
基于多步的多分类器在入侵检测中的研究
2021-03-16 13:29江泽涛马伟康
计算机应用与软件 2021年3期
江泽涛 马伟康
(桂林电子科技大学广西图像图形与智能处理重点实验室 广西 桂林 541004)
0 引 言
网络的快速发展带来了巨大的便利,同时也带来了一系列安全问题,如何提高网络的主动防御能力、增强网络的安全性成为了研究热点。入侵检测[1]的概念于1980年就已经被提出。随后便出现了入侵检测系统[2],并成为了网络安全中的一道重要防线。
机器学习的出现使得网络安全得到了极大的发展。机器学习中的分类算法能够应用到入侵检测[3-5]当中,识别“正常”和“非正常”信息,将机器学习引入到入侵检测当中极大地推动了入侵检测系统的研究。由于网络需要及时响应的特点,因此必须要提高入侵检测算法的准确度和效率。文献[6]使用SMOTE对数据进行平衡处理,之后在处理后的数据上使用GBDT算法进行分类。文献[7]利用不同的离散化与特征选择算法生成具有差异的多个最优特征子集,并对每个特征子集进行归一化处理,用分类算法对提取后的特征进行学习建模。文献[8]提出模型决策树,该方法具备一定的抗过拟合能力,但在处理缺失数据时存在一定的困难。文献[9]是针对一种新颖的攻击方法,该攻击方法是篡改训练数据,导致支持向量机在建模过程中学习到了错误的数据,使得入侵检测系统的检测率降低,通过获取该攻击样本,提出使用支持向量机解决该类型攻击。文献[10]提出了一种将K-means和随机森林结合的方法,首先对数据进行预处理,再对处理后的数据使用K-means方法进行聚类操作,最后使用随机森林对数据进行分类操作,在一定程度上提高了准确率并且减少了训练时间。上述方法在处理入侵检测过程中对多种数据类型的数据集都采用单一的分类器,而单一的分类器并非对每种类型数据的分类的效果都是最好的。
针对多数据类型检测问题,本文提出了一种基于多步的集成分类器方法,该方法通过对数据进行预处理和降维操作,去除数据中冗余特征,减少噪音数据对分类结果的影响。使用处理后的训练集构建多种分类器,完成训练后,检验各个分类器的性能,选出针对每种类别中分类效果最好的分类器,使用多步分类完成对多类别数据的分类。
1 多步分类模型及实现
1.1 多步分类模型图
现代网络传输数据中总是混杂着多种类型的数据,不同类型的数据之间或有很大差异或又十分相似。对于差异很大的数据,在分类时相对容易,并能得到不错的分类效果。但对于相似的数据,则较难分类或者易错分类,因而较难得到很好的分类结果。本文使用的KDD CUP99 10%数据集数据分布如表1。
分析KDD CUP99 10%训练集,可知DoS类型的数据占总训练集约80%,建立DoS的分类器模型时可以得到很好的拟合效果。但R2L和U2R分别只有52条和1 126条记录,并且这两个类型的数据和Normal的数据很相似,为此先将U2R和R2L合并为一种数据类型,再提出多步分类模型,该模型在进行多步分类时遵循以下原则:(1) Normal是正常类型数据,将各种攻击类型分离出后,剩余的数据便是Normal类型,将其最后分出是为了避免过多的攻击数据被误检为正常数据。(2) 其余数据的分类顺序按照模型拟合度依次将不同的数据类型分类出来。根据以上两条原则可知Normal应该最后被分离出,其余类型数据的模型拟合度由高到低分别为DoS、Probe、R2L、U2R。
数据分类步骤如下:1) 对数据进行预处理,预处理操作包括数据标准化[11]和特征选择。2) 选取对DOS类型数据分类效果较好的分类器1对预处理后的数据进行分类操作,此时得到DoS类型的数据和Rest1(剩余部分)数据,此时Rest1数据中还混杂有Probe、R2L、U2R和Normal四种类型的数据。3) 选取对Probe类型分类效果较好的分类器2,对Rest1数据进行分类,分类完成后得出Probe类型的数据和Rest2数据,此时Rest2数据中混杂有R2L、U2R和Normal三种类型的数据。4) R2L和U2R这两种类型的数据较为相似本文中将R2L和U2R作为相同的类型的数据,选取对Normal类型数据分类效果较好的分类器3,完成分类操作后得到Normal类型和R2L、U2R类型的数据,完成分类操作。
使用该方法会在每次分类过程中经过对比选取对某一类型最优的分类器,这种操作会得到更好的分类效果。针对入侵检测系统多步分类模型图如图1所示。

