的类别间常存在非平衡的现象,而各类之间的例数相差较大常会对判别效果产生影响[1]。而如何对非平衡数据建立预测模型进行分类是一个较难解决的问题[2]。目前对非平衡数据的处理主要在数据及算法两大层面。数据层面的基本思想是应用重采样技术使各类别的分布达到平衡,再使用传统分类器进行分类判别,常用的方法如随机欠采样、随机过采样以及Chawla等人[3]提出的合成少数类过采样技术(SMOTE)等。算法层面以代价敏感学习(cost-sensitive learning)、一分类学习(one-class learning)以及集成学习(ensemble learning)为主,其中boosting作为一种强大的集成学习算法,以算法集合的思想将基础弱分类器转换为优效分类器,已被证明可对各种不规则的数据类型显示出良好的分类效果[4]。极端梯度提升算法(extreme gradient boosting,XGBoost)是近年来一种基于boosting的新算法,具有运算速度快、效果好等特点[5]。本文在介绍XGBoost算法原理的基础上,通过模拟实验及实例分析,比较并考察它与其他处理非平衡数据常用方法的分类效果。
原理与方法
1.XGBoost的目标函数
boosting是一种集成学习算法,其主要思想是将许多弱分类器集合在一起,形成一个强大的组合分类器以提高分类精度,主要算法有自适应增强(adaptive boosting,Adaboost)与梯度提升树(gradient boosting decision tree,GBDT)[6]。XGBoost是GBDT的一种优化算法,是将许多CART回归树模型集合在一起形成一个强分类器。其算法步骤如下:
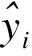
(1)
其中,f(x)表示一棵CART回归树,wk是第k棵回归树的叶子权重,q(x)是叶节点的编号,即样本x最后会落在树的某个叶节点上,其值为wq(x)。

(2)