图1 多步分类模型图
1.2 改进的特征选择方法
在高维的数据中总是存在一些冗余的特征,这些特征会使一些分类器产生过拟合现象并且对分类结果产生较大的影响。对数据进行特征选择[12]可以降低数据复杂度,减少数据噪声对分类结果的影响,使得模型泛化能力更强,预防过拟合问题,增加模型可读性。根据特征选择的形式又可以将特征选择方法分为:过滤法(Filter)、包装法(Wrapper)和嵌入法(Embedded)3种。本文使用Embedded式特征选择中的基于学习器的特征选择方法。
Embedded式特征选择是将特征选择过程与学习器训练过程融为一体,两者在同一个过程中完成。在基于树的特征选择方法中,使用基于树的预测模型可以用来计算特征的重要程度,因此可以用来消除不相关的特征。基于树的模型是使用基尼系数或者均方差对特征进行选择,而在最近邻模型中是通过计算特征之间的距离对数据进行分类。为了增强选出特征的普适性,本文使用多种机器学习模型(支持向量机、决策树、随机森林等)进行特征选择,对每种模型得出的结果按照特征重要性由高到低排序,选出特征中对分类结果影响较大的特征。但学习器在选择特征过程中存在着不同学习器打分不一定相同的现象,因此使用相对投票法即预测为得票最多的标记,若同时有多个标记获最高票,则从中随机选取一个选取排名较高的特征。
(1)
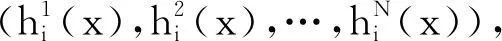
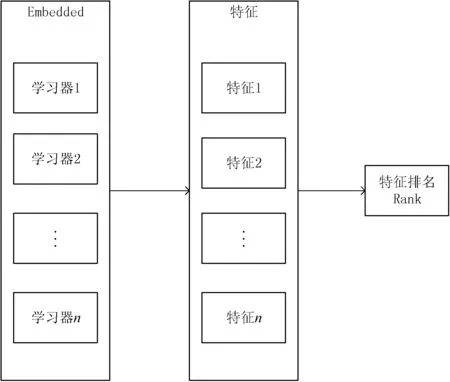
图2 特征选择模型图
本文选用多种学习器并进行多次实验,对每种类型的数据都单独进行特征选择,避免不同特征对不同类型的数据产生的影响不同,因此分别对本文中四组类型的数据分别进行特征选择,得到对每种类型分类效果最好的特征。选取出现频率最高的一些特征,有利于增强被选出特征的普适性。
1.3 改进的Bagging学习器
Bagging[13]是在样本数量为M的原始训练集中随机且有放回地抽取样本数量为N的子训练集,构成n个样本空间,每个样本空间的总样本数N总是小于原始训练集的样本数量M,使用抽取出的子训练集构建估计器,把这些估计器的预测结果结合起来形成最终的预测结果。因此Bagging具有较强的泛化能力,能够有效地降低模型的方差,但对于训练集的拟合程度较差,也就是模型存在较大的偏倚。
在进行多步分类过程中,选择Bagging分类器对Normal、R2L、U2R数据进行分类时存在结果不稳定的现象。分析后发现,在KDD99训练集中R2L和U2R的数据量分别为1 126和52条,而Normal的数据量多达97 278条,Bagging分类器采用有放回的随机取样方法,在取样得到的子训练集中可能只包含极少的R2L和U2R数据甚至无法取到R2L和U2R数据,因此造成分类结果不稳定。本文改进Bagging取样方法,按照比例有放回地随机抽取各个类型中的样本,得到较为平衡的子训练集,保证每次取样都能完整地将每种类型的样本包含到子训练集中,这种改进有利于减少模型的偏倚问题,使分类结果较为稳定。将改进后的Bagging称为B-Bagging(Balance-Bagging)。取样方法如下:
(2)
式中:k为某类型样本中所要选出的数据量;n为某类型样本中总的数据量;N为整个样本集中的数据量;P为子训练样本的总数据量。
1.4 多步分类实现
使用多步分类算法需要对数据进行多次分类操作,在每次分类操作时选取分类器对分类结果有着很大的影响。对不同类型的数据选择合适的分类器对分类结果有着积极的影响,能提高分类准确率。
设训练集T={x1,x2,…,xn}每个样本为42维,包含41个特征和最后一列数据标签。数据标签共有4类(U2R和R2L合并为1类),在建模时需要选取每种标签进行建模。多步分类算法的实现如算法1和算法2所示。
算法1分类器模型选取
输入:数据集T。
输出:三种分类器模型。
步骤1根据式(1)对数据进行标准化处理。
步骤2将DoS类型的数据取出,使用不同学习器的特征选择算法对数据的特征进行多次排序,按照分类影响重要性由高至低依次排序。使用投票法思想将多次出现的重要特征选取出来。其余类型的数据特征选择使用和DoS相同的特征选择方法。
步骤3使用特征选择后的数据分别建立分类器,取出DoS类型数据集D进行标记,并将余下的数据集P标记为同一类,共形成了两类数据,使用数据训练分类器模型。完成建模后去除DoS类型的数据。
步骤4使用步骤3分别对Probe、R2L和U2R训练分类器模型,直至完成使用类型模型的建立。
步骤5输出三种分类器模型。
完成分类器建模后可以使用分类器模型对待分类数据进行分类操作,设待分类数据集M={x1,x2,…,xn},该数据集中每个样本有41维特征不包含标签。
算法2分类器分类
输入:数据集M。
输出:分类结果。
步骤1根据式(1)对数据进行标准化处理。
步骤2复制数据集M,得到相同的数据集M′。
步骤3首先从数据集中分类得出DoS类型数据,选出对DoS类型数据有着积极影响的特征,使用分类器模型完成第一次分类,得出DoS类型数据和Rest1数据。
步骤4从数据集M′中删除DoS类数据,得到数据集N,复制数据集N得到相同的数据集N′。按照数据类型的分类顺序,重复步骤3,直至分类完成。
步骤5输出分类结果。
2 实 验
本实验采用KDD CUP99数据集,使用训练集建立分类器模型,测试集测试分类器的性能。在KDD CUP99数据集中,数据共有五大类:NORMAL、Probe、DoS、U2R、R2L。其中:Probe类包括6小类,DoS类包括10小类,U2R类包括8小类,R2L类包括15小类。这五大类数据的分布极其不平衡,比如在训练集中DoS类的数据多达391 458记录,而数据量最少的为U2R仅仅只有52条记录。使用准确率(Accuracy)、检测率(DR)和误检率(FAR)作为算法的评价标准。