(3)对损失函数进行泰勒二阶展开近似原函数并移除常数项,则:
(3)
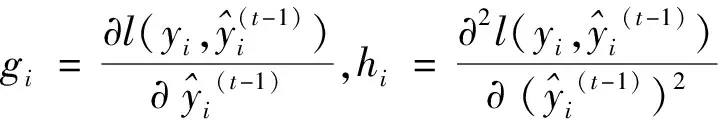
(4)
(4)定义Ij={i|q(xi)=j}作为叶节点的实例集,将公式(1)代入公式(3)中,整理可得:
(5)
(6)
2.寻找最佳分裂点的近似算法
XGBoost使用近似分位点算法,通过对特征值进行排序[8],在既定误差ε和序列大小N的情况下可以以εN的精度来计算任意分位,同时还可用原序列的一个子集代替全集以减少数据量。XGBoost通过对该算法增加权重,提出了加权分位数略图(weighted quantile sketch),同样是在训练前对数据排序来列举数个候选分裂点,同时将位于相邻分位点间的样本以“块”的结构储存到内存中,可在串联进行的迭代过程中重复使用。在选择增益最大的特征进行节点分裂时,也可使各特征的增益计算并联进行。模拟实验表明,该算法较传统的boosting算法可提高计算速度10~50倍。
模拟实验
本模拟实验以基于树的模型构建XGBoost算法模型,旨在考察XGBoost对非平衡数据的分类判别效果,并将其与典型的传统分类器如随机森林(RF)、支持向量机(SVM)以及处理非平衡数据常用的随机欠采样(random under-sampling)和随机梯度提升树(stochastic gradient boosting based trees,SGBT)算法[9]进行比较。
该模拟实验考察二分类数据在不同非平衡率(imbalanced ratio,IR)、不同大小的真实区分度θ(ROC曲线下面积)及不同数量噪声的情况下五种算法的判别能力。具体步骤如下:
(1)设定20个服从正态分布X~N(μ,1)的差异变量,训练集和测试集样本量各占50%,均为400例,分别设置非平衡率(IR)为1/19、1/9、1/4和2/3。
(2)设定两类间的真实区分度θ为0.85和0.95两个水平,并另设定500个噪声(均数为0,方差为1);数据间的相关性均简单设定为0。
(3)分别使用上述五种算法对训练集建模100次,再用训练好的模型对测试集做判别预测,最终各评价指标的结果取100次计算的均值(表1)。五种算法在各实验条件下的AUC值分布见图1和图2。

表1 五种算法在不同情况下对模拟数据的分类效果AUC均值
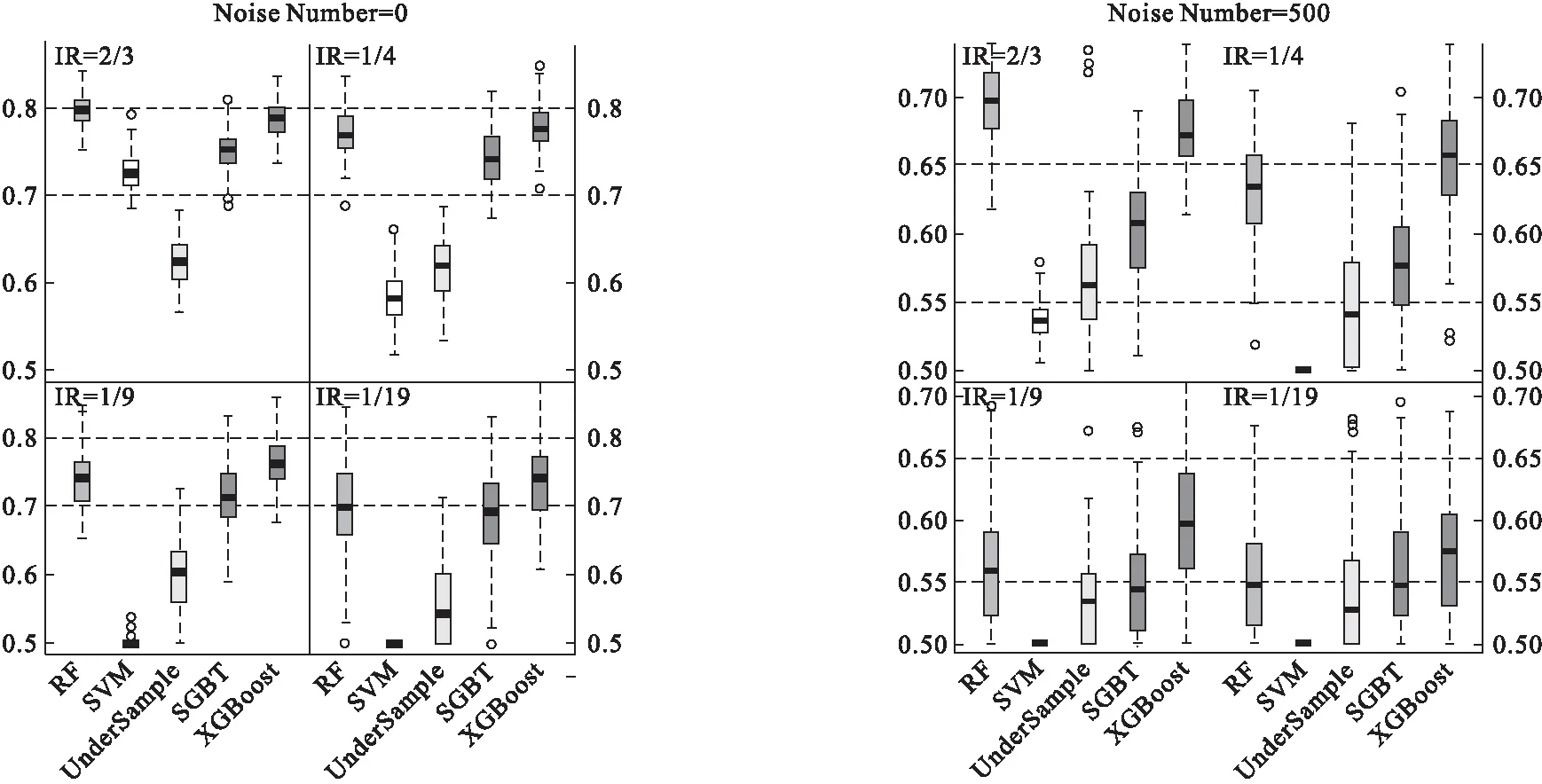
图1 真实区分度θ=0.85时各算法的分类效果AUC值
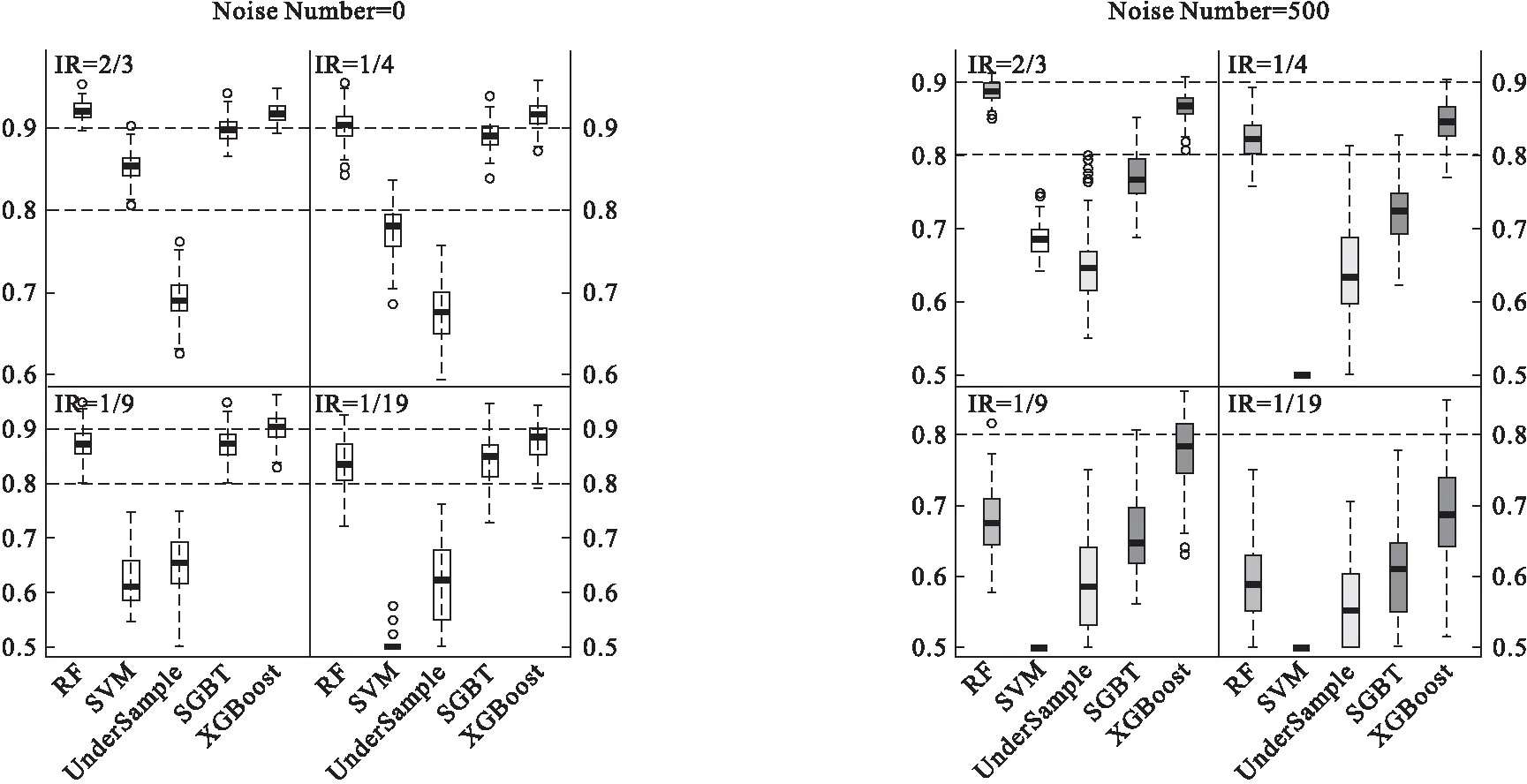
图2 真实区分度θ=0.95时各算法的分类效果AUC值
由图1和图2可知,在各种不同的条件下,非平衡较严重时(非平衡率IR<2/3),XGBoost算法的分类效果均优于其他算法,而在接近平衡的状态时(IR=2/3),XGBoost的AUC值略低于效果最佳的RF算法。当噪声数量由0增加到500时,XGBoost的分类效果仍优于其他算法,说明该算法对噪声变量具有一定的抗干扰能力。
实例分析
选取同一批次检测的大肠癌(CRC)患者和炎性肠病患者的血浆代谢组学数据进行研究。该数据共包括662个代谢物和644例样本,其中大肠癌组571例,炎性肠病组73例,非平衡率为12.8%。经过变量筛选后(取VIP>1.1且FDR校正后的P值<0.05),剩余68个代谢物。使用无放回的随机抽样,分层抽取每一类别的50%样本作为训练集,剩余50%作为测试集,并重复100次。使用XGBoost算法和其他四种算法对未筛变量及变量筛选后的组学数据分别建模训练,得出各模型预测的AUC值以及灵敏度、特异度(根据约登指数最大选取诊断阈值)。各算法的分类判别结果分别见表2和表3。

表2 五种算法在662个变量时CRC的分类判别效果

表3 五种算法在筛选出68个变量时CRC的分类判别效果
分析结果显示,XGBoost在无论变量筛选与否的情况下均具有良好的分类判别效果,证明其在高维数据判别领域广泛应用的可行性,可为临床疾病诊断与癌症筛查提供一定帮助。