(3)

(4)
2.1 数据预处理操作
KDD CUP99数据集是入侵检测做模型分析时最常用到的数据集之一,因此本文中采用KDD CUP99的10%训练集(共494 021条数据)建立学习器模型,使用KDD CUP99的测试集(共311 027条数据)验证模型效果,该数据集每行表示一个记录,每条记录有41维特征和一个类标签。在该数据集中的某些特征值为非数值类型,因此首先对数据中的非数值类型值转换为数值型。例如第二列特征Protocol-type,其值有三种协议:tcp、udp、icmp。对其进行数值化处理,将tcp、udp、icmp依次转化为0、1、2,如表2所示。

表2 非数值类型特征转化为数值类型
在入侵检测过程中,对给定的数据集进行分类操作。这需要准确分辨出哪些是正常数据,哪些是异常数据。因此,本文将训练集中正常数据的类标签Normal的替换为‘0’,其余非正常数据标签Probe、DoS依次替换为‘1’,‘2’,U2R和R2L 替换为‘3’。
对数据完成标准化操作,数据标准化又称去均值和方差按比例缩放,表示原始值与均值之间差多少个标准差,是一个相对值,所以它也有去除量纲的效果。同时,它还有两个额外的好处:均值为0,标准差为1。对数据进行Z-score标准化处理:
(5)

KDD数据集中,每条数据包含41个特征,一些特征对分类结果有较小或者没有影响,因此需要进行特征选择操作。本文使用基于学习器的特征选择方法选择重要特征,主要用到了支持向量机、KNN、决策树、GBDT、LightGBM五种学习器。对每次选取的特征按照重要性进行排序,得到五种特征排序结果,选取在五种排序里重要性较大的特征进行实验对比,最终选取实验结果较好的特征。对DoS类型的数据一共选取了15维的特征,Probe类型的数据一共选取了19维的特征,R2L和U2R一共选取了18维的特征。所选取的特征对分类结果有着积极的影响,被去除的特征对分类结果影响较小或者是一些噪音数据影响分类结果。各个类型数据选取的特征如表3所示。

表3 各个攻击类型所选取的重要特征

续表3
2.2 实验模型与结果分析
在多步分类过程中,经过对比实验选出对各种类型数据分类效果最好的分类器。对DoS类型数据使用支持向量机分类器,对Probe类型数据使用决策树分类器,对U2R和R2L使用B-Bagging分类器。分类器如图3所示。

图3 分类器模型图
因为U2R和R2L的训练样本数量只有1 178条记录,因此在建立B-Bagging的模型时需要重新调整训练集中Normal、U2R和R2L样本数量的比例,在实验中发现提升U2R和R2L训练样本的比例能提高其检测率并降低误检率。使用KDD CUP99的验证集对建立的模型进行测试并与其他方法进行对比,得到各个类型的检测率和误检率分别如表4和表5所示。

表4 各种方法的检测率对比结果

表5 各种方法对数据集总体的检测率和误检率对比
可以看出,使用支持向量机使得DoS的检测率达到了99.55%且误检率仅为5.23%;决策树对Probe的检测率达到了90.88%且误检率仅为6.74%;B-Bagging方法使U2R和R2L的检测率达到了52.16%且误检率仅为8%。各个攻击类型数据的检测率都有相应的提高,并且总体的检测率也有一定提升,但总体的误检率有所增高,原因是正常数据被预测为非正常数据的样本增多,这在现实生活中,可能会影响用户访问网络的体验,但增强了网络的安全性,因此也在合理范围内。U2R和R2L在KDD训练集中共有1 178个样本,相比较总体的49万条样本所占比例极低,这对在KDD测试集的31万条样本中检测16 417条的U2R和R2L带来了一定难度,但在使用了本文的B-Bagging方法后也带来了较高的提升。在网络中U2R和R2L会带来更大的危害,提升U2R和R2L的检测率对增强网络的安全具有更大的意义。各方法的检测率和误检率的对比分别如图4、图5所示。

图4 不同方法的检测率对比

图5 不同方法的误检率对比
3 结 语
针对每种特征对每种数据分类时的影响并不相同和不同的分类器对不同类型数据分类结果存在差异的问题,本文采用了多步分类的方法并将相似度较高的U2R和R2L合并为一类,同时采用不同的分类器对每种类型的数据进行分类。该方法能充分利用数据特征对分类结果产生的积极影响,并且选取针对每种类型数据最优的分类器进行分类,达到最好的分类效果。实验结果表明该方法切实可行,采用检测率和误检率这两个评价指标与其他方法进行对比可以看出该方法对分类效果的提升。为进一步提高算法的性能与准确率,下一步考虑将深度学习和神经网络相结合用到入侵检测系统当中。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
软件导刊(2017年4期)2017-06-20
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