讨 论
XGBoost是一种基于boosting思想的新算法。该算法在传统梯度提升树的基础上,加入了正则项以控制模型复杂度,减少过拟合。同时XGBoost对损失函数进行泰勒二阶展开以近似原函数,因此损失函数只需满足函数二阶可微。该算法中所使用的加权分位数略图可快速生成可保证精度的候选分割点,且在模型训练前预先保存了排序后的数据特征,以支持在迭代中高效反复利用,从而大大提高了运算效率。
模拟实验结果显示,在数据非平衡较严重的情况下(如IR<1/4),XGBoost算法在各种实验情况下均可取得最优的分类效果,并且对噪声也具有一定的干扰能力。其他模拟实验显示,当训练集两个类别的样本量由两类均为100例的完全平衡状态增加信息量至300例与100例的非平衡状态时,相比其他分类器,XGBoost可以克服非平衡造成的影响从而表现出更好的分类效果。实际代谢组数据分析结果显示,相比于其他四种算法,XGBoost在有无变量筛选的情况下判别效果均相对最优。以上结果均说明XGBoost算法对处理非平衡数据具有明显优势。
XGBoost算法的其他特点还包括可以进行特征选择、自动学习缺失值的分裂方向以处理缺失值等。同时,本研究中该算法的损失函数使用的是机器学习常用的均方误差(MSE),在实际应用中也可以根据数据的特点选取其他二阶可微的函数。
猜你喜欢
数学杂志(2022年4期)2022-09-27
石油地质与工程(2019年3期)2019-09-10
测控技术(2018年4期)2018-11-25
材料科学与工程学报(2016年2期)2017-01-15
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中国海上油气(2015年3期)2015-07-01
弹箭与制导学报(2015年1期)2015-03-11
应用数学与计算数学学报(2014年3期)2014-09-26
电测与仪表(2014年15期)2014-04-04
